
高速列车晚点预测的机器学习模型
2021-01-19 14:28:20胡瑞文超张梦颖徐传玲
中国铁路 2020年11期
胡瑞,文超,3,张梦颖,徐传玲
(1.西南交通大学综合交通运输国家地方联合工程实验室,四川成都610031;2.西南交通大学综合交通大数据应用技术国家工程实验室,四川成都610031;3.滑铁卢大学铁路研究中心,安大略滑铁卢N2L 3G1)
0 引言
智能高铁将云计算、大数据、北斗定位、下一代移动通信、人工智能等先进技术,通过新一代信息技术与高速铁路技术的集成,全面感知、融合处理、主动学习和科学决策,实现高铁的智能建造、智能装备和智能运营。智能调度理论是高速铁路智能运营的核心基础理论,“列车晚点传播问题”和“轨道交通调度指挥智能化及风险预警”入选由教育部、科技部、中国科学院、国家自然科学基金委员会等联合发起的《10 000个科学难题交通运输科学卷》[1],说明运营调度智能化理论是轨道交通运输组织优化亟待解决的难题。
得益于大数据技术的发展,机器学习方法已经在诸多领域的理论研究和运营实践中凸显了优势[2]。在数据充足的条件下,机器学习模型可以研究列车间更为复杂的作用过程,更深入地解析晚点传播及恢复过程[3]。文超等[4]认为传统数学模型不能有效处理列车运行产生的巨复杂数据,而机器学习相关模型适用于处理数据驱动的智能铁路运营分析。Lulli等[5]以描述大型铁路路网的态势为目标,混合传统分析和数据驱动模型的描述方法,构建了一个动态铁路多源数据分析系统。孙略添等[6]运用灰色模型对技术站列车晚点进行预测,再综合运用马尔可夫和改进的神经网络模型进行修正和预测,最后将2种方法进行了对比,显示神经网络模型在大规模数据集情形下预测精度更高。Huang等[7]提出一种基于SVR算法和KF算法的混合模型用于预测列车运行时间,该混合模型结合了2种算法的特点,做到了更短计算时间下的高准确率预测。解熙等[8]建立以6个绝对指标和5个相对指标的列车晚点事件统计体系,对传统城市轨道交通晚点评价进行了完善。
目前,相关研究对铁路运行数据的处理尚不够精细,没有充分结合高速列车调度实际与机器学习模型运算特点,因此优先运用相关模型对列车数据进行分析,对列车数据进行筛选,可使其在机器学习模型预测中发挥更有效的作用。
1 晚点数据统计分析
1.1 数据描述
数据来源于中国铁路广州局集团有限公司管辖的广深高铁,时间跨度为2015年6—12月,共计10万余条。广深高速铁路全长113 km,铁路下行方向分别是广州南、庆盛、虎门、光明城、深圳北、福田共6个车站。列车运行数据包含高速列车的计划运行图和实际运行图,具体为列车车次、到达车站、实际到达时间、实际出发时间、图定到达时间、图定出发时间和经停股道等。使用的数据经过预处理和清洗,具体处理对象有数据记录为空值、数据记录错误、数据存在极端异常值等,经过清洗后的数据各参数间不存在数量级差异。
1.2 列车晚点描述性统计
要详细了解列车运行数据的特征和规律,对列车运行数据进行描述性统计是必要的手段。列车晚点时间作为度量列车运行情况的重要指标也是预测的目标,有必要对其进行详细分析和挖掘,为下一步建模预测晚点时间做准备。箱线图是一种常见的数据描述方法,常用于表示数据量较大且分布跨度较大的数据集,将一组数据按照由大至小的顺序排列,不被纳入箱中的数据作为数据分布的异常值,上边缘为最大值,然后是上四分位数值、中间值、下四分位数和下边缘。在实际调度过程中,只有终到时间大于图定终到时间4 min的列车才统计为晚点列车,广深高铁各站到达晚点时间箱线见图1,其中广州南站晚点时间为始发站出发晚点时间,其余各站为到达晚点时间。
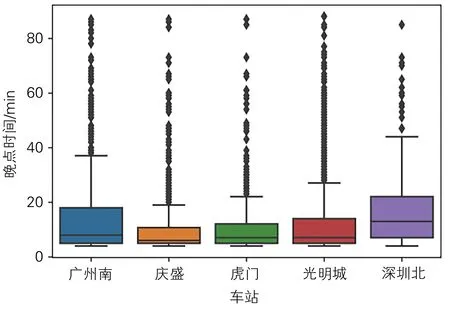
图1 各站晚点时间箱线
由图1可知,广州南站出发晚点列车数为784列,平均晚点时间为14.96 min;庆盛站晚点列车数1 070列,平均晚点时间10.15 min;虎门站晚点列车数604列,平均晚点时间11.20 min;光明城站晚点列车数1 259列,平均晚点时间12.95 min;深圳北站晚点列车数237列,平均晚点时间17.68 min。各站晚点数据描述性统计见表1。结合图1和表1可知,各站的晚点时间均值都大于第二分位数,这表明各站的晚点时间分布很不均匀,这也是图1中各站箱线图绘制的都更接近底部的原因,部分严重晚点列车拉高了平均晚点时间。图1中各站箱线图上方异常值较多则说明数据呈现明显的右偏态势。晚点偏度系数指标也证实了广深线所有车站的晚点数据分布呈现右偏,广州南站和深圳北站晚点偏度系数较低,分别为2.16和1.82,而中间站的晚点偏度系数均较高。
对列车相关数据进行进一步分析可知,在始发站广州南站的始发列车晚点数虽不多,但晚点时间偏高,随着列车在广州南—庆盛区间运行,产生了更多的晚点列车,但是晚点时间得到了部分恢复,其中庆盛站—虎门区间恢复了大量晚点时间较短的列车。这是因为列车在区间运行中可有效吸收5 min左右的晚点时间,但对于始发晚点时间大于10 min的列车,往往并不能有效恢复晚点,甚至会产生增晚的情况,导致始发晚点事件本就严重的列车在终到站依旧晚点。从晚点方差指标可以看出全线晚点列车分布都不均匀,列车晚点时间跨度都较大,其中始发站广州南站的始发晚点方差达到了252.11,深圳北站的终到晚点时间方差是236.19,始发和终到站的晚点时间分布跨度最大。各站的晚点时间峰度指标均大于3,表示广深线的晚点数据分布非常陡。

表1 各站晚点数据描述性统计
2 晚点特征分析及数据降维
结合预处理后的数据计算各列车在各站的到达晚点时间、出发晚点时间、停站时间、实际区间运行时间、图定区间运行时间、列车接续时间、车站冗余时间、区间冗余时间共8个列车运行参数。由于列车运行参数较多且其数据量较大,有必要对参数进行定量的相关性分析和数据降维处理。
2.1 晚点影响因素定量分析
对于多个特征系数常用皮尔逊相关系数(Pearson)去度量特征系数间的联系强度,该系数计算公式和应用可参考文献[9]。现令X1为到达晚点时间,X2为出发晚点时间,X3为停站时间,X4为实际区间运行时间,X5为图定区间运行时间,X6为列车接续时间,X7为车站冗余时间,X8为区间冗余时间,Z为目标值,即下一车站列车到达晚点时间。经过计算得到各特征系数之间与目标值之间的Pearson(见表2)。从表2可知,X1、X2、X3、X4、X7共5个列车运行参数与目标值的Pearson为正,表明其与列车到下一车站的晚点时间呈现正相关性,其余特征系数值X5、X6、X8的Pearson为负,表明其与列车到下一车站的晚点时间呈现负相关性。

表2 列车运行参数Pearson
2.2 晚点影响因素数据降维
Lasso模型是一种常见的回归方法,通过压缩估计构建惩罚函数,计算出一个更简洁的模型。模型的相关公式和应用可参考文献[10]。λ取值为5,经过计算得到相关系数非零的数量为5个,各参数相关系数分别为0.298 85、0.601 71、0、0.200 85、-0.426 10、0、0、-0.356 77。将Lasso模型计算的参数系数与Pearson的结果进行结合,得到晚点特征评估表(见表3)。

表3 晚点特征评估
由 表3可 知,X1、X2、X4、X5、X8这5个 参 数 在Lasso系数评估中都是不可缩减的一部分,再综合考虑Pearson相关系数和列车运行实际情况,停站时间也是预测列车在下一车站晚点时间的重要因素,而列车接续时间和车站冗余时间不会因列车晚点而产生时间值上的变化,只是将事件发生的时间点在时间的水平坐标上平移,因此添加X3停站时间也作为预测晚点时间的参数。综上,共有6个参数被用于预测模型建立。
3 基于梯度提升决策树的晚点预测
机器晚点预测是铁路运营智能化的功能之一,既可一定程度上减轻调度员的工作压力,也可为调度行车指挥命令提供参考,选择梯度提升决策树模型进行预测。
3.1 模型介绍
GBDT算法是一种集成算法,广泛应用于工业界、金融界和各类数学竞赛中[11],由Gradient Boosting算法和Decision Tree算法2部分组成,将2者综合即为梯度提升决策树,该集成算法以残差下降为优化方向,不停地将上一个优化的输出作为下一次优化的输入,从而以期达到最优值。该模型算法在回归分析中的表现非常出色,是目前使用度高且具有良好泛化能力的算法。模型具体步骤如下:
(1)假设有训练集数据。(xm,ym)为一组数据,则训练集数据为:

(2)确定生成数个数(迭代数)为N,损失函数为L(y,f(x)),yi为真实值,c为对应预测值,则设置初始化弱回归器为:

(3)对迭代次数n=1,2,3,…,N,设置负梯度为:
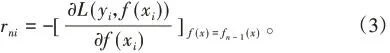
运用上式计算回归树,得到第n颗回归树。其叶子节点域为Rns,s=1,2,3,⋅⋅⋅,S,S为回归树N的叶子节点个数,计算S的最优拟合值为:

得到S的最优解后,从而更新回归器:
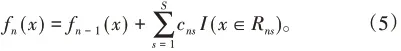
(4)得到最终学习器为:
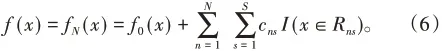
拟解决的是回归问题,利用负梯度拟合残差可实现回归功能[12]。
3.2 晚点预测实验及结果分析
要运用GBDT模型进行晚点时间预测,还需要对相关重要参数的取值进行研究,将数据集划分为训练集和测试集,选取总数据量的20%作为测试集,训练集数据进行参数训练。现选取了一些主要参数包括nums学习器的数量、max_features最大特征数、subsample采样比例、max_depth树的最大深度。
nums是学习器的数量,即初始学习器的迭代次数,通常取值过小易导致欠拟合,取值过大易导致过拟合,在此默认取值100。nums参数训练结果见图2,nums参数随着取值增加训练集分数快速提升,该参数取值100。

图2 nums参数训练结果
max_features是最大特征数,划分子节点时需考虑的值。max_features参数训练结果见图3,max_features参数随着取值增加测试集分数波动巨大,当取值大于0.8后较稳定,因此该参数取值1。
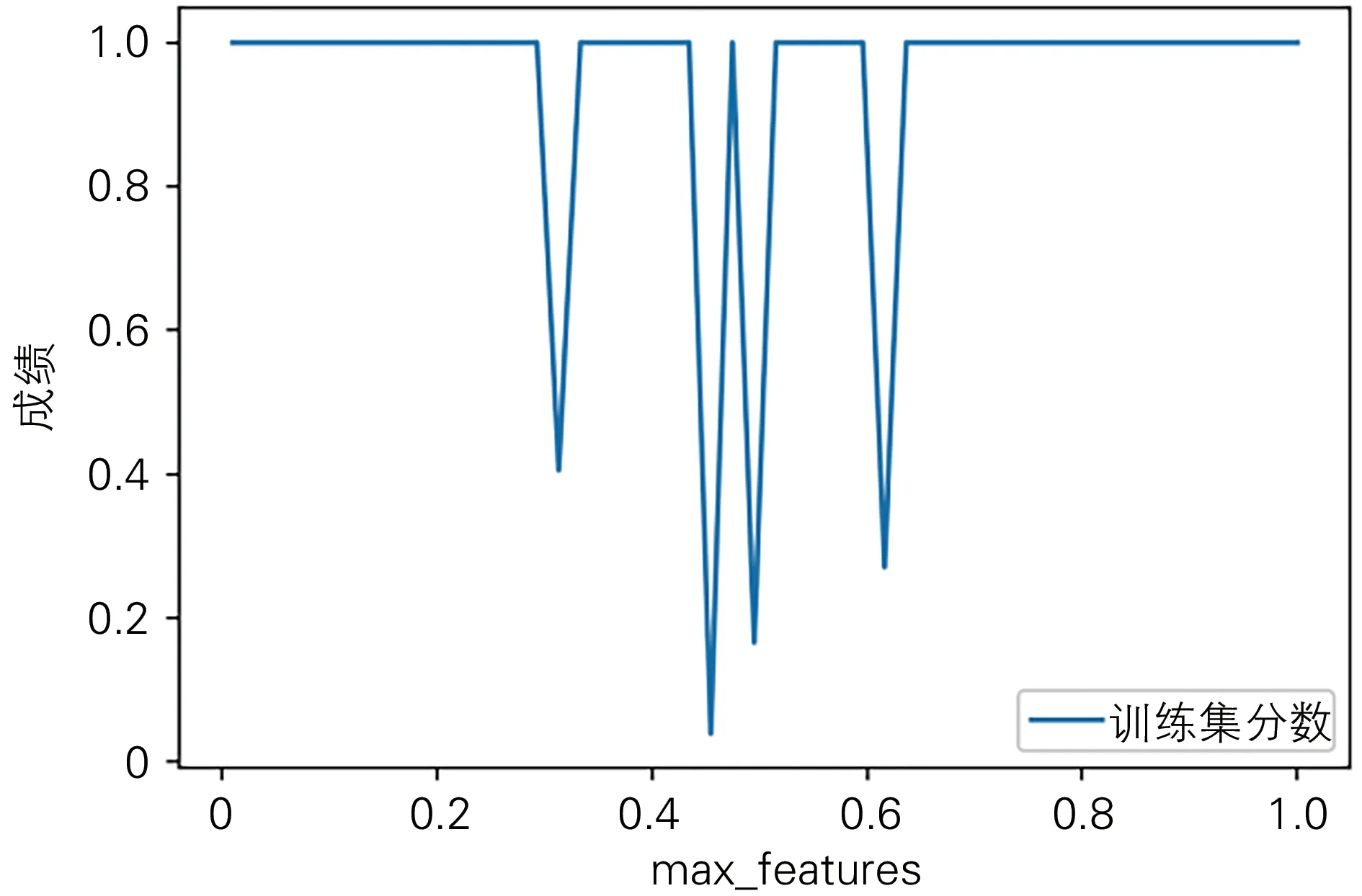
图3 max_features参数训练结果
subsample是采样比例,即在多少数据集上运用决策树去提升梯度,该值默认比例为100%。subsample参数训练结果见图4,subsample参数随着取值增加,模型测试集分数波动较大,参数取值超过0.6后准确度达到了平稳且优异的状态,因此该参数值为1。

图4 subsample参数训练结果
max_depth是树的最大深度,决定决策树生出子树的深度。max_depth参数训练结果见图5,max_depth参数随着取值增加测试集分数快速提升,取值10以后准确度非常平稳,因此该参数取值17。

图5 max_depth参数训练图
在确定了主要参数取值后,运用GBDT模型预测各列车在下一车站的晚点时间,用R2值和平均绝对误差MAE评价回归模型,R2值着重评价晚点时间预测准确度,MAE着重评价对各车次晚点时间预测的误差。


结果显示预测准确率较高,晚点列车训练集数据的R2值为0.97,测试集R2值为0.89;晚点列车训练集数据MAE为0.09 min,测试集MAE为0.32 min。同时,设置以机器学习的近邻算法模型(KNN)为预测方法的对照组,邻近样本个数设置为5,叶子节点数量设置为30,则对照组晚点列车测试集数据的R2值为0.76,MAE为0.84 min。因此,基于GBDT模型的高速列车晚点时间预测的效果是非常优秀的。考虑到测试集数据量较大,因此仅显示测试集部分列车的预测情况,晚点时间预测效果见图6。

图6 GBDT模型部分预测结果对比
绘制图6时,先绘制表示实际晚点时间的蓝色折线,当预测完全一致时,表示预测晚点时间黄色折线将覆盖蓝色折线。结合模型指标与图6可知,该模型预测结果贴近实际,其预测准确度很高,可以为列车晚点预测提供一定辅助作用。
4 结束语
基于高速列车运行实绩,通过充分挖掘和分析列车运行数据,运用皮尔逊相关系数分析数据的相关性,运用Lasso模型实现数据降维,并进而建立高速列车晚点预测的GBDT机器学习模型,模型测试结果表明所建立模型能够很好地预测高速列车晚点。准确预测高速列车的晚点时间,能够降低调度工作负荷、提高调度决策的质量,是高速铁路实现智能调度的重要环节。智能运营是智能高铁的核心价值体现,是智能高铁研究和实践必须攻克的难题,其中高速列车晚点预测及列车运行调整的高铁调度是重要内容,利用机器学习方法预测高速列车的晚点,将能够为高铁调度智能化提供理论支撑,相关预测模型可作为高铁智能调度决策系统的相应模块,助力高铁智能调度系统开发。
猜你喜欢
铁道科学与工程学报(2022年10期)2022-11-30 13:02:12
金沙江文艺(2022年4期)2022-04-26 14:14:22
小哥白尼(趣味科学)(2021年4期)2021-07-28 02:23:50
云南画报(2021年4期)2021-07-22 06:17:10
铁道通信信号(2020年1期)2020-09-21 08:55:16
小学生学习指导(低年级)(2019年6期)2019-07-22 03:32:48
西南交通大学学报(2018年6期)2018-12-18 02:23:24
铁道通信信号(2016年8期)2016-06-01 12:10:21
中国铁道科学(2015年6期)2015-06-21 06:54:54
中国火炬(2014年11期)2014-07-25 10:32:08
