
基于深度学习SERA-Net网络的糖网病病变检测模型研究
2021-01-13 05:04张荣芬宋鑫蔡乾宏刘宇红
贵州大学学报(自然科学版) 2021年6期
张荣芬 宋鑫 蔡乾宏 刘宇红





摘 要:为了对糖尿病视网膜病变的严重程度进行更准确的分类,提出了一种基于深度学习的糖尿病视网膜病变(diabetic retinopathy, DR)程度分级模型SERA-Net。首先,对输入的眼底图像使用主干网络SE-ResNeXt-50进行特征提取,避免了网络深度和宽度不断增加所导致的模型收益递减,在保证网络参数的情况下增加了模型的准确率。其次,将提取到的特征图输入Attention-Net,利用通道注意力和空间注意力相互促进,让网络在关注有用特征信息的同时忽略无用的背景噪音信息,使得DR分级结果更准确。再次,将特征图和注意力图通过乘法操作进行融合得到掩膜,进一步将注意力图和掩膜各自全局平均池化后再将两者的池化结果相除。最后,通过Softmax函数对结果进行五分类。实验结果表明:所得模型在EyePACE数据集上测试的二次加权Kappa分数为0.760 6、分类准确度的平均值(average of classification accuracy, ACA)为0.557 4、平均ROC曲线下的面积(area under curve, AUC)为0.871 9,在糖尿病视网膜病变五分类任务里拥有较好的分类性能。
关键词:糖尿病视网膜病变分级;深度学习;注意力机制
中图分类号:TP391 文献标志码:A
随着信息技术和经济的快速发展,人们的生活水平越来越高,生活方式也发生了很大的变化。近年来,电子产品已经成为现代人生活中不可分割的一部分,通过手机可以点外卖、打车、看电视,通过平板电脑可以进行线上学习,通过笔记本电脑可以线上办公,可以说人们每天都会花大量时间来与电子产品打交道。但是这种长时间与手机电脑做伴的现代生活方式,导致长期运动量不足,加之高糖分、高热量的饮食习惯,导致糖尿病患病率逐年上升。糖尿病会引起多种并发症,糖尿病视网膜病变(diabetic retinopathy, DR)又称糖网病即为其中之一。它是糖尿病常见的微血管并发症,是指由糖尿病导致视网膜微血管损害所引起的一系列病变,严重会造成人视力低下及失明[1-2]。一个人患糖尿病时间越长,引发糖网病的几率就越大。研究发现,提前发现和早期预防是防止糖尿病视网膜病变造成视力障碍和失明的主要方法[3]。
糖网病患者视网膜上的病变包括视网膜出血、渗出物、糖尿病性黄斑水肿、棉絮斑、静脉或动脉病变等[4]。一般根据病变特征的大小、位置、类型等进行糖网病病变等级的划分,按其严重程度划分为正常、轻度、中度、重度和增殖型糖网病[5]。轻度糖网病仅能在眼底图像上观察到微血管瘤,中度糖网病患者的眼底图像上会观察到渗出和轻微出血。到了重度糖网病时期,视网膜上出现棉絮斑,微血管瘤增多,不久之后就会发展为增殖型糖网病,导致弱视及失明。目前,临床的糖网病筛查主要是依靠有经验的眼科专家对病变图像进行人工筛查,其检测流程复杂,对医生临床经验和专业素养要求较高。我国糖尿病患者群体庞大,给有限的医疗资源带来极大的压力。若能在早期对眼底图像进行自动化分析与病变分级检测,则可以为患者节省大量的时间,还可以减轻医疗体系的负担,具有重大的研究意义。
近年来,随着机器学习[6]及深度学习在医疗图像分类任务中取得显著成果,基于深度学习方法的糖尿病视网膜病变检测方法被不同学者相继提出。主流方法有两类:第一类是使用局部病变特征(如微动脉瘤、出血等)的位置信息来确定糖网病的等级。例如PRATT等[7]搭建了具有数据增强功能的卷积神经网络(convolutional neural networks, CNN)网络结构,能够在分类过程中识别微动脉瘤、渗出液及出血等复杂病变特征,从而实现自动诊断分类。VAN GRINSVEN等[8]通过动态选择错误分类的阴性样本进行出血检测,加快了模型训练的速度。DAI等[9]利用文本报告和彩色眼底图像的专业知识,提出了一种用于微动脉瘤检测的多模式框架。YANG等[10]使用微动脉瘤出血和渗出液的位置信息,设计了一个两阶段病变检测与分类框架。LIN等[11]提出了一种先提取病变特征信息,然后将提取的特征信息与原始图像融合的DR分级网络。第二类则是基于全局图像的监督训练分类模型来对DR进行分级。GULSHAN等[12]提出了使用Inception-V3网络对DR进行分级。BRAVO等[13]使用了VGG16和Inception-V4预训练模型,并对糖网病分类。GARGEYA等[14]设计了基于CNN的DR严重性检测模型。WANG等[15]使用注意力机制着重关注可疑区域,并根据整幅图像以及可疑的病变斑块准确预测疾病等级。连先峰等[16]提出一种基于多特征融合的深度学习视网膜病变图像识别方法,增强模型的特征提取能力。总的来说,基于局部病变特征的深度学习分类方法需要提取眼底图像中的病变特征,能为DR分级提供合理的依据。而全局图像的深度学习分类方法省去了复杂的特征提取步骤,使得模型的泛化能力更强,分类效果更好。
本文提出了一种新颖的DR五分类SERA-Net模型。该模型通过将ResNeXt-50、SE-Net和Attention-Net结合,实现了空间注意力机制和通道注意力机制的相互促进,使网络更加关注眼底图像的病变特征而忽略背景噪音,分级结果更准确。
1 病变分类的网络模型设计
1.1 整体结构设计
本文DR病变检测的五分类SERA-Net模型选用SE-ResNeXt-50为主干网络。SERA-Net模型网络结构如图1所示。
SE-ResNeXt-50結构是在每个残差ResNeXt单元都结合了SE-Net模块的一种结构。对输入眼底图像预处理,用SE-ResNeXt-50结构提取图像的特征得到特征图F,之后将特征图F输入到Attention-Net模块中生成注意力图A。接着将特征图F和注意力图A逐元素相乘得到掩膜M,将注意力图A和掩膜M分别进行全局平均池化(global average pooling, GPA)操作,并将池化结果进行逐元素相除。最后逐元素相除的结果通过Softmax层输出分类的结果。整个模型可以用公式表示为
当网络深度逐渐增加时,分类结果的准确率会随之提升;但是当网络深度达到一定的程度,网络深度的继续增加可能会导致在反向传播过程中出现梯度消失与梯度爆炸等问题,引发准确率的下降。这种问题称为网络的退化。为了解决网络退化的问题,何凯明等在2015年提出了ResNet[17]的网络结构。ResNet引入了恒等映射的思想,将浅层的特征与更深层的特征进行特征融合,可以有效解决网络退化等问题。
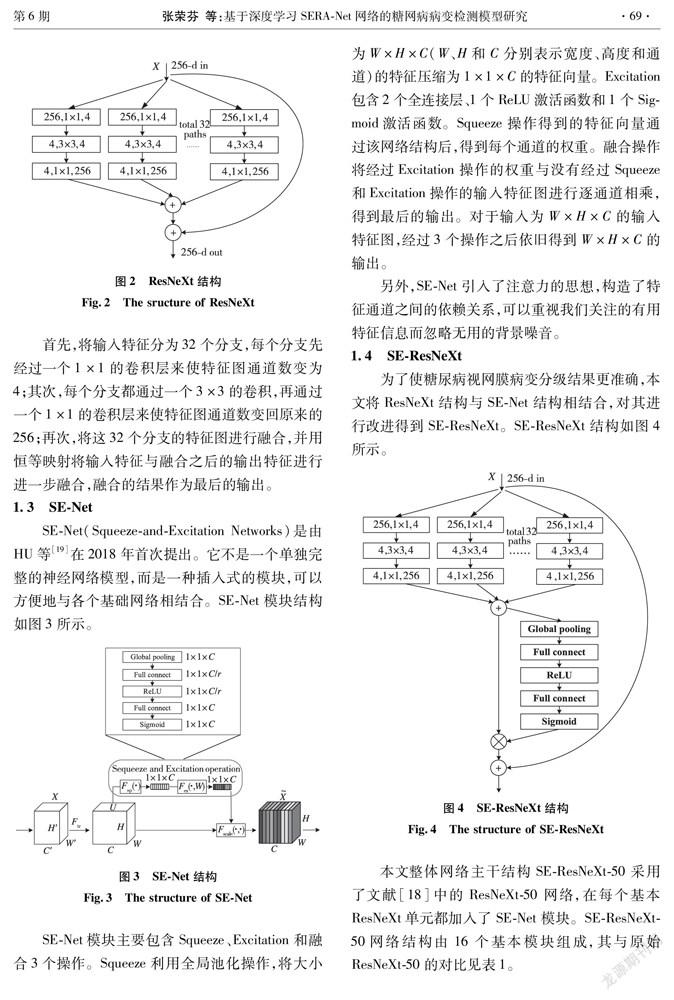
多分支聚合转换残差网络ResNeXt[18]与ResNet结构相似,使用了ResNet最经典的恒等映射结构,并且以可扩展的方式使用了split-transform-merge策略,可在不增加参数的情况下提升模型准确率。ResNeXt结构如图2所示。
首先,将输入特征分为32个分支,每个分支先经过一个1×1的卷积层来使特征图通道数变为4;其次,每个分支都通过一个3×3的卷积,再通过一个1×1的卷积层来使特征图通道数变回原来的256;再次,将这32个分支的特征图进行融合,并用恒等映射将输入特征与融合之后的输出特征进行进一步融合,融合的结果作为最后的输出。
1.3 SE-Net
SE-Net(Squeeze-and-Excitation Networks)是由HU等 [19]在2018年首次提出。它不是一个单独完整的神经网络模型,而是一种插入式的模块,可以方便地与各个基础网络相结合。SE-Net模块结构如图3所示。
SE-Net模块主要包含Squeeze、Excitation和融合3个操作。Squeeze利用全局池化操作,将大小为W×H×C(W、H和C分别表示宽度、高度和通道)的特征压缩为1×1×C的特征向量。Excitation包含2个全连接层、1个ReLU激活函数和1个Sigmoid激活函数。Squeeze操作得到的特征向量通过该网络结构后,得到每个通道的权重。融合操作将经过Excitation操作的权重与没有经过Squeeze和Excitation操作的输入特征图进行逐通道相乘,得到最后的输出。对于输入为W×H×C的输入特征图,经过3个操作之后依旧得到W×H×C的输出。
另外,SE-Net引入了注意力的思想,构造了特征通道之间的依赖关系,可以重视我们关注的有用特征信息而忽略无用的背景噪音。
1.4 SE-ResNeXt
为了使糖尿病视网膜病变分级结果更准确,本文将ResNeXt结构与SE-Net结构相结合,对其进行改进得到SE-ResNeXt。SE-ResNeXt结构如图4所示。
本文整体网络主干结构SE-ResNeXt-50采用了文献[18]中的ResNeXt-50网络,在每个基本ResNeXt单元都加入了SE-Net模块。SE-ResNeXt-50网络结构由16个基本模块组成,其与原始ResNeXt-50的对比见表1。
1.5 Attention-Net
由于眼底视网膜图像结构复杂,包括黄斑、正常的血管等结构,因此,细粒度对眼底图像的病变特征提取非常重要。本文引入了注意力模块,让网络在关注有用特征信息的同时忽略无用的背景噪音信息,从而提高结果的准确性。
本文的注意力模块如图5所示。输入图片先经过1个Batch Norm层正则化,再经过5个大小为1×1的卷积层输出,其中前4个1×1卷积层后面连接1个ReLU激活函数。通过Attention-Net和SE-Net的融合,实现了空间注意力和通道注意力的相互促进,将网络训练的重点集中在眼底图像的病变区域,可以更好地学习DR的病变特征,从而提升网络的分类性能。
2 设计损失函数
将上述网络模型提取出的特征图输入Softmax函数,数据被分为5类。由于DR数据集间分布极其不平衡(表2),没有病的眼底图像要远多于患有糖尿病视网膜病变的眼底图像,因此,以往的损失函数如交叉熵损失函数不能区分类别之间的距离,而各个样本的权重是一样的,这使得DR图像分级结果不理想。
为了缓解数据失衡问题以及减少精度损失,本文选用分级损失函数[20],这是一种为softmax函数增加权重的损失函数设计方法。分级损失函数公式如下:
式中:L为DR分级的损失函数;weighty通过除以S对权重进行归一化;L为经过Softmax层之后的损失函数; S为所有类别中样本的总和;x为训练样本的类别;y为预测值(y∈[0,C-1]);N为类别数量。分级损失函数通过预测x和y之间的最大差值来计算类别之间的距离。在DR分级任务中,病变等级分为0~4这5个等级,采用上述增加权重的分级损失函数时,将第0级错误地归类为第4级会比归类为第1级付出更大的代价(错误权重分别为5/15和1/15)。
3 数据集与图像预处理
3.1 数据集
本文使用的EyePACE数据集来自Kaggle中的“糖尿病视网膜病变检测竞赛”,https://www.kaggle.com/c/diabeticretinopathy-detection。该数据集包含了2组数量非常多且在不同成像条件下拍摄的高分辨率视网膜眼底图像。其中,有35 126张公开评级的训练眼底图像和53 576张未公开评级的测试图片,并且数据集中每一张右眼图像都有一张相对应的左眼图像;这些图像尺寸从289×433像素到3 456×5 184像素;每一张眼底图像都给出了病变等级标签,其标签值为{0,1,2,3,4},病变严重程度从0(正常)到4(增殖性DR)依次加重。EyePACE數据集训练集的数据分布情况见表2。从表2可以看出,EyePACE数据集的确高度不平衡,其中大多数图像都属于第一类(无DR)。
本文的训练、验证和测试使用EyePACE公开的35 126张图像数据集,包含0级图片25 810张,1级图片2 443张,2级图片5 292张,3级图片873张,4级图片708张。图像数据集按照3∶1∶1的比例划分为训练集、验证集和测试集,其中测试集不参与训练。每张图片根据糖网病的严重程度标记为{0,1,2,3,4}5个等级,如图6所示。
3.2 图像预处理
在糖尿病视网膜图片的采集过程中,由于成像环境、图片采集设备以及操作人员的技术差距等客观因素的影响,获取到的眼底图像在亮度、对比度以及分辨率大小上会有较大的差距。因此,在将彩色眼底图像输入网络进行训练之前,应该先对数据集进行预处理操作。
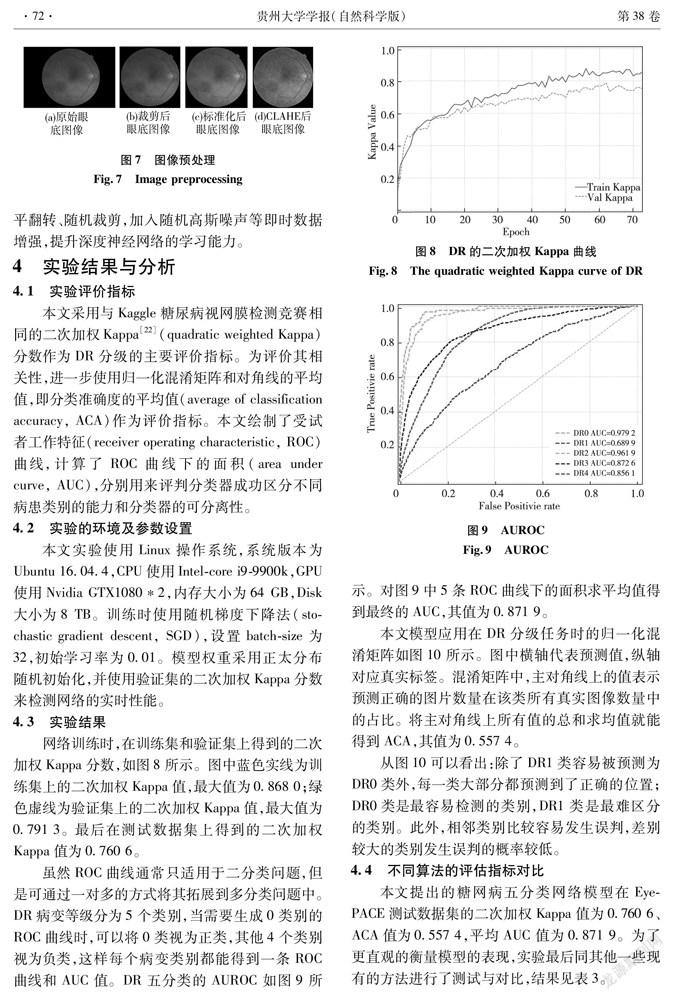
EyePACE数据集图像分辨率不一样,先裁剪原始图片周围的黑色边框来缩小图片宽度,将图片分辨率调整为512×512;然后对所有图片进行减去均值后除以标准差的操作,实现RGB三个通道上的标准化;最后使用CLAHE[21]增强病理特征与背景之间的对比度。如图7所示,(a)是分辨率为1 520×960的原始眼底图像,(b)为裁剪掉黑色边框后尺寸为512×512的图像,(c)为标准化后的眼底图像,(d)为经过CLAHE操作后的眼底图像。由图7可见,经过预处理之后的眼底图像,病变特征更为明显。
同时,为了防止有限训练数据带来的过拟合,还需对实验中每个epoch的所有训练图片进行水平翻转、随机裁剪,加入随机高斯噪声等即时数据增强,提升深度神经网络的学习能力。
4 实验结果与分析
4.1 实验评价指标
本文采用与Kaggle糖尿病视网膜检测竞赛相同的二次加权Kappa[22](quadratic weighted Kappa)分数作为DR分级的主要评价指标。为评价其相关性,进一步使用归一化混淆矩阵和对角线的平均值,即分类准确度的平均值(average of classification accuracy, ACA)作为评价指标。本文绘制了受试者工作特征(receiver operating characteristic, ROC)曲线,计算了ROC曲线下的面积(area under curve, AUC),分别用来评判分类器成功区分不同病患类别的能力和分类器的可分离性。
4.2 实验的环境及参数设置
本文实验使用Linux操作系统,系统版本为Ubuntu 16.04.4,CPU使用Intel-core i9-9900k,GPU使用Nvidia GTX1080*2,内存大小为64 GB,Disk大小为8 TB。训练时使用随机梯度下降法(stochastic gradient descent, SGD),设置batch-size为32,初始学习率为0.01。模型权重采用正太分布随机初始化,并使用验证集的二次加权Kappa分数来检测网络的实时性能。
4.3 实验结果
网络训练时,在训练集和验证集上得到的二次加权Kappa分数,如图8所示。图中蓝色实线为训练集上的二次加权Kappa值,最大值为0.868 0;绿色虚线为验证集上的二次加权Kappa值,最大值为0.791 3。最后在测试数据集上得到的二次加权Kappa值为0.760 6。
虽然ROC曲线通常只适用于二分类问题,但是可通过一对多的方式将其拓展到多分类问题中。DR病变等级分为5个类别,当需要生成0类别的ROC曲线时,可以将0类视为正类,其他4个类别视为负类,这样每个病变类别都能得到一条ROC曲线和AUC值。DR五分类的AUROC如图9所示。对图9中5条ROC曲线下的面积求平均值得到最終的AUC,其值为0.871 9。
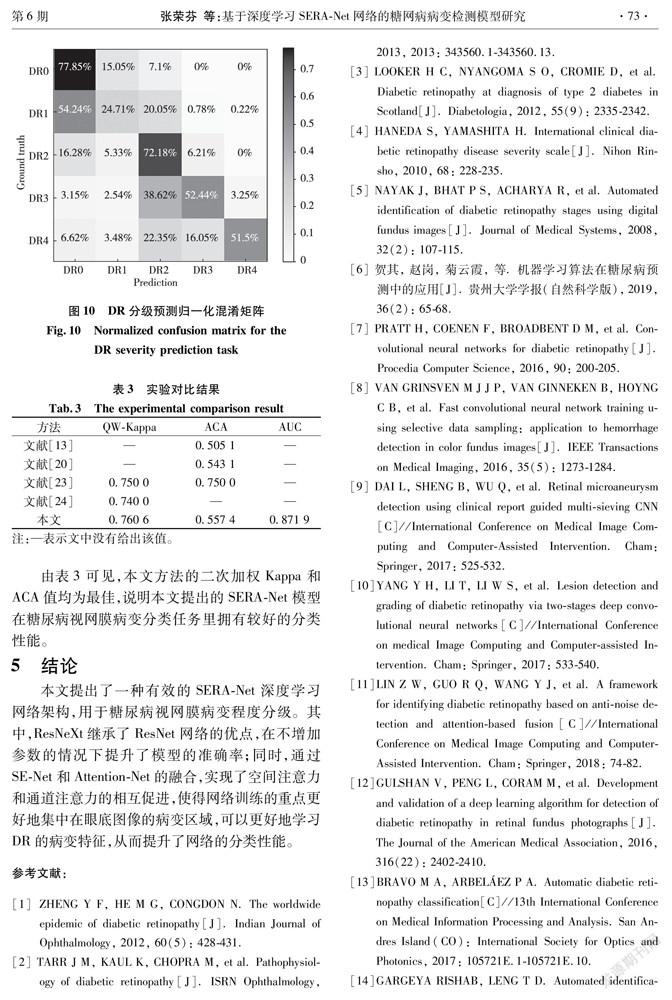
本文模型应用在DR分级任务时的归一化混淆矩阵如图10所示。图中横轴代表预测值,纵轴对应真实标签。混淆矩阵中,主对角线上的值表示预测正确的图片数量在该类所有真实图像数量中的占比。将主对角线上所有值的总和求均值就能得到ACA,其值为0.557 4。
从图10可以看出:除了DR1类容易被预测为DR0类外,每一类大部分都预测到了正确的位置;DR0类是最容易检测的类别,DR1类是最难区分的类别。此外,相邻类别比较容易发生误判,差别较大的类别发生误判的概率较低。
4.4 不同算法的评估指标对比
本文提出的糖网病五分类网络模型在EyePACE测试数据集的二次加权Kappa值为0.760 6、ACA值为0.557 4,平均AUC值为0.871 9。为了更直观的衡量模型的表现,实验最后同其他一些现有的方法进行了测试与对比,结果见表3。
由表3可见,本文方法的二次加权Kappa和ACA值均为最佳,说明本文提出的SERA-Net模型在糖尿病视网膜病变分类任务里拥有较好的分类性能。
5 结论
本文提出了一种有效的SERA-Net深度学习网络架构,用于糖尿病视网膜病变程度分级。其中,ResNeXt继承了ResNet网络的优点,在不增加参数的情况下提升了模型的准确率;同时,通过SE-Net和Attention-Net的融合,实现了空间注意力和通道注意力的相互促进,使得网络训练的重点更好地集中在眼底图像的病变区域,可以更好地学习DR的病变特征,从而提升了网络的分类性能。参考文献:
[1]ZHENG Y F, HE M G, CONGDON N. The worldwide epidemic of diabetic retinopathy[J]. Indian Journal of Ophthalmology, 2012, 60(5): 428-431.
[2] TARR J M, KAUL K, CHOPRA M, et al. Pathophysiology of diabetic retinopathy[J]. ISRN Ophthalmology, 2013, 2013: 343560.1-343560.13.
[3] LOOKER H C, NYANGOMA S O, CROMIE D, et al. Diabetic retinopathy at diagnosis of type 2 diabetes in Scotland[J]. Diabetologia, 2012, 55(9): 2335-2342.
[4] HANEDA S, YAMASHITA H. International clinical diabetic retinopathy disease severity scale[J]. Nihon Rinsho, 2010, 68: 228-235.
[5] NAYAK J, BHAT P S, ACHARYA R, et al. Automated identification of diabetic retinopathy stages using digital fundus images[J]. Journal of Medical Systems, 2008, 32(2): 107-115.
[6] 賀其, 赵岗, 菊云霞, 等. 机器学习算法在糖尿病预测中的应用[J]. 贵州大学学报(自然科学版), 2019, 36(2): 65-68.
[7] PRATT H, COENEN F, BROADBENT D M, et al. Convolutional neural networks for diabetic retinopathy[J]. Procedia Computer Science, 2016, 90: 200-205.
[8] VAN GRINSVEN M J J P, VAN GINNEKEN B, HOYNG C B, et al. Fast convolutional neural network training using selective data sampling: application to hemorrhage detection in color fundus images[J]. IEEE Transactions on Medical Imaging, 2016, 35(5): 1273-1284.
[9] DAI L, SHENG B, WU Q, et al. Retinal microaneurysm detection using clinical report guided multi-sieving CNN[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2017: 525-532.
[10]YANG Y H, LI T, LI W S, et al. Lesion detection and grading of diabetic retinopathy via two-stages deep convolutional neural networks[C]//International Conference on medical Image Computing and Computer-assisted Intervention. Cham: Springer, 2017: 533-540.
[11]LIN Z W, GUO R Q, WANG Y J, et al. A framework for identifying diabetic retinopathy based on anti-noise detection and attention-based fusion[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2018: 74-82.
[12]GULSHAN V, PENG L, CORAM M, et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs[J]. The Journal of the American Medical Association, 2016, 316(22): 2402-2410.
[13]BRAVO M A, ARBELEZ P A. Automatic diabetic retinopathy classification[C]//13th International Conference on Medical Information Processing and Analysis. San Andres Island(CO): International Society for Optics and Photonics, 2017: 105721E.1-105721E.10.
[14]GARGEYA RISHAB, LENG T D. Automated identification of diabetic retinopathy using deep learning[J]. Ophthalmology, 2017, 124(7): 962-969.
[15]WANG Z, YIN Y X, SHI J P, et al. Zoom-in-net: Deep mining lesions for diabetic retinopathy detection[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2017: 267-275.
[16]連先峰, 刘志勇, 张琳, 等. 一种基于深度学习的视网膜病变图像识别方法[J]. 计算机应用与软件, 2021, 38(1): 179-185.
[17]HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// IEEE Conference on Computer Vision & Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016: 770-778
[18]LIN T Y, DOLLR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017: 1492-1500.
[19]HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 7132-7141.
[20]ZHAO Z Y, ZHANG K R, HAO X J, et al. Bira-net: bilinear attention net for diabetic retinopathy grading[C]//2019 IEEE International Conference on Image Processing (ICIP 2019). USA: IEEE, 2019: 1385-1389.
[21]REZA A M. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement[J]. Journal of VLSI Signal Processing Systems for Signal Image & Video Technology, 2004, 38(1):35-44.
[22]BEN-DAVID A. Comparison of classification accuracy using Cohen’s Weighted Kappa[J]. Expert Systems with Applications, 2008, 34(2): 825-832.
[23]ARA U′JO T, ARESTA G, MENDONA L, et al. DR| GRADUATE: Uncertainty-aware deep learning-based diabetic retinopathy grading in eye fundus images[J]. Medical Image Analysis, 2020, 63: 101715.
[24]DE LA TORRE J, PUIG D, VALLS A. Weighted kappa loss function for multi-class classification of ordinal data in deep learning[J]. Pattern Recognition Letters, 2018, 105: 144-154.
(责任编辑:周晓南)
Diabetic Retinopathy Detection Model Based on SERA-Net
ZHANG Rongfen SONG Xin CAI Qianhong LIU Yuhong
(College of Big Data and Information Engineering, Guizhou University, Guiyang 550025, China)
Abstract: In this paper, in order to classify the severity of diabetic retinopathy more accurately, we propose a degree grading model of diabetic retinopathy(DR) based on deep learning, which is named SERA-Net. First of all, the main network SE-ResNeXt-50 is used to extract the feature of the input image, which avoids the decreasing model revenue caused by the increasing depth and width of the network and increases the accuracy of the model while guaranteeing the network parameters. Furthermore, the extracted feature map is input to Attention-Net to make the channel attention and spatial attention in mutual promotion and pay more attention to useful feature information meanwhile ignoring useless, noisy background information, which obtains a more accurate classification result. Then, the feature map and attention map are fused by multiplication to obtain the mask, the global average pooling are followed to attention map and mask, and the results are divided latterly. Finally, the results are classified into five cagegories through Softmax function. The experimental results show that the quadratic weighted Kappa score on the EyePACE test dataset is 0.760 6, the ACA is 0.557 4, and the average AUC value is 0.871 9, which has great classification performance on DR severity classification task.
Key words: diabetic retinopathy classification; deep learning; attention mechanism
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
软件工程(2017年11期)2018-01-05
智能计算机与应用(2017年5期)2017-11-08
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
