
改进YOLOV3 算法的视频目标检测
2021-01-15 07:27宋艳艳马子豪任雪平
计算机与生活 2021年1期
宋艳艳,谭 励,马子豪,任雪平
北京工商大学计算机与信息工程学院,北京100048
在日常生活中,监控无处不在,广场、火车站、住宅小区、机要室等重要场所,都分布着大大小小,不计其数的摄像头,可实现犯罪、交通管制意外检测和防范的作用,在社会工作安全领域中发挥着越来越重要的作用。随着大数据、云计算技术在安防领域的应用,深度学习技术具备了应用条件。因此,实现智能分析处理视频的关键在于面向视频的目标检测与识别具有较高的准确率和处理效率。
目标检测是从视频或者图像中提取运动前景或感兴趣的目标,其要解决的问题就是标记出物体的具体位置,同时检测出物体所属的类别。实时且准确的目标检测可以为后续目标跟踪、行为识别等提供良好的条件。目前,主流的目标检测算法主要有:一是基于手工特征所构建的传统目标检测算法,如Viola-Jones检测器[1],采用了最传统的滑动窗口检测,在图像中的每一个尺度和像素位置进行遍历,逐一判断当前窗口是否为人脸目标;HOG 行人检测器[2],是基于梯度方向直方图特征的改进,通过固定检测器的窗口大小且构建多尺度图像金字塔来检测不同大小的目标;可变形部件模型[3],该算法将目标整体检测转化为各部件检测问题,然后将各部件检测结果进行聚合得到目标整体检测结果。二是基于目标候选区域的检测算法,通过提取候选区域,并对相应区域进行深度学习实现分类检测结果。该类算法主要包括R-CNN[4](region-based convolution neural networks)、SPPNet(spatial pyramid pooling network)[5]、Fast R-CNN[6]、Faster R-CNN[7]、R-FCN(region-based fully convolutional network)[8]等系列方法。三是基于深度学习的回归方法,包括YOLO(you only look once)[9]、SSD(single shot multibox detector)[10]、DenseBox[11]等方法。随着深度学习出现之后,目标检测领域在特征表达能力及时间效率上取得了突破性进展,可以轻松实现实时检测速度。针对目标检测中处理多尺度问题,YOLOV3 检测算法直接利用深度网络在目标对应位置提取的特征对其边界框进行回归处理,减小了计算量且设计比较简单。但由于目标检测中存在背景复杂,目标尺度和姿态多样性的问题,造成YOLOV3 算法对部分目标检测不准确,会产生误检、漏检或重复检测的情况。
为解决行人目标尺度和姿态多样性导致目标检测不准确的问题,本文借助YOLOV3 本身算法思想将前层特征和中层特征进行融合,构成包含不同尺度的目标定位信息和语义信息的融合层。通过增加多尺度融合层,解决其对多尺度目标的预测边界框不够准确问题。同时,利用K-means 聚类算法对数据集的目标真实框尺寸进行聚类分析,更改网络检测层的边界框尺寸,以实现更好的目标检测结果。另外,针对数据集中出现的人与周围目标相互遮挡影响检测的问题,使用斥力损失函数,缩小预测框与真实边框的聚类,增大与周围边框的距离,从而降低模型的错误率,提高检测效果。实验结果证明,本文改进的视频目标检测算法对出现的多尺度目标具有很好的定位能力,并且能检测出处于遮挡部分的行人目标,并在实验数据集上取得了好的目标检测结果。
1 相关介绍
目标检测是当前计算机视觉和机器学习领域的研究热点,相对于传统目标检测算法,R-CNN[4]将问题转变成找出可能含有物体的区域框,这些框之间是可以相互重叠互相包含的,这样就避免了暴力枚举所有的框。R-CNN 目标检测算法利用选择性搜索算法在图像中取2 000 个左右可能包含物体的候选区域,然后将每个候选区域缩放成统一的大小,并输入到卷积神经网络(convolutional neural networks,CNN)提取特征,最后将提取的特征输入到支持向量机(support vector machine,SVM)进行分类。He 等人针对R-CNN 进一步改进提出了SPPNet[5],在R-CNN网络最后一个卷积层后接入了金字塔池化层,保证传到下一层全连接层的输入固定。因为在R-CNN 中存在wrap/crop 预处理,导致图像出现拉伸变形或物体不全等问题,限制了识别精度。SPPNet 在CNN 结构上加入了金字塔池化层,使得网络的输入图像可以是任意尺寸,输出是一个固定维数的向量。RCNN 目标检测算法对所有候选区域进行特征提取时会有重复计算,针对这个问题,Girshick 提出了Fast R-CNN 模型[6],与R-CNN 相比,其在最后一个卷积层后添加了一个ROI(regions of interest)池化层,同时其损失函数使用了多任务损失函数,将边框回归直接加入到CNN 网络训练中,在保证准确率的同时提升处理速度。在Fast R-CNN 目标检测算法中,对于选择性搜索,找过所有的候选框,是非常耗时的。针对此问题,Ren 等人提出了Faster R-CNN 框架[7],在Fast R-CNN 中引入了区域生成网络(region proposal network,RPN)代替选择性搜索算法,同时引入锚点(anchor)应对目标形状的变化问题。
2016 年,Redmon 等人提出了一种新的物体检测方法YOLO[9]。他们将对象检测作为回归问题构建到空间上分离的边界框和相关的类概率。单个神经网络在一次评估中直接从完整图像预测边界框和类概率。该检测算法,对于一个给定的输入图像,将其划分成7×7 的网格。然后,对于每个网格,都预测2 个边框值(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率)。针对预测出的7×7×2个目标窗口,根据阈值去除可能性比较低的目标窗口,最后利用非极大值抑制(non-maximum suppression,NMS)去除冗余窗口。YOLO 将目标检测任务转换成一个回归问题,大大加快了检测的速度,使得YOLO 可以每秒处理45 张图像。但YOLO 没有候选区域机制,只使用7×7 的网格回归会使得目标不能非常精确地定位,这也导致了YOLO 的检测精度不是很高。为了提高物体定位精确性和召回率,Redmon等人在YOLO 的基础上提出了改进YOLO9000[12],相比于YOLOV1 提高了训练图像的分辨率,引入了Faster R-CNN 中的候选框的思想,对网络结构的设计进行了改进,输出层使用卷积层代替YOLO 的全连接层,联合使用COCO(common objects in context)物体检测标注数据和ImageNet 物体分类标注数据训练物体检测模型,其效果显示无论是在速度上还是精度上都优于SSD[10],但是YOLOV2 在面对不同尺度的目标时,其检测效果依然不够理想。2018 年Redmon 等人再次提出了YOLOV3[13],其主要改进是调整了网络结构,新的网络结构darknet-53 借用了ResNet[14]的思想,在网络中加入了残差模块,这样有利于解决深层次网络的梯度消失问题。其次,采用了多尺度检测,选择3 个不同尺度的特征图来进行对象检测,能够检测到更加细粒度的特征。再者,YOLOV3 中预测对象类别时不使用softmax 函数,改成使用logistic 的输出进行预测,这样能够支持多标签对象。YOLOV3 虽然具有不错的结果,但随着IOU(intersection over union)的增大,性能下降,说明YOLOV3不能很好地与真实框切合。因此,在YOLO算法的基础上,针对不同数据集进行创新优化,提高检测效果的相关研究逐渐增加。例如王殿伟等人[15]提出的小目标检测算法,葛雯[16]、孔方方[17]和Wu 等人[18]改进的YOLOV3 算法,高宗等人[19]提出的基于YOLO网络的行人检测方法,船舶等目标检测[20]及手势跟踪等应用[21]。
2 方法
为了使YOLOV3 算法适用于行人目标检测数据集,本文针对YOLOV3 算法进行以下工作:首先对行人目标检测数据集进行K-means 聚类分析,根据聚类结果确定算法中边界框尺寸;其次,增加YOLOV3 的尺度检测层,以提高人群密集中小目标检测的效果;最后,在YOLOV3 的原有损失函数基础之上,加入了斥力损失函数解决行人目标检测出现的遮挡问题。
2.1 目标框聚类分析
YOLOV3 算法引入了anchor概念,anchor是针对不同尺度网络层而确定的初始候选框。在之前的目标检测算法中,都是手动挑选候选框的尺寸,这样选取的候选框过于主观。因此利用K-means 算法对训练集中的真实边界框进行聚类,根据聚类结果选择出具有客观性和代表性的候选框。
K-means 是发现给定数据集的K个簇的算法,每一个簇通过其质心(centroid),即簇中所有点的中心来描述。一般的K-means 聚类通过度量样本间相似性进行聚类,通常利用欧式距离作为度量公式。在候选框聚类过程中,若使用欧式距离的标准K均值,则较大的边界框会比较小的边界框产生更多的误差。真正想要选择的样本间的距离度量应该与边界框本身的大小无关,因此对于候选框聚类的距离度量,使用以下公式进行计算:
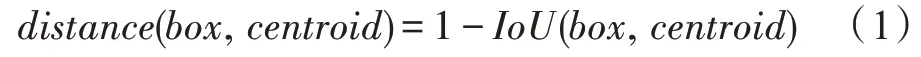
其中,box表示真实框的集合,centroid表示边界框的簇中心集合,IoU(box,centroid)表示真实框与边界框簇中心的交集与并集的比值。IoU值越大,代表两者相关度越高,即两者越相近。在目标检测中IoU计算方式如图1 所示。
对于给定的真实框数据集,通过计算边框间IOU值来度量边框间的距离,避免边界框本身大小所带来的误差。利用该聚类算法将数据集划分为K个簇,通过一系列迭代使得簇内的边框距离尽可能小,而簇间的边框距离尽量大,最后通过目标函数的变化值从而确定候选框的尺寸。总的来说,K-means 聚类分析的目的,行人数据集的真实框本身存在“高瘦”的特点,YOLOV3 检测算法原有的候选框尺寸并不完全适用密集行人数据集。因此,通过数据集本身标注出的真实框(包括无遮挡和遮挡的目标)的尺寸大小进行聚类分析,选出具有客观性、代表性的候选框,替换YOLOV3 检测算法原有的候选框尺寸,以提高检测的效果。
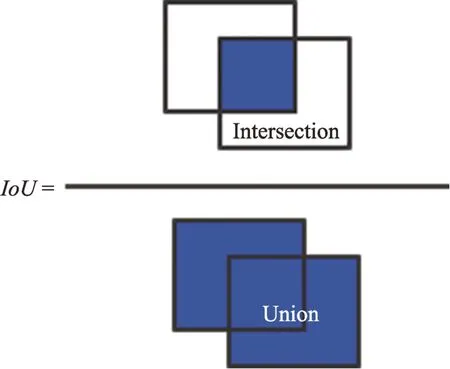
Fig.1 IoU calculation formula representation图1 IoU 计算公式表示图
2.2 多尺度网络层
针对行人目标尺度和姿态多样性导致目标检测不准确的问题,借助YOLOV3 本身算法思想选择将浅层特征和中层特征进行融合,构成包含不同尺度的目标定位信息和语义信息的融合层。经分析,浅层特征对小尺度目标具有很好的细节定位能力,但语义表征信息弱。随着网络层的加深,深度特征图包含丰富的语义信息,而经过连续下采样操作,小目标定位信息丢失。因此,利用残差思想,将浅层特征与深层特征信息进行连接融合进行目标检测。但直接利用最深层特征图对浅层特征进行语义增强的效果并不明显,因此在构建融合层时,选择通过上采样操作将深层特征图放大到和浅层特征图相同的尺寸进行连接操作。将增加融合检测层的网络模型称为YOLOV3_104,其网络结构图如图2 所示。
从网络结构图中可以看出,在原有YOLOV3 网络结构基础上,将深层特征图经过上采样操作放大到与浅层特征图同一尺寸,之后进行连接操作构建了新尺度目标检测层。在原有网络基础上增加了104×104 尺度检测层,相对其他尺度检测层,将图像划分成了更精细的单元格,可以检测出越精细的物体,对小目标的检测效果提升明显。
在增加104×104 尺度检测层的基础上,将数据集真实框进行聚类分析得到的候选框尺寸分别应用到13×13,26×26,52×52,104×104 尺度检测层上进行目标检测。对于较大的特征图,其感受野较小,对小目标相对敏感,因此选用尺寸小的候选框,而较小的特征图,其感受野较大,对大目标相对敏感,因此选用尺寸大的候选框。
2.3 斥力损失函数
针对数据集中出现的人与周围目标互相遮挡出现检测不准确的问题,在YOLOV3 原有损失函数的基础上,即缩小预测框与其负责回归的标注框的距离的同时,添加了斥力损失[22]函数,增大预测框与其周围非负责标注框及相交预测框的距离。更新后的损失函数,可以使得预测框向正确的目标靠近,远离错误的目标,降低模型的误检率。其损失函数计算公式如下所示:

Fig.2 YOLOV3_104 network structure diagram图2 YOLOV3_104 网络结构图

其中,LYOLOV3表示预测框与其负责回归的标注框的损失计算值,沿用了YOLOV3 的中心点、长宽、类别及置信度差方相加的损失计算方式;LPBox-GBox表示预测框向其他标注框偏移的损失计算值;LPBox-PBox表示预测框与其他预测框靠近的损失计算值,α、β用于平衡后两者损失值的权重。
当预测框与其他标注框靠得太近时,使得预测框容易受非真实标注框影响,回归出来的预测框同时包含不同标注框间的部分区域,出现检测不准确的情况。因此LPBox-GBox表现为斥力作用,使得预测框不受其他标注框的干扰,其计算公式如下所示:

其中,P+表示预测框集合,BP表示候选框P所对应的预测框,表示除了真实标注框外具有最大IoU区域的标注框,IoG、Smoothln计算公式如下所示:

当不同标注框对应的预测框靠得太近时,在NMS 处理中容易筛选掉IoU值大于阈值的部分预测框,出现漏召回的问题,因此LPBox-PBox表示为斥力作用,将不同标注框对应的预测框分开,其计算公式如下:
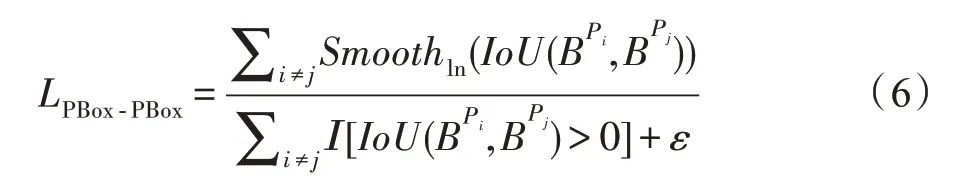
其中,I表示取预测框间IoU值大于0 的值进行计算,ε为很小的常数。
3 实验
3.1 实验环境
本实验平台为戴尔服务器PowerEdge R730,操作系统Ubuntu 14.04,CPU Intel®Core i3 3220,内存64 GB,GPU NVIDIA Tesla K40m×2,显存12 GB×2。
3.2 实验参数设置
3.2.1 数据集
实验所选择的数据集是MOT16 数据集[23]。该数据集标注的主要是移动中的目标,主要分为三种类别:第一是出现在视野中的移动或直立的行人,包括在自行车或滑板上的人,处于弯腰、深蹲、与小孩对话或捡东西状态的行人;第二是包括像行人的目标(模特、出现人的图片、反射的人影),不处于直立状态的人(坐着或躺着的)和划分为模糊目标(不同观察者出现意见变化较大的);第三种类别标注所有的移动车辆、非机动车和其他存在潜在包含/遮挡关系的物体,其类别及示例标注如图3 所示。在实验开始之前,首先对MOT16 数据集提供的标注数据按照YOLOV3 数据格式进行调整计算,然后随机获取该实验的训练集和测试集数据。
3.2.2 实验参数
本实验选取的环境是Pytorch 框架,所用的模型是改进的YOLOV3 目标检测算法。训练时批量(batch-size)设置为16,图像大小默认设置为416×416,输入通道数为3,动量值(momentum)设置为0.9,学习率(learning_rate)设置为0.001。首先,将处理好的数据集先用YOLOV3 原模型进行目标检测,得到一组检测结果。然后,将聚类分析的结果应用到改进后的YOLOV3 模型中,并更新其损失函数后进行目标检测,得到的检测结果与YOLOV3 原模型进行实验对比,观察改进后的检测模型针对多尺度且多姿态行人检测中存在的问题优化效果及性能。
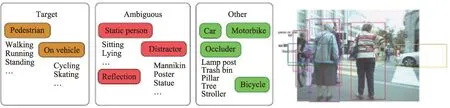
Fig.3 Examples of MOT data set categories and labels图3 MOT 数据集类别及标注示例
3.2.3 实验结果
首先,针对行人检测数据集利用K-means 算法进行聚类分析,得到适应于行人检测数据集的候选框尺寸。在聚类过程中,将K-means 算法的K值设置为12,依据不同标注框值决定的距离度量方法进行分簇,经过迭代后,得到数据集的候选框聚类结果。在这里选择K=12,一是因为网络结构具有4 个尺度检测层,而每个检测层具有3 类候选框,从而在聚类分析时选择划分为12 类候选框。二是通过设定不同的K值进行聚类分析,发现相比于YOLOV3 检测算法的原数据集设定K=9,在MOT16 数据集上设定K=12 时经过迭代后其损失值较小,说明进行检测算法前针对不同的数据集进行K-means 聚类分析的效果是有优势的,具有客观性。之后,按照特征图越大,感受野越小,对小目标相对敏感和特征图越小,感受野越大,对大目标相对敏感的原则,将得到的候选框尺寸分别应用到网络不同尺度检测层中,其结果如表1 所示。
进入初产期的柚果树座果率低,树体营养过旺,容易促发夏梢萌发。如果没有及时抹去夏芽,会导致梢果争肥,引发落果。因此,控制夏芽有利于提高四季柚座果率。
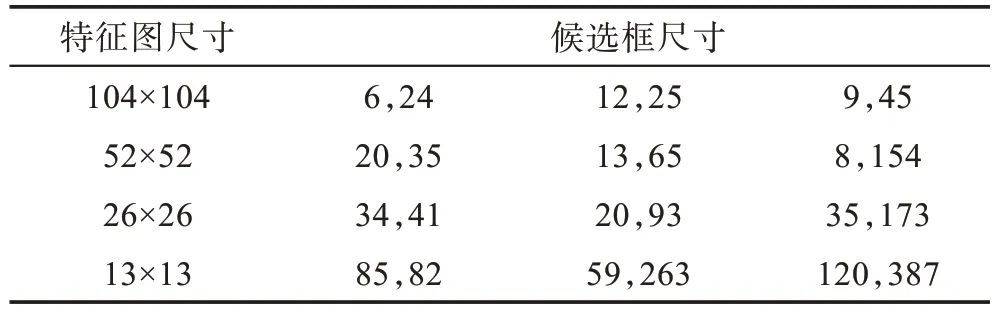
Table 1 Candidate box size after clustering表1 聚类后候选框尺寸大小
从表1 中数据可以看出,相对104×104 和52×52特征图层偏重于对数据集中小目标的检测力度,而26×26,13×13 则兼顾中等或较大尺寸的物体检测。通过结合不同细粒度特征,增强网络对多尺度行人检测的鲁棒性。
在候选框聚类结果的基础上,将表1 的候选框尺寸替换原来网络层的候选框尺寸,替换后的网络模型称为YOLOV3_105。为了验证改进后模型的性能,将YOLOV3 网络模型,增加104×104 特征检测层的YOLOV3_104 网络模型和应用聚类得到的候选框尺寸的YOLOV3_105 网络模型三者进行实验对比,其在MOT16 数据集检测结果AP(average precision)值如表2 所示。
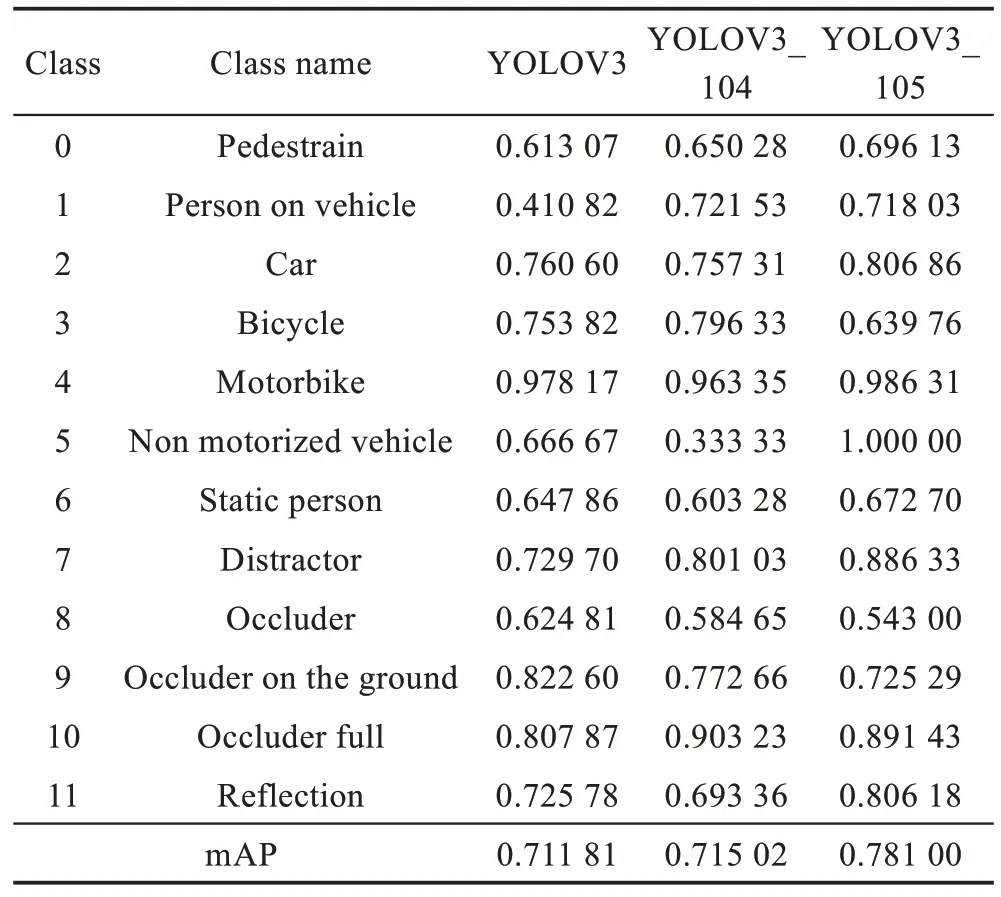
Table 2 Comparison of detection results AP of different network models表2 不同网络模型检测结果AP 比较
从表2 中数据可以看出,相比YOLOV3 网络模型,增加104×104 特征检测层的YOLOV3_104 在该数据集上多尺度行人的检测效果有明显提高,但整体检测平均准确率相对提高了0.004。而增加了特征检测层同时应用聚类得到的候选框尺寸的YOLOV3_105 网络,相对YOLOV3 网络模型,在MOT16 数据集上不仅提高了多尺度和多姿态行人的检测效果,同时对该数据集的其他标注类别检测效果也有所提高,因此整体检测平均准确率相对提高了约0.07。由此可以看出,改进后的YOLOV3_105网络模型对多尺度和多姿态的行人检测效果优于YOLOV3,该网络模型通过利用残差思想和上采样操作融合了多级特征图,让不同细粒度的特征参与行人检测,从而解决了该数据集中行人目标多尺度和多姿态的问题,提高了目标的检测效果。
为了验证应用斥力损失的损失函数能否有效解决数据集中出现的人与周围目标物体互相遮挡的问题,在YOLOV3_105 网络基础上,添加斥力损失更新其损失函数,将该网络模型称为YOLOV3_106,其在MOT16 数据集检测效果如表3 所示。
数据集的8、9、10 类别代表被遮挡的类别,代表数据集中部分被遮挡的目标,相比于表2 的YOLOV3检测模型进行数据对比,可以看出,相比于普通遮挡,引入斥力损失函数的YOLOV3_106 模型的检测结果对比YOLOV3 模型的检测结果并没有体现出优势,但对于严重遮挡情况(occluder full)来说,YOLOV3_106 模型相比于YOLOV3 模型检测准确率提高了大约0.12。并且从表中数据可以看出,增加斥力作用的损失函数,整体提高了数据集的检测准确率,相比YOLOV3 网络模型,其平均准确率提高了大约0.1,说明在一定程度上缓解了数据集因目标间遮挡出现的误检、漏检或漏召回问题,提高了网络模型的检测效果。
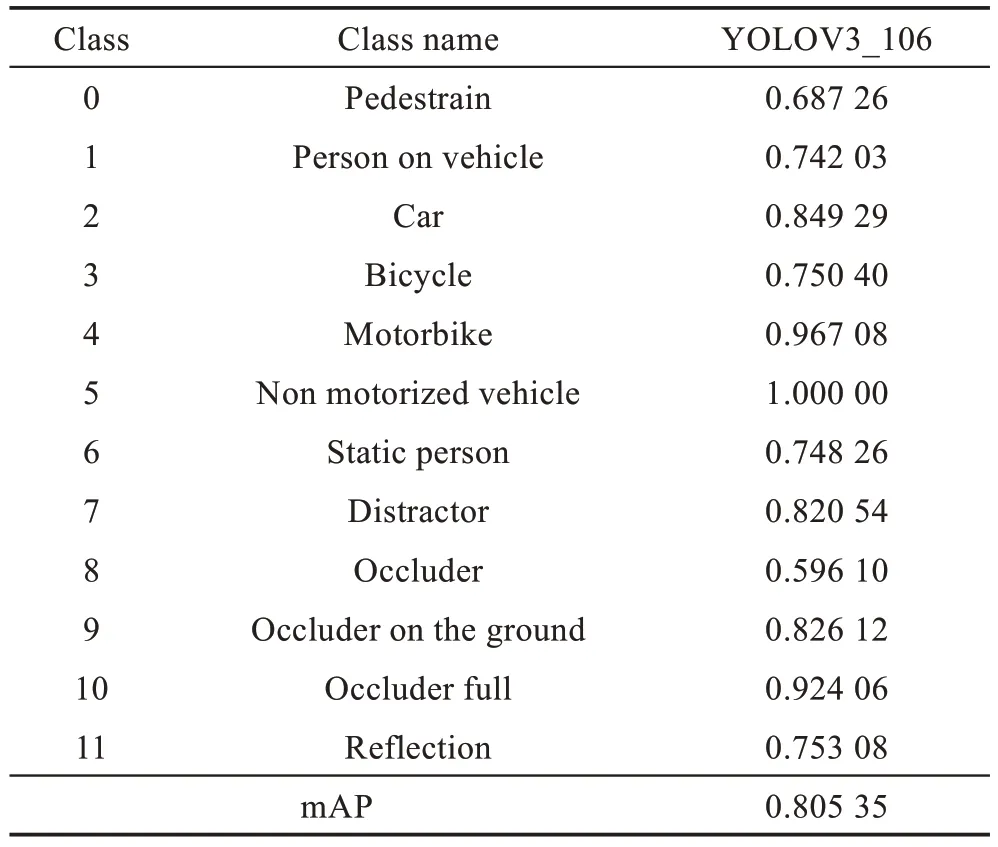
Table 3 Detection results AP of YOLOV3_106 network表3 YOLOV3_106 网络检测结果AP
为了进一步比较YOLOV3网络模型及YOLOV3_104、YOLOV3_105、YOLOV3_106 网络模型目标检测性能,截取训练过程中loss 值变化情况,其loss 值变化如图4 所示。

Fig.4 Change of loss value of different network models图4 不同网络模型loss值变化
同时,将YOLOV3、YOLOV3_104、YOLOV3_105及YOLOV3_106 网络模型的部分目标检测图片的预测框在图中标注出来,进行可视化展示比较。为了验证各个模型的性能,首先将数据集中图片真实边界框的值进行计算,并在图中进行标注,得到标注好真实框的数据集。同时,利用训练好的YOLOV3、YOLOV3_104、YOLOV3_105 和YOLOV3_106 模型对数据集进行检测,得到标注好预测框的数据集,其部分检测结果如图5~图8 所示。其中,图5、图7 表示数据集标注的真实边界框的图像,图6、图8 表示不同网络模型标注预测框的图像,其中图像中标注目标的边框的颜色是随机产生的,同一图像中的不同颜色代表数据集中的不同类别。

Fig.5 Real box example 1图5 真实框示例1

Fig.6 Example 1 detection results图6 示例1 检测结果
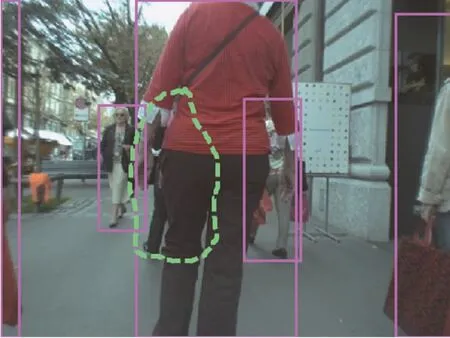
Fig.7 Real box example 2图7 真实框示例2

Fig.8 Example 2 detection results图8 示例2 检测结果
另外,YOLOV3_104 是在YOLOV3 模型基础上添加104×104 尺度检测层,其对小目标检测比较敏感,但对行人检测数据集并不完全适应,因此在YOLOV3_104 基础上进行边界框聚类分析后的网络模型YOLOV3_105 和YOLOV3_106 对行人检测数据集具有很好的鲁棒性,能够准确检测出图像中的行人及遮挡目标。从图6 中可以看出,YOLOV3_106网络模型能够检测出在YOLOV3 网络模型中未被检测到的遮挡的目标(图中虚线圈出的目标),因为引入的斥力损失函数,在保证预测框向目标的真实框靠近的同时,还增大了预测框与其周围非负责框的距离,尤其当出现遮挡情况时,使得两遮挡目标的预测框呈现尽可能远的趋势,从而降低了模型的误检和漏检率。虽然在图7 中没有标注遮挡严重的目标(虚线标注出的部分),但仍被训练好的网络模型检测并标注,结果如图8 所示,说明YOLOV3_105 和YOLOV3_106 具有很好的网络学习能力。
4 结论
针对行人目标检测存在的多尺度和多姿态的问题,在YOLOV3 算法的基础上,通过添加104×104 尺度检测层增加网络对小目标检测的敏感性。之后,通过K-means 聚类分析得到适用于行人目标检测数据集的边界框尺寸,用于目标检测以提高其网络性能。同时,通过利用边界框间的斥力作用更新模型的损失函数,改善目标遮挡影响以提高检测效果。实验结果证明,改进的YOLOV3_105 和YOLOV3_106 网络模型在行人检测数据集上的准确率分别为78.10%和80.53%,同YOLOV3 网络模型比较,具有较好的检测性能和鲁棒性,证明了方法的有效性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
社会科学战线(2022年7期)2022-08-26
汽车实用技术(2022年4期)2022-03-07
意林(2021年5期)2021-04-18
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
雕塑(2000年2期)2000-06-22
