
基于TextRank的关键词提取改进方法研究*
2021-01-19 11:01孟彩霞李楠楠
计算机与数字工程 2020年12期
孟彩霞 张 琰 李楠楠
(西安邮电大学计算机学院 西安 710121)
1 引言
关键词是表达文档核心的最小单位。从单个或多个文档中的文本中提取关键短语是信息检索(IR),文本挖掘(TM)和自然语言处理(NLP)领域中的重要问题,也是文档聚类,文档摘要和信息检索任务的基本步骤。因此,关键字提取在文本数据挖掘领域发挥着重要作用。
关键字提取包含有监督的提取方法和无监督的提取方法[1]。鉴于有监督的关键词提取方法需要人工标记的语料库,而人工标记因人而异,从不同的角度出发有不同的结果。本文主要关心无监督的关键词提取方法,表1为典型的无监督关键词提取方法对比。
基于图形的文本表示被称为提取关键短语的最佳无监督方法之一,可以非常有效地查询文本和结构信息之间的联系。其中,最具有代表性的就是谷歌提出的PageRank算法[7]。TextRank将PageRank算法思想引入文本,以词语为图节点,文本间的共现关系表示为图结构,并通过图的迭代计算实现重要性排序,可以用于关键词/文本摘要抽取[6]。经典的Text Rank算法在摘要提取时只考虑了句子节点间的相似性,而忽略了文档的篇章结构及句子的上下文信息。文献[8]中,于珊珊等提出引入标题、段落信息、句子长度等外部信息,改善TextRank中句子相似度计算方法和权重调整因子。文献[9]中,利用Word2vec模型训练词向量计算词汇之间的相似度,进而对TextRank算法进行改进。文献[10~12]中,利用LDA算法对文本语料库进行挖掘,进而改善TextRank算法。文献[13]中,利用聚类算法调整簇内节点的投票重要性,结合节点的覆盖和位置因素,改进TextRank算法以提高关键词的提取效果。
本文利用word2vec词向量工具表示文本信息,并结合文本的外部信息,如词语位置信息和语义相似度对TextRank算法进行改进,实验取得了良好的效果。
2 Word2vec
Word2vec是一个用于生成单词向量的开源工具包。由Word2vec训练的矢量具有以下特征:字之间的相关性可以通过字矢量之间的矢量距离来测量。语义相关性越高,两个词向量之间的距离就越短[15]。Word2vec可以利用连续词袋模型(CBOW)和Skip-gram模型来产生词向量。CBOW的主要思想是根据单词周围的上下文预测中心单词的概率,而Skip-gram模型是围绕中心单词来预测上下文[16]。在Word2vec的基础上,文本关键词提取算法可以在一定程度上保持句子之间的语义相关性。
3 TextRank
基于图的排序算法本质上是一种基于从整个图递归绘制的全局信息来确定图中顶点的重要性的方法。基于图表的排名模型实现的基本思想是“投票”或“推荐”。当一个顶点链接到另一个顶点时,它基本上就是为该另一个顶点投了一票。为一个顶点投的投票数越高,该顶点的重要性越高。此外,投出选票的顶点的重要性决定了投票本身有多重要,排名模型考虑了这一信息。因此,与一个顶点相关联的得分是基于为其投出的选票以及投出这些选票的顶点的得分来确定的。
形式上,令G是具有顶点集V和边集E的有向图,其中G'=V*V的子集。对于给定的顶点Vi,令In(Vi)是指向它的顶点集(前趋),令Out(Vi)是顶点Vi指向的顶点集(后继者)。顶点Vi的得分定义如式(1)所示:
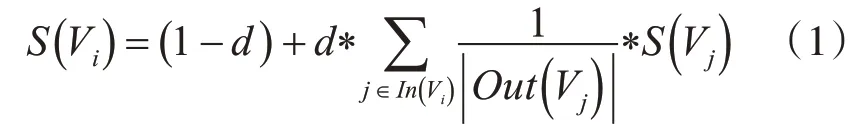
其中d是可以在0~1之间设置的阻尼因子,其作用是将从给定顶点跳到图中的另一个随机顶点的概率整合到模型中。阻尼因子d通常设置为0.85。
TextRank运行完成后获得的最终值不受初始值选择的影响,只是收敛的迭代次数可能不同[6]。鉴于此,本文将研究重点放在词语的状态转移矩阵上,通过状态转移矩阵改善TextRank算法运行结果。
4 本文研究方法
基于TextRank的关键词提取问题,是将关键词提取问题转化为图排序问题。图1为改进Text Rank提取关键词的工作流程。

图1 改进Text Rank提取关键词的工作流程
4.1 文本预处理
清理和标准化文本的整个过程叫做文本预处理[15]。本文包含的处理过程为:1)除去数据中非文本部分,如:图片。2)处理中文编码问题。中文的编码并非是utf8,而是unicode。未处理的编码问题会导致在分词的时候出现乱码。3)中文分词。中文不同于英文,分词结果的好坏很大程度上影响了后续的实验结果。本文采用Python实现,分词和词性标注使用jieba开源工具包。
4.2 TextRank词图构建
TextRank是基于图形的关键词提取方法,因此首先要根据单个文本的候选关键词构建词图。主要步骤如下:
Step1:对单文档D进行分词,即D=[w1,w2,w3,…,wn];
Step2:对D去停用词、词性标注,选特性词性的词(如名词、动词、形容词)作为候选关键词,得D1=[w1,w2,w3,…,wm];
Step3:对D1应用TextRank算法,本文以词语间的相似性和共现频率作为关键词提取的权重。
构建候选关键词图G=(V,E),其中V为节点集,表示由步骤(2)中生成的候选关键词D1=[w1,w2,w3,…,wm],G'=V*V,对于图G中的任意的一个节点,In(Vi)表示指向Vi的节点,Out(Vi)表示由Vi所指向的节点。令wij表示由节点Vi→Vj的边的权重,则节点Vi的分值WS(Vi)如式(2):

其中d等于0.85,节点初始值为1,根据式(2)迭代获得节点权重。当两次迭代误差小于等于0.0001时,算法收敛。
4.3 节点权重
在构建关键词图的过程中,本文为实现节点间非均匀的进行权重传递,将权重的影响因素分解为:词语位置影响力和词语跨度影响力[13]。令w表示节点权重,a、b分别表示词语位置影响力和词语跨度影响力,则:w=a+b=1。
1)词语位置影响力
令e=

其中Loc(Vi)表示词语的位置信息,具体计算如下:

2)词语跨度影响力
在TextRank算法中,由于滑动窗口的设定,在同一窗口内会经常有若干相同词的情况,这样就会导致算法的提取结果是局部关键词而非全局关键词[17]。因此本文将词语跨度作为考虑因素。计算式(4)如下:

其中D(V)如式(5):
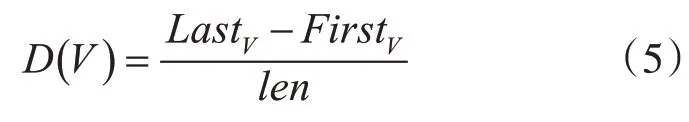
其中Lastv表示词语v在文中最后一词出现位置,Firstv表示第一次出现位置,len表示文档词语总数。
结合以上,wij可通过以下式(6)得到,Wij表示Vi转移到Vj的权重:
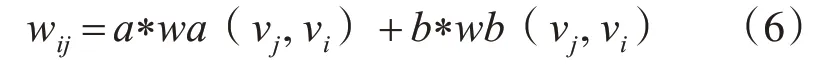
5 实验与结果
5.1 实验数据
本文采用夏天论文中提供的新闻数据[12]。通过python中文分词包jieba进行分词,词性标注。然后,采用Word2Vec模型,以默认参数对这批文本数据进行训练得到词向量模型文件。
5.2 评价标准
为便于与已有方法对比分析,本文采用准确率P、召回率R以及测量值F作为关键词抽取效果的评判标准,其计算公式如下:

5.3 实验结果与分析
本文将以下方法进行对比:1)传统的TF_IDF方法;2)文献[6]提出的TextRank关键词提取;3)文献[9]提出的Word2Vec+TextRank方法;4)本文关键词提取方法。
通过调整实验参数,当a=0.35,b=0.65时实验效果相对较好。当提取关键词个数为[1,7]时,实验结果如图2。
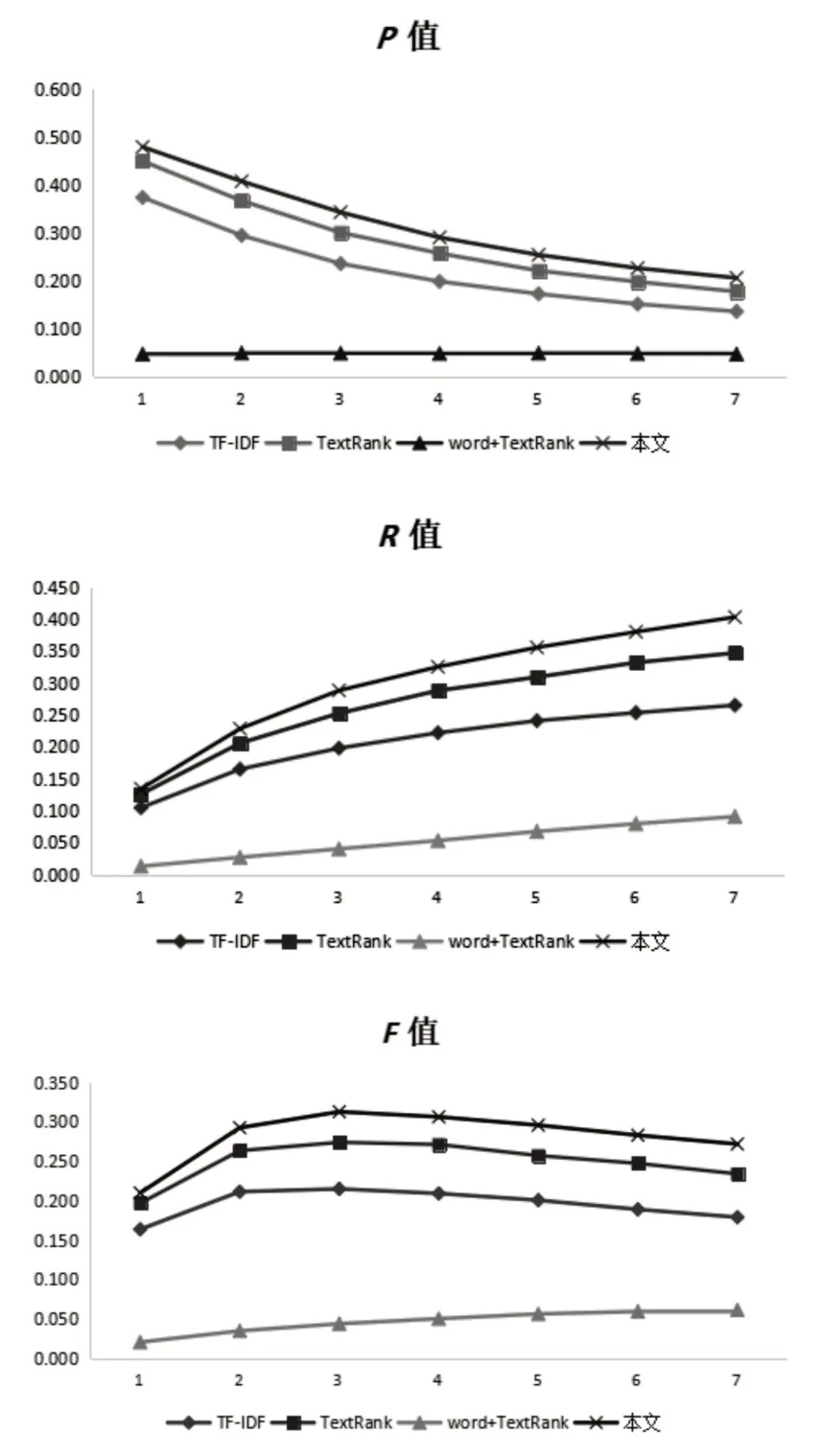
图2 准确率P、召回率R,平均值F
由图2可知,当关键词个数在K=3、4时,F值较高,所得实验效果最佳。当K≥4时,随着关键词个数增加,准确率P和平均值F逐渐降低,这是由于实验数据中的关键词个数大多在3~5之间。因此当实验数据提取关键词个数为3、4时,提取效果最好。
6 结语
实验结果表明,对于单文档的无指导关键词抽取来说,TextRank只考虑了部分语义信息,但没有考虑文档的结构信息,因此当利用文档外部信息改善TextRank算法时能取得较好的实验结果。具体表现:使用基本的TextRank算法进行关键词提取时,当关键词个数相同K=3时,TextRank算法评价指标P、R、F分别为22.21%、19.78%、20.92%;加入文档结构信息后评价指标P、R、F分别为29.83%、31.34%、30.56%。
猜你喜欢
客联(2022年3期)2022-05-31
中等数学(2021年9期)2021-11-22
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
小学生学习指导(中年级)(2018年9期)2018-09-07
电脑爱好者(2017年7期)2017-05-06
中学生数理化·高一版(2009年6期)2009-08-31
