
基于抗噪多核卷积神经网络的轴承故障诊断方法
2021-01-15 07:46:12董绍江杨舒婷吴文亮
北京化工大学学报(自然科学版) 2020年6期
董绍江 杨舒婷 吴文亮
(1.重庆交通大学 机电与车辆工程学院,重庆 400074;2.西南交通大学 磁浮技术与磁浮列车教育部重点实验室,成都 610031)
引 言
轴承作为现代制造业的重要组成部分,在大多数旋转机械的运行中发挥着至关重要的作用,其健康状况直接影响机构性能的稳定性与寿命,因此轴承故障诊断对机械系统运行的可靠性和安全性具有重大意义。在实际应用中,机械系统的工作环境变化很大。由于振动信号容易被噪声污染,因此在工业生产中不可避免地会产生噪声。在嘈杂的环境下诊断故障类型的能力至关重要且具有挑战性。
防止轴承可能损坏的最常见方法是在旋转机构运行时对振动进行实时监控,目前常应用智能的故障诊断方法来识别故障类型[1-3]。Amar等[4]提出了一种故障诊断方法,该方法使用预处理的快速傅里叶变换(fast Fourier transform,FFT)频谱图像作为人工神经网络的输入。从原始振动信号生成的FFT频谱图像首先使用2D平均滤波器进行平均,然后通过适当的阈值选择转换为二进制图像。Shao等[5]针对滚动轴承故障诊断提出一种带有压缩感知的改进卷积深度置信网络,即先用高斯可见单位构造一个新的卷积深度置信模型,以增强压缩数据的特征学习能力;其次采用指数移动平均技术来提高构造的深度模型的泛化性能。
近年来,随着深度学习[6]在各种研究领域中作为计算框架的迅速普及,研究人员尝试使用卷积神经网络(convolutional neural networks,CNN)来诊断机械零件的故障。Wang等[7]提出了一种新的自适应深度卷积神经网络用于滚动轴承的故障诊断:首先,将深度CNN模型进行自动特征学习;其次,采用粒子群算法确定深度CNN模型的主要参数。Janssens等[8]提出一种用于旋转机械状态识别的CNN模型,其输入是从彼此垂直放置的两个传感器收集的两行信号的离散傅里叶变换(discrete Fourier transform,DFT)。Abdeljaber等[9]提出一种自适应1D CNN模型,用来对旋转机械进行检测和定位结构损伤。Guo等[10]提出了一种分层自适应CNN模型,该CNN模型通过将故障位置确定层和故障大小评估层按层次排列来实现故障诊断。以上这些模型在轴承故障诊断方面取得了不错的效果,但是并没有考虑在嘈杂的环境下诊断故障类型的能力,难以保证精度。
综上所述,本文提出了一种基于抗噪多核卷积神经网络(anti-noise multi-core convolutional neural network,AMCNN)的轴承故障识别新方法,在训练中,为增加样本数,抑制过拟合,对原始训练样本进行加噪、重叠采样处理,获得轴承信号样本并实现标签化。然后,根据标签化轴承样本训练改进的AMCNN轴承故障诊断模型,为提高模型抗噪能力,将AMCNN的一层设为dropout层。
1 卷积神经网络
CNN的基本结构由正向传播和反向传播组成[11]。正向传播的参数通过反向传播算法进行优化。正向传播由多个卷积层、池化层和几个完全连接的层组成,卷积层的目的是在输入数据通过各层传播时提取它们的不同特征。CNN训练过程如下。
1.1 前向传播
步骤1卷积
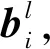
(1)
步骤2批量标准化
在将输入数据映射到非线性函数之前,批量标准化(batch normalization,BN)可减少内部协方差的移位,加快深度神经网络的训练过程,迫使输入数据分布呈标准正态分布。输入到该层的数据落入激活函数的敏感区域,以避免梯度消失。通过始终保持较大梯度的状态,可以调整神经网络的参数以更快地收敛。BN层的转换如下。
(2)
(3)
(4)
(5)
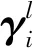
步骤3激活函数
最常见的激活函数为修正线性单元(rectified linear unit,ReLU)[13]。ReLU解决了S型局部梯度爆炸和梯度消失的问题,加速CNN的收敛。ReLU的算法如下。
(6)
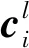
步骤4池化
池化层可以有效地减小矩阵的尺寸,不仅可以加快计算速度,而且可以防止过拟合[14]。通过简单的最大值计算该层的前向传播,转换如下。
(7)
式中,Ui表示cl的第i个特征矩阵。
步骤5SoftMax回归
在神经网络的输出进入SoftMax分类之前,执行全连接层。SoftMax回归模型可以是用于优化分类结果的学习算法[15],它将神经网络的输出转换为概率分布,该概率分布绘制了不同事件发生的概率。其转换如下。
(8)
式中,y′i表示神经网络的第i个预测值,S(·)表示SoftMax函数,di表示汇聚层的第i个输出,n是神经网络预测值的数量。
1.2 反向传播
步骤6交叉熵
交叉熵是评估神经网络输出的指标,它描述了模型的预测分布与真实标签分布之间的距离。输入参数相应标签值y′的交叉熵由神经网络的预测分布y-表示,转换如下。
(9)
式中,H(y-,y′)描绘了用y-表达y′的难度。交叉熵是神经网络的损失函数,当交叉熵的值较小时,神经网络的预测值接近真实值。
步骤7损失函数
损失函数是神经网络优化的目标函数。神经网络的优化是使损伤函数最小化的过程,损失函数值越小,则预测值越接近实际结果,其转换如下。
(10)
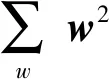
步骤8梯度下降
通过梯度下降法对模型的参数进行优化[16],其公式如下。
(11)
(12)

2 轴承故障诊断模型的建立
2.1 多核卷积神经网络
多核卷积是高灵活性的非线性学习模型,本文针对噪声下的轴承信号,采用AMCNN模型来增强模型的提取特征能力,提高识别精度。所提出的AMCNN识别模型建立了12层模型,包括1个输入层、5个卷积层、4个池化层、1个全连接层和1个输出层,第三卷积层采用多核卷积。同时,通过BN方法对数据进行处理。BN层使得输入到该层的数据落入敏感的非线性变换函数区域中,以避免梯度消失。
2.2 数据集增强
数据集增强技术通过添加训练样本的方式实现最大化神经连接的通用性目标。AMCNN模型需要大量的训练数据,对于轴承信号的特征,在采样时采用重叠采样的方式以增加训练样本的数量。这种采样方式不仅可以在相邻元素之间保持尽可能多的相关性,同时增加了参与模型的样本数量,从而可以使模型学习到更强的分类特性。
此外,神经网络的训练过程容易造成过拟合,在测试集上的识别率不佳,通用性较差。因此,在测试样本中加入了-10~50 dB信噪比的随机高斯白噪声,以增加有限的样本数量,减弱神经网络的神经元之间的连接关系。加入随机高斯白噪声相当于增加样本,减少神经网络过拟合,高斯白噪声可由下列方法得到。
(13)
(14)
(15)
式中,Pn是噪声序列的功率,Pave是信号序列的平均功率,x(·)是信号序列,N是信号序列中的总点数,k是信噪比,z表示噪声能量的大小。同时,在神经网络的第一层采用了dropout层,模拟真实环境对信号的干扰,以增强神经网络对噪声的抗干扰能力。
最后构建轴承故障识别模型,其结构如图1所示。首先,将原始信号进行预处理,获得轴承信号样本并实现标签化。然后,根据标签化轴承样本训练改进的AMCNN轴承寿命状态识别模型。在训练过程中,为抑制过拟合对原始训练样本进行加噪、重叠采样处理,为提高模型抗干扰能力,将dropout层作为第一层。
3 实验验证
在实际应用中,机械系统的工作环境变化很大,其中主要涉及两种变化:首先,工作负荷可能会随着生产的需要而不断变化,所以需要对训练样本进行分类和标记;其次,工业生产中噪声是不可避免的,振动信号容易受到噪声的污染。
3.1 数据描述
实验数据来自美国凯斯西储大学(Case Western Reserve University,CWRU)轴承故障信号,选取了包含无故障样本数据在内的10类数据。分别选取内圈、外圈、滚动体在轻度损伤、中度损伤和重度损伤下的信号各200个样本,采用重叠采样的方式以增加训练样本的数量,每个样本长度为2 048(3种损伤分别采用电火花加工出0.177 8、0.355 6、0.533 4 mm单点故障),另外还包含正常数据共10类数据,采样频率为12 kHz,训练和测试集中的样本个数比为4∶1。实验数据详细介绍见文献[18]。
3.2 模型结构参数
AMCNN模型各层的参数见表1。
在实验中使用的所提CNN结构由5层卷积和4层池化层组成,紧接着是全连接层和SoftMax层,其中第3层卷积层是由多核卷积核组成,实验使用Google的TensorFlow工具箱实现。第一个卷积内核的大小为1×64,合适的第一个卷积内核可以起到抗干扰作用[19,10],第3层多核卷积核的尺寸分别为1×1、1×4、1×8、1×16,多核卷积核对复杂特征提取能力更强,更具鲁棒性,能够更好适用于噪声环境。卷积层其余内核大小为1×4,激活函数为ReLU。池化类型为最大池化,在每个卷积层和全连接层之后,批量归一化用于改善CNN的性能。
3.3 CNN模型的可视化
本节通过对CNN训练过程的可视化展示模型特征提取过程。选用t分布随机领域嵌入(t-distributed stochastic neighbor embedding,t-SNE)算法,通过基于具有多个特征数据点的相似性识别观察到的模式来找出数据中的规律,将高维数据降低到2维以进行可视化,使相似的数据离得更近,不相似的数据离得更远。图2给出了从每个卷积层通过t-SNE方法提取的1 000个测试样本的特征分布的可视化结果。由图2可以看出,在最初的特征分布图中,各类的特征分布是不可分的,但最后的全连接层中各个类别的特征点是完全可分的。
由此可见,随着层的深入,特征变得越来越可分割,特别是在通过第三层的多核卷积之后,各类特征点的分布有了显著的变化,使得各个类别特征点的分布有了明显的区分,可见多核卷积核在故障分类识别中起到了关键的作用。同时,也验证了所提模型在故障分类上的有效性。
3.4 结果与比较
将本文所提模型与其他模型进行对比,验证不同模型性能的优劣。为了检验本文网络模型每个改进部分的效果,设置了3种情形:情形1将传统CNN和AMCNN进行对比,传统CNN结构中无多核卷积核,其他参数与AMCNN参数一致;情形2设置为是否在训练样本中添加噪声;情形3设置为是否添加dropout层作为AMCNN网络模型的第一层,其中dropout的值设为50%[20]。
表2中比较了不同信噪比环境下4种分类模型的识别正确率。
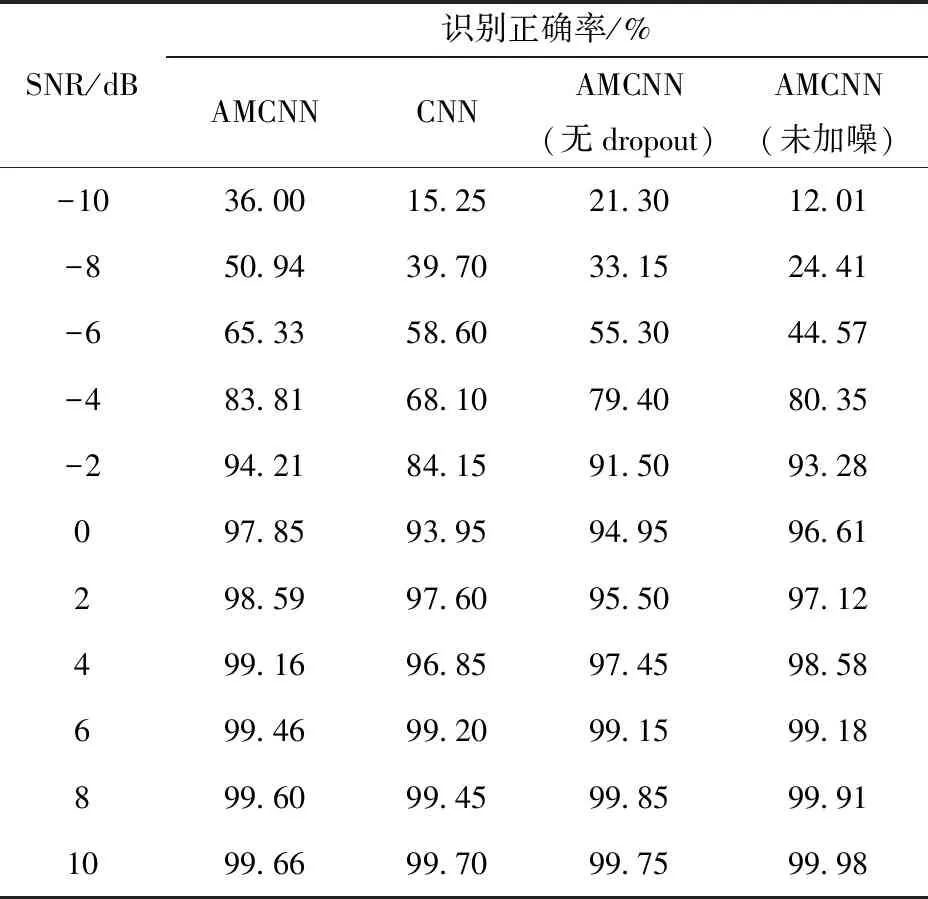
表2 不同信噪比环境下不同模型识别正确率Table 2 Accuracy of different models in different environments
AMCNN为文中所提出的方法,对训练样本进行加噪处理,第一层为dropout层;CNN模型为传统CNN结构,训练样本加噪,第一层为dropout层;AMCNN(无dropout)模型为采用AMCNN结构,训练样本加噪,第一层无dropout层;AMCNN(未加噪)模型为采用AMCNN结构,训练样本未加噪,第一层为dropout层。
由表2可以看出,当SNR为10 dB时,所有模型均显示出更高的精度(接近100%的正确率)。随着SNR的增加,CNN的准确性大大提升。CNN模型、AMCNN(无dropout)模型、AMCNN(未加噪)模型在SNR从-10 dB上升到10 dB时,正确率从10%~20%显著上升到接近100%。相比之下,AMCNN模型最为稳定,从-10 dB下的36%到10 dB下的99.66%。AMCNN模型在高噪声环境下的正确率都大大高于其他模型,如在-10 dB下,AMCNN模型的正确率比其他模型高出15%~25%,体现出本文所提方法的优越性,即在噪声环境下良好的抗噪能力和极高的故障诊断能力。
随着信噪比的上升,4个模型的识别正确率均呈现上升趋势,在信噪比高于6 dB的环境中,4个模型的识别正确率都能到达到99%以上,AMCNN模型与其余模型相比识别正确率差值小于0.32%。显然,随着信噪比进一步上升,4个模型识别正确率的差别将会越来越小,均接近100%。但在高噪声环境下,AMCNN模型与CNN模型相比,在-10 dB环境下识别正确率高出20.75%,在-8 dB环境下高出11.24%,表明在高噪声环境下AMCNN模型比传统CNN模型在抗噪能力上更优。同理,比较AMCNN模型与AMCNN(无dropout)模型,AMCNN模型的识别正确率在-10 dB环境下高出14.70%,在-8 dB环境下高出17.79%,在AMCNN模型的第一层中加入dropout层会使得识别模型在高噪声下的表现更加良好,比未改进前的AMCNN模型具有更好的抗噪能力。比较AMCNN模型与AMCNN(未加噪)模型,AMCNN模型的识别正确率在-10 dB环境下高出23.99%,在-8 dB环境下高出26.53%,表明加入噪声训练方法的样本可以抑制模型的过拟合,使得识别模型在高噪声环境下的表现更优。综上,这些实验验证了在低噪声环境下,本文所提模型能够实现高识别正确率(达99%以上),同时在高噪声环境下本文的改进部分具有有效性,比其他模型具有更高的识别率。
表3为支持向量机(support vector machine,SVM)、深度神经网络(DNN)、convolutional neural networks with wide first-layer kernels (WDCNN)[21]、多层感知器(MLP)等模型在信噪比从-5 dB到0 dB环境下对轴承故障的平均识别正确率。

表3 -5 dB到0 dB环境下不同分类模型平均识别正确率Table 3 Average accuracy of different models in the range -5 dB to 0 dB
由表3的比较结果可以看出,本文所提方法在信噪比从-5 dB到0 dB强噪声环境下的平均识别准确度要高于其他方法。主要原因是深度学习方法可以有效地从输入数据中学习基本特征,SVM等传统方法的效率在很大程度上取决于人工牵引;同时,本文针对噪声环境对模型进行了改进,其表现出的效果比部分神经网络算法更好。本文针对噪声环境改进了原始结构和参数,在从原始特征集中选择最敏感的特征或具有优异特性的一些新特征后,诊断结果将得到进一步改善。与人工提取特征的传统方法和其他深度学习方法相比,本文提出方法自动特征学习能力更强大。
4 结论
(1) 本文提出了一种新的解决故障诊断问题模型AMCNN,包括两个主要的抗干扰结构,即多核卷积核和外加dropout层,其中多卷核结构通过使用不同大小的卷积核对输入信号进行并行处理以增加模型的宽度,使得模型对复杂特征提取能力更强。AMCNN直接处理原始振动信号,无需任何费时的人工特征提取过程,为抑制过拟合,对原始训练样本进行加噪处理;为提高模型抗干扰能力,将dropout层作为AMCNN的第一层。
(2)针对在噪声环境下的轴承信号,所提出的带有dropout结构的模型相比其他模型对噪声的容忍度更高;所提出的样本数据加噪的训练方法有效地抑制了神经网络的过拟合问题。
(3)实验验证结果表明相较于其他模型,本文所提出的AMCNN的网络结构在噪声环境下对故障类型具有更好的识别率,在信噪比从-5 dB到0 dB强噪声环境下的平均识别正确率为94.21%。
猜你喜欢
中华养生保健(2020年7期)2020-11-16 01:14:26
科技创新与应用(2020年6期)2020-02-29 10:39:27
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
故事会(2016年15期)2016-08-23 13:48:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
