
Tensorflow人脸识别系统设计 ①
2021-01-13 07:54赵厚科
佳木斯大学学报(自然科学版) 2020年4期
吴 晶, 赵厚科
(1.东北石油大学秦皇岛分校,河北 秦皇岛 066004;2.西南民族大学电气信息工程学院,四川 成都 610225)
0 引 言
一个基于深度学习的人脸识别系统是学习机器学习的最好的一个案例。系统是基于深度学习平台Tensorflow所搭建的人脸识别系统,通过摄像头获取视频,使用opencv自带的分类器定位人脸[1],并且在每一帧图像中截取人脸,使用卷积神经网络进行训练人脸识别。
1 模块功能和结构划分
系统共分为四个部分,实时人脸截取模块、图片处理模块、CNN搭建和训练模块以及测试模块。
实时人脸截取主要负责采集人脸图片,通过USB摄像头截取人脸数据,使用OpenCV定位人脸,同一数据格式,并最终保存人脸图片。
本地图片处理模块主要用于处理在网络上下载下来作为第三个分类类别使用的图片,其主要功能是将图片读入,使用opencv定位人脸,然后将人脸图片保存成我设定好的规格以便使用。
CNN搭建和训练模块主要完成搭建神经网络、划分训练集与测试集,深度学习训练,训练模型的保存,是整个系统的关键部分[2]。
测试部分主要来调用摄像头捕获人脸图片,然后读入之前保存好的训练成熟的网络模型进行识别。
2 项目原理
2.1 卷积神经网络
卷积神经网络是一种具有卷积运算和深度结构的前馈神经网络,是深度学习的典型算法之一。卷积神经网络具有表示学习能力,能够根据其层次结构对输入信息进行分类,基本框架见图1。
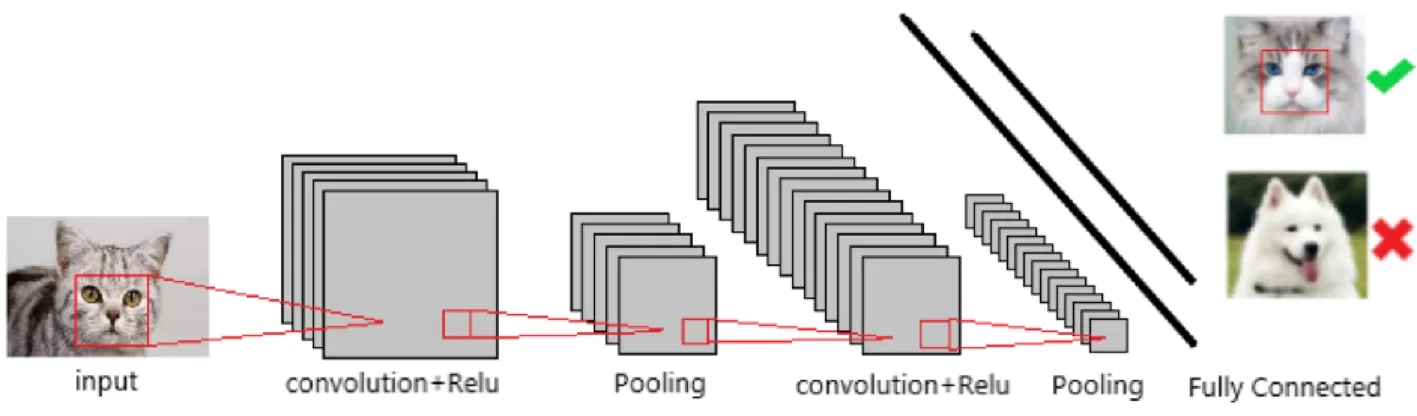
图1 卷积神经网络基本框架
2.1.1 卷积层
其中在卷积神经网络中存在着由许多卷积单元组成的卷积层[3],并且可以通过利用反向传播算法来优化各个卷积单元的参数。其中提取输入的不同特征是由卷积运算提供的,第一卷积层只能提取边缘、直线和角度等低级特征。更多的网络层可以迭代地从低级特征中提取更复杂的特征。可以将每个过滤器描绘成一个窗口,该窗口在图像的尺寸上滑动并检测属性。滤镜在图像上滑动的像素数量称为步幅。步幅为1意味着滤波器一次移动一个像素,其中2的步幅将向前跳过2个像素。
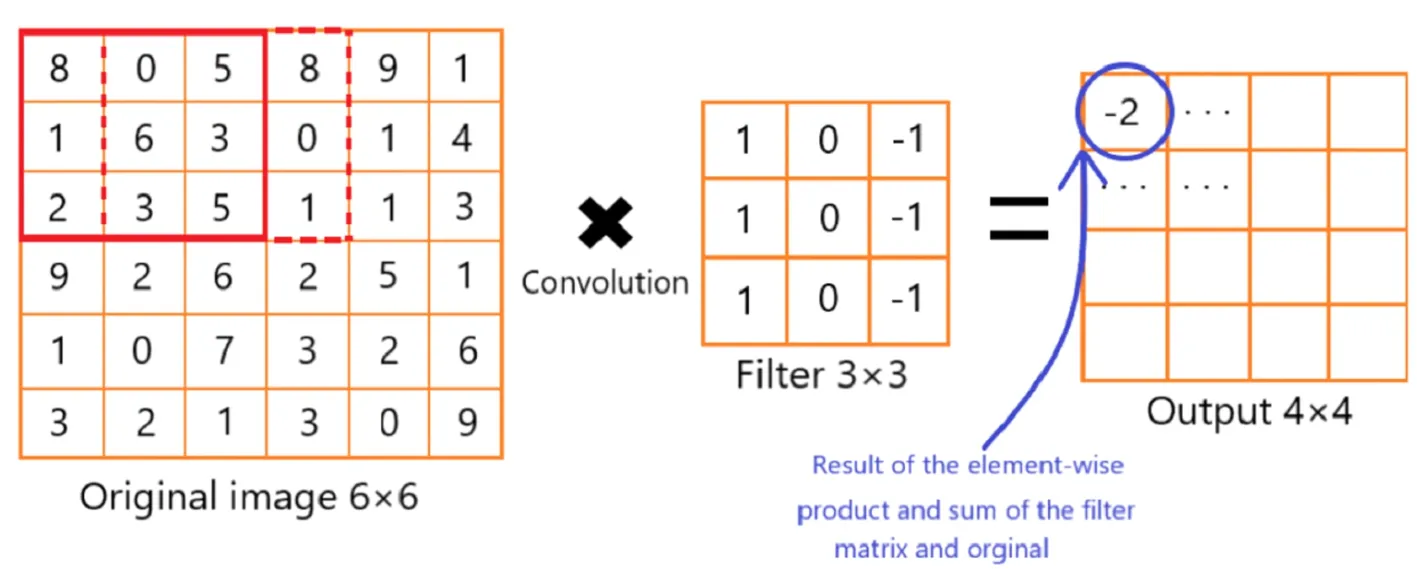
图2 提取特征向量并简化数据量
在图2所示的例子中,可以看到一个垂直线检测器。原始图像为6×6,它使用3×3滤镜进行扫描,步长为1,从而产生4×4尺寸输出。而过滤器仅对其视野左右列中的部分感兴趣。通过对图像的输入求和并乘以3×3滤波器的配置,得到8+1+2-5-3-2=-2。然后滤波器向右移动一步,然后计算0+6+3-8-0-1=0。0然后进入-2右侧的位置。此过程将持续到4×4网格完成为止。之后,下一个特征图将使用它自己的唯一过滤器/内核矩阵计算自己的值。
2.1.2 池化层
图3显示的池化层处理过程。池化层的目的是为了来进一步降低维度,通过聚合卷积层收集的值或所谓的子采样进行降维。除了为模型提供一些正则化的方案以避免过度拟合之外,这还将减少计算量。它们遵循与卷积层相同的滑动窗口思想,但不是计算所有值,而是选择其输入的最大值或平均值。这分别称为最大池化和平均池化。
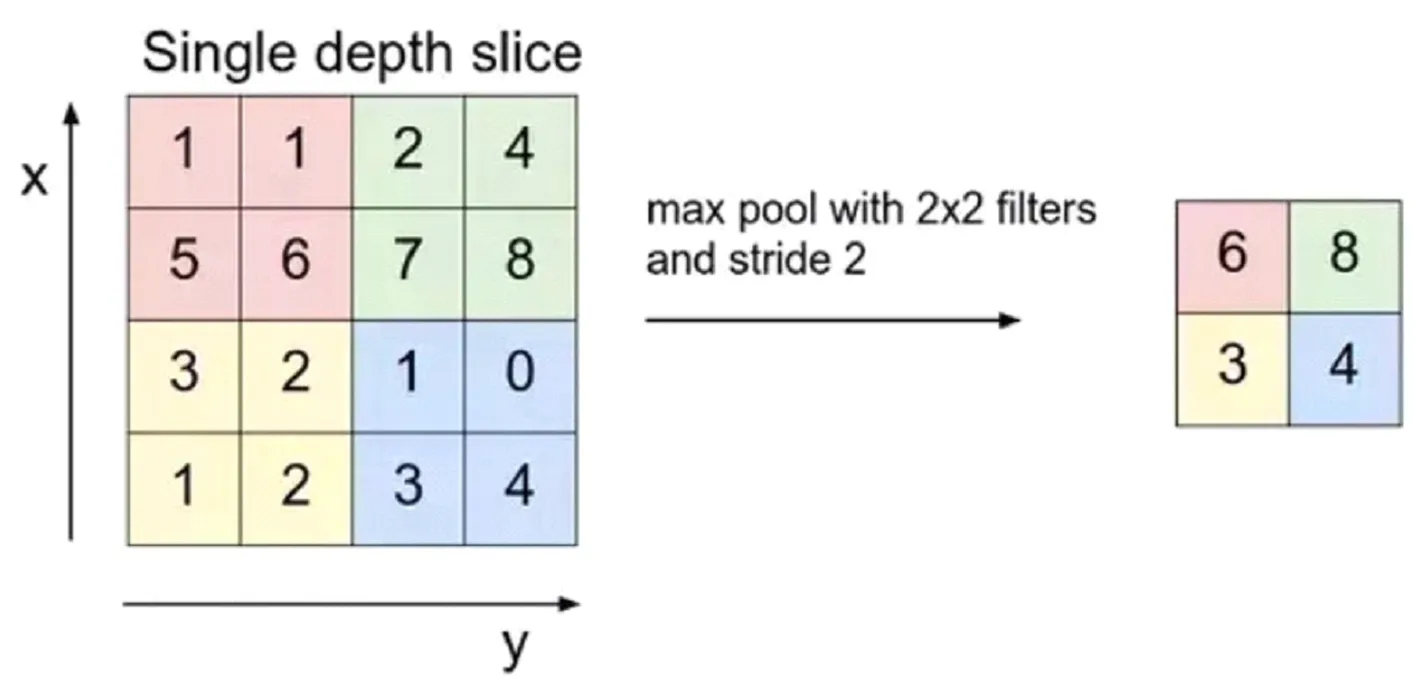
图3 池化层处理过程
这两个组件是卷积层的关键构建块。然后,通常会重复此方法,进一步减少特征图的大小尺寸,而且会增加其深度。每个特征图将专门识别它自己独特的形状。在卷积结束时,会放置一个完全连接的图层,其具有激活功能,例如Relu或Selu,用于将尺寸重新整形为适合的尺寸送入分类器。例如,如果你的最终转换层为3×3×128矩阵,但你只预测10个不同的类,则需要将其重新整形为1×1152向量,并在输入分类器之前逐渐减小其大小。完全连接的层也将学习它们自己的特征,见图4。
2.2 人脸识别分类器
2.2.1 Haar-like特征
Haar特征分为:边缘、线性、中心特征和对角线特征,这些特征相互组合成特征模板。特征模板内有白色和黑色两种矩形,模板的特征值定义为白色矩形和减去黑色矩形(在opencv实现中为黑色-白色)。
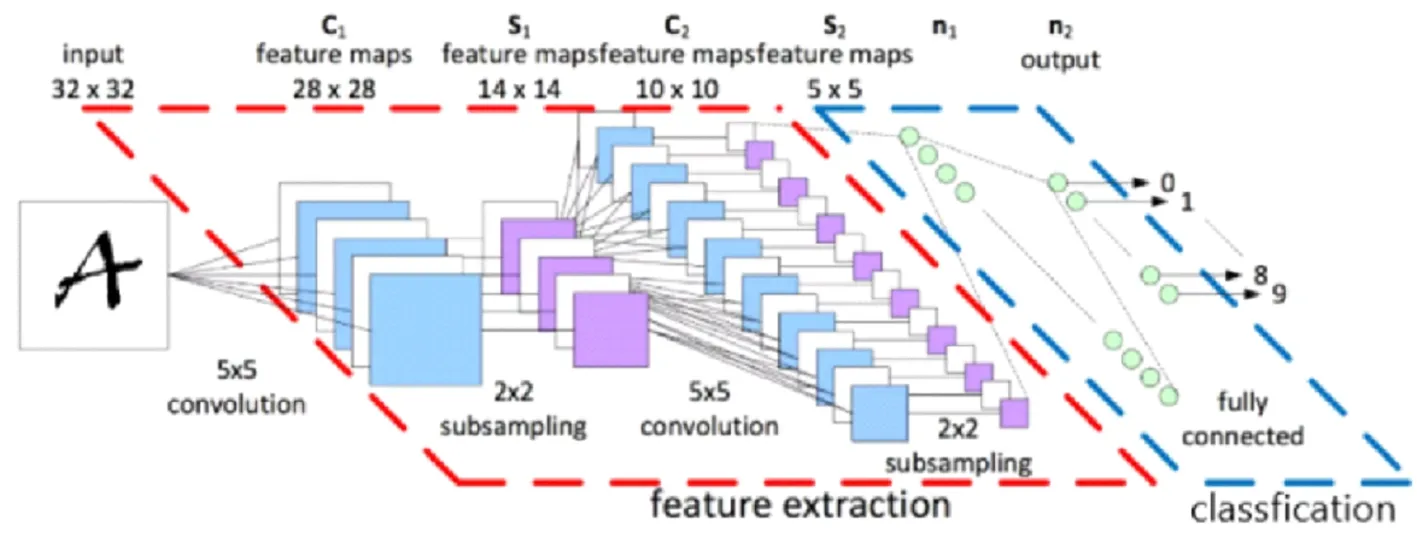
图4 神经网络框架总图
Haar的特征值反映了图像灰度的变化。例如,面部的某些特征可以简单地用矩形特征来说明,但是矩形特征只对一些简单的图形结构敏感,比如边缘和线段,所以这些特征模板只能描述特定方向,例如水平、垂直、倾斜的人脸结构。如果将这样的矩形设置在非人脸脸区域的话,计算出的特征值应该和脸部特征值有所不同,所以这些矩形为了区别脸部和非脸,去定量化脸部特征[4]。
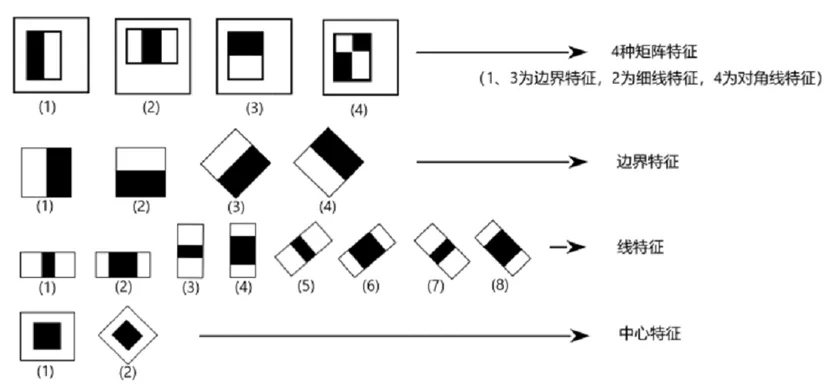
图5 人脸识别特征模板
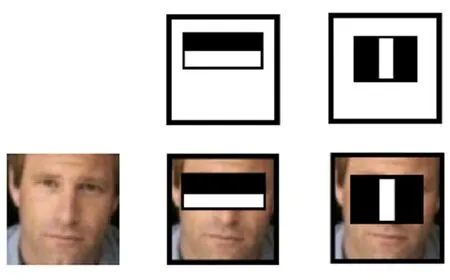
图6 矩形特征在人脸图像的特征匹配
2.2.2 特征模板
如图5所示,人脸的构造特征可以根据矩形的特征简单地描绘出来。例如,图6中眼睛比脸颊颜色深,鼻子的两侧比鼻子的梁颜色深,嘴唇比周围的颜色深等。
对于24×24像素分辨率的图像,矩阵特征的数量约为160000。此时,需要通过一种特定的算法来过滤合适的矩阵特征,并将它们组合成一个强分类器来检测人脸。
2.3 积分图
在得到矩形特征后,计算矩形特征的值。定义一个坐标为A(x,y)的积分图,这个积分图的定义是其人脸图像左上角的所有像素之和,因此,对每个像素进行少量计算就可以得到的“积分图”并且可以同时计算不同尺度的矩形特征值,从而大幅度的提高了计算效率。
对于图像中的点a(x,y),积分图被定义为ii(x,y):
其中i(x',y')为点(x',y')处的像素值。
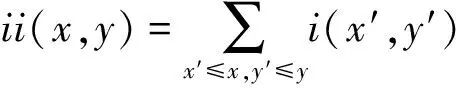
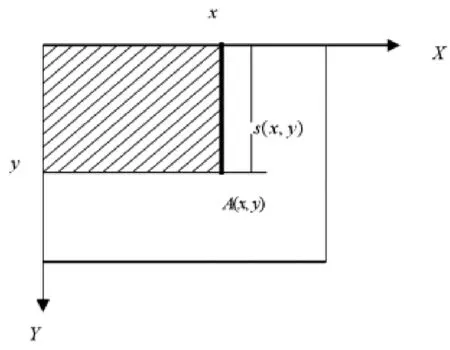
图7 积分图
坐标a(x,y)的积分图定义为左上角矩阵中所有像素的和,如图7阴影部分所示:
由此可以看出,要计算两个区域像素值之间的差(即计算矩形模板的特征值),只需使用特征区域端点的积分图进行简单的加减运算即可。积分图法可以快速计算矩形特征的特征值。
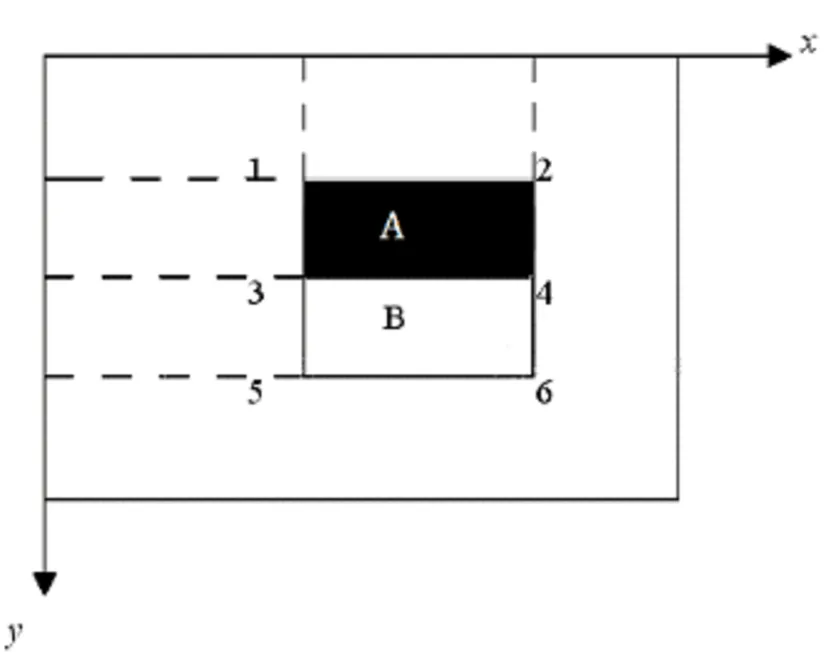
图8 特征模板的特征值计算原理图
如图8所示,特征模板的特征值 = pixel area(B)-pixel area(A) =[ii4 + ii1 - (ii2 + ii3)] -[ii6 + ii3 - (ii4 + ii5)]。
3 系统搭建
3.1 face-recognize.py(截取脸部数据用于训练)
选择用opencv来完成人脸截取。首先给opencv视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头(cv2.VideoCapture(camera_idx)),选择使用USB摄像头来进行实时截取。然后选择opencv自带的人脸识别分类器(haarcascade_frontalface_alt2.xml),之后循环来读取视频里每一帧的图像进行人脸截取。
首先把当前图像转换喂灰度图像,这样能大幅减少数据量,以便计算特征,然后开始进行人脸检测,调用classfier.detectMultiScale函数其中选取1.2为图片缩放比例,和2个检测有效点,其参数为grey, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32),当这个函数返回值的len长度大于0时检测到人脸然后保存到本地,当循环到达设定的要截取人脸数据量时退出循环。
3.2 face-dispose.py(处理下载的人脸数据库)
处理图片也用opencv大致步骤与第一步出不多,只是写2个循环来读取图片、处理图片、保存图片。把图片处理成64×64大小的图片,方便以后训练。
3.3 train_faces.py(训练模型)
学习平台选择Tensorflow2.0,并且导入opencv和sklearn,由于大部分功能都用不到Tf2.0的特性于是添加下面两行代码来让使用V1版本的功能import tensorflow.compat.v1 as tf和 tf.disable_v2_behavior()。接下来需要定义几个函数来实现一些功能,他们分别是:
def getPaddingSize(img):
此函数的作用是给2维图像一个坐标其中要用//整除符号,否则结果会进行偏移。函数返回 top, bottom, left, right。4个值。
def readData(path , h=size, w=size):此函数的主要功能是读取图片数据后先将图片放大, 扩充图片边缘部分,其次将图片数据与标签转换成数组、随机划分测试集与训练集,设置图片数据的总数,图片的高、宽、通道,接下来将数据转换成小于1的数,在此函数中设置一个图片块,每次取100张图片。
def weightVariable(shape):
权重变量,函数返回tf.Variable(tf.random_normal(shape, stddev=0.01))
def biasVariable(shape):
函数返回tf.Variable(tf.random_normal(shape))
def conv2d(x, W):2维的卷积层,用于图片的卷积, 输入图像的通道数= x (灰度图像),卷积核的种类数=W, 卷积核的shape是[1,1,1,1]的,padding = 'SAME'输入图片大小和输出图片大小是一致的。
def maxPool(x):
max pooling是CNN当中的最大值池化操作,函数返tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
def dropout(x, keep):
返回tf.nn.dropout(x, keep)
def cnnLayer():
第一层:卷积核大小(3,3),输入通道(3),输出通道(32),卷积,池化,减少过拟合,随机让某些权重不更新。
第二层:卷积核大小(3,3),输入通道(32),输出通道(64),卷积,池化,减少过拟合。
第三层:卷积核大小(3,3),输入通道(64),输出通道(64),卷积,池化,减少过拟合。
输出层:二维张量,1*512矩阵卷积,共2个卷积,对应开始的ys长度为2,最后的分类,结果为1*1*2softmax和sigmoid都是基于logistic分类算法,一个是多分类一个是二分类。
def cnnTrain():
开始数据训练以及评测,调用cnnLayer(),比较标签是否相等,再求的所有数的平均值,tf.cast(强制转换类型),将loss与accuracy保存以供tensorboard使用,数据保存器的初始化,开始循环,每次取128张图片,开始训练数据,同时训练三个变量,返回三个数据,打印损失,获取测试数据的准确率,准确率大于0.98时保存训练完成的模型,以便调用。
4 Distinguish.py(读取模型并验证模型)
在刚才train_faces.py的基础上再定义一个函数以便于验证模型,同样使用opencv来帮助验证模型,首先加载刚刚训练好的模型。
saver = tf.train.Saver()
sess = tf.Session()
saver.restore(sess, tf.train.latest_checkpoint('存放模型的目录'))
然后定义一个函数用来读取图像到模型中进行比对,是否为模型训练里的脸,并返回true或false。接下来就要调用opencv截取每一帧视频图像截取人脸作为参数传递给验证函数,并且在人脸框旁边显示这张脸人主人是谁。
5 结 语
此项目的最重要的部分有两个,首先是图片数据的处理,必须将图片处理成合适的大小来进行训练,这样能加快效率,其次是模型训练,这是整个项目的重中之重,这里总共用到了2个卷积,因为由于隐私问题不能随便使用别人的人脸数据,这里的数据主要是作者的人脸数据和少部分网上公开无版权纠纷的人脸数据库,数据不多,这个项目主要区分作者和其他人的脸,如果想训练模型识别多个人的人脸可以在数据处理时加几个循环,大体框架不变,训练时多几个变量即可完成项目。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
数学物理学报(2021年3期)2021-07-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
中学生数理化·八年级数学人教版(2020年4期)2020-10-29
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
动漫星空(2018年9期)2018-10-26
中学生数理化·八年级数学人教版(2017年4期)2017-07-08
