
基于狼群算法的软件可靠性模型参数估计研究*
2021-01-19 11:01于苗苗王东升魏海峰
计算机与数字工程 2020年12期
于苗苗 朱 兵 李 震 王东升 魏海峰
(1.江苏科技大学电子信息学院 镇江 212003)(2.上海船舶研究设计院 上海 201203)(3.江苏科技大学计算机学院 镇江 212003)
1 引言
软件可靠性是评判软件质量的重要特征之一,也是评价软件质量的主要定量标准,具有重要的研究意义,因此越来越受到研究者的重视。迄今为止,研究者们已经发表了近百种软件可靠性模型,比如G-O模型[1]、M-O模型[2]和J-M模型[3]等。然而这些模型基本上都是非线性函数模型,很难直接估计它们的参数,所以一种新的思路是将智能优化算法应用到模型参数的估计中。
群体智能算法在电力系统、航空航天、无线传感网络等领域得到了广泛的研究与应用,但是在可靠性方面的研究相对较少。Harish Garg等[4]提出将PSO算法用于工业系统的可靠性分析中,通过PSO算法来优化系统中的关键参数,从而提高工业系统的性能及可靠性;Tarun Kumar Sharma等[5]提出将一种改进的ABC算法用于软件可靠性增长模型的参数估计中,改进后的算法具有双向搜索的能力,这使得算法的全局探索能力更强,性能更好,能更准确地预测模型的参数;Alaa Sheta[6]提出将粒子群算法用于软件可靠性增长模型的问题中,通过PSO算法优化模型的参数,从而更好地通过模型来预测软件失效数。WPA作为群体智能优化算法的一种,是由吴虎胜等学者系统地提出[7]。该算法具有较好的全局收敛性和较高的精度值,种群的多样性较高。狼群算法也是一种典型的群体智能算法,目前对于狼群在一些领域的应用也是较多,比如图像分割、无人机等[8~12]。
张克涵等[13]使用粒子群算法进行软件可靠性模型参数的估计,存在的缺陷是算法搜索范围大、收敛速度较慢,并且求解的精度不高;王正初等[14]提出了将粒子群算法用于求解复杂系统可靠性优化问题,并通过2个实例验证了该算法的可行性和有效性。
鉴于狼群算法具有较好的全局寻优能力,收敛速度快。本文提出一种基于狼群算法(Wolf Pack Algorithm,WPA)的软件可靠性模型参数估计的方法。
2 基本概念
2.1 软件可靠性及模型
软件可靠性,是在规定的条件下和时间内,软件不引起系统发生失效的概率。IEEE计算机学会对软件可靠性作出如下的定义[15]:1)在规定的条件下,在规定的时间内,软件不引起系统失效的概率;2)在规定的时间周期内,在所述条件下,程序执行所要求的功能的能力。文章选择软件可靠模型中具有代表性的G-O模型作为研究对象,对其参数进行估计。
软件系统中累积失效数的估计函数形式如下:
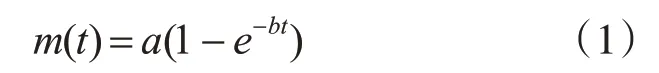
其中:m(t)代表到时刻t为止的累积失效数的期望函数;a代表测试结束后软件期望被检测出来的失效总数;b表示剩余失效被发现的概率,是一个比例常数,范围为(0,1)。
2.2 狼群算法的基本原理
狼群算法意在模拟狼群的捕猎行为处理函数优化问题,将狼群分为三类:头狼、探狼和猛狼。将狼群的整个捕猎活动抽象为3种智能行为(游走行为、召唤行为、围攻行为)以及“胜者为王”的头狼产生规则和“强者生存”的狼群更新机制。
1)头狼生成准则:从待寻优空间中的某一初始猎物群开始,其中具有最佳适应度值的狼作为头狼。
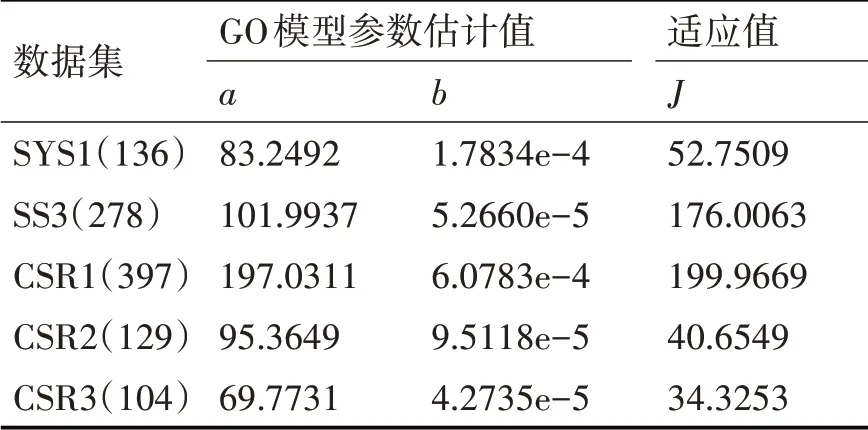
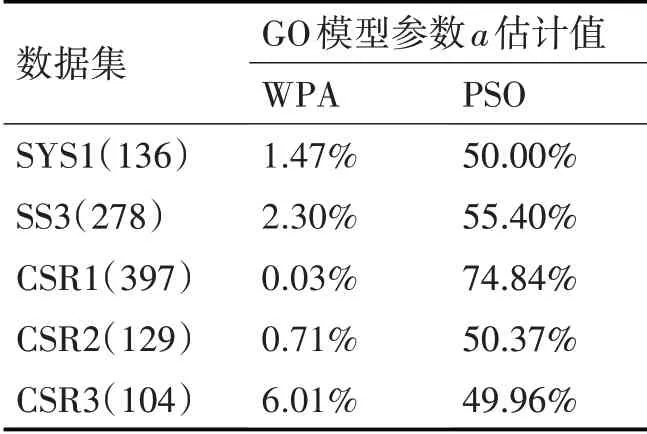
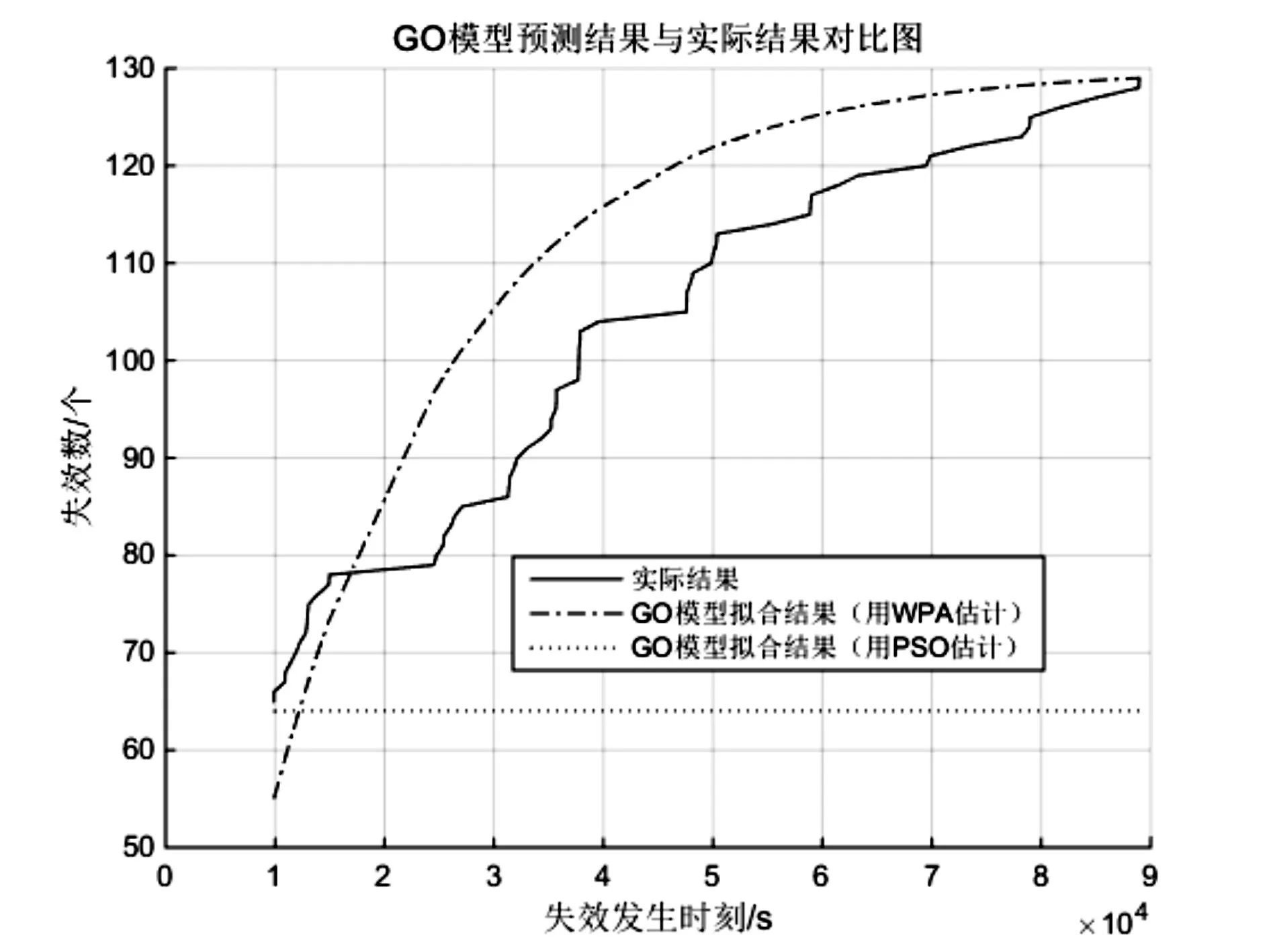
2)游走行为:选取除头狼外最佳的S_num匹人工狼作为探狼执行游走行为S_num随机取[(α+1),n/α]之间的整数,n为狼群中人工狼群的总数,α为探狼比例因子。首先计算探狼i当前位置的猎物气味浓度Yi,如果Y i 探狼i一直游走行为直至某一匹探狼所感知的气味浓度Yi 其中,对于每一匹探狼的猎物搜索方式是存在差异的,即h的取值是不同的,在实际情况中取[hmin,hmax]之间的随机整数。 3)召唤行为:头狼发起嚎叫进行召唤行为,通知周围M_num匹猛狼迅速向头狼靠拢,其中M_num=n-S_num-1;猛狼听到嚎叫,都以相对较长的奔袭步长快速地向头狼的位置逼近(此时的步长称为奔袭步长st ep b)。则猛狼j经历第k+1次迭代次数时,在第d维空间中的位置为 在奔袭的过程中,如果猛狼j感知到的气味浓度Y j 其中:D为待寻优变量空间的维数;maxd和mind是待寻优的第d维空间的最大值和最小值。w为距离判定因子,其不同取值将影响算法的收敛速度,当w增大时,会加速算法收敛,但是如果w过大,就会使得人工狼很难进入围攻行为,缺乏对猎物的精细搜索。 4)围攻行为:狼群根据式(5)进行围攻行为。对于第k代狼群,设猎物在第i维空间中的位置为,可用如下公式表示狼群的围攻行为 式中,λ为[-1,1]间分布的随机数;为人工狼i在第d维空间中采取围攻行为时的攻击步长。 式中,S为步长因子。 5)“强者生存”的狼群更新机制。剔除目标函数值最差的R匹人工狼,并且同时随机产生R匹新的人工狼。R的取值为之间的随机整数,β是群体更新比例因子。 文献[13]中使用粒子群算法进行了软件可靠性模型参数的估计研究。此方法是构造一种适应值函数,将参数估计的问题转变为函数优化问题。构造的适应值函数如下: 式(7)中:J表示实际测出的软件失效数与通过模型估计出的软件失效数之间的欧式距离,m(t)表示在测试时间段[0,t)中实际发现的累积失效数;m(t)代表在测试时间段[0,t)中用模型估计出来的累积失效数;t表示失效发生时刻;T表示终止测试的时间。 本文使用软件可靠性模型参数的极大似然估计公式来构造新的适应值函数,并且在算法执行过程中先剔除掉那些明显错误的解,再根据先验知识朝着更准确解的方向搜索。 文章使用极大似然法对G-O模型进行估计,a、b的结果计算公式如下所示: 上式中:n表示已知的失效数;t i为第i个失效发生的时刻;i=1,2,3,…n。 文章根据G-O模型参数a、b的极大似然估计公式构造一种新的适应值函数,具体做法是将式(8)中的第一项代入到第二项中并进行数学变换,构造成一个只与参数b相关的式子,如下所示: f即为新的适应值函数,公式中除了b以外其余的参数均为已知,f越小说明参数b估计的效果越好。通过WPA算法迭代搜索,当达到算法停止准则后输出最优的参数b,然后再代入参数a的极大似然估计公式中求出对应的最优的参数a。 在实现G-O模型的算法中,由于参数b是(0,1)范围内的随机数,在算法的迭代搜索过程中可能会出现一些问题解。为了得到较好的值,需要将实验中的问题解剔除。通过多次的实验运行可以发现,参数b的精度必须保持在1e-5内,因为当参数b的精度达到1e-6或者更高时,就会出现问题解。因此在程序中,对参数b加入限制条件,从而达到剔除问题解,使算法在较好解的范围内继续搜索的目的。 根据式(8)可知参数a和b是反向的关系:b大则a小,b小则a大。如果根据第一次运行得到的结果b求出的累积失效数a大于已知失效数,希望a的值变小,那么由先验知识可知参数b的值就要偏大,继续运行程序找出较大的b;如果根据第一次运行得到的结果b求出的参数a小于已知失效数,希望a的值变大,那么由先验知识可知参数b的值就要偏小,继续运行程序找出较小的b。由此,作为下一轮算法的迭代的开始,可以求出更加准确的参数。 本文使用实际工业项目中得到的5组软件失效间隔时间数据集SYS1、SS3、CSR1、CSR2、CSR3,数据下载地址为http://www.cse.cuhk.edu.hk/lyu/book/reliability/data.html[13]。文章将文献[13]中的参数估计方法与本文提出的基于狼群算法的软件可靠性模型参数估计方法的实验结果进行了对比。 WPA算法各参数设置如下:人工狼的总数n=50,距离判定因子w=100,最大游走限制次数Tmax=30,探狼比例因子α=4,更新比例因子β=10,步长因子S=1000;,适应值精度要求k≤1e(-5),每个狼群的位置即GO模型的参数b,b是初始化为(0,1)之间的随机数。算法初始运行20次,按照第3章节中的原则取最好的结果作为初始值。实验结果的对比见表1和表2所示。 表1 狼群算法的估计结果 表2 文献[7]的估计结果 使用本文的算法和文献中的算法的执行结果与实际结果的误差率对比如表3所示。 表3 两种算法误差率对比 已知SYS1、SS3、CSR1、CSR2、CSR3这5组数据集实际的累积失效数n分别为136、278、397、129、104。由表1、表2和表3可以看出用本文提出的狼群算法估计所得的累积失效数a相较于文献[13]而言,估计出的准确度是更高的,与实际结果n的误差均在2%内,而文献[7]估计出的误差率较大,由此有力地说明了文章提出的方法具有更好的准确性。 在这一小节中,我们主要的研究内容是将参数估计和模型预测结合起来,针对两种方法,分别用5组数据集的前一半失效来估计GO模型的参数,然后将估计出来的参数代入到GO模型的函数表达式中,对后一半失效的发生时刻进行预测。算法初始运行20次,按照第3章节中的原则取最好的结果作为初始值,参数估计的结果如表4、表5所示。 表4 狼群算法的估计结果 表5 文献[7]方法的估计结果 表6 两种算法误差率对比 观察表4、表5和表6,可以发现在只用数据集的前一半数据做参数估计时,本文方法估计出的结果与实际值的误差依旧是很小的,但是使用文献[13]方法估计出的结果与实际值之间的误差比较大。这说明在实际的工业项目中,在只有少部分失效数据的情况下,用本文提出的方法可以更加合理的进行估计与预测。 将表4和表5中的参数分别带回到公式(1)中,根据公式分别对5组数据集后一半失效的发生时刻进行预测,并将得到的预测结果曲线与实际曲线作对比,如图1~5所示。 从图1~5观察可以发现,使用本文提出的狼群算法预测的曲线与实际曲线相比,尽管有一定的误差,但大致上走势是一致的;并且曲线是呈指数分布,曲线的斜率不断变大,表明软件失效发生的时间间隔不断增大,说明软件的可靠性逐渐在得到改善,这是符合实际软件测试中可靠性随着失效的发现及修改而得到提高的情况。由此可知,根据本文提出的狼群算法用一半失效数据做模型参数估计,再通过模型来预测后面失效发生的时刻在实际中是比较可行的并且是较为准确的。 图1 SYS1数据集后一半发生失效时刻 图2 SS3数据集后一半发生失效时刻 图3 CSR1数据集后一半发生失效时刻 图4 CSR2数据集后一半发生失效时刻 软件可靠性模型参数估计的效果会直接影响模型预测的准确性,所以具有重要的研究意义。文章提出了一种基于WPA的软件可靠性模型参数估计方法,利用极大似然估计方法构造了新的适应值函数,在算法运行过程中增加了问题解的剔除,同时优化了参数的搜索方向。最终的实验数据和结果比对表明,文章提出的方法可以很好地提高软件可靠性模型参数估计和预测的准确性。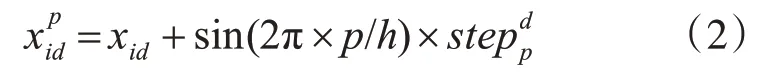




3 研究方法
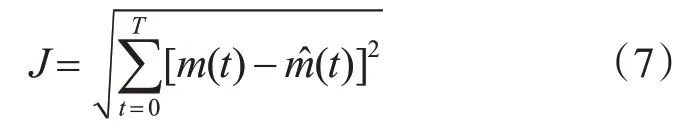
3.1 适应值函数的构造

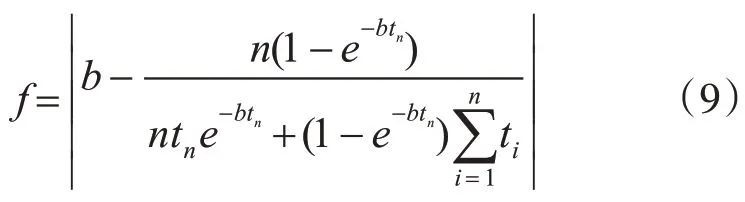
3.2 问题解的剔除
3.3 先验知识
4 算法仿真结果
4.1 参数估计


4.2 估计与预测





5 结语
猜你喜欢
小读者·爱读写(2021年9期)2021-09-26消费电子(2021年7期)2021-08-10北京航空航天大学学报(2020年10期)2020-11-14新少年(2020年10期)2020-10-30电影故事(2017年10期)2017-07-18智富时代(2017年4期)2017-04-27智富时代(2017年4期)2017-04-27时代金融(2017年6期)2017-03-25中学生数理化·八年级数学人教版(2016年4期)2016-08-23理科考试研究·高中(2016年9期)2016-05-14
