
基于组合logistic回归模型的高校贫困生认定研究
2021-01-15 08:57李步青
网络安全技术与应用 2021年1期
◆李步青
基于组合logistic回归模型的高校贫困生认定研究
◆李步青
(浙江农林大学信息工程学院 浙江 311300)
当前高校贫困生认定工作基本上以人工为主要审核方式,存在着认定不准确、不公平等问题,为此本文提出了一种利用因子分析降维的组合logistic回归算法贫困生预测模型。首先,通过高校中心数据库获取学生在校消费的数据,通过数据预处理提取需要的特征数据。然后,对提取的特征数据采用主成分的因子分析实现数据降维,得到相互独立的因子。最后,基于logistic回归算法进行判别与分类。实验结果表明,该算法模型具有一定的准确性,相比较其他模型预测准确率更高,为高校精准扶贫工作提供了重要依据,在一定程度上保证了扶贫工作的公平性。
高校贫困生;大数据;精准扶贫;因子分析;logistic回归
近年来,随着高校逐年扩招,贫困生人数也在不断增长,贫困认定工作也越来越重要。现阶段,高校扶贫存在于表面,深入实际不足,贫困认定来自学生自主申请、班级评议、院系审核、公示、复核等环节,认定结果往往存在缺乏客观性、困难等级划分不细致等问题。还有部分贫困生由于某些原因没有提交补助申请,整个过程存在着认定不准确、不公平等问题,且无法很好掌握贫困生的变化,使得扶贫的效果不显著,无法达到扶贫的目的。
目前高校已有研究人员采用学校学生消费情况进行贫困生认定与分析。陈晓等[1]提出了一种基于加权约束的决策树方法实现贫困生的认定,基于加权约束的决策树方法建立贫困生认定决策树,从而提高了贫困生认定效率。王文娟[2]通过对一卡通数据中心的后台数据库数据采用统计学中描述性统计和非参数检验的方法,分析学生在校园内经济行为的特点及不同自然特征学生的消费差异性。刘亮等[3]利用K-Means聚类算法构建聚类指标,从而确定高校困难学生贫困等级,为高校贫困生认定工作提供了研究指导。王泽原等[4]利用随机森林和决策树的算法进行贫困生的判别,为贫困生的认定提供了数据支撑。陆桂明等[5]通过机器学习的方法对贫困生进行预测研究,为贫困生的分类提供了研究方法。这些算法都在一定程度上对贫困生的认定工作起到了引导与促进作用,但在分类与准确性上存在着不平衡的问题。
本文针对高校贫困生认定上存在的分类与准确性上存在不平衡问题,提出了一种组合logistic回归预测模型,实现对高校贫困生的认定与监测。该预测模型利用高校大学生校园一卡通数据,对提取的多维数据采用因子分析算法实现降维,最后通过logistic回归算法对降维的数据进行数据挖掘,实现高校贫困生的认定工作。
1 数据获取与预处理
1.1 数据获取
本文所依据的数据是来自于某高校的一卡通数据。校园一卡通数据真实展现着学生在校消费情况,数据包括学生消费时间、消费金额、消费类型、卡内余额等数据。通过选取了2017级与2018级共6288名学生在2019年下半学期3月到7月的一卡通消费数据,共有2029499条数据。从学工部获得2017级和2018级学生在2019年获得的助学金数据,共有1098名学生获得资助。
学生校园消费数据如表1所示。选取的数据包括学生的学号、交易时间、交易地点、交易类型以及交易金额等,这些数据可以充分展示学生在校消费情况,对这些数据进行一定数据处理,得到实验所需要的信息。

表1 学生消费数据
1.2 数据预处理
学生一卡通数据来源于不同的数据库,且数据库信息量较大,并且存在多种数据类型。这就导致实验数据存在不完整、不一致以及数据异常等问题,这些低质量的数据将会导致低质量的挖掘结果。为了解决存在低质量数据的问题,需要将原始数据进行转换,得到可以理解的数据格式或者符合实验挖掘的数据格式。
这就需要对原始数据进行预处理[6],数据预处理的目的是为了提高数据的质量,没有高质量的数据,就没有高质量的挖掘结果,就不能更好地展示数据的价值。根据实际情况,对选取的高校学生一卡通消费数据进行以下三种方式处理。
(1)数据提取
首先是在数据里提取所需要用到的数据。
在数据库里提取关于学生一卡通消费的信息,按照选取学生的年级以及在校消费的时间,提取学生学号、交易时间、交易类型、交易地点、交易金额等数据。
(2)数据清洗
其次对已经提取的数据进行清洗。
第一步,先找到数据缺失的值,按照缺失比例和字段重要性,以及业务处理经验,通过不同的指标推测或计算缺失值,并进行填写补上;第二步,识别并检测一些离群数据以及无效和重复数据,进行删除处理;第三步,根据实际情况查找不合理以及相互矛盾的数据,把这些数据进行去除或者修正处理;第四步,对内容与字段属性不符,即不一致的数据进行格式归化。
对数据进行清洗时,要尽量保证数据信息损失的最小化,得到符合要求的高质量数据。
(3)特征计算
最后对清洗的数据进行整合计算,得到新的特征变量。
将清洗后的数据根据实际情况进行计算处理,发现在校学生消费类型有36种,其中食堂消费占比最大,其次是超市,这两种消费类型消费的金额占消费总金额的90%以上,故把学生在校消费进行整合分类为食堂消费、超市消费和其他消费三种类型,消费金额分为学期总金额、月均消费金额、次均消费金额等。
2 预测模型
高校贫困生认定采用组合logistic回归模型进行预测,该模型通过因子分析与logistic回归算法相结合,利用学生消费数据实现贫困生的认定。
2.1 因子分析
对统计的数据进行比较发现,数据维度较多,且部分维度之间存在一定的关系,在保证数据重要信息的前提下降低数据维度,采取主成分的因子分析算法[7]对相关性很强的数据维度进行一定的线性组合,实现数据的降维,有利于简化和解释问题,抓住问题的实质。因子分析算法根据相关性大小把原始变量进行分组,在信息损失很少的前提下使得同组内的变量之间相关性较高,而不同组的变量间的相关性则较低,即将维的特征向量重建为维的特征向量(<)。
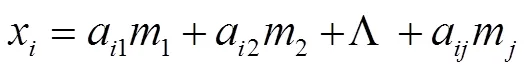
利用最大方差法对该方程的系数进行估算,从而获得每个个案的因子分。
计算出来各个成分的得分,即因子得分函数的系数,根据方差贡献率确定因子的个数,然后构建关于因子得分的回归函数,以此来确定新的变量。
2.2 logistic回归模型
本文使用的是logistic回归算法[8]建立预测模型,对高校贫困生的分类与预测提供了实际依据。logistic是一种广义线性回归算法,在数据的处理上类似于多重线性回归,与多重线性回归不同的是,logistic的因变量可以是非连续的,即其因变量可以是二分类的,也可以是多分类的。
Logistic模型中,因变量与自变量的一种非线性关系可表达为:
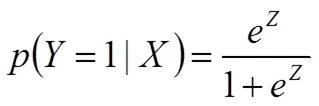
在公式(2)中,当为负无穷时,为0;当为正无穷时,为1。
将用一个函数()代替,假设
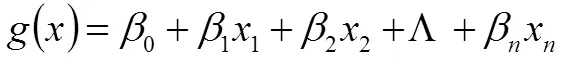


对(4)式取对数得到(5)式logistic回归线性方程
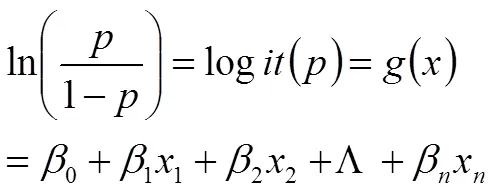
在logistic回归模型中,我们需要的是事件发生与不发生的概率的比例,即odds,odds能更好衡量数据模型指标的好坏。
得到事件发生与不发生的概率之比为
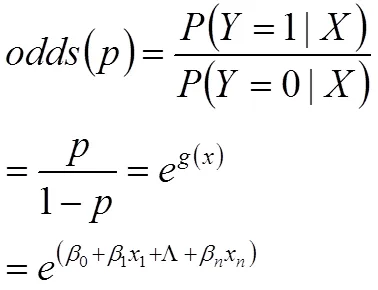

则

则似然函数为
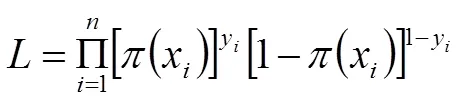
两边取对数得


求得的回归参数采用似然比方法进行检验估计参数的灵敏度,采用Hosmer-Lemeshow算法检验模型的拟合优度,置信区间默认为95%,判断显著性,最终确定参数值。
2.3 基于组合logistic回归模型的贫困生认定
最终选取6288名学生的在校消费数据,采用主成分的因子分析得到4个相互独立的特征值,这4个相互独立的特征值分别为食堂消费总金额、超市消费金额、恩格尔系数,以及一个结果值,是否为贫困生。然后把这些特征数据进行logistic回归训练,对输出结果进行判断。整个计算流程如图1所示。

图1 组合logistic回归模型流程
首先从数据库里获得原始数据,然后选取本文需要的数据组,对选定的数据组进行数据预处理,得到计算之后的特征值,最后把得到的数据变量使用组合logistic回归算法进行识别与预测,最后通过对输出进行判断,若输出值>0.5时,说明根据该学生最近一段时间内的表现,被预测为贫困生;<=0.5时,说明该学生被预测为非贫困生,该算法模型可实现对高校贫困生的识别与预测,并带有监测功能。
3 实验结果与分析
本文从贫困生查准率,贫困生查全率以及和的增加调和平均数三个方面对实验结果进行评估。
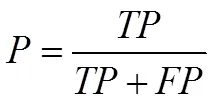
式(11)中,是指将贫困生判定为贫困生的学生数量,是指将非贫困生判定为贫困生的学生数量;

式(12)中,是指将非贫困生判定为非贫困生的学生数量;
和的调和平均数为

用查准率来验证模型的负面准确性,值越大,模型对贫困生的辨识能力就越准确;用查全率来验证模型的正面准确性,值越大,模型真正预测中贫困生占的比例就越高;用和的调和平均数来验证模型的稳定性,值越大,说明该模型越有效。
把处理的数据代入组合logistic回归预测模型中,最终得到的结果预测如图2所示。

图2 组合logistic回归模型结果
由下述表格可以看出,采用组合logistic回归算法,预测某高校贫困生的准确率达到89.1%,非贫困生的查准率97.9%,总的准确率达到96.3%。
采用值、值和值三个评估标准来综合评价模型2组合logistic回归模型评估方法和模型1 K-means聚类评估算法。

表2 两种模型对比结果
在表2中,可以看出,模型1中值、值以及F分别为70.1%、30.5%和42.5%,模型2中值、值以及值分别为89.1%、90%和89.5%。实验结果表明模型2对贫困生的辨识能力比模型1 更为准确,真正预测的贫困生比例远远大于模型1,并且模型2的稳定性更高。
综合以上三个评价标准,可以说明模型2在贫困生的识别预测方面更为理想,能够在很大程度上识别贫困生。
4 结语
针对目前高校贫困生认定过程中存在的问题,采用组合logistic回归算法进行贫困生认定,实现了高校贫困生预测。收集某高校关于学生某段时间内的消费数据,在数据预处理的时候,首先进行清洗、提取,然后采用因子分析对数据进行降维处理,减少数据的特征,有效降低了数据噪音以及过拟合问题。对降维后的特征值采用logistic回归算法进行训练,并且取得了更好的识别预测结果,在一定程度上为高校贫困生认定提供了积极的意义。该模型利用学生消费实现贫困生的预测,识别分类的准确率很高,预测结果分为贫困生与非贫困生两种,有待进一步的优化,对贫困生进行多层分类,选择更好的模型,研究预测的稳定性。
[1]陈晓,王树宝,李建晶,等.基于加权约束的决策树方法在贫困生认定中的应用研究[J].计算机应用与软件,2014(12):142-145.
[2]王文娟.基于一卡通数据的大学生消费分析的技术路线研究与实例分析[D].大连:大连医科大学,2013.
[3]刘亮,许灵,刘斯文.基于K-Means聚类的高校困难学生贫困等级划分研究——以蚌埠学院为例[J].白城师范学院学报,2017(08):38-41+64.
[4]王泽原,赵丽,胡俊.大数据环境下利用随机森林算法和决策树的贫困生认定方法[J].湘潭大学自然科学学报, 2018,040(006):115-120.
[5]陆桂明,张源,周志敏.基于机器学习的贫困生分类预测研究[J].计算机应用与软件,2019,36(01):322-325.
[6]丁小欧,王宏志,于晟健.工业时序大数据质量管理[J].大数据,2019,5(06):1-11.
[7]秦磊,郁静,孙强.混频时间序列的潜在因子分析及其应用[J].统计研究,2019,36(09):104-114.
[8]陈宫燕,普布桑姆,次仁旺姆,次仁,德庆央宗,李彦军.基于Logistic回归方法的林芝市山洪地质灾害预警研究[J].中国农学通报,2019,35(23):124-130.
猜你喜欢
疯狂英语·初中天地(2021年11期)2021-02-16
小康(2021年1期)2021-01-13
商周刊(2018年23期)2018-11-26
电子制作(2016年19期)2016-08-24
中国交通信息化(2016年3期)2016-06-05
大社会(2016年6期)2016-05-04
新高考·高一物理(2015年5期)2015-08-18
中国卫生(2014年2期)2014-11-12
中国火炬(2014年9期)2014-07-25
中国火炬(2012年5期)2012-07-25
