
一种基于频率的多最小支持度挖掘算法
2021-01-19 11:01古良云乐红兵
计算机与数字工程 2020年12期
古良云 乐红兵
(江南大学 无锡 214122)
1 引言
数据挖掘又称知识发现,它的目的是为了从庞大的数据中发现有意义的隐藏的知识[1],关联规则[2]是由R.Agrawal等于1993年提出的,在数据挖掘领域它是一个重要且热门的研究课题。关联规则,顾名思义它的目的是为了挖掘两个及以上项目之间隐藏的联系。关联规则的示例如下:
床单→枕套[sup=40%,conf=90%]
这条规则表示40%的顾客会同时购买床单和枕套,而购买床单的人中有90%购买了枕套。
关联规则有关定义为I={i1,i2,…,i m}D={T1,T2,…,T n}是m个不同项目的集合,那么任意一个项目i k则被称为一个项目。T是I的子集{t1,t2,…,t n},称为事务,每一个事务有一个唯一标识号,记作TID。事务全体构成了事务数据库D,|D|表示D中事务的个数。关联规则是形如X⇒Y的蕴含式,其中X⊂I,Y⊂I,同时集合X和Y也为不相交的两个集合,即X∩Y=φ。关于关联规则的蕴含式可解释为项目集合X出现在某一个事务数据中,则可能导致项目集合Y也会以某一个概率存在于相同的事务数据中。在研究领域,通常使用两个指标来度量项目集合之间关联规则的紧密程度,即支持度和置信度。其中支持度可解释为事务数据库中即包含集合X又包含集合Y的事务数量与|D|之间的比值。即:

支持度反映了X、Y同时出现的概率。定义置信度为包含X和Y的事务数与包含X的事务数之比。即:

置信度反映了如果事务中包含X,则事务中包含Y的概率。
在关联规则挖掘领域,若某一个集合在事务数据库中出现的频率大于一个用户设定的值,则将这个集合称为频繁项集[3],假设这个集合中有k个元素则称这个集合为k-频繁项集即L k,同时这个用户设定的值被称为最小支持度即min sup。
在关联规则的学习中,评价项集的一个重要指标即为支持度,支持度的大小代表项集在数据库中的普遍性,这个项集出现的越普遍则说明这个项集越重要[4]。置信度用来衡量关联规则的准确性。综上所述,在发现关联规则的过程中有两个不可或缺的评价标准,这两个标准能够衡量规则的好坏,即支持度和置信度[5]。针对关联规则的Apriori算法的局限性,人们提出了一些改进的算法。如基于交集的InterApriori算法[6],基于压缩矩阵的Apriori算法[7]等。文献[8]为了突破Apriori算法的瓶颈,利用矩阵有效地处理数据库中的事务,使用“与”运算以达到最大的计算效率,并且不需要频繁地扫描数据库来查找事务。文献[9]扫描数据库后对事务进行二进制编码,并根据事务出现的实际频率进行排序,以此来对候选项集进行剪枝,文献[10]提出了一种不产生候选项集的算法FP-growth,该算法采用递归策略并且扫描两次原始数据集即可。这些改进的Apriori算法使用的最小支持度均是用户指定的唯一的值,这就默认数据中的所有项均有相同的频率[11],但在现实生活中情况往往更加复杂,比如实际收集的数据具有多样性,有些项目出现的极其频繁,而有些项目则很少出现。如果项目的频率变化很大,将会出现两个问题:1)如果最小支持度设置的很高,则不能发现出现频率较低的项目;2)如果最小支持度太低,则会出现规则爆炸的现象,这样的挖掘结果是没有意义的[12]。
以购买商品为例,人们经常购买酸奶,但购买酸奶机的频率却很低,假设酸奶和酸奶机采用相同的支持度,如果支持度设置过高,在最后生成的关联规则中将很难得到有关酸奶机的规则。而在实际生活中,酸奶机的利润比酸奶要高许多,且在人们购买酸奶机时还会购买自制酸奶的其它材料,因此一般情况下用户会认为由酸奶机产生的关联规则是比较重要的,但是相同的支持度会导致在项目集中由于酸奶机的支持计数较低,包含酸奶机的频繁项集被丢弃,有关酸奶机的规则被遗漏。如果支持度设置过低,又会出现大量无意义的规则。
解决这一问题的方法是可以让用户指定多个最小支持度,比如可以为数据集的每个项目都指定一个最小项目支持度[13],这样可以反映出不同项目具有不同频率的特性。文献[14]提出了使用相关项目集中各项目最小支持度中的最大值来实现剪枝,避免产生过多无意义的规则。文献[15]提出了一个基于多最小支持度的加权关联规则算法,允许用户为每个数据项设置不同的权重和最小支持度,但仍然存在着产生大量候选项集,充分扫描事务数据库I/O开销很大等不足。
利用多最小支持度模型,本文提出了一种基于频率的多最小支持度算法,将事务数据库中项目的实际出现频率作为其最小项目支持度,并通过设置项目频率最小阈值避免产生过多无意义的关联规则。这对增强关联规则挖掘的实用性,提高生成关联规则的准确率具有积极意义[16]。
2 相关工作
本文描述的改进算法是一种根据事务数据库中各事务本身的出现频率再单独设定其最小支持度的算法,此改进算法仍使用之前的支持度定义。
在该挖掘策略中,一条规则的最小支持度[17]采用在规则中出现的所有项目的最小项目支持度。也就是说,在数据集中,每个项目都拥有一个用户指定的最小项目支持度,通过对不同的项目指定不同的最小项目支持度,用户就可以方便地对不同规则设置不同的支持度要求。
定义1:最小项目支持度
对于项目集I={i1,i2,…,i m},其中任一项目皆设置了其最小支持度,即是最小项目支持度,写作MIS(i)。

其中count(i)是项目i在数据集中出现的次数,|D|是事务集的大小。
定义2:项目频率最小阈值
对于项目集I={i1,i2,…,i m},用户设置项目出现的最小频率值,称之为项目频率最小阈值,记作MF,其中M F≥0。
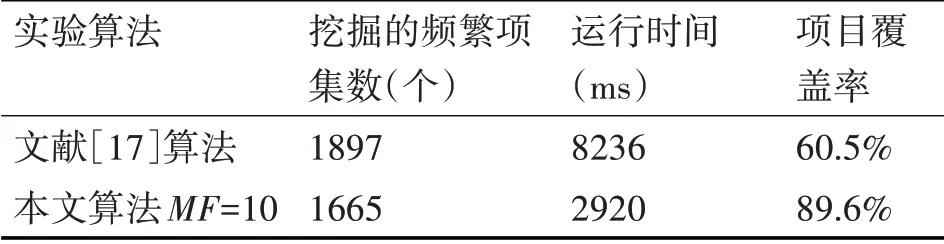
在大型数据集中,将项目出现频率作为最小项目支持度,考虑到现实情况中事务记录表会出现大量频率极低的项目,生成大量1-频繁项集,提高算法的运行时间开销。因此,用户可设置项目出现频率最小阈值MF,减少1-频繁项集的数量。在生成1-频繁项集过程中,∀i∈I,若count(i) 定义3: 假设有R:i1,i2,…,i k⇒i k+1,…,i r,其中i r∈I,在这个规则中最小项目支持度的最小值min(MIS(i1),MIS(i2),…,MIS(ik),MIS(ik+1),…,MIS(ir))则为规则R所需要满足的最小支持度。 由以上定义可知,采用最小项目支持度可以对不同的规则进行不同的最小支持度限制。对于包含出现频率较高的项目的规则,其最小支持度可以很大,而对于出现频率低的项目的规则,其最小支持度可以很小。 例1:项目集I={A,B,C},各项目最小项目支持度分别为MIS(A)=20%,MIS(B)=1%,MIS(C)=2% 1)规则C⇒A[sup=1.5%,conf=70%]不满足其最小支持度。 因为min(MIS(A),MIS(C))=2%>1.5% 2)规则C⇒B[sup=1.5%,conf=70%]满足其最小支持度。 因为min(MIS(B),MIS(C))=1%<1.5% Apriori算法挖掘关联规则通常需要两个环节[18]: 1)以迭代的方式发现原始数据集中全部的频繁项集; 2)根据设定的最小置信度,在频繁项集中挖掘关联规则。 Apriori算法的性质为[19]假设一个项集为频繁项集,则它的所有子集除非空子集外都是频繁项集。 但是,如果我们使用本文的改进算法来生成频繁项集,这一性质已经不再满足了。 例2:项目集I={A,B,C,D},各项目最小项目支持度分别为MIS(A)=12%,MIS(B)=18%,MIS(C)=3%,MIS(D)=5% 假设使用改进算法在第2轮搜索时得到2-项集{A,B},它的实际支持度为10%,由于实际支持度小于MIS(A),也小于MIS(B),所以,根据改进算法策略,项集{A,B}被丢弃。由于{A,B}被丢弃,将导致在第3轮搜索中不会产生3-项集{A,B,C}和{A,B,D}。但是经过分析,项目C和D的最小支持度很低,那么3-项集{A,B,C}和{A,B,D}就极有可能是频繁项集,所以丢弃项目集{A,B}就可能是错误的。因此,采用改进算法时,Apriori算法的性质将不再满足。 候选项集的大小直接影响算法的挖掘效率,因此可通过修剪候选项集来提高算法的挖掘效率。为了解决这一问题,本算法采用了将候选项集按照项目属性的最小项目支持度排序的方法,尽可能多地完成剪枝,减少算法运行的开销。 具体描述:在多最小支持度的情况下,对每个数据集所包含的项按照各自的最小项目支持度进行升序排列,经过排序后,整个数据集的最小支持度就由其首项的最小项目支持度确定,所以,当其(k-1)-子集包含首项或者(k-1)-子集的最小项支持度等于最小支持度时,就可以根据子集是否在(k-1)-频繁项集中来判断是否将其剪枝。 例3:假设有3项频繁集:L3={<1,2,3>,<1,2,4>,<1,3,4>,<1,3,5>,<1,4,5>,<1,4,6>,<2,3,4>},对各项目按照其最小项目支持度进行排序,结果为{1,2,3,4,5,6},由L3得到候选项集C4={<1,2,3,4>,<1,3,4,5>,<1,4,5,6>},对候选集进行剪枝时,由于<1,5,6>∉L3,由此可知,sup(<1,4,5,6>) 按照上文的算法思想,得到基于频率的多最小支持度算法如下: 输入:挖掘数据库DB,项目频率最小阈值MF 输出:频繁数据集L 算法步骤: 1)对数据库DB进行初次扫描,得到候选项集C1。 2)计算各项目的实际出现频率count(i) 3)if count(i)>MF 4)insertiintoL1 5)else 6)deleteifromC1 7)得到频繁项集L1,根据定义1中的公式(3)得到最小项目支持度 8)根据最小项目支持度对频繁项集L1中的各项目按照升序排序 9)for(k=2;Lk-1≠∅;k++) 10)Ifk=2 11) then C2=level2-candidate-gen(L1) 12)else 13) Ck=candidate-gen(Lk-1) 14)end 15)扫描数据库,计算每个候选项集中的数据集的支持度 16)若该候选项集的支持度大于或等于最小项支持度,则为频繁项集 17)合并各长度的频繁项集,得到所有的频繁项集 长度为2的候选项集C2的产生过程: level2-candidate-gen(L1) 1)for each item c inL1 2)if count(c)/|DB|≥MIS(c)then 3) for each item h inL1that is after c do 4) if count(h)/|DB|≥MIS(c)then 5) insert 在剪枝过程中添加了限制条件,具体描述如下: Candidate-gen-prune(Ck) 1)for each itemcinCk 2)for each(k-1)-subset s of c do 3) if s中包含首项c[1]ands∉Lk-1 then delete c fromCk 4) if s中不包含首项c[1]and(s中包含某项c[n]and MIS(c[n])=MIS(c[1]))ands∉Lk-1then delete c fromCk 上述算法与Apriori算法的剪枝过程相比,添加了步骤4)的限制条件。具体示例见例3。 4.1.1 实验平台与实验数据 为了验证算法的有效性,采用三个实验与基于频率的多最小支持度挖掘算法进行对比。实验环境为1.70GHz AMD A6 CPU,6G内存和Windows 7操作系统,算法在MyEclipse平台上采用Java语言编程实现。在Java中随机函数random()产生的数据上进行了测试,其好处是可以灵活产生所需数据,且无需进行预处理。随机函数生成的数据如表1所示,共8条事务记录,6个项目。 表1 随机数据 4.1.2 实验结果与分析 将该数据分别应用Apriori算法与基于频率的多最小支持度挖掘算法进行关联挖掘。生成的频繁项集如表2所示,两种算法的挖掘结果如表3所示,其中项目覆盖率指算法挖掘高、低频率项目的能力,覆盖率越高,说明算法挖掘的频繁项集中涉及的项目越全面。 表2 Apriori算法与多最小支持度算法生成的频繁项集 表3 两种算法挖掘结果对比 通过表2、表3的实验结果可以看出: 1)使用较小支持度的Apriori算法得到了大量的频繁项集,使用较大支持度的Apriori算法则遗漏了小概率频繁项集,而基于频率的多最小支持度挖掘算法生成的频繁项集数目则介于这两种支持度的Apriori算法之间。 2)使用基于频率的多最小支持度挖掘算法运行时间介于两种支持度的Apriori算法之间,但是在项目覆盖率方面,基于频率的多最小支持度挖掘算法明显高于其它两种Apriori算法。 选取标准UCI数据集中的Zoo数据集,将该数据集应用于本文提出的基于频率的多最小支持度挖掘算法和文献[17]提出的算法,并对实验结果进行比较。实验结果如表4所示。 表4 Zoo数据集挖掘结果对比 由表4可知,与文献[17]提出的算法对比,使用基于频率的多最小支持度挖掘算法具有较高的项目覆盖率,且运行时间短。因此,本文算法在效率提升方面的效果也是显著的。 将本文提出的基于频率的多最小支持度挖掘算法、文献[17]提出的算法与Apriori算法应用于真实数据[20],对实验结果进行对比。实验数据来源:https://www.kaggle.com。该数据库存储超市中顾客的线上交易记录,在该数据库中,User_Product表中共有12430条记录,记录中包括用户ID,用户名,用户购买的商品ID,商品名称,购买时间,商品类别,商品摆放位置等15个属性。对该表中的数据进行预处理,其中保留用户ID及商品ID属性值,处理后的数据形式如表1所示。挖掘后的规则中,可根据数据库中的Product表查询出对应的商品名称。实验结果如表5所示。 表5 交易数据库挖掘结果对比 由表5可知,使用基于频率的多最小支持度挖掘算法具有较高的项目覆盖率,且综合挖掘的频繁项集数和运行时间,基于频率的多最小支持度挖掘算法都具有较理想的挖掘效果。 本文主要讨论了在关联规则挖掘中,针对Apriori算法中的始终保持单一的最小支持度的不足,提出并实现了一种基于频率的多最小支持度挖掘算法。该算法针对每个项目设定了最小项目支持度,弥补了Apriori算法中的不足,并通过设置项目频率最小阈值避免产生过多无意义的关联规则,新算法能有效地挖掘出出现频率较低的项目的关联规则。通过在合成数据与实际应用中验证了新算法的有效性。3 基于频率的多最小支持度算法描述
3.1 基于频率的多最小支持度算法中的剪枝策略
3.2 基于频率的多最小支持度算法描述
4 实验分析
4.1 实验一



4.2 实验二
4.3 实验三

5 结语
猜你喜欢
节能与环保(2022年7期)2022-11-09计算机应用与软件(2022年7期)2022-08-10保健医苑(2022年5期)2022-06-10计算机应用与软件(2021年11期)2021-11-15哈尔滨理工大学学报(2021年4期)2021-10-07成都信息工程大学学报(2021年6期)2021-02-12计算机与数字工程(2020年7期)2020-10-09电脑知识与技术(2017年27期)2017-11-20计算技术与自动化(2017年3期)2017-10-26天津诗人(2017年2期)2017-03-16
