
区级人大报告中的地名自动标注研究
2021-01-15 11:33李红莲吕学强
北京信息科技大学学报(自然科学版) 2020年6期
喻 航,李红莲,吕学强
(1.北京信息科技大学 信息与通信工程学院,北京 100101;2.北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)
0 引言
随着信息技术快速发展,政府机关对信息化建设日益重视,各级人民代表大会(以下简称“人大”)开始逐步打造“智慧人大”[1]网络应用平台,通过充分运用网络信息技术,强化履职能力,推动人大工作的发展与创新。构建人大报告辅助生成系统,能够为人大工作人员撰写报告提供参考,提高工作效率。
区级人大报告的框架相对固定,往往分为当年工作总结和来年工作计划2大部分,每部分又分为监督工作、代表工作、自身建设和总结4个小部分。保留固定的内容,对报告中变化的实体进行标注,即可获得报告的模板框架。工作人员将变化内容输入模版内标注好的相应位置,即可生成参考报告。
通过对大量报告的分析可知,报告中出现最多的变化实体是地名,其他实体较少且具有很强的规律性。所以,对报告中出现较多且规律性不强的地名进行自动标注,就可以减少人工标注的工作量。
命名实体识别(named entity recognition,NER)是信息抽取和信息检索中一项至关重要的任务,其目的是将文本的命名实体识别出来,再进行分类,因此有时也称为命名实体识别与分类(named entity recognition and classification,NERC)[2]。
命名实体识别主要的方式有3种[3]:基于规则的方法、基于统计的方法以及基于深度学习的方法。谭红叶等[4]使用基于规则的动态规划方法对中国地名进行识别,提高了搜索最佳路径的效率,经过对真实语料的测试,地名的正确率和召回率分别达到92.3%和76.6%。但在大多数情况下,规则过于依赖于具体语言的领域和文本风格,其编制过程耗时长且不能包含全部的语言现象,存在可移植性差、更新维护困难等问题。而基于统计的命名实体识别,可将其视为序列标注问题,方法有隐马尔可夫模型[5]、最大熵模型[6]、条件随机场[7]等。基于统计的方法处理命名实体识别要对特征模板进行设计。基于深度学习的方法则不需要人工来设计特征模板,而是可以自己学习特征,从而减少了人对数据的干扰导致的误差。柏兵等[8]针对传统命名实体识别需要大量人工及规则信息的问题,提出一种基于条件随机场和双向长短时记忆神经网络的命名实体识别方法。谷歌研究员Jacob Devlin等[9]推出了一套新的语言表达模型BERT(bidirectional encoder representations from transformers),BERT不仅关注一个词的前后文信息,同时模型的所有层都会关注整体上下文的语境信息。
本文提出一种基于BERT预训练语言模型、CRF(conditional random field,条件随机场)和改进双向LSTM(long-short term memory,长短时记忆网络)相混合的方法,能够有效提升区级人大报告中地名自动标注的准确率,实验效果令人满意。
1 相关技术
1.1 BERT
常用的Word2Vec模型[10]在歧义词上识别效果较差。如“余杭”、“吴兴”等区县名,可能会与人名产生歧义。又如“朝阳”,它既是一个区名,也可能被理解为“初升的太阳”,这些词在Word2Vec模型里均被表示为同一个向量。而BERT使用预训练语言表示的新方法,将Transformers[11]双向训练作为一种注意力机制应用到语言模型当中:将输入中15%的单字随机用[MASK]代替,通过一个深度双向Transformer编码器运行整个序列,然后仅预测被屏蔽的单字。例如,在 “做好市人大朝阳团代表工作”一句中,BERT同时使用左侧和右侧上下文来表示“朝阳”:“做好市人大[MASK][MASK]团代表工作”,因为编码是从神经网络的最底层开始,所以它是深度双向的。
BERT可以学习句子之间的关系:B句是A句后面的一句话,或是语料库里的一个随机句。这一任务是借助A/B句最前面的特殊符[CLS]实现,该特殊符可以视为汇集整个输入序列的表征。如图1所示,有A句[强化监督]和B句[提高公信力],首先需要将这两句话进行分割,特殊符[SEP]是用于分割两个句子的符号,前半句会加上分割码A,后半句会加上分割码B,以及预测句子关系。
综上,BERT模型可以增加模型泛化能力,充分描述字符级、词级、句子级甚至句子之间的关系特征。
1.2 CRF
利用CRF计算每个字的转移概率。设X=(X1,X2,…,Xn)和Y=(Y1,Y2,…,Ym)是联合随机变量,若随机变量Y构成一个无向图G=(V,E)表示的马尔可夫模型,则其条件概率分布P(Y|X)称为CRF(条件随机场),即
P(Yv|X,Yw,w≠v)=P(Yv|X,Yw,w~v)
(1)
式中:w~v表示图G=(V,E)中与节点v有边连接的所有节点,w≠v表示节点v以外的所有节点。
在CRF中有两种特征函数,分别为转移函数T(yi-1,yi,i)和状态函数S(yi,X,i)。T(yi-1,yi,i)依赖于当前和前一个位置,表示从标注序列中位置i-1的标记yi-1转移到位置i上的标记yi的概率。S(yi,X,i)依赖当前位置,表示标记序列在位置i上为标记yi的概率。CRF的参数化形式为
(2)
式中:
Z(x)=∑yexp(∑j∑iwjfj(yi-1,yi,x,i))
(3)
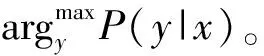
1.3 LSTM
1.3.1 LSTM单元
在LSTM单元内,首先一个向量会从左到右进行传输,从单元的左侧进入称作Ct-1,从右侧输出称作CT。左侧的Ct-1进入单元后,先被一个乘法器乘以一个系数后,再线性叠加一个数值后从右侧输出。其中,系数的来源为:左侧的ht-1和下面输入的xT经过连接操作,再通过一个线性单元,和一个σ(Sigmoid函数)之后,生成一个0~1之间的数字作为系数。忘记门为
ft=σ(Wf·[ht-1,xt]+bf)
(4)
所谓“忘记”就是指这一相乘的过程。如果Sigmoid函数输出为1,意味着全部记住,如果输出为0则为全部忘记,中间的值表示一个记忆或忘记的比例。Wf和bf作为待定系数是需要进行训练学习的。输入门为
it=σ(Wi·[ht-1,xt]+bi)
(5)
1.3.2 改进函数
在LSTM中,tanh是一种不可或缺的激励函数,但是此函数在两端的梯度几乎为零,优化算法更新网络参数的速度就会变得特别缓慢。
tanh的导数小于1。当神经网络的隐含层增多的情况下,在求解loss函数关于参数的导数时,上一层函数关于下一层导数的求导小于1,多个求导的连乘会发生梯度消失。tanh函数为
(6)
softsign函数也是中心对称,并返回-1和1之间的值。其更平坦的曲线与更慢的下降导数表明它可以更快速地训练模型,与tanh相比可以更好地规避梯度消失的问题。两者曲线对比如图2所示。因而本文改为使用softsign函数来训练模型。
改进LSTM的候选记忆单元为
(7)
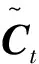
(8)
最后的输出有两个部分:一个输出到同层下一个单元,一个输出到下一层的单元上。输出门为
Ot=σ(Wo·[ht-1,xt]+bo)
(9)
式中
ht=Ot⊗softsign(Ct)
(10)
CT向量与OT输出门共同决定隐层状态hT。
单向LSTM存在局限性,如“上海”这个地名,当读入“海”字时,单向LSTM无法得到其上下文信息,有可能把“上”和“海”拆分成2个词。
1.3.3 改进BI-LSTM网络
为了规避单向LSTM的局限性,本文使用改进双向LSTM模型。BI-LSTM(BI-directional long short-term memory)同时考虑了过去的特征(通过正向过程提取)和未来的特征(通过反向过程提取)。通过上述改进LSTM函数的方法,得到由正反两个方向LSTM组成的改进BI-LSTM:
(11)
(12)
2 人大报告地名自动识别标注
2.1 基本框架
本文采用BERT+改进BI-LSTM+CRF的模型对人大报告中的地名进行识别并自动标注。框架结构如图3所示。首先把每个字的初始化向量输入BERT预训练语言模型训练,得到每个字包含位置信息的特征向量表示;接下来输入改进BI-LSTM网络模型(包括隐藏层、输出层)进行训练,获得每个字的类别概率;之后通过CRF标注层得到转移概率,通过每个字的转移概率与改进BI-LSTM输出概率累加得到每个字对应的最优标签。将识别出来的地名输入到列表中。最后借鉴了敏感词过滤算法的思想,把每篇识别到的地名替换为标记。
2.2 训练数据标注
BERT的训练数据有一定的格式要求,一般每行一个token,一句话由多行token构成,多个句子之间用空行分开。其中每行又分成2列,每行的第一列是字,后一列是标注符号,使用空格分隔。对训练数据采用 “B-LOC”、“I-LOC”和“O”标注。标注符号及含义如表1所示。

表1 标注符号及含义
2.3 文本向量化
由于神经网络只能进行数值计算,需要将每个字及特殊符号都转化为词嵌入向量。每个字有3个向量:一是位置信息的向量,在自然语言处理中字顺序是非常重要的特征,需要对位置信息进行编码;二是字向量本身;三是句子向量,即字在句子中的向量。把字对应的以上这3个向量叠加,可以得出每个词的字向量表示。
2.4 地名识别

P=σ(Vh+c)
(13)
式中:
h=(h1,h2,…,hn)
(14)
V为加权参数,代表了隐藏层到输出层之间的参数;c为偏置参数;σ(·)为激活函数。把P输入CRF标注层,根据输出序列,计算每个字符的标签分数:
(15)
将分数归一化得到概率:
(16)
因为误差是预测标签与正确标签的对比,所以,模型的训练目标就是最大化似然概率,对概率作对数似然,使用-logP(y|x)作为损失函数:
s(x,y)
(17)
3 实验和分析
3.1 实验环境
本次实验采用NVIDIA GeForce MX 150显卡来训练。编程语言为Python3.7,开发平台采用 tensorflow1.13版本。
3.2 评价指标
实验以准确率、召回率、F值作为评价指标[12]。用C记录正确的地名位置标记数,D记录识别出来的地名位置标记数,L记录全部的地名位置标记数。则准确率、召回率、F值分别为:
(18)
(19)
(20)
3.3 实验数据
本次实验采用的训练语料数据为1998年人民日报分词数据集,包含2 976 480字,部分数据集格式如图4所示。
把其中标注为“ns”的部分作为地名识别对象。如“[香港/ns 特别/a 行政区/n]ns”,就可提取出“香港特别行政区”(中括号以内的“ns”不单独作为一个地名)。
实验的测试集是近10年各个区县的区级人大报告,共收集230篇报告,包含1 372 243字,通过jieba分词并自动标注词性。
为保证实验标注的准确性,首先对训练集中的语料进行处理。通过人工校正对地理位置的标记。比如:“三B-LOC中I-LOC四B-LOC中I-LOC全O会O”句中,“三中”不是一个地名,所以在人工处理时,把“三中”这类的改为“三O中O”。用人工校正的语料训练,模型就学习到了特征。
3.4 参数的选择
要使深度学习模型取得较为理想的效果,需要选出一组合适的参数。对神经网络模型有较大影响的参数有:学习率、隐藏层单元数、丢弃率、批量训练数据大小等。经过几次实验结果对比,使用如表2所示参数时模型表现最好。

表2 参数选择
3.5 实验过程
为了与本文方法进行对比,另外还使用CRF、BI-LSTM+CRF和BERT+BILSTM+CRF这3种方法分别实验。在4个实验中,使用的数据集相同。
为解决在训练神经网络模型过程中可能出现的过拟合问题,本文在训练时加入Dropout[13],随机对一部分激活单元进行抑制,每一次训练的单元均不同,而在测试时保留所有神经元,从而避免过拟合现象的发生。
3.6 实验结果及分析
本文用了4种方法进行对比实验,实验结果如表3所示。

表3 不同模型结果对比 %
4个实验中,第一个是仅使用CRF方法识别,第二个是基于双向LSTM加CRF方法的实验,其中训练词向量[14]使用的是谷歌开源工具Word2Vec方法展开预训练,设词向量的维度为300。在后面两个实验中,都基于BERT来预训练字向量。
从表3可知,本文方法与CRF相比,F值提高了6.26个百分点。CRF中有大量标注过的语料,识别准确率取决于标注语料的准确度和数量,当训练集的语料较少时,CRF在训练时就无法学习到语料的全部特点,抽取时对于部分地名就无法识别或识别不准确。而使用改进BI-LSTM提取特征,比CRF提取特征的准确度高。
本文方法与BI-LSTM+CRF的方法相比,在F值上提高了4.25个百分点。对于本文中的方法,在使用改进BI-LSTM+CRF的模型识别之前,使用基于BERT的方法来预训练字向量,来替换原来网络的Word2Vec部分,从而避免了Word2Vec在歧义词上效果较差的问题。
在本文方法中BI-LSTM的激励函数由传统的tanh改为softsign,与BERT+BI-LSTM+CRF相比学习效率更高。记录了不同时间两种模型的F值,对比如图5所示。
由图可见,BERT+改进BI-LSTM+CRF在训练的初期F值就有了一定提升,并可以在更少的时间取得更高的F值。BERT+BI-LSTM+CRF在训练680 min时达到最大F值,而改进后在507 min即可达到最大F值。
在完成地名识别的基础上,借鉴敏感词过滤算法的思想,把地名都替换成标记,即可完成人大报告中地名的自动标注。
4 结束语
本文针对区级人大报告中地名自动标注的任务,提出了使用基于BERT预训练语言模型加改进BI-LSTM和CRF的方法对地名进行识别。该方法避免了条件随机场因语料受限识别不准确的问题,赋予了模型一定的纠错能力,可以更好更全面地捕获上下文信息。改进BI-LSTM通过减少梯度消失问题,加快了模型的训练速度,提升了模型的性能。后续的研究工作可在进一步细化识别效果等方面展开,例如可以按照地域来分级识别、分别标注:分为省级、市级、区级、街道级等。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
厦门大学学报(自然科学版)(2021年4期)2021-06-22
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
电脑知识与技术(2019年23期)2019-11-03
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
高中生学习·高三版(2016年9期)2016-05-14
理科考试研究·高中(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
外语教学理论与实践(2014年2期)2014-06-21
