
多特征融合的胶囊网络用于图像分类
2021-01-16 06:00:16李建桥贾晓芬赵佰亭
哈尔滨商业大学学报(自然科学版) 2020年6期
李建桥, 贾晓芬, 赵佰亭
(安徽理工大学 电气与信息工程学院, 安徽 淮南 232000)
近年来,机器视觉的发展非常迅速,在各个领域中取得了显著的进展.尤其卷积神经网络在计算机视觉领域是重要的部分,有广泛的应用,例如图像分类[1]、文本检测[2]、语音处理[3]等.CNN是通过卷积层提取图像的信息,经过池化层降维减少参数量,最后通过分类器进行分类.CNN通过权值共享和池化操作实现了平移不变性和旋转不变性.但是池化层的出现会导致提取的特征信息会丢失,影响最终的分类精度.图像的空间相对位置对于结果有着非常重要影响,CNN并不能识别.比如说,人的一张脸,把眼睛、鼻子、嘴巴的空间位置打乱,那么CNN还是会将其识别成一张人脸,我们知道这是错误的 .虽然后续有许多对CNN的改进方法[4-6],但是由于CNN中有大量的参数,池化层依然不可或缺.
为了解决这些问题,Sabour[7]提出了一种新型的网络模型—胶囊网络(CapsNet).胶囊网络利用变换矩阵对局部部分与整个对象之间的关系进行编码,从而CapsNet能够通过局部关系理解整个对象.不同于CNN使用标量,胶囊网络将标量替换为向量神经元,向量的长度代表实体存在的概率大小,方向代表实例化参数.同时,CapsNet中使用步幅卷积和动态路由来实现参数大小的控制,胶囊网络对于数据集的要求比较低.CNN需要大数据集,这样网络拟合效果才好,而胶囊网络只需要小样本的数据集.卷积网络在池化的过程中会有大量的信息丢失,这会影响分类精度,胶囊网络能够将详细的姿态信息(如目标的位置、旋转、厚度、倾斜、大小等等)在整个网络过程中保存下来.CapsNet在小数据集MNIST上表现良好,但是对于复杂数据集CIFAR-10分类精度较低.可能的原因有以下两点:1)卷积提取模块只有两层卷积层,而CIFAR-10中的图片都是多通道和高分辨的彩色图片.浅的卷积层不能提取到更深层的特征和语义信息,从而导致在复杂数据集上的错误率较高;2)解码器部分的三个全连接层会导致图片的重构误差增大,进一步使得分类精度降低.
目前已有学者对胶囊网络展开了研究和改进.Kang[8]等人提出基于双通道词向量的卷积胶囊文本分类算法,采用具有动态路由机制的卷积胶囊网络模型进行文本分类,提高了文本分类的准确度.Xiang[9]等人提出了一种多尺度胶囊网络(MS-CapsNet).通过多尺度特征提取获得更多的结构和语义信息,然后将特征层次编码到多维的原始胶囊中去.在FashionMNIST和CIFAR-10数据集准确率分别达到92.7%、75.7%.Chen[10]将路由过程和神经网络中所有其他参数一起嵌入到优化过程中,克服了必须手工寻找最优路由迭代数目的缺点.Lin[11]通过改进动态路由和压缩函数的方式对Hinton等的胶囊网络模型进行改进,相比较原始网络性能有了明显的提升.Jay[12]等人通过向相应的实例化参数添加随机噪声来模拟人类手写输入中的实际变化.这种策略对于缺少大量标记训练数据的本地化语言的字符识别非常有用,除此之外,还开发了一种策略,有效地利用损失函数的组合来改进重建.Han[13]等人提出特征提取器和空间关系提取器,以寻找特征和空间关系的最佳组合.特征提取器从下到上提取特征信息,空间关系提取器从上到下提供空间关系指导.Chang[14]等人提出了一种严格挤压多车道的胶囊网络模型,称为MLSCN.替换了压缩函数,优化了dropout的实现.相比较原始的胶囊网络,性能有一定的提升效果.
本文主要的贡献如下:1)使用残差网络替代了原始胶囊网络中卷积提取层,能够提取到更深层的特征信息; 2)用反卷积层代替原始网络中的全连接重构层,降低重构误差;3)提取图片的浅层、中层和深层特征,并嵌入SE模块得到权重系数,数字胶囊层进行加权融合.所提出的方法经实验后可得,在Cifar10数据集上达到了87.21%的结果,相比较CapsNet有了很大提升,说明该方法的有效性.
1 改进的胶囊网络
1.1 模型结构
相比较CNN在训练过程中池化层的信息丢失、需要大量的样本和不能很好地应对模糊性等问题,胶囊网络很好地解决了这些问题.在小样本集上,CapsNet地表现超过了CNN.它是分层级的网络模型,在训练中学习部分与整体的关系.同时,对于模糊性的问题,胶囊网络在MultiMNIST数据集(一种由重叠的不同数字组成的手写数字变体)上获得了比CNN好的多的结果.
本文所提出的网络结构如图1所示,主体架构主要分为两部分:编码器部分和解码器部分.输入的图片先是经过编码器部分编码,再经过解码器部分得到重构图像.其中编码器部分包括残差模块和胶囊模块,解码器部分包括5层反卷积层.残差模块主要是提取特征信息,胶囊模块将特征向量化.反卷积主要是对编码后的图片进行重构.
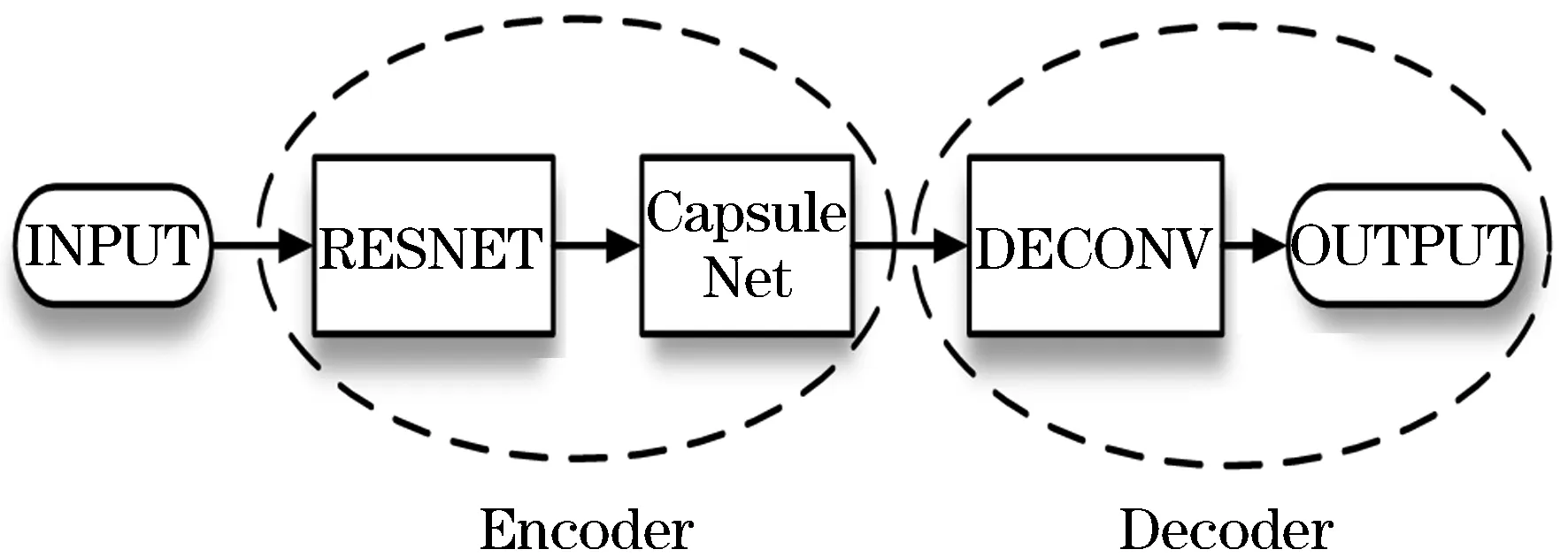
图1 网络结构模型
1.2 编码器
1.2.1 残差提取模块
编码器部分包括残差提取模块[15]和胶囊模块.残差提取模块主要用于提取图片中更深层的特征和语义信息,模型结构见图2,主要包括一个3×3卷积、8个残差块、一个BN层和ReLU激活层.图片先是经过卷积核大小为3×3、步幅为1的卷积,得到维度为32×32×16的特征图.然后经过3个核大小为3×3、步幅为1的残差块,得到维度为32×32×64的浅层特征图,将提取到的浅层特征输送到Primary1中.再经过3个核大小为3×3、步幅为1的残差块,得到维度为16×16×128的中层特征图,将提取到的中层特征输送到Primary2中.再经过2个核大小为3×3、步幅为2的残差,得到维度为8×8×256的深层特征图,将提取到的深层特征输送到Primary3中.最后经过BN层和ReLU激活函数层.
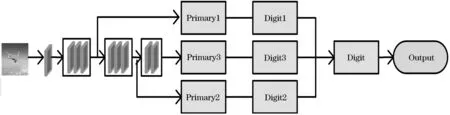
图2 编码器
1.2.2 胶囊模块
深层网络的感受野比较大,语义信息表征能力强,但几何信息的表征能力弱,深层特征表征的图像信息更丰富,能够将复杂的目标区分开.浅层网络的感受野比较小,语义信息表征能力弱,但几何信息的表征能力强,浅层特征表征的信息较少,但能够将一些简单的目标区分开.浅层和深层的特征进行融合能够互相弥补,这样对于分类任务有提升.
胶囊模块包括主胶囊层和数字胶囊层.如图3所示,经过前面残差网络提取到的浅层特征R1、中层特征R2和深层特征R3,再分别输送到主胶囊层Primary1、Primary2和Primary3中,里面都包含一个SE模块,经过SE模块后分别得到浅层、中层和深层特征的权重系数a1、a2和a3.将三个权重系数与三个数字胶囊层分别相乘,得到三个带有权重的数字胶囊层,分别为Digit1、Digit2和Digit3.权重系数对分类有用的胶囊起到放大的作用,对无用或作用比较小的胶囊起到抑制的作用.最后将三个带有权重系数的数字胶囊层融合成一个数字胶囊层.其中Digit1、Digit2和Digit3都是10个类别的输出向量,每个类别为16D的胶囊.Digit1、Digit2和Digit3的输出分别用D1、D2、D3表示,⊕代表串型连接.最后的数字胶囊融合层Digit用D表示,是一个48D的胶囊.则有

图3 带有SE的胶囊模块
D=(a1*D1)⊕(a2*D2)⊕(a3*D3)
(1)
在编码器部分,损失函数用边缘损失函数,定义为:
(2)
其中:m+为上边界,取值为m+=0.9,m-为下边界,取值为m-=0.1,λ=0.5,如果一个类别的对象存在m+时Tk=1.
1.3 解码器
解码器部分主要包括了一个反卷积模块.原始的胶囊网络将重建损失作为一个正则化方法,以鼓励数字胶囊层中的胶囊尽可能多的编码有用信息.这里的重建模块简单地通过将数字胶囊层的输出提供给3个全连接层组成的解码器来完成.虽然该方法在简单数据集MNIST上能够很好的重建数字,但是对于复杂数据集的重建性能并不好,重建后的图像较模糊,难以分辨.
基于以上的分析,本文提出了使用反卷积来重构图像的方法,以提高复杂数据集的重建性能和分类精度.如图4所示,由编码器部分得到的10个48D的胶囊向量,我们将其压缩成480D的向量.然后经过4个卷积核大小都为3×3,步幅分别为1、2、2、1,滤波器的数量分别为64、32、16、3的反卷积.最后得到通道为3,大小为32×32的重构图像.使用均方误差作为重构损失函数,定义为:
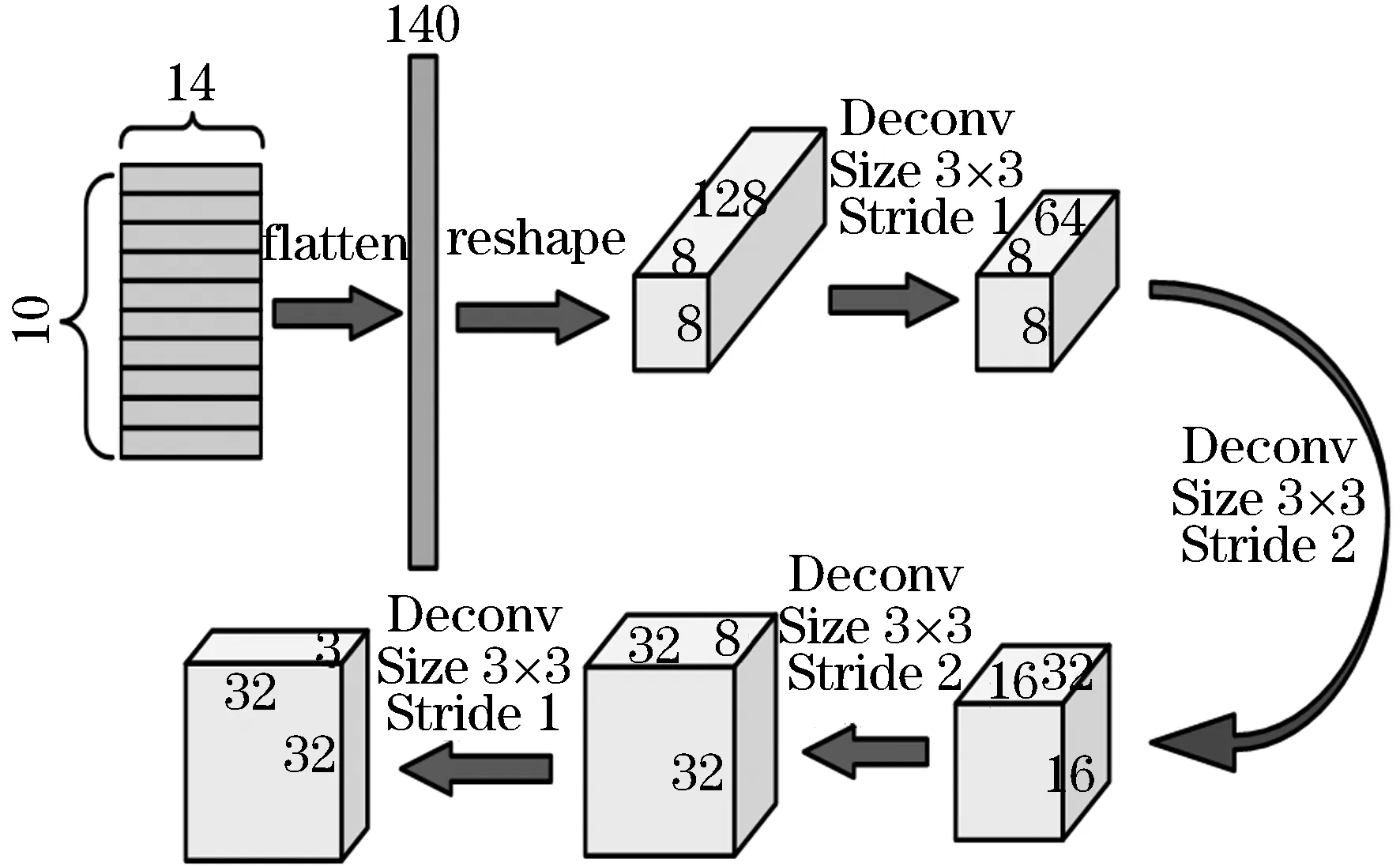
图4 解码器
(3)

2 实验和结果
2.1 数据集
为了评价所提方法的性能,我们在两个数据集Fashion-MNIST、CIFAR-10上进行实验.Fashion-MNIST是单通道的数据集,分辨率大小为28×28,共有十个类别.包含70 000张灰度图片,其中60 000张训练集图片,10 000张测试集图片.CIFAR-10是RGB三通道的数据集,分辨率大小为32×32,共有10个类别.包含60 000张彩色图片,其中50 000张是训练集,10 000张是测试集.
本文使用Keras框架编码实现改进的胶囊网络模型,并使用Adam优化器作为梯度下降算法进行训练.批大小设置为128,训练设置为150个周期,每个周期内迭代了390次,权重衰减系数设置为0.000 05.初始学习率为0.001,在训练过程中阶段性的减小学习率,使网络能够在训练时达到最优.所有的实验都是在安装内存为6 GB的GTX1060显卡的电脑上完成的.
2.2 结果与讨论
本文所提方法的准确率和参数量与其他方法的比较如表1所示,“-”表示该方法没有在数据集上实验.
实验结果如表1所示,通过表1可以看出MFF-CapsNet在Fashion-MNIST和CIFAR-10数据集上的性能明显优于已有的几种方法.同时参数量相比较于CapsNet没有增加多少,但是分类的准确率有了大幅的提高,在两个数据集上分别提高了1.7%和14.23%,特别是对于CIFAR-10数据集.相较于MS-CapsNet,准确率分别提高了0.65%和11.74%,但是参数量减少了接近一半.MFF-CapsNet的准确率比TextCaps高0.05%、8.25%,而参数量是TextCaps的1/3.MFF-CapsNet在CIFAR-10上准确率比FSc-CapsNet高7.18%,参数量有了大幅度的减少.模型在CIFAR-10上的准确率比在Fashion-MNIST上有了明显的提高,可能是由于CIFAR-10数据集是三通道的彩色图像,图片包含的信息量比较多,MFF-CapsNet网络提取的三个特征信息较全面,既有浅层网络提取到图片的纹理、细节特征,也有深层网络提取到的轮廓、形状等特征,将不同的特征融合到一起,这样使得提取到的特征更加全面,对于分类更加有帮助.
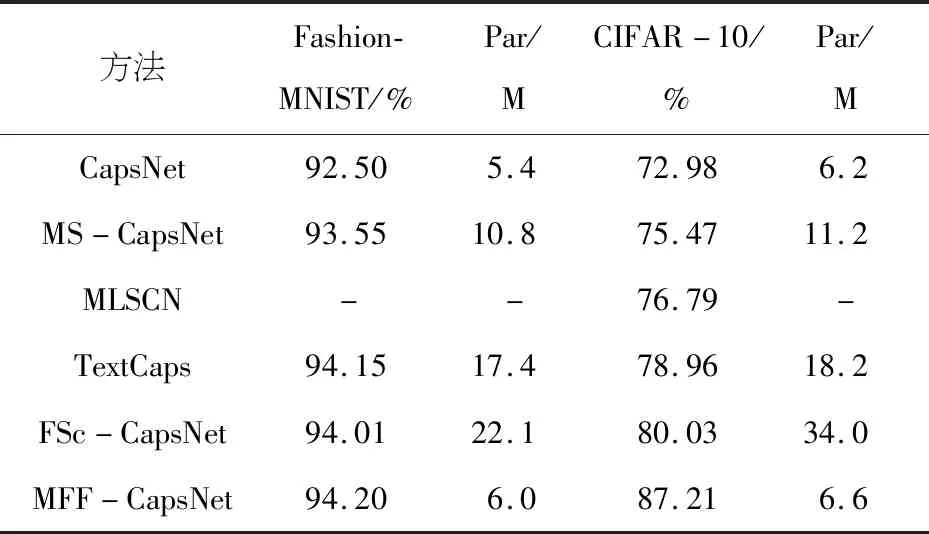
表1 实验结果对比
图5是MFF-CapsNet在数据集CIFAR-10上的模型训练图.训练准确率达94.31%,测试准确率达87.21%,两者相差不大,损失梯度比较平滑,说明模型的拟合效果较好.

图5 网络模型训练图
图6是CapsNet和MFF-CapsNet在数据集Fashion-MNIST上的损失下降图.从图6可以看出,随着迭代次数的增加,两个网络的损失下降,最终稳定下来.MFF-CapsNet网络相比较CapsNet网络损失下降多,说明MFF-CapsNet效果好.

图6 CapsNet和MFF-CapsNet在Fashion-MNIST上的损失图
虽然模型MFF-CapsNet在CIFAR-10数据集上分类精度有了大幅度的提升,但是和卷积神经网络相比还是有差距.同时,胶囊网络中的胶囊部分还有许多的改进之处.比如说对不同类别的胶囊维度使用不同维度,对压缩函数进行改进,使其能够对模长接近于0的胶囊进行放大,从而提取到更多的信息,优化动态路由机制等等.
3 结 语
本文提出了一种改进的胶囊网络,使用8个残差块代替了原始胶囊网络中的卷积层,从而提取到图片中更深层的语义和特征信息.同时将残差网络提取到的浅层、中层和深层特征融合,使得图片的信息得到充分的利用.将解码器部分使用反卷层代替,降低模型的重构误差,提高模型的分类精度.该结构的有效性在后面的实验中得到了体现,在数据集Fashion-MNIST和CIFAR-10上准确率达到94.20%和87.21%,同时相比较其他模型,参数量大幅减少.下一步我们将进一步的优化胶囊部分,使其在复杂数据集上的错误率进一步降低.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
水利规划与设计(2020年1期)2020-05-25 08:01:34
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2019年11期)2019-07-04 00:34:38
铁道通信信号(2018年1期)2018-06-06 02:27:37
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国卫生(2015年1期)2015-11-16 01:05:58
河南科技(2015年8期)2015-03-11 16:23:52
