
基于词法匹配与词嵌入的医疗知识实体上下位关系抽取*
2021-01-19 11:00刘子晨温延龙
计算机与数字工程 2020年12期
刘子晨 温延龙 徐 雷
(1.南开大学计算机学院 天津 300000)(2.南开大学现代远程教育学院 天津 300000)
1 引言
人工智能研究与社会需求表明,医学知识库的构建与医疗知识的组织和管理已成为精准医学领域的研究热点[1]。在大数据时代,随着医疗系统的电子化和信息系统的发展,医疗领域目前已经累积了海量的数据。知识图谱所具有的数据集成能力和知识推理能力顺应了这一发展趋势,可以将这些海量数据进行整合、管理及应用。
实体上下位关系抽取是知识图谱本体构建过程中的一个环节和该领域的研究重点。实体上下位关系的获取是语义层次结构构建的核心,而语义层次结构又是知识图谱构建不可或缺的一环。同时,实体上下位关系不仅是构建知识图谱的一个关键环节,而且由其所构建起来的分类体系在医疗知识的问答系统和决策支持系统等应用中同样有着重要作用。
目前在医疗领域,国内外已经构建了一些知识库,比如医学主题词表MeSH[2]、医学系统命名法-临床术语SNOMED-CT[3],以及国内上海曙光医院构建的中医药知识图谱[4]。但是这些已有知识库或是针对特定医学子领域,或是有着缺乏灵活性和能力不足等限制,无法满足如今人们对于医疗知识图谱的需求。而对于大规模数据的上下位关系抽取,因为人工方式工作量巨大,以及专家难寻等原因,通过计算机技术自动化从大规模医疗语料中抽取实体上下位关系的研究非常有必要。
虽然当前针对医疗领域的实体上下位关系抽取模型还很少,但对于开放域上的上下位关系抽取方法的相关研究已有许多。本文通过融合词法模式匹配方法和基于词嵌入的机器学习方法,构造出一个医疗知识实体上下位关系抽取的综合方法。该方法缓解了传统Hearst-like词法模式匹配[5]方法的召回率低,模式过于固定的缺陷,并通过引入分段线性投射改造基于词嵌入的上下位关系判别模型使其可以应用到上下位关系抽取任务中,而且利用两种方法的互补性,提出了一种融合方法将两种方法结合。
2 国内外研究现状
实体上下位关系也被称为“is-a”关系,是语义关系的一种。这种层次关系在知识表示和推理中起着核心作用。依据实体上下位关系构建的层次分类系统能够改善很多自然语言处理和信息检索任务,比如个性化推荐和问答系统。随着互联网时代的到来,借助大量网络数据,一些上下文层次结构的构建利用了人工编辑的知识库(比如维基百科、维基数据等)。但是这些大型层次分类系统缺乏专业领域知识。如今,国内外提出了很多方法来从大规模语料中抽取实体上下位关系。这些方法可以主要分为两类。
从Hearst等[5]开始通过词法匹配的方式抽取上下位关系成为这一领域的常用方法。该方法将同一语句中满足特定词法模式的两个词预测为上下位关系。该方法的一个典型词法模式就是“[A]such as[B]”,其中[A]和[B]表示名词短语,分别被视为上下位关系中的上位词和下位词。目前在业界,基于该方法已有一些成功的应用比如Probase[6]。但由于这种词法匹配过于具体,无法涵盖所有语言环境,导致其召回率较低。为提高召回率和正确率,Sonw等[7]用上下位词间的依赖路径进行模式匹配,同时对语法和词法联系进行匹配;还有一些工作试图自动学习词法匹配模式而非使用预定义的匹配列表[8~9]。然而此类方法还是有着一个众所周知的问题,就是它的稀疏性,该方法要求上下位词必须以一定的模式出现在同一语句中。
为解决Hearst匹配方法的稀疏性问题,目前实体上下位关系抽取的研究重点逐渐转向了基于词嵌入的方法。借助预训练神经网络语言模型,如Word2Vec[10]、GloVe[11]等,将上下位词表示为词嵌入形式,用机器学习、神经网络等模型,采用有监督方法判别词对是否为上下位关系[12~14]。Fu等[15]通过在中文语料上的实验,指出上下位关系词对的词向量保留了语言规律,如v(虾)-v(对虾)≈v(鱼)-v(金鱼),v代表词向量。这意味着可以通过线性投射矩阵将下位词向量映射到上位词向量,但是由于单一的投射矩阵并不足以覆盖所有上下位关系情况,所以其采用了分段线性投影的方法,来提高模型的效果。在这一工作基础上,国内外学者又提出了更多的方法取得了更优的结果[16~18]。
在文献中,对于那种方法能更有效地抽取实体上下位关系有很多争议。词法模式匹配方法有着非常明显的稀疏性问题[8]。一些研究也显示该方法非常依赖语言特征,在中文语料中的效果很差[15,17]。同时,对于词嵌入方法的质疑声也有很多。Roller等[19]的研究表明,词嵌入方法的模型效果非常依赖于数据集。一些研究也显示词嵌入方法并没有真的学习到上下位关系[20~21]。目前对于有监督任务,在SemEval-2018 task 9[22]所提供的数据集上Dash等[23]提出的SPON神经网络取得了广泛域数据集上的取得最优成绩,然而其在医疗数据集上的表现并不如CRIM系统[24]。
目前在实体上下位关系抽取领域已经有很多研究成果,然而针对医疗领域的实体上下位研究还不是很多。
3 实体上下位关系抽取综合模型
在医疗领域知识实体上下位关系抽取任务中,通常选用的语料是大规模的医疗文献数据集。因为文献相比广泛域写作更加规范而且医疗词汇命名更有规律,所以本文将在模型中使用词法模式匹配方法。又因为基于词法匹配的方法和基于词嵌入的方法存在着互补性[25],且有研究表明在领域内基于词嵌入的方法有着更好的表现[26],因此本文将结合两种方法构成综合模型。
在综合模型中,基于词法模式匹配的方法也可单独作为一个无监督方法进行上下位关系抽取,在该无监督方法中,为了提高召回率和准确率,其利用了PatternSim方法[16]寻找下位词的相似词并基于此构造了上下位关系抽取和可能性计算算法;基于词嵌入的抽取模型引入了分段线性投影的方法,改造了上下位关系判别模型使其更加适应上下位关系抽取任务;最终本文将两种方法进行融合,使得两个方法的所得信息能够互补并减少单一方法带来的错误情况。
同时,相比广泛域上的数据集,医疗领域的数据集词法模式更为规范,且医疗词汇的命名更有规律,这些特性使得词法模式匹配在该领域上有着更好的表现,因此在本综合系统中,提高了词法模式匹配方法所占权重。
3.1 基于词法匹配的无监督抽取模型
无监督实体上下位关系抽取模型主要基于Hearst-like词法匹配,并采用TAXI系统[15]中的子字符串匹配方法和PatternSim方法[16]来辅助提高召回率和准确率。
候选上下位关系抽取流程主要由两部分组成,一部分为Hearst-like词法模式匹配,一部分为子字符串匹配。因为通过Hearst词法模式匹配和子字符串匹配抽取得到的实体对存在很多噪声,所以需要将得到的实体对与实体词词典进行对比,过滤其中不存在于词典中的实体对。
候选上下位关系对将被存储用于后续分析,存储的将不止是其上下位关系,还包含每个实体对的可能性数值。抽取的实体对的可能性算法为ppmin,由roller等[27]提出的ppmi算法改进而来:

用P=表示从语料中抽取的上下位关系词对(x,y)集合,w(x,y)表示该词对被抽取到的次数,W=w(x,y)表示全部抽取次数。p-(x)=w(x,y)/W和p+(y)=w(x,y)/W分别表示在抽取的候选实体上下位关系中x和y分别作为上位词和下位词的概率。
但是ppmi所计算的并非直接的可能性,而是一种可供对比的可能度,其值域并不局限于(0,1],因此本文提出ppmin,用Sigmoid函数将ppmi的值归一化到0到1区间。

在实际应用中,将e改为1.5等更小的数值,以使得Sigmoid函数更加平滑,从而增大ppmi值的区分度。
在得到候选实体上下位关系以及关系为真的可能性的集合后,用PatternSim得到词间相似度,而后用算法1得到最终结果。
算法1上位词查询及可能性计算算法
输入:下位词q
输出:上位词和可能性集合H=
1:初始化结果集合H=Cand idateHyper(q)
2:相似词集合C=(ci,sniq)=PatternSim(q)
3:for each(ci),sniq∈Cdo
4:Hi=CandidateH y per(ci)
5: for each(h j,ppmin(ci,h j))∈Hido
6: ifh j∈Hthen
7:p(q,h j)=1-(1-p(q,h j))×(1-ppmin(ci,h j)×sn(ci,q))
8: else
9:p(q,h j)=ppmin(ci,h j)×sn(ci,q)
10: end if
11:end for
12:end for
CandidateHyper(q)函数将会返回在用词法匹配和子字符串匹配方法抽取的q的候选上位词hi集合,以及在抽取过程中计算的该候选词与q之间为上下位关系的可能性ppmin(q,h i)。PatternSim(q)函数将会返回用PatternSim方法从语料中抽取的q的相似词ci集合,以及在抽取过程中计算的相似度sn(q,ci)。
3.2 基于词嵌入的抽取方法
目前大部分针对上下关系的基于词嵌入的方法,都是判别模型。判别模型在应用到抽取任务时,通常做法为将大量的候选上位词与所输入下位词组合,构造多个上下位关系词对,将每个词对都输入到判别模型中计算上下位关系可能性。这种模式有着非常明显的缺陷。通常情况下,候选上位词集合会很大,全部组合后,每个词对都放进模型进行计算会浪费大量时间,同时,大量的候选词对也会导致模型的鲁棒性不高,在预训练时的参数调整,将对模型效果产生非常大的影响,提出CRIM系统的论文[17]中的消融实验也证明了这点。
为解决这一问题,本文将分段线性投影模型和CRIM模型进行融合。与Fu等[15]相同,本模型将上下位关系词对依照其差值用Kmeans算法分为k个聚类。对每个聚类中的词对训练一个线性投射矩阵φi,其可将下位词投射到上位词。但是在预测时,由于并不知道对于特定下位词,应当选用具体那个投射矩阵,因此用CRIM模型来计算投射后所构造的k个候选上下位关系词对为上下位关系的可能性。如图1所示,在线性投影模型中,对于每个聚类都会得到一个投影矩阵,从而得到k个投影矩阵,在将下位词词向量经过k个投影矩阵的转换后,将得到k个向量。随后,分别找到这k个向量余弦相似度最高的c个词向量。将找到的c×k个词向量与e q输入CRIM模型,得到上下位关系可能性,随后挑选出可能性最高的几个词作为最终结果。

图1 基于词嵌入的抽取模型
方法不止适用于CRIM模型,同样可以应用于其他判别模型用于上位词预测的任务。
3.3 综合方法
如图2所示,综合方法为以上两种方法融合而成,融合方法为以下三个部分:1)将训练数据集融入到词法模式匹配模型作为候选上下位关系集合的一部分。该步骤将通过训练集数据,重新评估每个候选词对的可能性。2)将词法模式匹配的结果输入到词嵌入模型,CRIM模型将不止判断由线性投影所构造的上位词,也将计算词法模式匹配方法所抽取的候选上下位关系。3)将两个模型计算所得结果用如下公式计算可能性:
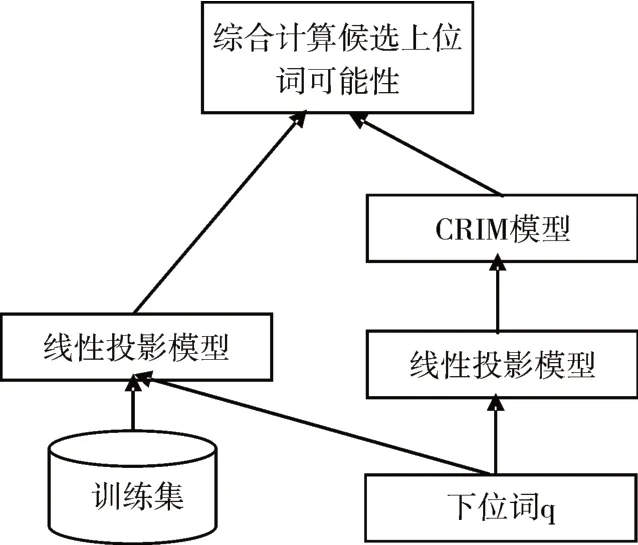
图2 综合方法

sup和unsup分别表示词嵌入方法和词法模式匹配的可能性,若一方不包含该词对,则将其视为0。这种计算方式综合考虑了两个系统对于实体上下位关系的判断,并且也对于单个系统中的强判断给予了关注。
4 实验与分析
本次实验为针对医疗知识的实体上下位关系抽取,所以本次实验的数据集也为医疗数据集。数据集来自SemEval-2018任务9[22]中的Subtask 2A的医疗领域数据集。

表1 医疗实体上下位关系抽取实验结果
表中CRIM为之前在实验数据集上取得最好结果的模型,CRIM_U为CRIM模型中的无监督方法,同样是该实验数据上表现最优的无监督方法,而SPON[23]则是在多个语言的广泛域数据集上取得最优实验结果的有监督模型。通过对比发现,本文构造的综合系统Hybrid在该医疗文本数据集上取得了当前最优的实验结果,相比CRIM模型在MAP、MRR、P@1和P@5指标上分别提升了0.23%、4.40%、2.00%和0.39%。而且本文的无监督模型Unsupervised也为当前实验结果最优的无监督模型,相比CRIM_U无监督模型,在MAP、MRR和P@1指标上分别提升了0.12%、4.76%和7.80%。

表2 对比实验结果
本文的系统由多个部分融合而成,为评估系统每个部分对于整个系统实验结果的影响,将每部分单独进行实验。
Final为最终综合系统的结果;Supervised为3.2节所述模型;SupPattern为将候选集合添加入词嵌入方法后的结果;PatternBase即为系统的无监督方法;PatternSup为将训练集结合入模式匹配的方法。
通过分析该实验结果,可得出如下结论:1)CRIM模型对于词法模式匹配得到的候选词对的可能性判断并不准确。2)词法模式匹配方法和词嵌入方法所得出结果的重合度不高,因此在综合两种方法后系统的效果提升非常明显。
5 结语
本文提出了一种医疗实体上下位关系抽取的综合系统,该系统由两部分融合而成,作为系统一部分的词法模式匹配方法为无监督方法,基于Hearst词法模式匹配方法,提出了一种利用Pattern-Sim方法提高召回率的上下位关系抽取与可能性计算算法;系统的另外一部分为词嵌入方法,本文提出了一种将上下关系判别模型应用到抽取任务的方法,在本次实现的系统中,采用的是CRIM上下位关系判别模型。在实验所采用的医疗数据中,相比其他模型,本系统在所有指标上均取得了最优效果,同时作为系统一部分的无监督模型也取得了无监督任务的最优效果。
猜你喜欢
现代仪器与医疗(2022年4期)2022-10-08
现代仪器与医疗(2022年2期)2022-08-11
军民两用技术与产品(2021年10期)2021-03-16
当代陕西(2019年5期)2019-03-21
21世纪商业评论(2018年3期)2018-03-02
科技经济市场(2017年5期)2017-09-16
青年文学家(2017年21期)2017-07-28
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
少年文艺·我爱写作文(2016年9期)2016-05-14
