
基于Tesseract文字识别的预处理研究
2021-01-19 02:24:14马明栋
计算机技术与发展 2021年1期
章 安,马明栋
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003; 2.南京邮电大学 地理与生物信息学院,江苏 南京 210003)
0 引 言
1929年德国科学家Tausheck提出了OCR的概念[1],通过对图像像素点的分割,与字符库对照,获取最近似的计算机文字。最初的OCR技术目的在于信息化处理大量的印刷品,例如报刊杂志、文件资料和其他文字材料,进而开始了西文OCR技术的研究,以便代替人工键盘输入[2]。随着时间的推移,科技公司的不懈努力以及计算机技术的飞速发展,西文OCR技术现已广泛应用于各个领域,实现了“电子化”信息处理。
国内对于印刷体汉字识别的研究从20世纪70年代末起步[3],至今己有近四十年的发展历史。从最开始对数字、英文、符号识别的研究,到对汉字识别进行了探索,80年代后期,大量研究人员钻研其中,汉字识别技术也趋于实用化[4]。如今市场上的OCR识别平台层出不穷,最常见的百度、华为和腾讯等公司都提供了文字识别云平台,在所需的环境之下,调用其提供的在线接口,便可以实现文字的识别。
Tesseract是一个开源OCR库,源码存在于github上。基于其开源的特性,可以添加接口,丰富其功能。支持Tesseract的Leptonica组件有着优越的图像分析性能,保证了文字识别的精度。除此之外,Tesseract还具有多平台的可移植性,拥有庞大的Unicode字符识别库。
识别是智能的基础[5],目前互联网技术迅速发展,在AI(artificial intelligence,人工智能)技术的需求之下,OCR技术成为了不可忽略的部分,通过文字的识别,提高了各行各业的生产效率。
1 文字识别流程
文字识别通常有两种形式,手写体与印刷体[6]。对于印刷体而言,研究结果相对成熟,而手写体更为复杂,该文的讨论范围仅在于印刷体的文字识别。
文字识别通常包括以下流程:
(1)预处理:预处理操作在图像识别之前。已采集的图像质量受多方面因素影响,图像的亮暗、印刷体质量、污点或阴影都是干扰识别的因素。预处理主要是对图像进行处理,将图像灰度化以及二值化,进而对图像的倾斜、边框等问题进行处理,使得文字规范,图像平滑,从而有利于接下来的处理操作[7]。
(2)版面分析:版面分析主要处理文本图像的不同部分,分析图像中不同类型文本,例如标题或是正文,插图或是表格,从而获取文章逻辑结构,包括各区域的逻辑属性、文章的层次关系和阅读顺序。最后根据版面分析和文字的结果,进行版面重构。
(3)图像切分:识别是单个文字的识别,因而必须对图像进行行列切分。印刷体文字图像行列间距、字间距大致相等,简化了处理方法。
(4)特征提取与模型训练:通过深度学习框架,对文字识别进行特征提取和模型训练,提高了识别的有效性和可靠性。
(5)识别后处理:识别后处理通常包括版面的重构和识别的校正,对原图像版面的恢复以及不同语言模型的校正[8]。
通过以上流程,计算机通过输入的图像,分析并识别文字,同时保存于硬件中。识别流程不包括图像的采集、最终图像的输出,这类工作由其他硬件实现。
2 图像预处理
预处理是文字识别的重要一环,预处理对图像质量的提升起到了关键作用。预处理通常包括灰度化、二值化、倾斜校正和噪声消除[9],该文实现了以下几个预处理方法,为Tesseract文字识别做好准备。
2.1 图像缩放
Tesseract处理图像的DPI(dots per inch,每英寸点像素数)默认为300 DPI,因而对于DPI不足的图片,需要进行缩放处理。常用的缩放算法有最近邻算法(最近邻插值)、双线性插值算法以及更为复杂的三次插值算法[10],三种算法的精度不一。基于文字识别的精度要求,该文实现了双线性插值图像缩放算法。
在离散数学中,插值是指在离散数据的基础上补差连续函数[11],使得该连续曲线通过全部给定的离散数据点,关键在于恢复曲线的连续与平滑。与之类似,图像基本构成是有限像素集,在图像缩放的过程中,需要对图像进行像素的插入(放大)或是叠加(缩小)。
图像缩放的过程中,原图像与输出图像具有一定的映射关系:
Y(x'+u,y'+v)=X(x,y)=X(h1(x,y),h2(x,y))
(1)
其中,X(x,y)表示输入图像,Y(x'+u,y'+v)表示输出图像,h1和h2表示映射函数。转换之后可能出现小数的情况,令x'和y'作为坐标的整数部分,u和v作为小数部分。
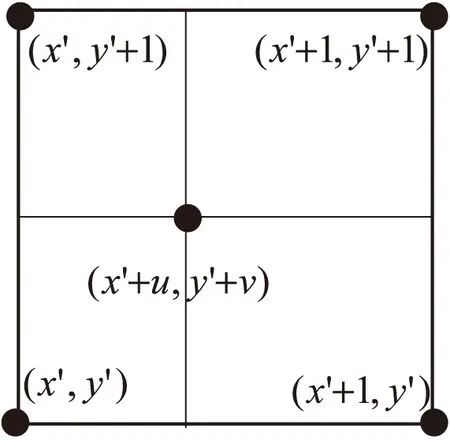
图1 双线性插值示意
如图1所示,取转换点四个领域整数位置点(x',y'),(x',y'+1),(x'+1,y'),(x'+1,y'+1)。设RGB满足函数f(x,y),则转换之后的点坐标中的RGB值为:
f(x,y)=f(x'+u,y'+v)
(2)
f(x'+u,y'+v)=f(x,y)*(1-u)*(1-v)+
f(x',y'+1)*(1-u)*v+
f(x'+1,y)*u*(1-v)+
f(x'+1,y'+1)*u*v
(3)
式(3)类比于一维坐标系下的长度比值关系,在二维坐标系下,是富含规律的面积比值关系。即所求点的RGB等于:
f(x,y)=∑Ri*S对角
(4)
其中,Ri表示领域点的RGB中的某一项,S对角表示对角的矩形面积值。
示例代码:
for (int k=0;k<3;k++)
{
change[x+k]=image[o_x+k]*(1-a_x)*(1-a_y)+
//对应f(x,y)*(1-u)*(1-v)
image[o_b+k]*a_x*(1-a_y)+
/对应/f(x',y'+1)*(1-u)*v
image[o_c+k]* a_y*(1 - a_x) +
//对应f(x'+1,y)*u*(1-v)
image[o_d+k]* a_y*a_x;
//对应f(x'+1,y'+1)*u*v
}
2.2 二值化
二值化的过程形如二进制中的01变化,图像的二值化就是将图像的像素点的灰度值设置成0或255。首要工作是将图像灰度化,灰度化是将原图像各像素R、G、B三个值按照不同的权值,将加权和均赋值给目标图像的RGB值。二值化的算法的重点是获取像素点灰度的阈值,高于阈值的像素点灰度设置为255,反之设置为0。二值化的算法众多,常用的如利用聚类思想、根据灰度特征划分前景后景的Otsu算法,以及基于像素点为中心确定利用范围像素确定像素阈值的Bernsen算法[12]。
由于人眼对RGB三色的敏感度不同[13],因而灰度化时权值必然不同,该文利用心理学公式(5)中的权值实现灰度化,该公式适用于sRGB存储空间的图像。
Gray=R*0.299+G*0.587+B*0.114
(5)
实现方法只需遍历所有像素点,对其RGB求加权和,将新值更新到源像素点中。
对于二值化过程,该文使用Otsu算法,Otsu算法又称为“大津法”、最大类间方差法[14]。该算法的主要思想是根据图像的灰度特征将图像分为前景与背景两部分,而前景就是所求的目标图像[15],使用方差这一统计量,反映前后景灰度差距,其中存在概率分布,实行概率加权,最终遍历所有可能的灰度值,方差最大处为灰度阈值。
具体流程如下:
设图像灰度范围为[0,L-1],阈值M∈[0,L-1]。
(1)分别计算像素灰度值在[0,M]与(M,L-1]出现的概率P1和P2,其中:
P1+P2=1
(6)
(2)分别计算像素在[0,M]和(M,L-1]的平均值μ1和μ2及总体灰度平均值μ。
(3)灰度类间方差函数为:
σ2=P1(μ1-μ)2+P2(μ2-μ)2
(7)
由概率以及均值关系可推出最终表达式:
σ2=P1P2(μ1μ2)2
(8)
(4)遍历所有灰度阈值M,方差最大时的M即为最佳阈值。
示例为部分代码:
int OtsuAlgThreshold(const Mat){
int M;//阈值
for(int i=0;i < 255;i++){
double p1=0,u1=0,p2=0,u2=0;
double sum1=0,sum2=0;//像素点总数
double gray_sum1=0,gray_sum2=0;//灰度值总数
for(int j=0;j<=i;j++){
sum2+=gram[j];
gray_num2+= j*gram[j];
sum1+= gram[i+j];
gray_num1+=(i +j)*gram[i+j];
}
u2=gray_sum2/sum2;
p2=sum2/total;
u1=gray_sum1/sum1;
p1=sum1/total;
//类间方差计算
double Sq=p1*p2*(u1-u2)*(u1-u2);
if(SqMax < sq){
SqMax=sq;//更新最大方差值
M=i;
}
}
return M;//返回阈值M
}
以上获取最佳方差的灰度值之后,便可通过遍历像素点进行灰度值调整。
2.3 边框与偏移
输入的图像由于采集设备的原因可能存在意想不到的边框,或是图像角度发生了偏移,因而会影响接下来的版面分析与行列切分工作,最终影响识别效果。此部分涉及到两个部分,一是发生偏移的角度,二是边框的选取。该文参考OpenCV库中的函数,实现了一种方法,方法的重点在于遍历查找最小外接矩形,旋转之后进行切割,从而获取最终图像。方法流程如下:
(1)获取图像最小外接矩形。
(2)获取图像偏移角度,同时进行旋转操作。
(3)对图像进行轮廓检测,循环筛选。
(4)切边,获取最终图像。
该思路之前需要对图像进行灰度化和二值化处理,以便于提高检测的精度。
3 文字识别
此前的图像预处理是为了文字识别作铺垫。预处理过程使得图像质量得到一定的改善,其DPI和对比度得到显著提升,文字的方向和边框也得到校正,从而改善了识别的准确性。文中的汉字识别,依赖于Tesseract框架,识别出Unicode字符。
此测试环境需要的配置如表1所示。

表1 配置环境与说明
预先需要使用CMake编译工具将Libtiff、Leptonica编译,在Tesseract中添加动态链接库(后缀为.dll)文件之后方可使用。
识别代码如下:
char *outPut;
tesseract::TessBaseAPI *ocr=new tesseract::TessBaseAPI();
//初始化ocr识别模式
if(ocr->Init(NULL, "eng")) {
cerr<<"Initialize Failed”< exit(1);//退出 } //传入参数 Pix *image=pixRead(Imag_name); ocr->SetImage(image); //输出结果 outPut=ocr->GetUTF8Text(); cout<
猜你喜欢
美与时代·美术学刊(2020年7期)2020-10-13 12:24:04校园英语·月末(2020年4期)2020-06-08 12:54:41电脑知识与技术(2018年35期)2018-02-27 13:29:44自动化学报(2017年11期)2017-04-04 02:52:44中学生天地(C版)(2016年4期)2016-09-16 03:19:02中国经济周刊(2016年34期)2016-09-02 12:13:26新闻传播(2016年3期)2016-07-12 12:55:35新闻前哨(2015年2期)2015-03-11 19:29:25电视技术(2014年11期)2014-12-02 02:43:28小猕猴智力画刊(2014年5期)2014-04-29 10:03:23
