
图像匹配的物体空间关系推理表达
2021-01-18 01:01王玮琦
测绘学报 2021年1期
李 钦,游 雄,李 科,王玮琦
信息工程大学地理空间信息学院,河南 郑州 450001
图像匹配是众多视觉任务的基础环节,如即时定位与地图构建(simultaneous localization and mapping,SLAM)中的闭环检测[1-2]、图像检索[3-4]以及视觉定位[5-6]等。图像匹配的关键在于判断图像中是否包含相同的物体,由于现实世界场景的复杂性,同一物体在不同图像中会呈现不同的形态,同时不同物体在各自图像上的成像也可能会很相似,只有准确地表达图像中物体间的相互关系,才能有效地解决图像匹配问题。
特征提取与相似度计算是图像匹配的基本步骤[7],特征提取的目的是对丰富的图像信息进行抽象简化表达,进而构建用以表达图像的描述向量。常见的图像特征如SIFT[8]、SURF[9-10]和ORB[11]等,仅仅表达了特征点周围区域信息,为了构建整幅图像的最终表达,需要进一步对图像包含特征进行聚合,常见的聚合模型包括BoW(bag of words)模型[12-13]、VLAD(vector of locally aggregated descriptors)模型[14]以及FV(fisher vector)模型[15-16]等。相似度计算的实质是度量图像间的距离,在构建图像整体表达的基础上,计算图像间的特征距离,设置距离阈值判定图像是否匹配。
近年来,深度学习在各种视觉应用中取得了巨大的成功,其通过对输入图像的层层特征提取,不断挖掘隐藏在图像内部的抽象语义信息,更能表达图像的本质,因此基于深度学习构建的图像特征具有更强的表达能力。受VLAD模型[14]的启发,文献[17]训练NetVLAD模型构建影像的整体表达,首先利用一般的CNN网络模型提取影像特征,然后在网络中添加NetVLAD层构建影像的VLAD描述符,NetVLAD模型在影像匹配实践中取得了很大的成功。文献[18]采用训练好的深度卷积网络模型(AlexNet)[19]构建图像深度层次特征,通过截取网络不同输出层的特征图构建特征向量,该方法对特征的每个维度进行单独计算,特征构建效率受到很大的限制。文献[20]利用预先训练好的AlexNet模型[19]的某一输出层构建图像的整体表达,不同输出层可以生成不同的特征,相比于深度层次特征,这种方法构建的特征具有更高的效率。文献[21]采用Siamese网络[22]直接进行图像匹配,该网络将特征提取与相似度计算过程融合在一起,网络输入为两张图像,输出即为图像的匹配结果。
图像空间关系在图像匹配实践中至关重要,图像空间关系表达就是描述图像中物体在欧氏空间中的几何关系。文献[23]利用成像物体的三维点云信息概略判定物体的空间位置,进而对物体的空间关系进行描述;文献[24]根据城市场景中的道路网建立物体的空间关系,将同一道路上的物体看作是相连的,进而建立城市道路与建筑物实体的空间矢量关系;文献[7]将图像规则的划分为4×4的图像块,根据物体所处的图像块粗略地表达不同物体在图像幅面中的空间关系,由于同一物体可能会被划分到不同的图像块,因此该方法对物体空间关系的表达较为混乱;文献[25]基于Edge Boxes算法[26-27]检测图像中包含的物体目标,根据物体在图像序列中的共现性推理物体的邻近关系,即若两个物体在一张图像中共同出现,则这两个物体是邻近的。该方法在闭环检测应用中取得了较好的匹配效果,然而一张图像中的不同物体间的邻近程度是不同的,该方法仅仅根据物体的共现性无法对物体的邻近程度进行推理。
由于现实世界的复杂性以及场景拍摄的随机性,同一物体在不同图像上的成像会发生显著变化,单纯依赖图像的整体表达计算图像相似度很难准确地对图像进行匹配。图1所示为一组匹配图像对,红色方框内的区域为两张图像中相同的物体块,一方面,该物体块在两张图像中的成像形态差异很大,另一方面,红色方框之外的图像内容是不一致的,在构建图像整体表达的过程中,这些占据图像主体的不一致内容也参与了特征计算,最终使得构建的图像特征很难对图1中的图像进行匹配。
不同于传统的图像匹配方法,本文通过分析图像中物体的空间邻近关系推断图像是否匹配,如图1所示,两张图像中蓝色方框内的物体虽然是不相同的,但是它们在欧氏空间中是邻近的,这些空间邻近信息对于判断图像是否匹配至关重要,若两张图像中的物体相互邻近,表明图像的拍摄点位置也是邻近的,则图像很可能是相互匹配的。
图2所示为本文图像匹配算法流程,首先基于先验的基础图像数据推理表达图像中物体的空间邻近关系,构建场景物体空间邻近图。对于来自该场景的图像对,在物体块检测的基础上,基于构建的空间邻近图分析图像中物体的空间邻近关系,定量计算图像对的邻近程度,进而完成图像匹配任务。
1 场景物体空间邻近关系推理表达
物体空间关系表达在图像匹配实践中至关重要,同一物体在不同的图像中成像时,其成像形态会发生显著变化,但是其与邻近物体间的空间关系一般都保持稳定。另外,由于现实世界的复杂性,存在一些不同物体视觉上很相似,如统一规划建设的居民楼,风格一致的窗户,具有重复纹理的道路等,单纯地根据这些物体的成像很难对其进行区分,虽然物体自身形态很相似,但是其与周边物体的邻近关系却很容易区分。因此,相比于图像中单一物体的匹配,图像空间关系匹配具有更强的稳定性,其涉及多个物体间的相互关系,即使单一物体匹配错误,也不会影响整体的空间关系匹配。
为了表达物体空间关系,本文首先训练特征提取网络,构建物体块深度特征,匹配不同图像中的相同物体块;在此基础上,基于先验图像序列推理表达场景中不同物体的邻近关系,构建场景物体空间邻近图。
1.1 基于深度特征的相同物体块匹配
物体块特征提取是推理表达物体空间关系的基础,构建物体块特征,准确地对不同图像上的相同物体块进行匹配是构建场景物体空间邻近图的关键。
物体块特征旨在表达物体不变的本质信息,物体在不同的图像上会呈现不同的形态,而用于表达物体块的特征应尽可能保持稳定,以实现对相同物体块的准确匹配。由于拍摄角度、光照、尺度等因素的影响,同一物体在不同图像中的成像颜色、纹理、形状会有显著的不同,因此,传统的颜色、纹理、形状特征难以维持不同成像中物体信息的稳定性。然而无论何种成像,物体自身语义信息始终不变,而深度学习技术在图像语义识别应用中已经取得了巨大成功,因此,本文探索利用深度学习方法构建物体块深度特征,该特征旨在表达隐藏在物体内部的本质语义信息,其不因物体在图像中呈现形态的变化而变化,能够有效匹配不同图像中的相同物体块。
1.1.1 物体块深度特征提取
本文基于对比机制构建物体块特征提取网络,网络结构如图3所示,网络包含两个完全一致,权值共享的通道,每个通道为包含7个卷积层,2个全连接层的深度卷积网络。网络训练过程中,同时输入两组物体块,分别通过网络的两个通道,生成各自特征。训练标签为两组物体块的匹配真值,若两张物体块包含相同的物体,则标签为1,否则,标签为-1。
特征提取网络中每个通道的网络参数如表1所示,其中T代表非线性操作,本文利用反正切函数(tanh)对各卷积输出进行处理,将卷积输出值限缩至[-1,1],P代表池化操作,采样步长为2。通过对输入物体块的层层表达,挖掘隐藏在物体块内部的抽象语义信息,构建物体块深度语义特征。另外,本文对网络输出的特征向量进行归一化处理(l2_norm),使得最终得到的深度特征模长为1。
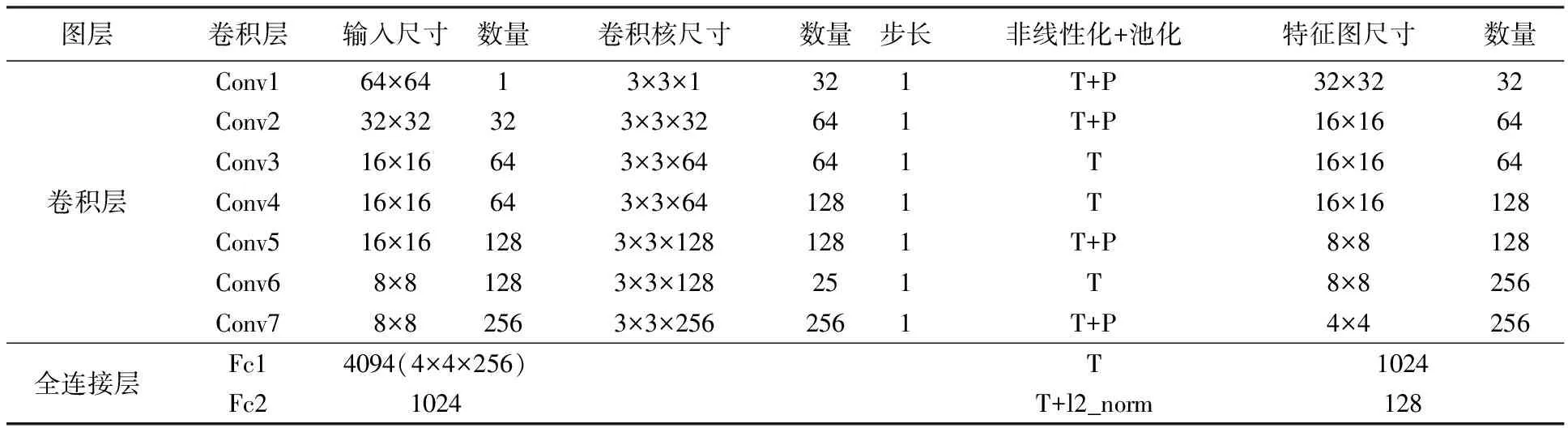
表1 特征提取网络中的各层参数(一个通道)
物体块特征提取的目的是匹配不同图像中的相同的物体块,区分不同的物体块,基于此,网络训练的目标是:对于包含相同物体的样本(正样本),使其特征距离尽可能的小,对于包含不同物体的样本(负样本),使其特征距离尽可能的大。本文结合匹配标签,对两个通道的特征输出进行对比构建误差函数。另外,本文采用特征向量间的余弦距离度量物体块相似度,由于输出的深度特征模长为1,特征向量点乘即为物体块相似度。结合网络训练标签(正样本的标签为1,负样本的标签为-1),定义网络训练误差函数如式(1)所示
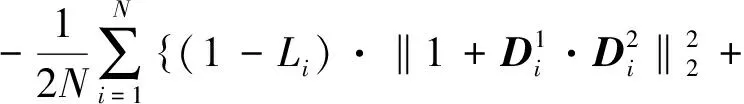
(1)
式中,D1,D2为两个通道的特征输出;D1·D2即为物体块间相似度;L为训练标签,N为训练过程中每个批次的样本数量。通过最小化误差函数,使得相同物体块的相似度趋于1,不同物体块的相似度趋于-1。
本文采用多视角立体数据集(multi-view stereo dataset,MVS)[28]训练特征提取网络,选取60万组样本进行训练(正负样本各30万组),所有训练数据按照每批次600组样本输入网络,所有数据遍历51次,采用随机梯度下降法(stochastic gradient descent,SGD)对网络进行优化,选取最优模型保存。另外,在深度特征提取实践中,仅利用网络模型的一个通道即可,模型输入为固定尺寸(64×64)的灰度图像块,输出即为模长为1的深度特征。

图1 匹配图像对及其部分物体块Fig.1 Matched image pair and object patches within images
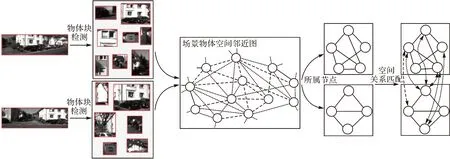
图2 本文图像匹配算法流程Fig.2 Process of the proposed image matching method

图3 特征提取网络结构Fig.3 Architecture of the feature extraction network
图4所示为基于训练好的模型计算的2000组测试样本相似度与样本初始相似度对比图,其中红点代表正样本,蓝点代表负样本,所选的测试样本不包含在训练数据中,且正负样本各1000组。图4(a)中训练前正负样本的初始相似度数值没有明显的区分,而图4(b)中正样本相似度数值明显高于负样本,表明本文基于对比机制的训练过程使得正样本的特征距离变小(相似度数值较大),而负样本的特征距离变大(相似度数值较小),正负样本具有明显的区分,训练结果达到了预期的效果。
1.1.2 相同物体块匹配
在物体块深度特征提取的基础上,匹配两张图像中的相同物体块。对于图像对中的每一张图像,本文基于Edge Boxes算法[26-27]检测图像中包含的物体块(https:∥github.com/samarth-robo/edges),该算法通过对图像进行边缘检测得到图像中物体的边缘信息;通过对边缘点进行多次聚合,将同一物体的轮廓边缘汇集到同一边缘组中,最终根据各边缘组的外包围盒确定各物体在图像中的成像区域。本文物体块检测方法是一种纯几何的方法,该方法不受物体类别的限制,凡是在成像上具有显著边缘纹理结构的目标均能被检测为物体块。
调整各物体块尺寸至64×64,利用训练好的特征提取网络构建各物体块深度特征,基于相互匹配机制确定两张图像中的相同物体块,具体为:

(2) 定义S中的第i行元素集合为:Ri={sij,j=1,2,…,n},第j列元素集合为:Cj={sij,i=1,2,…,m},对于S中的任意一个元素spq,若满足式(2)、式(3)、式(4),则对应物体块(第1张图像上的第p个物体块与第2张图像上的第q个物体块)相互匹配
arccos(spq)<π/6
(2)
spq=max(Cq)
(3)
spq=max(Rp)
(4)
在物体块深度特征提取的基础上,匹配两张图像中的相同物体块,若两张图像中包含相同的物体块,即可判定图像匹配。然而,在图像匹配实践中,不同图像中的相同物体很难同时被检测为物体块,单纯依赖匹配相同的物体块进行整幅图像的匹配存在很大的随机性,因此,必须构建各物体间的空间关系,才能稳定准确地对包含相同物体的图像进行匹配。
1.2 场景物体空间邻近图构建
在物体块深度特征提取的基础上,基于已有的先验图像序列构建场景物体的空间邻近图,根据各物体在先验图像上的分布,推理分析场景中不同物体的空间邻近关系,推理依据包括:
(1) 若两个物体在同一张图像上出现,表明其在欧氏空间中是邻近的。
(2) 两个物体在同一张图像上出现的次数越多,其在空间中越邻近。
由于先验图像数据包含精确的位置信息,且图像质量高,内容丰富,因此基于该图像序列构建的场景物体空间邻近图可以准确全面地表达场景中物体间的空间邻近信息,定义场景物体空间邻近图如式(5)所示
G={N,E,P,Ι}
(5)
式中,I代表用于构建场景物体空间邻近图的先验图像序列,其中的每帧图像都具有拍摄点位姿信息,且每帧图像包含若干物体块,来自同一帧的各物体块间相互邻近;P代表在各帧图像中检测到的物体块集合,基于特征提取网络构建各物体块深度特征,每个物体块来自特定的图像帧,属于某个特定的节点;N代表空间邻近图中的节点集合,每一个节点对应场景空间中唯一的物体,由于同一物体会出现在不同的图像上,因此,每一个节点即为不同图像中的同一物体块集合,如图5所示,红色方框内的图像块Pi、Pj、Pk包含相同的物体,它们属于同一个节点Nr,表示为:(Pi,Pj,Pk)∈Nr;E代表不同节点之间的连接权值集合,两个节点间的连接权值表达了相应物体间的空间邻近程度,若两个物体在先验图像序列中同时出现的次数为a,表示为:E(Ni,Nj)=a,其中,Ni、Nj分别为两个物体的所属节点,节点间的连接权值越高,表明相应物体在空间中越邻近。
本文基于先验的基础地理实景序列构建场景物体空间邻近图,图6所示为空间邻近图构建示意图,基于第1帧图像对空间邻近图进行初始化,基于后续图像不断更新空间邻近图。图6中圆圈代表空间物体的节点,节点间连线上的数字为其连接权值,表示两端节点对应物体在同一图像上共同出现的次数,通过统计各物体在先验图像上的分布,确定物体间的邻近关系。
构建场景物体空间邻近图的具体步骤如下:
1.2.1 空间邻近图初始化

1.2.2 空间邻近图更新

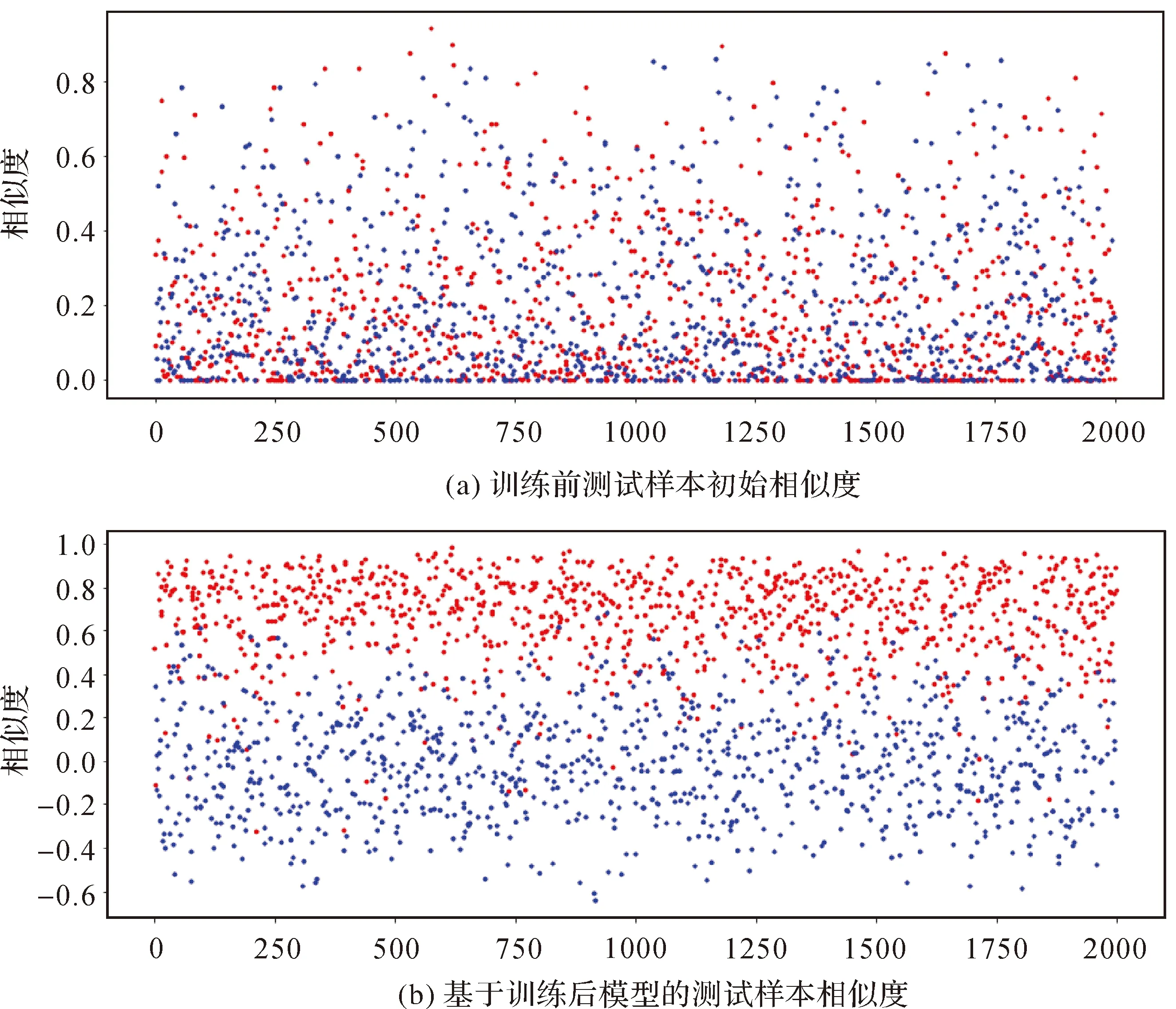
图4 基于训练后模型的测试样本相似度与样本初始相似度对比Fig.4 Initial patch similarities and well-trained model-based patch similarities

图5 同一物体出现在不同图像示意Fig.5 Consistent object patches in different images
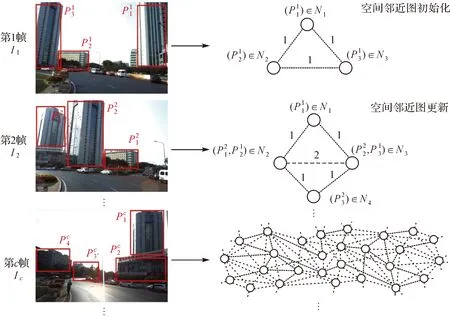
图6 空间邻近图构建示意Fig.6 Process of building the spatial adjacency grapy


在Candi_N中搜索Ic中每个物体块的所属节点,并将物体块加入其所属节点,同时将该所属节点加入待更新节点集T_N。若物体块不属于Candi_N中任何节点,则构建新节点,将该物体块加入新节点,同时将该新节点加入新增节点集合New_N与待更新节点集T_N。对于T_N中的任意两个节点:Ni,Nj,对其连接权值进行更新,具体为:
(1) 若Ni或者Nj也属于New_N,则E(Ni,Nj)=1。
(2) 若Ni,Nj均为场景节点集N中已经存在的节点,判断:Ni,Nj是否已经存在连接权值,若存在,则E(Ni,Nj)=E(Ni,Nj)+1;若不存在,则E(Ni,Nj)=1。
(3) 对T_N中节点之间的连接权值进行更新之后,将New_N中的新增节点加入N,将T_N置空,同时将Ic加入I。
对于后续的每一帧图像,重复空间邻近图更新步骤,直至所有先验图像处理完毕,进而构建场景物体空间邻近图。空间邻近图汇总了场景中出现的所有物体,并且定量地表达了不同物体间的邻近程度。图7所示为空间邻近图中部分节点包含的物体块示意图,物体块上的数字为该物体块所在的图像编号,图7中不同图像上的相同物体块被聚合在同一节点中。
2 图像空间关系匹配
在场景物体空间邻近图构建的基础上,对于来自该场景的一组图像对,首先在空间邻近图中搜索图像中物体的所属节点,根据节点间的连接权值确定图像中物体间的邻近关系。两张图像间的空间关系可以通过图像中物体的邻近关系表达,通过定量计算图像空间邻近度完成图像空间关系匹配。
2.1 物体块所属节点判定
场景物体空间邻近图表达了场景中各物体的空间邻近关系,对于一幅来自该场景的测试图像It,其包含若干物体块,在节点集N中搜索每个物体块的所属节点,具体为:


(5) 重复步骤(2)、(3)、(4),在N中搜索It中所有物体块的所属节点,构成所属节点集合Nt。对于Nt中的节点,其存在自身约束:由于物体同时出现在It上,各物体在空间中是相互邻近的,因此Nt中各节点间应该是相互连接的,对于Nt中与其他节点连接权值为0的节点,属于错误的所属节点,对其进行剔除。图8所示为基于自身约束的错误所属节点剔除示意图,图中圆圈代表空间邻近图中的节点,节点之间的连线代表其邻近关系,线段粗细代表连接权值的大小,红色圆圈标识的节点为It中所有物体块的所属节点集Nt,由于Nt中节点之间应该具有连接权值,然而N5与Nt中其他节点均不存在连接关系(连接权值为0),可以断定相应物体块的所属节点判定错误,因此,在Nt中对N5进行剔除。

图7 空间邻近图中部分节点包含的物体块Fig.7 Object patches contained in partial nodes of spatial adjacency graph
基于自身约束的错误所属节点剔除可以有效消除单一物体块匹配错误带来的影响,根据物体间的邻近关系,推理出与实际不符的错误匹配,从而使最终的判定结果更加可靠,增强了空间关系匹配的稳定性。

图8 基于自身约束的错误所属节点剔除Fig.8 Deleting the error belonging node based on self-restraint
2.2 图像对空间邻近度计算
本文基于已有的先验影像对未知影像中物体的空间关系进行分析。先验影像与未知影像必须来自相同的场景,这样未知影像中的物体也在先验影像中出现,根据先验影像中物体的分布情况可以分析未知影像中物体的空间关系。首先基于已有的先验影像构建物体空间邻近图,其次在空间邻近图中判定未知影像中物体的所属节点,最后根据所属节点间的连接信息分析物体间的空间邻近关系,实现未知影像的空间关系匹配。
对于两幅未知图像,分别在空间邻近图中找到图像中物体的所属节点,图像间的空间关系可以通过其包含物体间的邻近关系表达。图9所示为基于空间邻近图的不同图像空间关系表达示意图,图9(a)、(b)、(c)中方框内区域为基于Edge Boxes算法[26-27]在各自图像内检测到的物体块,图9(d)为场景物体空间邻近图,红色、绿色、蓝色圆圈分别代表图像1、图像2、图像3中物体的所属节点集,另外,图像1与图像2中存在相同的物体块,它们的所属节点都是N1。节点间的连线代表其邻近关系,线段越粗表示连接权值越高,节点越邻近。图9(d)表明图像1与图像2是相互邻近的,因为两张图像中物体的所属节点存在邻近关系(两张图像中物体所属节点的连接情况用红色虚线表示),说明两张图像中的物体在先验图像中同时出现过。对于图像3,其包含物体的所属节点与图像1、图像2均不存在连接关系,表明图像3与图像1、图像2均不邻近。
为了判断两幅图像的邻近关系,首先检测图像中各自包含的物体块,判断各物体块在N中的所属节点,组成所属节点集合为:N1、N2。所属节点间的连接权值代表了图像中物体间的邻近关系,为了定量表达整幅图像间的空间邻近程度,定义图像空间邻近度如式(6)所示
(6)
式中,m、n分别代表N1、N2中的节点数量,K值越大,两张图像包含的物体越邻近,图像的拍摄点位置也相应越邻近。
图10所示为对两张图像进行空间关系匹配的示意图,图10中的两张图像是现地采集的场景图像,它们包含部分相同的内容,是一组匹配图像对。为了对两张图像进行空间关系匹配,沿着图中道路预先拍摄序列图像作为先验图像构建物体空间关联图。在此基础上,基于Edge Boxes算法[26-27]在两张图像中检测物体块(图中红色方框区域为检测到的物体块);在空间关联图中判定各物体块的所属节点,根据所属节点间的连接权值确定物体块间的邻近信息,图中曲线上标示的数字即为两端物体所属节点间的连接权值,例如对于物体块A、B,其所属节点间的连接权值为3,表明在先验图像序列中,两个物体在3张图像中同时出现,定量计算两张图像的空间邻近度如式(7)所示
(7)
判断图像是否匹配的关键在于判断图像中是否包含相同的场景内容,两张图像拍摄点位置越邻近,其拍摄到相同场景内容的可能性越高,判定图像匹配的置信度也就越高。因此,图像空间邻近度可以作为判定图像是否匹配的依据,设置邻近度阈值,当两张图像的空间邻近度大于该阈值时,即可判定图像匹配。对于图10中的两张图像,其包含的相同内容较少,传统的通过构建图像整体表达的图像匹配方法很难对其进行准确匹配,本文通过推理表达不同物体间的空间邻近关系进行图像空间关系匹配,即使两张图像中的相同内容很少,通过计算图像空间邻近度也可以稳定准确地完成图像匹配任务。
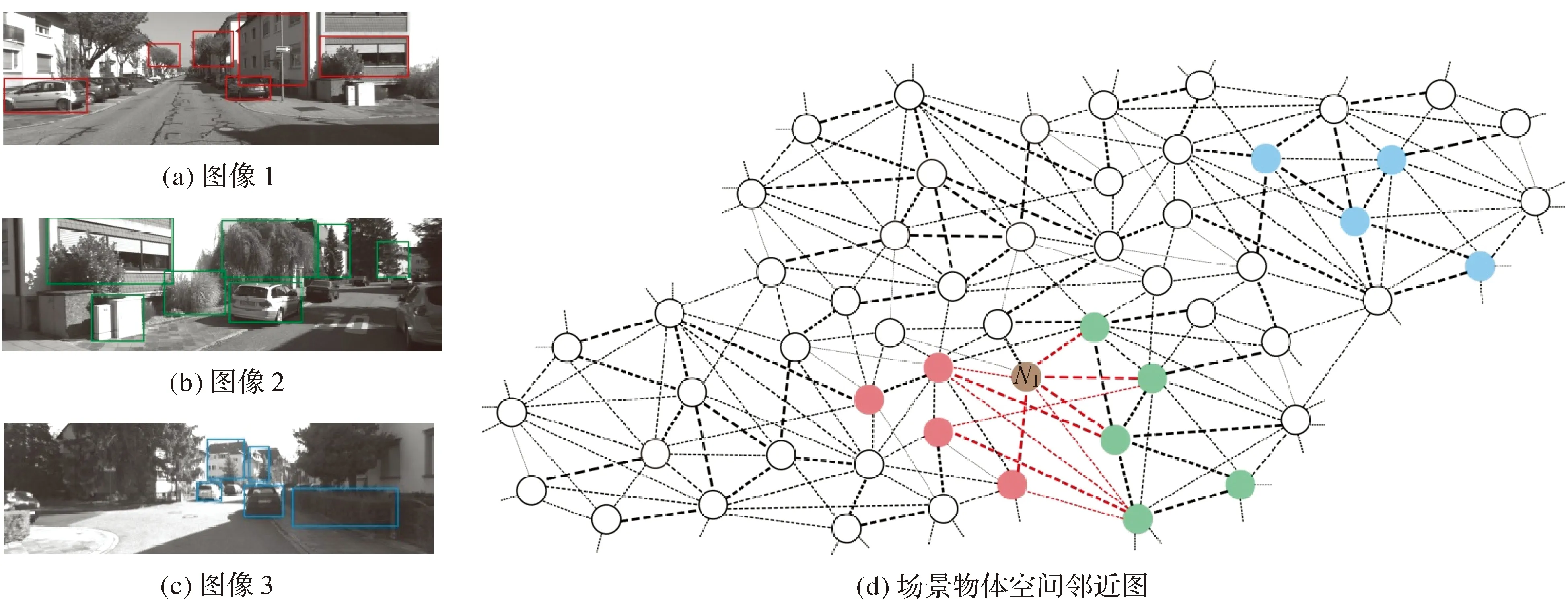
图9 图像空间关系表达Fig.9 Spatial relation matching
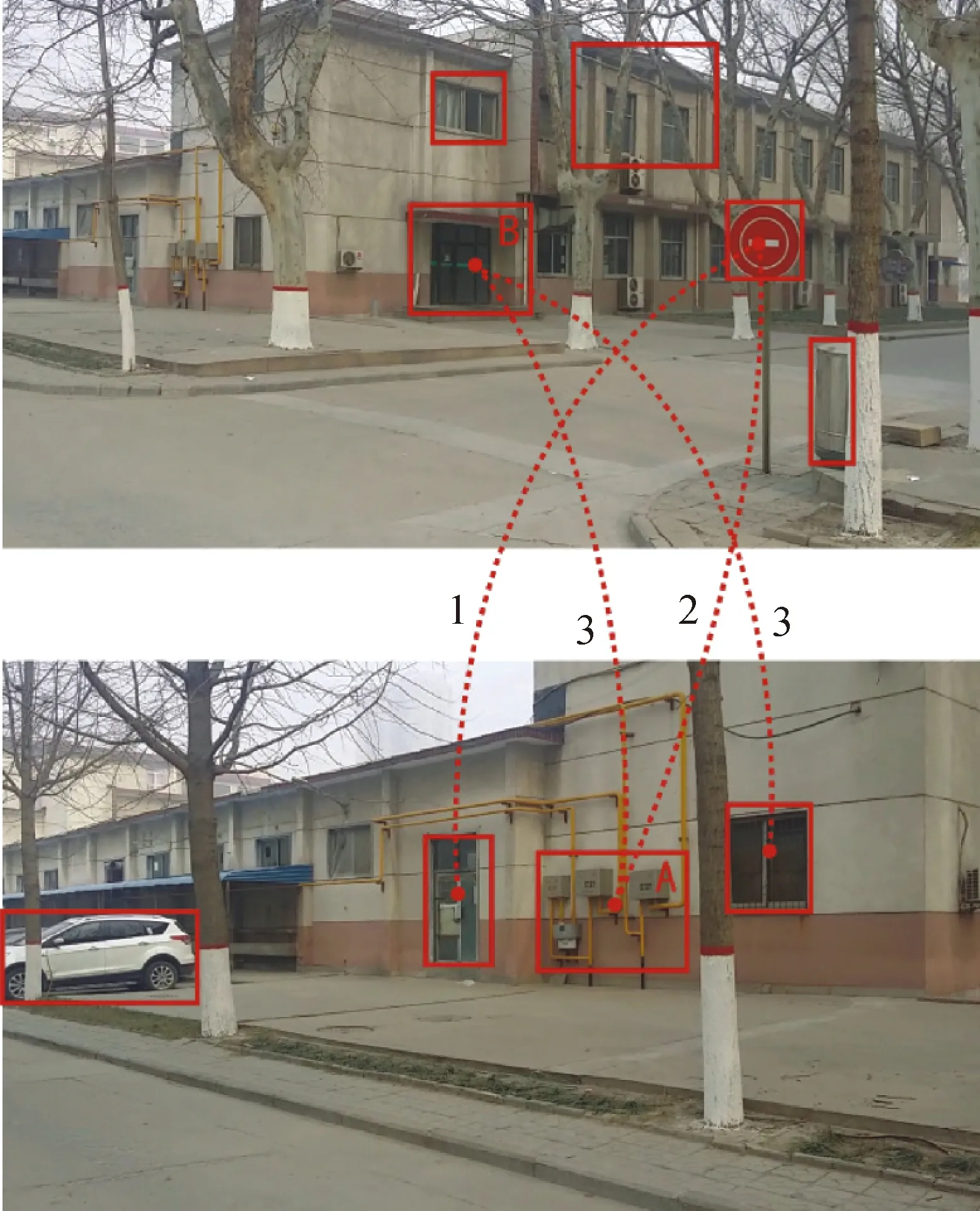
图10 图像空间关系匹配举例Fig.10 Example of the spatial relation matching
3 试 验
为了验证本文图像空间关系匹配算法的可行性,以及相比于已有算法的优势,构建测试数据进行图像匹配试验。另外,本文试验平台为64位的Ubuntu 16.04 LTS,16 GB内存Xeon 3.2 GHz处理器,试验代码基于Python 2.7编写,相关深度学习模型的训练是基于TensorFlow1.1.0框架,GPU为Nvidia Titan Xp。
3.1 试验数据与试验对比方法
本文利用Kitti数据集(Sequence 00)[29]与Apollo数据集(Road 04)[30]构建测试样本。所选的两组数据中,每帧图像均包含位姿信息,且图像序列形成多个环路,因此方便构建匹配图像对。序列中的任意两张图像即可组成一组测试样本,结合图像的位姿信息,若两张图像拍摄点位置距离小于5 m,且拍摄方向夹角小于π/6,则其为匹配样本(正样本),若拍摄点位置距离大于200 m,则其为非匹配样本(负样本)。利用每组数据集随机构建正、负样本各400组,分别利用不同方法进行图像匹配试验,参与对比试验的方法包括:
基于Bow模型的图像匹配:基于每组数据集的第2组序列(每组数据集包含两组序列,第1组序列用于构建测试样本)构建SIFT特征词典,词汇数目设为1000,基于该词典构建样本图像的词频向量,归一化后作为图像描述符,图像描述符间的欧氏距离即为图像间的相似度。
基于Inception-v3模型的图像匹配:Inception-v3模型可以准确地对图像进行分类[31-32],表明该深度卷积网络可以有效地挖掘图像语义信息,因此,基于Inception-v3模型的图像特征具有更强的表达能力。利用训练好的Inception-v3模型(http:∥download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz)对整幅图像进行表达,将pool3层输出(2048维的向量)作为图像特征,且图像相似度用特征向量间的欧氏距离表达。
基于VLAD模型的图像匹配:对每组数据集第2组序列中的局部特征(ORB特征)进行聚类,聚类中心数目设为64。利用得到的聚类中心为样本图像构建2048维的VLAD描述向量,归一化后作为图像描述符,图像描述符间的欧氏距离即为图像间的相似度数值。
基于NetVLAD模型的图像匹配:基于训练好的NetVLAD模型(https:∥github.com/uzh-rpg/netvlad_tf_open)构建样本图像VLAD描述符[17],根据描述符间的欧氏距离评估样本图像间的相似度。
基于深度特征匹配相同物体块的方法:基于训练好的特征提取网络构建样本图像中物体的深度特征,匹配样本中的相同物体块,统计每组样本包含的相同物体块数目。样本中匹配到的相同物体块越多,判定样本匹配的置信度越高。因此,将样本中匹配到的相同物体块数目作为评估样本是否匹配的判定指标,设置相同物体块数目阈值,当样本中匹配到的相同物体块数目大于该阈值时,即可判定样本匹配。
本文空间关系匹配:采用每组数据集的第2组序列构建场景物体空间邻近图,在此基础上,对于来自第1组序列的测试样本,检测样本图像中包含的物体块,在空间邻近图中搜索各物体块所属节点,进而计算样本的空间邻近度,设置邻近度阈值,当样本空间邻近度大于该阈值时,判定样本匹配。
3.2 图像匹配效果对比分析
图11所示为6种方法在部分测试样本中进行图像匹配的试验结果图,其中,红点代表正样本,蓝点代表负样本。基于BoW、Inception-v3、VLAD与NetVLAD模型的方法采用欧氏距离度量图像相似度,距离越小代表图像相似度越高,图11(a)、(b)、(c)、(d)表明4种方法中,正样本整体上具有更高的相似度(图像描述符距离较小)。
图11(e)表明本文基于深度特征可以在正样本中匹配到更多的相同物体,而大部分负样本中没有匹配到相同物体。尽管如此,仍有部分负样本中匹配到了较少的相同物体块,这是由于试验场景中包含很多难以区分的相似物体,如风格相似的窗户,同一型号的车辆等,本文深度特征难以对其进行准确区分;另外,部分正样本中没有匹配到相同的物体块,可能的原因包括:①正样本中的相同物体未被同时检测为物体影像块;②正样本中的相同物体在各自图像上的成像形态发生了显著变化,此时深度特征无法对其进行准确匹配。
图11(f)表明本文空间关系匹配可以达到较高的匹配准确率,几乎所有负样本的空间邻近度为0,而大部分正样本的空间邻近度大于0。
对比分析各种方法的匹配结果,统计各方法在不同阈值条件下样本的召回率与准确率,绘制准确率-召回率曲线(P-R曲线)对比,如图12所示。
对于基于深度特征的方法,其样本相似度为样本中匹配到的相同物体块数目,相似度阈值只能取非负整数,因此该方法的P-R曲线(绿色虚线)上只有部分点有意义(星号标记的离散点)。图12表明在图像空间关系匹配中(红色曲线),随着邻近度阈值从最大值减少到0,样本召回率不断增加,而样本准确率先是维持不变,随后急剧降到0.5(邻近度阈值为0时,样本召回率为1,准确率为0.5),这是因为几乎所有的负样本空间邻近度为0,大部分正样本的空间邻近度大于0,因此当邻近度阈值在0以上变化时,样本准确率几乎维持在1.0不变(召回率随着邻近度阈值的降低而增加)。
图12对比结果表明本文基于物体空间关系推理表达的图像匹配算法在测试样本中的匹配效果明显优于对比试验中的其他方法。已有的图像匹配方法一般在构建图像整体表达的基础上,计算图像相似度完成图像匹配,对图像的具体内容结构不做更细致的区分表达,这无疑会限制其匹配性能。现实世界中总是存在视觉上相似的不同场景以及变化显著的相同场景,只有对场景中的物体结构关系进行细致准确地表达,才能有效解决充满挑战的图像匹配问题。
相比于对整幅图像构建特征表达的方法,本文对图像内的物体邻近关系进行推理表达,对图像的描述更加的精细。即使图像对中存在视觉上难以分辨的不同物体,也可以通过其与邻近物体的空间关系对其进行区分;另外,即使同一物体在不同图像上成像差异很大,与其相邻近的物体却总是一致的,通过邻近关系分析也能对其进行准确匹配。


图11 试验结果Fig.11 Matching results of different models

图12 P-R曲线对比Fig.12 Comparison of the P-R curves
在图像匹配实践中,可以根据图像中物体是否存在邻近关系推断图像是否匹配,当空间邻近度为0时,表示图像中物体在欧氏空间中不邻近,此时图像不匹配;当空间邻近度大于0时,表明图像中物体存在一定的邻近关系,此时可以判定图像是匹配的。由于单一物体的错误匹配不会影响整体空间关系的匹配,本文通过分析图像中物体的空间邻近信息完成图像空间关系匹配,具有更强的稳健性。
3.3 图像匹配效率对比分析
匹配效率是评价图像匹配性能的又一重要指标,为了对比分析各种方法的图像匹配效率,统计基于各种方法完成测试样本匹配的耗时,计算每组样本的平均匹配耗时,汇总如表2所示。
表2表明基于BoW与VLAD模型的图像匹配方法耗时较长,这是由于这两种方法需要在样本图像中检测特征点,生成特征向量,这些过程需要消耗大量的时间。Inception-v3与NetVLAD模型将整幅图像作为网络输入,其处理的数据量较多,且由于其模型结构复杂,网络层数较多,图像匹配耗时也相应较多。

表2 各种方法平均匹配耗时对比
本文通过深度特征匹配样本中的相同物体块,该过程只需要提取局部物体块的特征,对于物体块区域外的图像内容并不参与匹配计算,这实质上降低了数据量。另外,本文特征提取网络层数较少,结构简单,大大提高了物体块深度特征的构建效率,表2表明本文基于深度特征匹配相同物体块的方法耗时最少。
在物体块深度特征提取的基础上,本文空间关系匹配需要判定各物体块在空间邻近图中的所属节点。通过物体块特征与节点向量点乘运算,预先概略计算物体块与各节点的相似度,筛选出候选节点,在候选节点集中搜索物体块的所属节点,进而大大限缩了节点搜索范围,提高了匹配效率。表2表明相比于其他方法,本文空间关系匹配耗时较少,取得了极高的匹配效率。
试验结果表明本文空间关系匹配方法可以稳定高效地完成图像匹配任务,在测试数据上取得了极佳的匹配结果,基本满足实时准确图像匹配应用的需求。
4 结 论
本文通过推理分析图像中物体的空间邻近关系解决整幅图像匹配的问题,首先基于对比机制训练特征提取网络,为图像中物体块构建深度特征。其次,基于先验的图像数据推理表达场景中不同物体间的邻近关系,构建空间邻近图。对于来自该场景的测试图像对,基于该空间邻近图表达测试图像中物体间的邻近关系,最终定量计算整幅图像的空间邻近度,完成图像空间关系匹配,试验表明本文方法优于对比试验中的其他方法,具有较高的稳定性,可以准确高效的解决图像匹配问题。
另外,由于本文研究还处于初步探索阶段,相关技术仍然需要改进完善,在未来的学习实践中,将重点在以下方面展开研究:
(1) 面向特定类别的物体目标检测。本文基于Edge Boxes算法[26-27]检测图像中的物体块,该方法是一种纯几何的方法,检测到的物体具有一定的随机性,可能一些非显著的物体被检测出来,或者一些显著的物体未被检测。目前,深度学习在目标检测实践中取得了很大的成功,因此,基于深度学习的物体目标检测相关研究,包括构建训练数据集、面向不同场景(街道、室内、户外)的物体目标归类、借鉴已有的目标检测模型训练面向特定类别的物体目标检测网络,都将是后期工作的重点。
(2) 更加细致的物体空间关系表达。本文对空间关系的表达仅仅局限在物体间的邻近关系,对空间关系的描述较为粗糙。更细致的空间关系表达是对场景内容更充分准确的描述,在各种视觉任务中都是十分必要的。在空间邻近关系表达的基础上,后期将探索如何对物体空间关系进行更加精细的表达,例如描述物体间的空间方位关系,所属关系(包含与被包含)等。
猜你喜欢
中学生数理化·高一版(2020年1期)2020-02-20
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
电子制作(2018年19期)2018-11-14
计算机测量与控制(2017年6期)2017-07-01
自动化学报(2017年11期)2017-04-04
科普童话·百科探秘(2015年4期)2015-05-14
集美大学学报(自然科学版)(2015年1期)2015-02-28
噪声与振动控制(2015年4期)2015-01-01
西安建筑科技大学学报(自然科学版)(2014年5期)2014-11-10
航天器工程(2014年4期)2014-03-11
