
综合数据特征与服务关联的机器学习流程生成*
2021-01-19 11:00赵汝涛
计算机与数字工程 2020年12期
赵汝涛 王 菁
(北方工业大学大规模流数据集成与分析技术北京市重点实验室 北京 100144)
1 引言
生活中很多领域需要用到数据分析,但是根据不同的数据集选择合适的模型并训练、优化参数是一件专业、复杂且耗时的事情,且进行数据分析对业务人员的专业水平和经验都要求非常高,如何根据数据集自动生成机器学习流程(pipeline)是一个难点问题。针对此问题,研究学者开展了AutoML(Automated Machine Learning)研究。AutoML旨在以数据驱动,客观和自动化的方式做出这些决策:用户只需提供数据,而AutoML系统会自动确定最适合该特定应用程序的方法[1]。
因为在实践中探索原始元素和超参数值的整个空间是不可行的,所以这些系统使用复杂的搜索策略来修剪空间并减少需要评估的pipeline数量[2]。AutoML的主要实现方法有:网格搜索方法、随机搜索方法、贝叶斯方法、启发式方法、基于语法的方法等。在当前AutoML工具当中,AutoWeka[3]使用贝叶斯优化,Auto-sklearn[4]使用元学习,TPOT[5]使用遗传编程,而AlphaD3M[6]使用强化学习。据本文了解,到目前为止这些AutoML中大部分都存在耗时长或者性能低的情况,且并没有考虑将pipeline中primitive之间关联关系进行利用。
本文从primitive服务关联角度入手,定义了primitive服务关联模型及挖掘算法,从历史pipeline当中挖掘出primitive间的关联关系,设计了结合服务关联与数据特征的机器学习流程生成方法,可以在产生pipeline的性能和耗时维持在较好水平的同时,使产出pipeline的性能整体提升。
2 综合数据特征与服务关联的机器学习流程生成方法
2.1 整体流程
本文综合数据特征与服务关联的机器学习流程生成方法原理如图1所示,主要分为这几个模块:LSTM预训练模块、GAME生成器模块、LSTM生成器模块和Coach模块。
LSTM预训练模块指将数据集和任务作为输入,训练出预训练LSTM model,在本文当中用于预测pipeline性能和primitive出现概率,训练出的LSTM model供Coach内部使用。
GAME生成器用来生成博弈模型,博弈模型是一个针对于机器学习流程生成问题框定的单人游戏。
LSTM生成器模块用于生成LSTM模型,连同博弈模型一起用于Coach的内部使用。
Coach模块,以GAME生成器、LSTM生成器生成的博弈模型、LSTM和预训练LSTM模型、best-model(预置或上次博弈胜出的模型)为输入,生成两个不同的玩家(图1中的Player)互相博弈,博弈模型中以MCTS[6](蒙特卡洛树搜索)为选点策略的玩家,其中,MCTS用于在巨大的搜索空间高效搜索节点,可用来解决primitive搜索空间过大问题。博弈完成后保留胜者的模型,该博弈过程称为self-play。
机器学习流程生成方法的具体流程是:输入数据集和任务,通过预训练模型模块产生预训练模型,并利用GAME生成器生成博弈模型,以博弈模型为输入通过LSTM生成器生成LSTM,将这些输出一起作为Coach的输入,在Coach内部根据这些输入生成为两个玩家:玩家1、玩家2,用self-play的方式去在博弈模型中博弈(先结束游戏的玩家为胜,即先生成可用机器学习流程的玩家为胜),博弈时使用MCTS算法选择primitive,MCTS中以LSTM(数据特征角度)、服务关联(流程角度)两者共同作为MCTS的选择策略,最终保留获胜玩家的LSTM模型,用于下次指导MCTS选择primitive,从而用强化学习的方法达到不断自我优化的目的。
本文将上述MCTS使用LSTM和服务关联共同指导来生成机器学习流程的方法简称为DFSR方法。
2.2 Primitive服务关联
通过分析机器学习流程中存在的服务关联关系,在Matthew B.Dwyer的系统特性规范模式[11]基础上,将primitive服务关联关系定义如下:

例如对LL0_13_breast_cancer数据集执行分类任务的机器学习流程当中primitive间的存在的部分关联关系示例如表1所示,根据关联关系程度不同分为强关联和弱关联,最终整生成primitive服务关联约束模型。

表1 Primitive服务关联关系示例
Occurrence patterns(发生模式)(a、b均代表单个primitive):
“stron g exist directly”:表示a紧邻b出现,且为强约束关系。
“weak exist d i rect ly”:表示a可能紧邻b出现,弱约束关系。
Order pattern(模式发生顺序):
“a fter”:表示发生模式一直到b出现后才会发生。
2.3 Primitive服务关联模型及挖掘算法
2.3.1 Primitive服务关联模型
Primitive服务关联关系模型用于表示primitive之间的二元行为约束关系,可以表示为一个四元组:
l i=
其中:linkID是服务超链的唯一标识。linkID=ℏ(sourceI D,tar getI D),其 中 ℏ 是 由sourceID和targetID唯一确定l inkI D取值的函数,例如ℏ可以表示为sourceI D+"_"+t argetID。sourceID是源primitive的唯一标识。target ID是目标primitive的唯一标识。consT ype表示两个primitive之间的二元约束关系。
2.3.2 挖掘算法
假设S和T为primitive,将需要的数据构建成频度表,其中包含以下信息:
&S:S在其他primitive前直接出现的总次数;
S>T:T在S之后直接出现的次数;
S→T:T在S之后直接出现的概率。

表2 频度表(示例s为sklearn.preprocessing.KBinsDiscretizer)
为了准确反映服务行为约束的强度,在传统流程挖掘算法中结合AutoML的情况,考虑了机器学习流程的性能指标,本文过滤掉性能过低的机器学习流程结果,使用挖掘算法计算最终的primitive的前后关联关系。基于以上定义,提出基于机器学习流程案例挖掘以发现primitive间二元服务行为约束关系的算法。
算法1服务关联挖掘算法
输入file:生成机器学习流程历史数据
primitives:生成机器学习流程所需要的primitive
输出factor:服务关联系数结果
算法的大致流程为:
Step1输入所有待计算的primitives和待挖掘的文本文件file,file是包含机器学习流程的数据文件,其中包含机器学习流程和机器学习流程的性能数据。
Step2初始化所有primitive。
Step3从file中统计出每个primitive在紧随其他primitive之前和之后出现的次数。
Step4然后嵌套两层循环,第一层为S(服务关联中前一个primitive),第二层为T(服务关联中后一个primitive),分别统计出S>T和&S次数,并利用两者的结果计算出每一个S→T的结果。
Step5将统计结果更新到factor(字典结构,用于记录每一个S→T的结果),最后程序将挖掘结果factor输出。
2.4 基于服务关联与LSTM指导的MCTS方法
MCTS接收s和a作为输入,s指代的是当前数据集的数据特征和机器学习流程,a指代的是action:当前所选的primitive在MCTS中的表述,主要是为了方便于系统操作,将primitive结合相应的语法做出的结构调整,调整后以action的形式呈现。
MCTS接收s和a之后,分别查询出a在s下的LSTM预测值和服务关联预测值,将最终结果用于指导MCTS选点。MCTS的输出是一组action的预测值,玩家在此组action中选出最佳action用于生成机器学习流程,进而和另外一个玩家对抗。
受AlphaD3M的启发,本文考虑到MCTS的UCT算法当中仅考虑下步操作的情况,在其基础上引入primitive服务关联约束模型,与LSTM方法不同,LSTM从数据特征角度给MCTS以指导,服务关联关注的是在流程中前后primitive之间的约束关系,从流程的服务关联角度给MCTS以指导,利用历史经验来对每一个有关联约束强度的action进行指导,从而整体提高机器学习流程的性能。
具体做法是:在MCTS的基础上加入服务关联关系T(l,a),使用服务关联和LSTM的预测值共同指导MCTS的选择,由于这个self-play循环过程是强化学习,在强化学习中存在a在s中的强化学习奖励值、不存在a在s中的强化学习奖励值两种情况,根据情况不同,更改后MCTS的上限绑定更新规则的随机搜索公式如下:

其中,T(l,a)公式是:

wT(l,a):其中l是当前所选action指代的primitive在pipeline中的前一个primitive,a是当前所选action,T(l,a)是前后primitive间的约束强度(通过挖掘到的关联强度表获得),当关联约束关系是“strong exist”时,T(l,a)输出值为1,当关联约束关系是“weak exist”时,T(l,a)输出值为τ的值,当关联约束关系是“always absent”时,T(l,a)输出值为0;强弱界定阈值默认为0.06。w是根据LSTM和UCT输出值大小制定的权值,将T值限制到LSTM预测值的相同数量级,以确保它们具有同等的决策力。
Q(s,a):Q(s,a)是当前action在当前数据集的数据特征和机器学习流程中的预期奖励值,用于强化学习。
cP(s,a)和cP(s,a)sqrt(N(s)):其中,N(s)是当前数据集的数据特征和机器学习流程s被访问的次数;N(s,a)是action在当前数据集的数据特征和机器学习流程s当中被访问次数。P(s,a)是LSTM对从状态s采取行动a的概率的估计,c是决定探索量的常数。
这样,每次循环,当整个公式最终的结果大于新的阈值时,MCTS更新阈值将会更新为当前action的U值,最终选出当前actions中评分最高的action,用于指导MCTS对最优action的选择。如果选择的action既有LSTM预测值,又有服务关联约束值,就意味着该action对于当前数据集的数据特征和机器学习流程有更大价值,那么将比其他普通action更容易成为best action,从而从众多actions中脱颖而出,循环多次后最终结果中将具有更多包含服务关联信息的pipeline,而这些服务关联信息是由满足高性能条件的机器学习流程中提取而来,意味着这种具有服务关联关系的前后primitive搭配更有希望成为高性能的机器学习流程,进而提高生成的整体机器学习流程性能。
综合数据特征和服务关联的DFSR MCTS算法描述如下:
算法2 DFSR MCTS算法
输入board:当前博弈模型中的配置信息
player:当前玩家
numMCTSSims:MCTS规定模拟次数
输出probs:一组action的预测值
算法的大致流程为
Step1输入博弈模型中的board(内容是当前博弈模型的当前数据集的数据特征和机器学习流程,包含可选action、当前机器学习流程等信息)、玩家、numMCTSsims。
Step2然后循环运行numMCTSsims次,每次循环,初始化本次循环当前数据集的数据特征和机器学习流程和玩家的状态信息,清空上次循环的数据,获取本次循环的数据。
Step3接下来使用服务关联和LSTM共同指导从可选action列表中选取综合评分最高的action,替换到当前数据集的数据特征和机器学习流程中的机器学习流程上面(初始机器学习流程是一个模板,替换就是查找出该action在机器学习流程中所属的位置,然后替换到模板相应的位置),再次递归,每次递归到最后的节点后,都会向上反向传播每个点的概率值。
Step4如此多次循环后返回一组包含所有可选action的概率值probs。
3 实验结果及分析
3.1 实验设计
实验使用的数据集来源于OpenML。实验执行分类任务,性能评价指标选择为f1_macro。实验环境如下:
操作系统:Ubuntu18.04;内存:8G;CPU:Intel Pentium(R)CPU G4400 3.30GHz;GPU:Nvidia GTX950;GPU内存:4G。
首先进行数据集划分,每个待运行的数据集为测试集,其余为训练集(剔除每次训练集的关联约束结果)。之后使用TPOT、Autostacker、AlphaD3M和DFSR分别对数据集执行相同任务并对输出结果做对比。实验过程中,对每个数据集运行多次,分别记录了所有产出pipeline的性能和总耗时,最后对实验结果进行了对比。
3.2 结果分析
将本文提出的DFSR方法与TPOT、Autostacker、AlphaD3M在生成的机器学习流程性能和总耗时方面进行了比较,结果如图2、3所示。
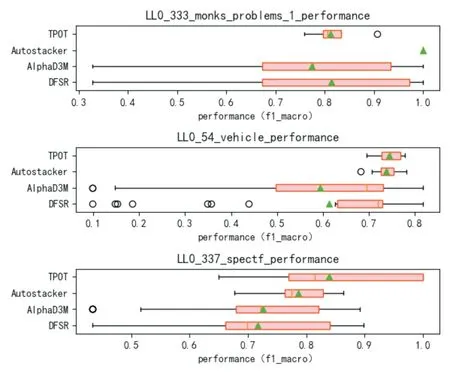
图2 机器学习流程的整体性能对比

图3 生成机器学习流程的整体耗时对比
图2显示的是生成的所有pipeline的性能结果对比。从中可以看出,使用DFSR方法生成的pipeline性能达到了目前AutoML的良好水平。在所有数据集上,使用DFSR方法产生的pipeline性能都高于AlphaD3M。在第一个数据集中,使用DFSR方法产生的性能结果高于TPOT,仅次于Autostacker。在第三个数据集中,使用DFSR方法产生的性能结果高于AutoStacker,仅次于TPOT。
图3显示的是生成的所有pipeline的总耗时对比。从中可以看出,在运行同一数据集的总耗时方面,AlphaD3M和DFSR方法远低于TPOT和Autostacker,执行任务的总耗时从TPOT和Autostacker的小时级别下降到分钟级别;此外,由于服务关联的数量,DFSR方法在不同的数据集上比AlphaD3M多十几秒到几十秒不等。
分析实验结果,降低耗时的原因是由于本文的DFSR方法使用的primitive选择方式与大多数AutoML生成过程中选择primitive不同,大多数AutoML选择的方法是预置一系列模型,然后尝试每个模型,在尝试过程中使用各种算法进行参数调整,然后选择效果好的模型使用。而本文使用的方法是根据数据特征和问题定义去预测机器学习流程每个阶段所需要的primitive,将机器学习流程结构化、工程化,使用神经网络预测来选择模型而不是全部尝试之后选择模型,减少了大量计算时间,从而维持良好的机器学习流程性能水平的同时,降低时间消耗。
此外,由于本文使用了博弈策略,所以理论上输出LSTM模型对生成机器学习流程指导意义更大,同时加上服务关联又可以利用到性能良好的机器学习流程的历史经验,所以生成的机器学习流程整体性能可以达到良好水平。
4 结语
本文介绍了一种在数据分析领域中根据数据集自动生成pipeline的方法,通过结合数据特征与服务关联关系,在耗时方面极大的缩短了AutoML耗时,将总耗时缩短至分钟级。在数据分析领域,本文提出的这种方式,将AutoML和服务组合两个领域的技术应用到了机器学习的pipeline流程生成,为pipeline合成提供了一个新思路。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
今日农业(2021年10期)2021-07-28
ViVi美眉(2019年8期)2019-09-10
当代陕西(2019年15期)2019-09-02
电影(2018年8期)2018-09-21
劳动保护(2018年5期)2018-06-05
学苑创造·A版(2018年11期)2018-02-01
高校招生(2017年7期)2017-06-30
读者(2017年5期)2017-02-15
