
基于时序图像的面部表情识别算法研究*
2021-01-19 11:00李佳希蔡思堃赵长宽
计算机与数字工程 2020年12期
李佳希 蔡思堃 赵长宽 张 昱 陈 默 于 戈
(东北大学计算机科学与工程学院 沈阳 110169)
1 引言
自2012年大规模在线开放课程诞生以来,经过数年的发展,已经对教育教学改革产生重大影响。政府、高校正在围绕实现“确保包容、公平和有质量的教育,促进全民享有终身学习机会”目标,积极推动利用“人工智能、大数据发展、信息通信技术等信息化手段推动教育可持续发展”[1]。随着大规模在线开放课程的快速发展,开展线上和线下相结合的混合式教学改革正在成为课堂教学的重要方向。
相对传统的e-learning系统,大规模在线开放课程力求满足来自不同国家、不同年龄层次的、数以万计的学习者共同的学习一门课程的需求,并尝试通过海量数据实现个性教学目标。在当前的大规模在线开放课程教学中,教学录像依然是教学资源主体。但是基于教学录像的教学交互,这是一种单向的传播行为。师生和生生互动,更多需要借助在线练习、测试、互评作业和论坛等异步方式开展。在传统的课堂教学中,可以开展包括对话、手势、表情等形式多样的交互形式。另外,师生可以视教学交互成果,灵活调整教学交互内容。线下教学具备的自然、亲切、富有人文情感的交互形式是大规模在线课程所欠缺的。
情感对人类活动的影响是显而易见的,情感对认知、注意力、记忆和推理的影响已经获得心理学、教育学和神经生物学等领域的关注[2]。随着语音、视频、传感器、无线网络、增强现实技术发展[3],基于情感计算深入洞察教学交互主体的情感互动与交流,将有助于提升大规模在线开放课程和混合式课程的教学质量和水平。
依据面部表情照片,计算其蕴含的情感,并将其归入Paul Ekman提出的六种基本情感(包括生气、害怕、厌恶、开心、伤心和惊讶)之一[5],是情感计算的核心任务之一。直接辨别与基于面部动作编码系统(Facial Action Coding System,FACS)的符号判别是主流的研究方法[6],已经取得很多成果。但是,此类研究所用数据大多数来自于实验室采集而非现实场景,例如FERPlus、AffectNet、Emotio-Net、MMI和SFEW/AFEW等[4],其特点是以专门采集的正面的、清晰的面部照片为主体,如图1所示。
但是现实场景中,由于拍摄视角问题,很难获得正面照片,很多都是侧面的、扭曲或有遮挡的劣质图像。例如,图2展示几张影视作品中的表情照片,受制于电影场景设计和镜头限制,很难获得正面照片。针对现实场景中的情感计算,仅仅依赖单张的面部表情照片,需要在计算模型和算法方面取得较大的突破,难度较大。目前已经初步建立了相关数据集,例如Aff-Wild和EMOTIC[7],相关的研究工作开始启动。
一个表情动作的发生,是在一个时间段内完成的,基于视频录像中的连续图像序列,利用表情动作的时间连续性[8~9],临近时间段的图像信息可以弥补劣质图像带来的问题,是解决表情识别一条重要的技术路线。本文尝试将表情图像序列中多张图像对齐后,叠加合成复合图像,作为神经网络模型的输入,实现表情识别,主要贡献如下:

图2 现实场景下面部表情照片示例
1)使用表情公开数据集The MUG Facial Expression Database,经过数据清洗后,提取表情强度较大的高质量时序帧图像,对每张图像进行仿射变换,并将图像进行叠加,得到临近时刻的复合图像。
2)构建卷积神经网络模型,对复合图像分类,实现表情识别,并且通过实验验证算法的有效性。
2 相关工作
基于面部动作单元(Action Unit,AU)的情感计算思想是将与表情紧密相关的面部肌肉动作命名为动作单元,并发现动作单元组合与情感之间的关联关系,实现情感识别。FACS从面部图像中抽取重要的27个面部AU和20个眼部和头部位置作为情感计算基础,并制定了分类规则库,从1978开始,Paul Eckman不定期发布FACS使用手册[11],其最新版本为2020年由牛津大学出版社发行的《What the Face Reveals》。
由于面部动作本身是在三维空间中完成,从计算机视觉的角度,从二维图像自动识别动作单元依然存在很多的困难[12]。为了解决此问题,形成如下三条技术路线。
1)基于面部的AU计算。以表情动作时间连续性为前提,利用时序图像,识别AU。其研究方法细分为基于AU特征点的方法[12~13]、基于面部图像的方法[14~15]和基于动态纹理[10,16]的方法。
2)基于多模态数据的识别方法:基于语音[17~18]、肢体[19]、心跳[20],以及对话[21~23]的关联信息,或者多模态数据融合的方法。
3)重构三维图像的方法,通过多角度照片重构面部三维图像[24]。
在表情分类研究方面,前期主要采用方法包括SVM[25]和HMM[13],近期开始尝试使用深度卷积神经网络模型,例如CNN[26]和LSTM[27]等等。
基于图像序列的识别方法包括多帧图像融合[28~29]、学习不同强度表情、深度时空网络等,Zhao[30]等提出一种基于峰值引导的神经网络PPDN,通过建立峰值与非峰值表情之间的映射关系来解决微小表情难以识别的问题。在此基础上,Yu[31]等提出深度级联峰值引导网络DCPN,采用更深的网络来提取特征。深度时空网络适合具有空间关系和时间规律的数据,例如RNN、LSTM等。Kahou[32]等利用CNN提取视频序列中每帧图像的高层语义特征,然后使用RNN提取这些特征的时序依赖关系,进而实现动态人脸表情识别。
3 模型与算法设计
3.1 问题定义
本文中,使用YP=F(ZP,W)来表示表情计算问题,其中ZP是表情序列中的第P个表情,W表示训练模型中的相关参数,输入的表情序列在参数W的模型计算后,得到表情的预测标签YP。
3.2 图像预处理
face_recognition是一个基于C++开源库dlib中的深度学习模型以及python开发的人脸识别库。使用face_recognition的标定脸部特征点模块标定表情序列图像首张表情图像的脸部特征点,从视频(图像序列)中检测出人脸,并标定68个脸部特征点,对特征点进行旋转平移的仿射变换。人脸特征点对应的脸部器官如表1所示。将特征点移动到图像中央,利用线性插值算法连接相邻的脸部特征点生成脸部轮廓特征图,如式(1)所示。以首张表情图像的脸部轮廓特征图为基准,对后续所有脸部特征点进行归一化操作后连接生成脸部轮廓特征图。最后将整个表情序列图像的脸部轮廓特征图叠加在一张空白的同尺寸图像中,生成表情特征图。
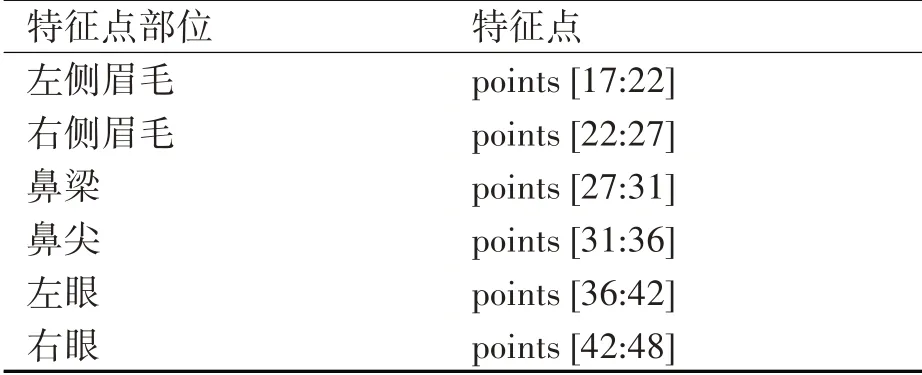
表1 人脸特征点对应表(face_recognition库提供)
算法1 生成表情特征图算法
ALGORITHM1:Generate expression feature graph
Input:expression_file_path
Output:feature_picture
feature_picture=image.new
For每种表情素材
For每个表情序列
For每张图像
提取每张图像的特征点且归一化处理。
将图像平移到图像中央。
将特征点连成线画在空白图像上并叠加。
End
feature.save(path)
End
End
这是整个算法的核心,也是本文创新点,特征提取过程使用了一个合理高效的方式生成了对于机器来说可识别的表情符号,如图3所示。
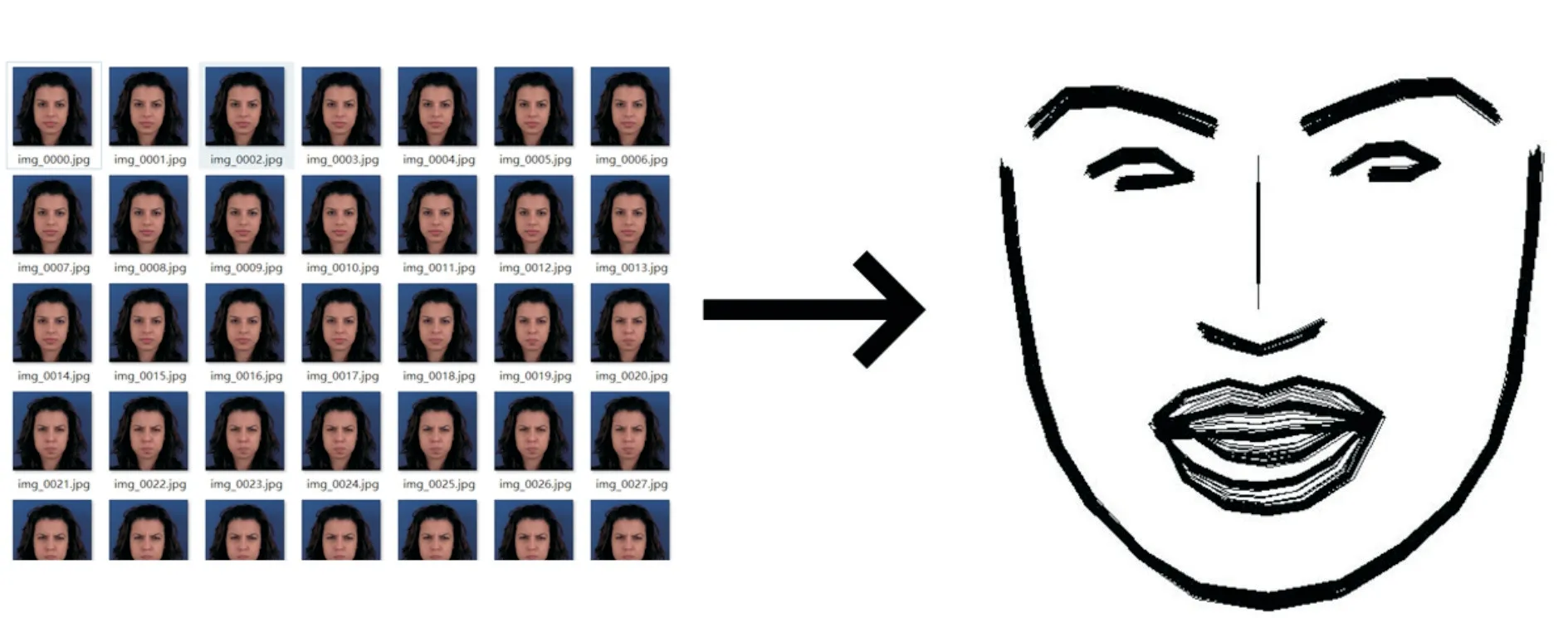
图3 生成表情特征图
仿射变换是整个特征提取过程中最关键的一步。表情计算依赖于人脸检测功能的稳定性和标定脸部特征点的准确性。基于图像序列的表情计算需要处理大批量的脸部图像。本文使用的数据集约有972*80=77760张图像,随着识别图像数量的提升,标定脸部特征点功能产生的错误也越来越多。并且志愿者们的头部也会有些微的偏转与变化,因此使用仿射变换来降低这两个因素带来的影响,在可接受范围内校准了表情序列图像的脸部特征点,舍弃了超出可接受范围内异常的脸部特征点。
算法2 仿射变换算法
ALGORITHM2:Affine transformation
Input:face_landmarks,cordinate_origin,rotate_radian
Output:new_face_landmarks
For每个特征点
减去鼻梁底部的横坐标与纵坐标得到新坐标
(x,y)=each.(x,y)-cordinate_origin.(x,y)
计算旋转角
radian=math.atan(distance.x/y)
distance=math.sqrt(x*x,y*y)
new_y=distance*math.cos(radian-rotate_radian)
new_x=distance*math.sin(radian-rotate_radian)
连接变换后的特征点并平移到图像中心
new_face_landmarks.appen(each)End
设首张脸部图像鼻梁上下距离为L,后续脸部图像的鼻梁上下距离为L',计算缩放比k=L/L'。因为人类的鼻梁不会随着表情的变化而变化,所以以鼻梁底部为坐标原点建立新坐标系。第一步在原有的坐标系下将所有特征点减去鼻梁底部的横坐标与纵坐标再乘以缩放比k,得到新坐标系下的特征点坐标。第二步是计算旋转角,按照表1提供的特征点位置,取鼻梁顶点(x27),y27与坐标原点(x31),y31。以顺时针为正,逆时针为负,计算旋转角q。坐标示意图如图4所示。
第三步利用平面距离公式计算每个特征坐标原点的距离rj。
第四步计算每个特征点与x轴正向的夹角b。

第五步根据旋转角q、距离rj和夹角b计算仿射变换后的特征点坐标M',j为特征点序号。再连接变换后的脸部特征点,平移到图像中心生成脸部轮廓特征图,如图5所示。

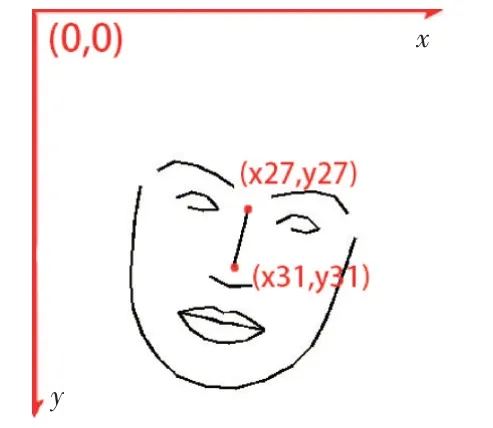
图4 特征点坐标示意图

图5 特征点仿射变换示意图
使用上述方法处理脸部表情序列图像,生成规范的脸部轮廓特征图,最终将一个表情序列的脸部轮廓特征图叠加后得到表情特征图。
3.3 神经网络结构
本文构建了专门识别脸部特征图的卷积神经网络。该网络主要分为两个部分,前端特征提取由卷积层和池化层组成,后端分类器进行预测。整体架构图如图6所示。
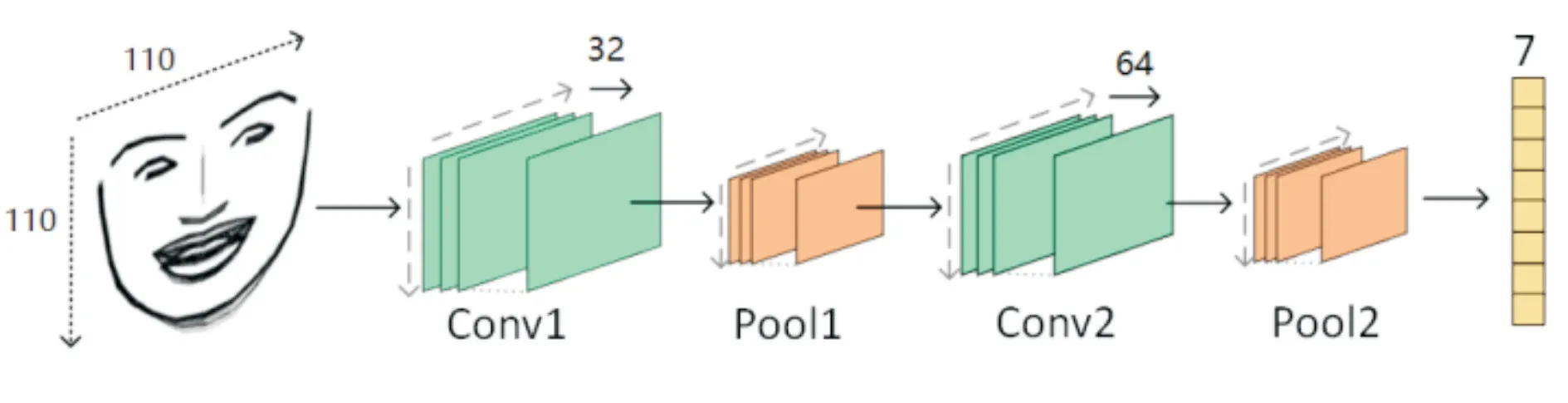
图6 ConvNet整体架构图
输入层使用单色表情特征图作为输入数据。然后使用两个3×3的卷积层和两个最大池化层,之后扁平化池化层的输出。最后使用Softmax回归分类器进行分类。在特征提取器和输出层之间,添加一个dropout层来防止过拟合。该问题是一个多分类问题,需要一个具有7个节点(对应七种表情)的输出层来预测属于这7个类中每个类的图像的概率分布。所有层都使用he权重初始化方案。
损失函数使用交叉熵作为损失指标,如式(6)所示,其中概率分布p为期望输出,概率分布q为实际输出,H(p,q)为交叉熵。

4 实验
4.1 实验环境
本实验的硬件环境如下:Windows10操作系统,16GB DDR3内存,i7-10750H CPU,NVIDIA Ge-Force RTX 2060M 6GB的GPU硬件环境。软件环境为Python3.6,TensorFlow 2.0.0版本,编译器为JetBrains PyCharm Community Edition 2020。
4.2 实验数据
本文使用face_recognition工具开发了识别模块,该模块能检测出视频中的脸部图像区域并进行人脸识别将图像区域保存到对应文件夹中。
由于表情强度较弱的低质量图像对于表情识别的贡献较少,清洗掉这些图像对结果不会有太大影响,同时使用实验室采集的标准图像也可以对模型进行验证,因此本文采用公开的表情图像数据集The MUG Facial Expression Database作为训练数据并对其进行数据清洗。该数据集由希腊亚里士多德大学的Multimedia Understanding Group创建,克服了其他数据库分辨率低,照明不均匀主题不明确等问题。数据集由20~35岁的35名女性,51名男性,共86名志愿者的面部表情图像序列组成。每个图像以jpg格式保存,896×896,大小范围为240KB~340KB。每个志愿者根据FACS手册定义的六种情绪原型,自愿选择做出相对应的情绪表达[34]。表4为通过不同方式公开发表的各个表情的数量。

表4 MUG Facial Expression Database中每种表情的数量
一个志愿者的七种表情数据压缩在一个文件夹中,文件夹根据志愿者拍摄顺序编号命名。需要以Ekman提出的六种基本表情再加上平静表情为标签对原始数据进行分类,重新进行人工标注。经过手动分类,最终获得愤怒、厌恶、害怕、开心、伤心、惊讶、平静共七类,954组素材。
虽然算法在特征提取步骤应用仿射变换降低了错误的表情特征图的数量,但是仍有部分表情特征图具有严重的偏差,例如有双下巴的男性,算法有时会错误地把双下巴区域当成脸部区域,原本的下巴区域则被当成了嘴部区域,从而生成一张部分正确,部分错误的表情特征图。
4.3 实验结果与错误分析
4.3.1 预处理与特征提取
经过预处理特征提取工作后,最终的表情特征如图7所示,可以看出不同的表情呈现出较大差异,证明预处理的工作有助于后续卷积神经网络的分类。
图7 六种基本表情特征图
4.3.2 神经网络
使用tensorflow框架构建的卷积神经网络进行100轮epoch的训练,训练过程如表3和图8所示。

表3 总体模型评价

图8 模型训练过程直方图
最终在测试集上的准确率为0.881,实验过程中的混淆矩阵如图9所示,可以看出在fear、neutral和sadness上的效果较差,误分类主要出现在anger和surprise上,分析其原因,这三个表情的特征差异不如其他四种表情显著,有一定的相似性,需要进一步改进模型来提高识别率。

图9 混淆矩阵
本文使用单张未叠加的特征图以及未进行仿射变换的特征图进行对比,前者混淆矩阵如图10所示,后者混淆矩阵如图11所示,准确率对比如表4所示。通过对比可以看出,使用经过仿射变换并叠加的特征图作为表情计算输入的效果明显更优,这表明仿射变换和时序图像叠加是有助于表情识别的。

表4 三种方法对比
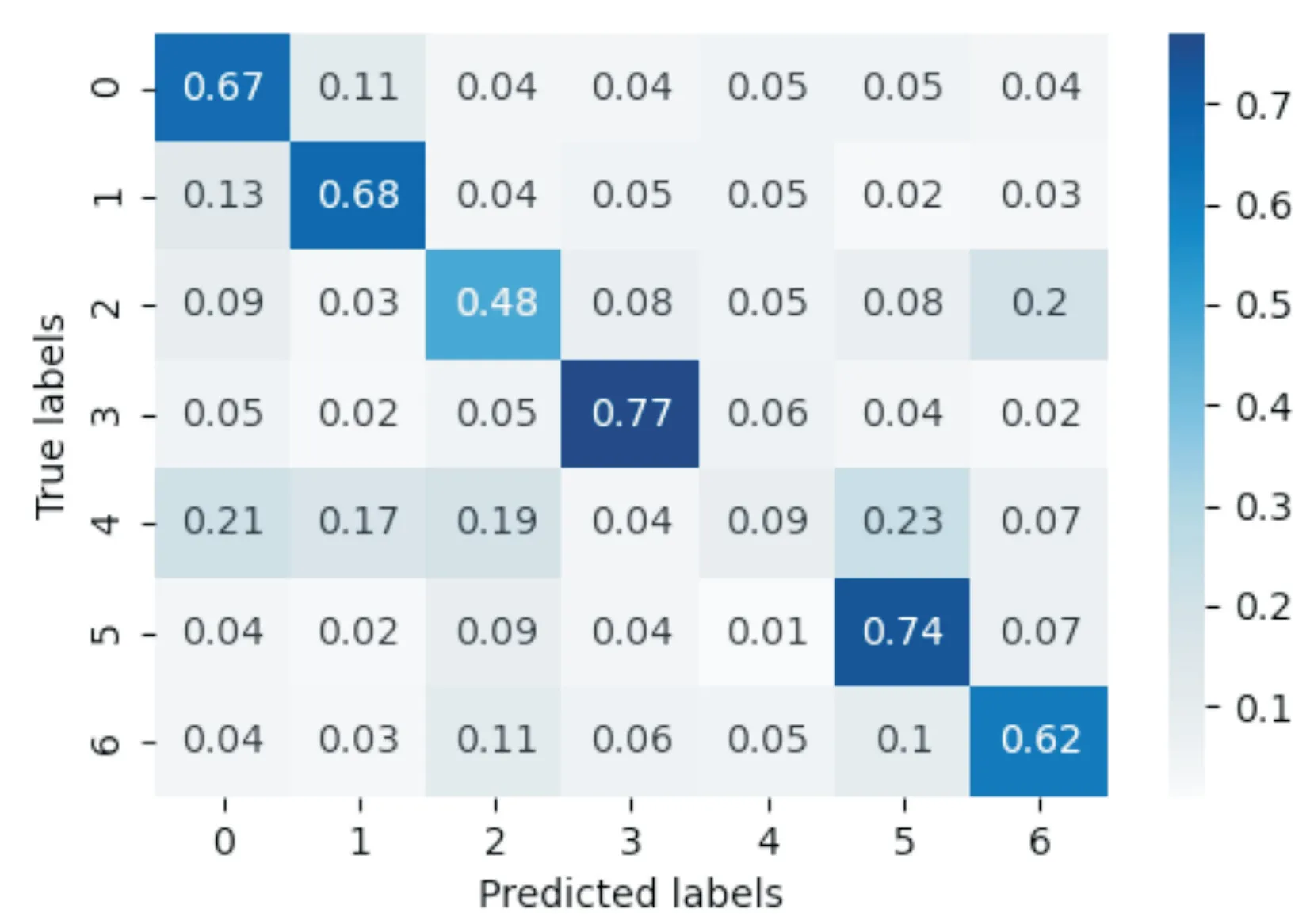
图10 未叠加特征图的混淆矩阵

图11 未进行仿射变换征图的混淆矩阵
5 结语
本文针对7种基本表情,使用人脸特征点定位算法,捕捉表情序列视频中的每一帧人脸图像的特征点,经过仿射变换和简单叠加后得到表情特征图。结合卷积神经网络进行分类识别,得到最终表情结果。实验结果表明时序图像包含了丰富的表情信息,有利于提高表情计算的准确率。
本文所使用的训练集源于实验室。实验者在拍摄基本表情视频时事先经过培训,拍摄环境有着严格的光照控制。而在真实的课堂环境下,很难完整且清晰地捕捉到每位学习者的脸部表情变化。因此下一步的工作需要在教室环境下,利用有限的摄像头资源捕捉到足够清晰且是正脸的表情素材,以应用于更复杂的真实课堂环境中。
猜你喜欢
养生月刊(2022年8期)2022-11-25
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
电子制作(2019年24期)2019-02-23
黄河黄土黄种人(2017年4期)2017-04-26
意林(2011年10期)2011-05-14
