
Machine learning and geostatistical approaches for estimating aboveground biomass in Chinese subtropical forests
2021-01-11 07:08HuiyiSuWenjuanShenJingruiWangArshadAliandMingshiLi
Forest Ecosystems 2020年4期
Huiyi Su,Wenjuan Shen,Jingrui Wang,Arshad Ali and Mingshi Li,2*
Abstract
Keywords: Forest aboveground biomass, Random forest co-kriging, ALOS PALSAR, Landsat TM, National forest inventory, Digital elevation model
Introduction
Forests play an important role in global carbon cycling because they act as carbon sinks and sources for atmospheric CO2(Pan et al. 2011; Chave et al. 2014). Forest aboveground biomass (AGB) is an indicator for assessing forest ecosystem productivity and health and determining the potential for carbon storage and carbon sink, as well as an important parameter for estimating carbon emissions and disturbances caused by land use and climate change (Schulze 2006; Muukkonen and Heiskanen 2007; Baccini et al. 2017; Rodríguez-Soalleiro et al.2018). Currently, the most accurate methods for obtaining forest AGB are the use of site- and species-specific allometric equations based on measured forest biometric parameters, such as the diameter at breast height (DBH),height, crown closure, and stem density (Chave et al.2014; Ali et al. 2015; Paul et al. 2015). However, due to the time required to obtain the field data, the biomass information is often outdated when it is used (Chave et al. 2014). Thus, region-level estimates of AGB using only field data may not attain the same precision and timeliness as methods that combine field data with auxiliary information, such as remote sensing data.
Remote sensing images contain abundant spectral and textural information and have excellent temporal and spatial resolutions, wide coverage, and excellent timeliness (Zhu and Liu 2015). The combination of forest inventory plots and remote sensing data to estimate forest AGB has become a mainstream method (Lu 2006; Lu et al. 2016) in the last decades. Remote sensing-based AGB estimates have used three types of remotely sensed data: optical imagery, radar, and light detection and ranging (LiDAR), depending on the spatial resolution required and the application purposes. Optical remote sensing data are the most widely available type of data.The most commonly used optical data include lowresolution AVHRR and MODIS (Li et al. 2018),medium-resolution Landsat and SPOT data (Gasparri et al. 2010; Zhu and Liu 2015), and high-resolution IKONOS, Quickbird, Worldview, and drone data (Proisy et al. 2007; Arroyo et al. 2010; Dassot et al. 2012). High spatial resolution images have a significant amount of shadows from trees and terrain, resulting in errors for AGB estimation (Thenkabail et al. 2004; Vaglio Laurin et al.2019).Due to the high cost of the imagery,the estimation of biomass is often limited to a relatively small area (Foody et al. 2001; Gonzalez et al. 2010). Meanwhile, biomass estimation using low-resolution remote sensing images typically has two major drawbacks,namely, mixed pixels and difficulty to match the pixel size with the sample plot size; these problems result in relatively large errors of AGB estimates, limiting the application to national, continental, or global scales(Chopping et al. 2011; Baccini et al. 2012). In contrast,medium-resolution Landsat (30 m) data are widely used in combination with sample plot data for AGB estimations in the past two decades because they are freely available since 2008, have a 16-day revisit time, and obtain wide coverage. In addition, the 30-m resolution is similar to the size of sample plots in the national forest inventory of China (NFIs), thus reducing the error when matching the pixel to the field plot and obtaining better estimation results (Hall et al. 2006; Powell et al. 2010;Karlson et al. 2015).
In structurally complex forests, spectral saturation is encountered when using optical remote sensing imagery,causing estimation errors for areas of large biomass(Mermoz et al. 2015).Optical images are also susceptible to the influence of clouds and differences in solar illumination (Avtar et al. 2012). The successful launch of the Advanced Land Observing Satellite (ALOS) Phased Array L-band Synthetic Aperture Radar (PALSAR) in 2007 has increased the use of radar data to measure biomass. The instrument is the first long-wavelength (Lband, 23-cm wavelength) synthetic aperture radar (SAR)satellite sensor, it has the capability of collecting data in single, dual, full scan-SAR mode, and can provide crosspolarized (horizontal-transmit, vertical receive (HV))data and co-polarized (horizontal-transmit, horizontal receive (HH); vertical-transmit, vertical receive (VV))data (Avtar et al. 2013). The high penetration capability of SAR allows for extensive information extraction of the structural parameters of plants for improving biomass estimation. Methods that use L-band radar and optical data to estimate AGB have proven successful in forests with low to medium biomass levels (Lu et al.2012; Mitchard et al. 2012; Ploton et al. 2013; Shen et al.2019)but similar to passive optical remote sensing,these systems suffer from signal saturation at high AGB and show limited sensitivity to large AGB.Thus,the combination of optical and radar systems to estimate AGB in dense tropical and subtropical forests remains problematic and often results in the underestimation of AGB in complex and mature forests (Sandberg et al. 2011). Furthermore, radar systems are affected by terrain, surface moisture, and speckle noise (Imhoff 1995; Martins et al.2016; Mermoz and Le Toan 2016). As such, light detection and ranging (LiDAR) is an active remote sensing technology capable of providing detailed, spatially explicit, and three-dimensional information on forest canopy structure (Lefsky et al. 2002b). Thus, LiDAR estimates of AGB provide better precision than radar and optical data(Cao et al. 2016). However, it is expensive to collect wall-to-wall LiDAR for forest structure characterization over large areas, e.g., at the state or country level. Thus,current LiDAR systems are limited to areas smaller than those extents. Multi-source remotely sensed images in conjunction with appropriate statistical modeling algorithms are regarded as an effective and reliable means for mapping AGB over large areas.
Linear regression models have been widely used in early studies of AGB estimation (Myneni et al. 2001;Lefsky et al. 2002a). This parametric method is simple and straightforward, but can require strict assumptions on the model error and the normality of dependence variable. In addition, relationship models for practical AGB estimation are limited because of the complex nonlinear relationship between forest AGB and remote sensing features. Non-parametric methods do not require a strictly linear relationship between the response and covariates, and training data are used to train the model to estimate the parameter of interest. Due to the development of non-parametric estimation models, numerous studies on forest biomass estimation have used these methods in recent years, including the k-nearest neighbor (KNN) method (Chirici et al. 2008), neural networks(Foody et al. 2001), support vector machines (SVM)(Chen et al. 2010; Shen et al. 2018) and decision trees(Hansen et al. 2016). Random forest (RF) is a machine learning algorithm based on decision trees that has been used extensively for forest AGB mapping using remote sensing data in the last two decades. RF provides higher accuracy than comparative machine learning methods and conventional statistical regressions because RF is less sensitive to noise in the training samples (Powell et al. 2010; Hoover et al. 2018; Zhao et al. 2019). However, a major shortcoming of RF is that it ignores the spatial autocorrelation of the data when mapping the feature distribution(Chen et al. 2019a).
Geostatistics is based on the theory of regionalized variables; it does not only quantitatively describe spatial heterogeneity or spatial correlation but also establishes a spatial prediction model to interpolate and estimate spatial data (Isaaks and Mohan 1989). Kriging is a geostatisticial method and is also known as local spatial estimation or local spatial interpolation; it provides the best linear unbiased prediction (BLUP) of the regionalized variable values in a limited area and is based on the theory of variograms and structural analysis (Le and Zidek 2006). On the basis of linear regression, kriging needs to assume the spatial stability in the spatial variation analysis within limited distance, which can make up for the defects of non-parametric models (RF) to some extent.Fox et al. (2020) proposed the random forest regression kriging (RFRK) model to improve the two techniques by comparing spatial regression and the RF (Fox et al.2020). The prediction accuracy of RF model combining with kriging outperformed RF for predicting the spatial distribution of soil attributes and pollutant concentrations (Guo et al. 2015; Tziachris et al. 2019). Several studies have focused on AGB prediction using remote sensing data from different sources based on RF coupled with ordinary kriging (OK) (RFOK); this method combines RF predictions and residual estimations by OK(Chen et al. 2019a; Silveira et al. 2019a). OK is a linear estimation method that is suitable for inherently stationary random fields and satisfies the isotropic hypothesis.In a large study area, the interpolation of the RF residuals is affected by the uneven distribution of terrain and climate, and OK is the most suitable method (Cressie 1990; Le and Zidek 2006). Co-kriging (CK) is an extension of OK and uses one or multiple auxiliary variables to interpolate the variables of interest.The auxiliary variables are related to the target variables and are used to improve the accuracy of target prediction (Chatterjee et al. 2015).
Subtropical and tropical forests are very diverse (in the type, climate, and site conditions), with high uncertainty of AGB estimates. AGB prediction models trained with limited ground observations in tropical or subtropical forests over a large area are prone to overfitting and do not describe local features adequately (Lu et al. 2016;Zhao et al. 2016). In this case, the optimized integration of multiple types of remote sensing data and multiple modeling algorithms may provide an alternative to reduce high uncertainty (Yu et al. 2014; Santoro et al.2015). Numerous studies have combined active and passive remote sensing data sources for forest mapping over large spatial scales (Shen et al. 2016; Su et al. 2016; Deo et al. 2017). However, there are few studies on AGB mapping of large areas in subtropical forests using the combination of RF and CK (RFCK), especially in mountainous areas with complex terrain. In this study, we proposed a framework that uses field sample plot data,time-series passive and active remote sensing data, and co-kriging with RF models to improve the mapping accuracy of AGB of subtropical forests in southern China for the years 1992, 2002, and 2010. We expect that the results of this study will support the strategic development of carbon sequestration forests and sustainable forest management practices.
Materials and methods
Study area
The study area is located in northern Guangdong Province (extending from 113.10° E, 23.64° N to 114.75° E,25.44° N), China, and includes the administrative cities of Shaoguan, Qingyuan, and Heyuan (Fig. 1). The topography is undulating, and the elevation ranges from 13 to 1709 m above sea level. The area has a mid-subtropical monsoon climate, with mean annual precipitation of 1300 to 2400 mm and a mean annual temperature of 18°C to 21°C.The rainy season lasts from March to August, and approximately 53% of the annual precipitation falls between April and June. The vegetation includes natural forests and plantations. The dominant tree species are Pinus massoniana, Cunninghamia lanceolata, Pinus elliottii Engelm, Eucalyptus, Pinus kwangtungensis, Castanopsis fissa, Acacia mangium, and Phyllostachys edulis. Most of these species are evergreen and fast-growing. Other vegetation includes deciduous trees and shrubs. The most common meteorological events causing plant damage in the region are chilling events,storms,floods,and droughts.
Data collection
Field data
The NFI in China is the first level of China’s three-tiered inventory system, which is administered by the State Forestry and Grassland Administration (Xie et al. 2011).The system is based on permanent sample plots collected using a systematic sampling design. Estimates of forest attributes are typically produced using designbased inference. The NFI has been conducted nine times from the 1970s to 2017, with a cycle of 5 years; the sample sites are fixed and evenly distributed. The Guangdong Provincial Center for Forest Resources Monitoring provided us with nine NFI datasets collected between 1979 and 2017 to support this research. In this study, we used 4 years (1992, 2002, 2007 and 2012) of data from the inventory plots located in the study area.The hundreds of plots with a size of 25.82 m×25.82 m(0.0667 ha) were located in the study area. The AGB of the plots was derived using tree species-specific allometric equations developed by the Guangdong Provincial Center for Forest Resources Monitoring. The AGB is calculated using linear or non-linear regression models and DBH, tree height, and wood density of the surveyed trees. The biomass of the sample plots in 2010 was obtained by linear interpolation of the results of 2007 and 2012 to match the date of the used remote sensing data.
Since most remote sensing images have some amount of cloud cover, the sample plots covered by clouds in the images were excluded in the analysis to obtain more accurate inversion results. Additionally, quality control of the raw sample data was selected to remove unreliable observations. Statistical analysis was conducted in SPSS software (version 21.0, IBM, Armonk, NY, USA) after screening of the samples in the three inventories. Values that were larger or smaller than the mean plus/minus three times the standard deviation were considered outliers and were removed. The AGB unit used in this paper is tons per hectare (t∙ha−1).
Landsat data and SRTM digital elevation data
The Shuttle Radar Topography Mission (SRTM) digital elevation data produced by NASA represents a breakthrough in global digital elevation mapping, providing access to high-quality elevation data for large portions of the tropics and other areas of the developing world. This study used a free digital elevation model (DEM) with a resolution of 90 m (https://earthexplorer.usgs.gov/). We extracted geographical variables from the DEM data. We resampled the SRTM data from 90 to 30 m resolution for consistency with the image data and extracted the slope and aspect in ArcGIS.
The study area of Northern Guangdong is covered by the Landsat World Reference System-2 path/row 122/043 tile. The Landsat 5-Thematic Mapper (TM) imagery was acquired from the United States Geological Survey(USGS) EROS data center (https://glovis.usgs.gov/). We downloaded the images for 3 years (1992, 2002 and 2010) and ensured that the acquisition dates of the imagery fell into the growing season, and the images had minimal cloud cover (Table 1).
The Landsat ecosystem disturbance adaptive processing system (LEDAPS) is an image preprocessing algorithm developed by NASA for the generation of surface reflectance for the analysis of long-term time-series Landsat data. The algorithm is based on the 6S radiation transmission model and performs inversion of atmospheric parameters, such as aerosol data, the visible,near-infrared, and short-wave bands of Landsat TM/Enhanced Thematic Mapper (ETM)+data (Vermote and Saleous 2007). In this study, LEDAPS was used to obtain surface reflectance products through geometric correction, radiometric calibration, atmospheric correction,and F-mask processing for cloud detection. Subsequently, the C-correction (Fan et al. 2014) model was used to conduct topographic correction based on the surface reflectance data. The relationship between the slope and aspect from the DEM and the solar azimuth was used to correct the pixel reflectance value in the shadows of the mountains.
It is crucial to select appropriate variables for the inversion of remote sensing data to determine AGB. We performed spectral feature transformations, including principal components analysis (PCA), tasseled-cap transformation, and extraction of vegetation indices to obtain suitable variables. In addition to the six original bands of the image (excluding the thermal infrared band), we also extracted the reciprocal reflectance of the band as an additional variable for the inversion.
For extracting image texture, the first principal component (PC1) of the PCA, which contained more than80% of the original spectral information, was used to extract image texture using eight texture variables. The texture variables were calculated with three window sizes (3×3, 5×5, and 7×7) with an offset ([1, 1]) and 64 Gy-level quantification.
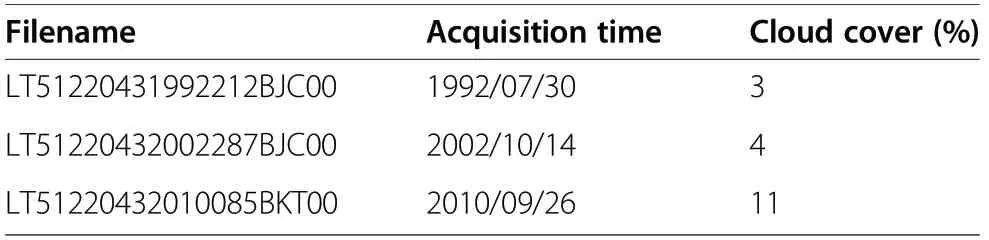
Table 1 Description of the Landsat imagery used in this study
ALOS PALSAR data
The ALOS/PALSAR data were pre-processed at the Japan Aerospace Exploration Agency (JAXA). The global 25 m resolution PALSAR/PALSAR-2 mosaic is a seamless global SAR image created by mosaicking SAR images of the backscattering coefficient obtained from PALSAR/PALSAR-2, where all the paths within 10×10 degrees in latitude and longitude are path-processed and mosaicked for processing efficiency. Since the ALOS/PALSAR data ranged from 2007 to 2010,we selected the mosaicked images of the study area in 2010 to match the sample field data and Landsat images. Correction of the geometric distortion specific to SAR (orthorectification) and topographic correction based on image intensity(slope correction)were performed to facilitate forest classification.The digital numbers of the SAR signal amplitude were extracted from the imagery and were converted to backscattering coefficients in dB using Eq.1:
The variables included the HH and HV polarizations and HH/HV and the radar forest degradation index(RFDI)(HH −HV)/(HH+HV) (Aslan et al. 2016). The RFDI is a useful input layer for wetland vegetation mapping because HH polarized data are sensitive to water beneath the canopy, whereas HV polarized data are known for the sensitivity to volume scattering and biomass (Hess et al. 1995; Wicaksono 2017). The derived variables were resampled to 30-m resolution using bilinear interpolation to match the Landsat datasets.
Prediction methods
Random Forest model
The RF model is a supervised machine learning algorithm based on decision trees. It has the advantages of providing variable importance, being robust to data reduction, generating an internal unbiased estimate of the generalization error as the forest building progresses,and having higher accuracy than individual decision trees and low sensitive to parameter adjustment than other machine learning models (e.g., neural networks)(Amit and Geman 1997; Breiman 2001, 2004; Hastie et al. 2008). We used the randomForest package (Liaw and Wiener 2002) in the R software for AGB prediction.
Numerous variables have been used for forest AGB prediction (Kumar et al. 2015), but choosing the right variables has a significant influence on the prediction accuracy of the model. After stacking the available feature layers, the coordinates of the sample plots were matched to those of the pixels so that the AGB of the plot corresponded to the suite of predictor variables (feature names), and established the models. We then performed variable importance analysis in the randomForest package by deriving two different variable importance measures, the analytical result provided means to assess the contribution of each predictor variable to the modeling performance based on the response type. The first importance type was calculated by randomly permuting each predictor variable and computing the associated reduction in predictive performance using the out of bag(OOB) error for RF models and the second importance type was calculated using the decrease in node impurities attributable to each predictor variable (Breiman 2001). The larger the percent increase in mean square error (MSE) (%IncMSE) and increase in NodePurity(IncNodePurity) indicated a stronger importance of these predictor variables (Karlson et al. 2015; Shen et al.2016).
In order to ensure the comprehensive representation of each variable to the RF models, so as to balance the accuracy and generalization ability, the variable that has relatively high ranking in both importance types was selected as the modeling variable. Based on the ranking of each variable in GI-index and OOB error rate,a comprehensive chart can be obtained to help determine the variables with high importance of both types, the variables with the higher comprehensive ranking were selected as the predictors highly related to AGB, so as to reduce the calculation complexity and obtain more accurate and easily interpretable results. Additional file 1 Table A1 shows all the alternative variables.
The correct parameters in machine learning do not only increase the predictive power of the model but also facilitate model training. The parameters of the model in this study included the mtry, ntree, and nodesize, where mtry represents the number of variables used to split the tree at each node, ntree represents the number of decision trees in the RF, and nodesize represents the minimum number of nodes in the decision tree. For parameter tuning, mtry was defaulted to the quadratic root of the number of variables in the data set (classification model) or to one third (prediction model). Nodesize was defaulted to the classification model at 1 and the regression model at 5. The selection of ntree value was determined by constantly testing that how much number of decision trees was gained - when the error in the model was relatively stable. After multiple tries, we used the following values for the parameters: mtry=3, ntree=500, and nodesize=5.
Kriging-based model
Geostatistics is an effective method for determining spatial or spatiotemporal variation based on statistical measures. Since the RF model does not consider spatial autocorrelation of the AGB sample plots, we used a combination of RF and kriging to determine the spatial distribution of AGB. The detailed flowchart of RFCK is shown in Fig. 2. Specifically, a regression-kriging technique was used to extract the components of the residuals obtained from the RF regression (Guo et al. 2015).The residual is the observed AGB minus the predicted AGB from RF. By adding the extracted components to the RF-based predictions, we obtained a larger prediction accuracy of the AGB. Since the RFOK considered the spatial autocorrelation of the AGB residuals, the saturation problem encountered in optical remote sensing data for dense or mature forests was minimized (Lu 2005), resulting in an unbiased and reliable AGB map.Here, we focused on comparing the accuracies of ordinary kriging (OK) and co-kriging (CK).
OK is a linear estimation method suitable for inherently stationary random fields and satisfies the isotropic hypothesis (Cressie et al. 1990). In this hypothesis, the mathematical expectation of the variable of interest is independent of its position, and the covariance is a function of the distance between the points. We assume that we estimate n points in the neighborhood of point x0;the interpolation formula of the OK method is defined in Eq. 2:
CK is an improvement over the OK method and can deal with multivariable problems.The random fields that need to be modeled are called primary variables, and other random fields involved in modeling are called covariables. Variograms and covariograms of each attribute are used in the calculation. Since the research area is located in the mountainous area of northern Guangdong Province, the AGB is affected by the terrain.Therefore, elevation was selected as a covariable for the interpolation. The residual value is defined in Eq. 3:
A variogram describes the structural changes of regionalized variables, as well as random changes, and is an effective tool for the analysis of spatial variation and spatial structure. In kriging, the type of variogram is important because it determines the accuracy and reliability of the estimate. In this study, the semivariogram was modeled in GS+ (version 9.0, Leland Stanford Junior University, Stanford, California, USA) using spherical,exponential, and Gaussian functions. According to the parameters obtained from the simulation, select the model with the maximum R2and the minimum RSS for use. The three model parameters of a semivariogram are the nugget, range, and sill. The nugget represents the small-scale variability of the data. The range is the distance beyond which little or no spatial autocorrelation occurs. The sill is the maximum value of the semivariogram, where the spatial distance between two locations reaches the range (Ou et al. 2017). The nugget effect, that is, the ratio between the nugget and sill, calculating the nugget effect can be used to compare the relationship between local variation and population variation, the stronger spatial autocorrelation is denoted by the smaller values of nugget/sill (Matheron 1963; Zimmerman and Zimmerman 1991). The fitting performance of the variogram was estimated by the coefficient of determination (R2) and the residual sum of squares (RSS). The larger the R2, and the smaller the RSS, the lower nugget effect, the better the fitting performance is.
The following steps were performed for RFOK modeling: the estimated residual value of each sample point was obtained by subtracting the predicted value of the RF result from the observed AGB value (Eq. 4). The residual values of the sample points were modeled using Eqs. 2 and 3 to obtain the structure of the component in the residuals. Subsequently, the final AGB estimate was obtained by adding the structure of the component to the RF-based prediction (Eq. 5).
Model fitting and evaluation
The stratified sampling method was applied to all the AGB observations to pick up 80% of the samples as the training data, and the remaining 20% as the validation data. We used several statistical measures to quantify the model performance, including the R2(Eq. 6), the mean absolute error (MAE) (Eq. 7), the root mean square error (RMSE) (Eq. 8) the RMSE% (Eq. 9), bias(Eq. 10) and bias% (Eq.11).
Results
Variable importance
In the variable importance analysis, %IncMSE is the importance ranking result obtained by replacing the OOB data, and IncNodePurity is the importance ranking result calculated by the Gini index. Figure 3 shows the top 25% IncMSE variables identified by the RF OOB strategy, the size and color of the circles indicate the IncNodePurity, the two importance types comprehensively indicate the ability of the variables to predict AGB. The 10 variables with the largest IncNodePurity were selected as independent variables for AGB mapping. In the 2010 variable selection, the PALSAR-derived variables(e.g., HH_HV and RFDI), were included in the list, indicating the relatively large importance for the prediction of AGB. Overall, the reflectance and combined indices from Landsat-5 accounted for a large proportion of the better-performing variables, and the texture variables from the PC1 were also important variables for AGB estimation.
We selected 10 variables to reduce the complexity and calculation load, including TM7_1, B7, B2, SAVI, TM14,TM17, B5, TM37, VRI, and second77 to map AGB in 1992. For 2002, we used the mean55, RSI, mean77,TM37, VRI, TM12, TM27, TCD, elevation. And TM34,Mean77, B1, TM34, HH_HV, TM2_1, TM25, ARVI, B2,RFDI,and EVI were selected for mapping AGB in 2010.
Random forest modeling
We attained the performance measures for the three RF prediction models. Table 2 lists the performance measures of the fitted models for 1992, 2002, and 2010. The R2for model training ranged from 0.86 in 1992 to 0.95 in 2010; when the fitted models were used to predict the training data, we obtained RMSEs of 9.05, 43.68, and 37.51 t∙ha−1for 1992, 2002, and 2010 respectively, and the corresponding RMSE% were was 71.57%, 63.34% and 56.21% respectively. We also obtained bias of −0.01,0.35, 1.09 t∙ha−1for 1992, 2002, and 2010 respectively,the corresponding bias% were −0.05%, 2.29%, and 1.02%respectively. The smallest RMSE was observed for the 1992 AGB because the biomass values were smallest for the 1992 training plot; the same was observed for the standard deviation (Table 3). As a result, the R2had the smallest value (0.86) of the 3 years. Compared with those of 2002 and 2010, the values of the bias% for the 1992 model were nearer closer to 0, with the smallest RMSE and the largest RMSE%. Figure 4 shows the validation performances of the three fitted models; 20% of the data were used to conduct the validation. The validation R2values were around 0.40, and the fitted line(red) was substantially different from the 1:1 line; the small AGB observations were overestimated, and the large AGB observations were underestimated.
Random forest combined with kriging models
Residuals of RF-derived AGB and semivariance analysis
Table 4 summarizes the descriptive statistics of the residuals. The absolute kurtosis values of the three groups of residuals were close to 3 or 2, and the skewness was close to 1, indicating that the residuals were approximately normally distributed (Fig. 5). The means of the residuals in 1992 and 2010 were 0.004 and 0.186 t∙ha−1,respectively; these values were closer to 0 than the value in 2002 (−1.223 t∙ha−1). The 1992 residuals had the smallest standard deviation, indicating a small difference between most residuals and the mean residual. The range of the residuals was largest in 2002 (159.1 t∙ha−1).The residuals are shown in different colors and sizes based on the quartile distribution (Fig. 5).
After confirming the approximate normality, the three groups of the residuals were used to calculate empirical semivariograms for the subsequent RFOK interpolation.In the simulation results obtained from GS+, the model with the largest R2and smallest RSS is selected for the semivariogram, the Gaussian model was used for 1992,the exponential model for 2002, and the spherical model for 2010. Additionally, the elevation of the plots was used as a covariable in the RFCK model to obtain accurate estimates. Table 5 and Fig. 6 show the parameters of the semivariogram models and the semivariograms, respectively of the RFOK and RFCK models. Overall, the fitting performance was better for the RFCK than the
RFOK model; the former had a larger R2, smaller RSS,and smaller nugget/sill value than the latter (Table 5).In comparison to Table 5, the nugget/sill values indicated that the variability caused by spatial autocorrelation in the 1992_RFOK model is the larger than the other years’ models. The largest nugget value of 402.91 for the 2002 RFOK model suggested that the 2002 residuals exhibited the strongest spatial heterogeneity.The RFCK models had smaller nugget values than the RFOK models, indicating that the addition of the elevation covariable reduced the spatial variability (Table 5).Overall, there was lower spatial heterogeneity in the 1992 residuals than in the 2002 and 2010 residuals, indicating by the smallest nugget/sill ratio in the 1992_RFOK model. The 1992 models had the highest spatial autocorrelation and highest suitability for kriging than models in 2002 and 2010, so 1992 models provided better kriging results.
Forest AGB mapping using RFOK and RFCK
Based on Eq. 5, the predicted AGB was obtained from the RFOK and RFCK models (Fig. 7), followed by validation with 20% of the samples. Table 6 shows the validation accuracies of the three AGB models in each of the 3 years. The 1992 RFCK model had the largest RI value(17.7%) (compared with the 1992 RF model); the R2increased from 0.41 to 0.81, the MAE decreased from 9.93 t∙ha−1to 6.54 t∙ha−1, the bias% changed from −22.59%to −10.68%, and the RMSE% decreased from 112.47% to 92.48%. The accuracy of the 1992 AGB maps was substantially larger than that of the 2010 and 2002 maps.The reason may be that the observed forest AGB values were smallest in 1992, and the variability was lowest(Table 3); thus, the saturation effect was minimal in the 1992 models, resulting in larger validation R2values. At the same time, the 1992 models had larger bias% and RMSE%, which were also related to the smaller arithmetic mean value of observed AGB in 1992. In 2002 and 2010, saturation occurred (the largest measurements on the ground were above 250 t∙ha−1, Table 3), resulting in a significant decrease in the validation R2values to about 0.4 and 0.5. The absolute value of bias% and bias of the validated model in 2010 was smaller than those in 1992 and 2002. The RFCK models outperformed the RFOK and RF models in all 3 years (Table 6).

Table 2 Summary of the modeling performance measures derived from the three RF training models

Table 3 Descriptive statistics of the AGB(t∙ha−1) of the sample plots in the three forest inventories

Table 4 Descriptive statistics of the RF models’ residuals
In addition to accuracy evaluation, the generalization ability of the model is also important. The range of AGB values in the prediction map of the study area could reflect the adaptability of the models to new samples (i.e.generalization ability) to some extent. The range of the AGB predictions obtained from the RF model was 3.73-36.73 t∙ha−1in 1992, 24.47-247.04 t∙ha−1in 2002, and 33.30-258.38 t∙ha−1in 2010. The range of AGB predictions obtained from the RFOK model was 3.78-48.84 t∙ha−1in 1992, 8.09-266.67 t∙ha−1in 2002, and 23.23-270.58 t∙ha−1in 2010. The range of AGB predictions obtained from the RFCK model was 2.09-51.03 t∙ha−1in 1992, 14.15-259.55 t∙ha−1in 2002, and 21.89-267.43 t∙ha−1in 2010. The range of AGB showed an increasing trend from 1992 to 2010. A decreasing trend in AGB was observed from the southeast to the northwest in 1992, whereas, in 2002 and 2010, larger AGB was observed in high-elevation mountain areas (Fig. 7a, d, e).From 2002 to 2010, areas with AGB greater than 100 t∙ha−1increased substantially, whereas areas with AGB less than 40 t∙ha−1decreased.
Discussion
Variable selection and AGB estimation accuracy
The selection of suitable remote sensing variables is a critical step in AGB estimation (Lu et al. 2016). The variables used as input parameters before modeling can be divided into three types: spectral index, terrain variables,and texture measures. An importance analysis was used to determine the best predictors. The importance of the variables on AGB mapping was determined by the order of importance (Fig. 3), the performance measures of the models(Table 2),and the mapping results(Fig. 7).Previous research has shown that texture measures have the potential to improve AGB estimation. Zhao et al. (2016)found that texture measures were valuable for AGB estimation of subtropical forests in southwest China, especially for forests with complex stand structures, such as mixed forests and pine forests with understories of broadleaf species. Tuominen and Pekkarinen (2005) extracted features from normalized difference vegetation index and band ratio images and analyzed the correlations between the extracted image features and forest attributes measured from sample plots. Our research results confirm the role of texture in AGB estimation.The results of the importance analysis of the 2002 and 2010 variables indicated a high correlation between the textural variables and AGB, especially for the mean texture measure of the gray-level co-occurrence matrix(Fig. 3). The eight texture measures based on the grayco-occurrence matrix generated from the PC1 and the backscatter of PALSAR performed well for AGB estimation, and the texture variables obtained from the Landsat PC1 in the 2010 model were better than those from PALSAR HH/HV. All predictors contributed to the integrated model, but the vegetation indices and spectral bands comprised the largest proportion of modeling variables (Table 2); this result was consistent with previous studies (Foody et al. 2003; John et al. 2018; Zhang et al.2019). For forest sites with complex forest structure and species composition, such as pine forests with understories of broadleaf species,texture measures are needed.They had higher importance values than spectral information when TM imagery or PALSAR HH and HV polarization data were used. The importance analysis of the 1992 data showed that spectral variables ranked higher than texture variables. The reason may be that no large-scale afforestation projects were conducted in Guangdong Province, and the average AGB in the study area is relatively small; thus, spectral saturation was not a problem. Furthermore, most forests are not mature(small AGB values in Table 3) and have a relatively simple structure; therefore, texture measures are less suitable than spectral variables for capturing the simple structure.
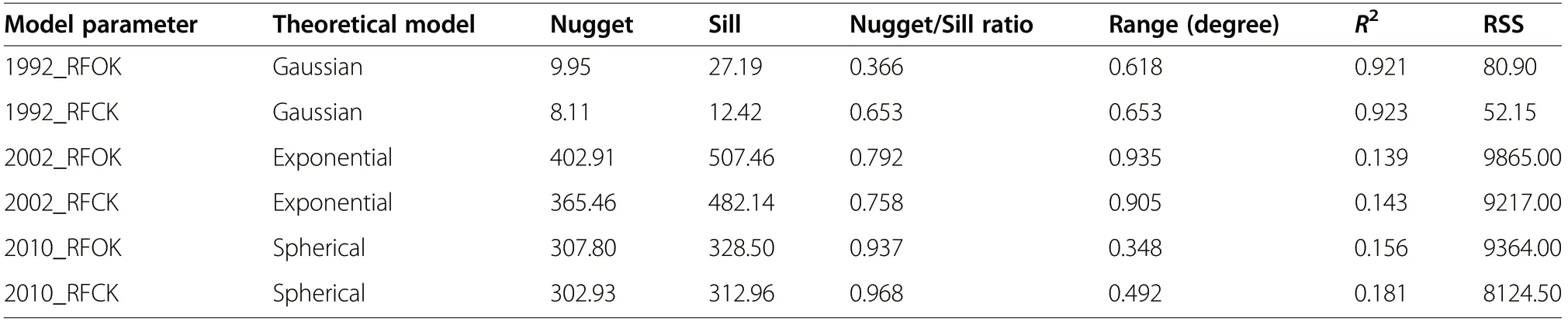
Table 5 Parameters of the theoretical semivariogram models of the residuals for the RFOK and RFCK models

Table 6 Accuracy of the RF,RFOK,and RFCK models based on the validation data
Precipitation is absorbed by the forest soil and plant leaves, and the moisture affects not only the spectral information of ground features but also the forest biomass(Chen et al. 2019b). We used Landsat images acquired during the summer in the growing season (Table 1),which was coincident with the period of heavy precipitation in the study area. The spectral signatures of sparse forests are affected by the soil background. Subtropical forests grow vigorously due to the abundance of water.Vegetation indices were included because they minimize the influence of the background on AGB estimation, but more ground data need to be obtained by multi-source sensors. HH polarized data are sensitive to moisture beneath the canopy, whereas HV polarized data are sensitive to volume scattering and biomass (Hess et al. 1995).However, the estimation of forest biomass using ALOS PALSAR data currently has limitations, because the Lband saturates at about 150 t∙ha−1(Ho Tong Minh et al.2018). Mermoz et al. (2015) found a negative correlation between the SAR backscattering coefficient and forest biomass after reaching a maximum value. This result was attributed to signal attenuation from the forest canopy as the canopy becomes denser with increasing biomass. We also selected PALSAR-based polarized features as predictors to map AGB, and our results were in agreement with previous research findings.
We found that RF modeling overestimated small biomass values and underestimated large biomass values(Fig. 4), which partly explained the presence of bias in the AGB prediction and indicated a saturation problem.The 2010 RF model incorporated a combination of Landsat TM and PALSAR variables, and this model improved the AGB estimation of forest stands by less than 150 t∙ha−1. The scatterplots in Fig. 4 showed that the points of the 2002 RF model were clustered. The predicted value obtained by the 2010 RF model was smaller than that of the observed AGB. Similarly, the predicted values of the two verification points with AGB values greater than 150 t∙ha−1in 2010 are small, indicating the limitation of the L-band SAR sensor when dealing with saturation in high biomass stands. In the comprehensive ranking of variable importance (Fig. 3), the variable HH_HV from microwave data was relatively high in 2010,and the R2of 2010 model was the largest (0.95) in the RF modeling performance measures (Table 2). The model accuracy evaluation in Table 6 also shows that,when the measured AGB in 2002 and 2010 have similar range, mean and standard deviation (Table 3), the 2010 models with microwave data have better prediction effect (i.e., the smaller RMSE and RMSE%, and the closer to 0 bias and bias% values). Nonetheless, the use of SAR sensors with higher radar wavelengths (e.g., P-band) may be suitable for the estimation of biomass at higher levels(on the order of 300 mg∙ha−1) (Ho Tong Minh et al.2014). Additionally, LiDAR systems can capture the horizontal and vertical structure of vegetation in great detail, and the data have a larger threshold for sensor saturation (e.g., biomass estimation on the order of 1200 Mg∙ha−1) (Lefsky et al. 2002b; Giannico et al. 2016;Manuri et al. 2017; Valbuena et al. 2017). However, considering the high acquisition cost and limited acquisition scope, LiDAR data were not considered in this study.
In addition, we had to obtain the AGB of the sample plots in 2010 by linear interpolation to ensure time matching of the data; therefore, the results may have differed from the AGB obtained by the allometric growth equations using NFI data. The forest growth rate is not uniform, and the dependent variable in 2010 was not accurate enough compared with the AGB obtained from field investigation, which affects reliability of the subsequent mapping to some extent. During sample point screening, the standard deviation method we used to remove outliers may not be appropriate enough, because the occurrence of outliers would have a great impact on the mean value and standard deviation. There is a more stable technique of outlier removal worth considering like the Center distance calculation method based on median absolute deviation (Leys et al. 2013). In the cokriging process for the residual, we did not consider the nonlinear relationship between the covariable with AGB,the selection of covariables could be quantitatively considered in the further research, and some methods should be used for linear transformation of covariates(e.g. Box-Cox transformation) (Fox et al. 2020). In general, the results of the RF model indicate that timeseries derived from multi-temporal Landsat images and PALSAR data can improve the accuracy of AGB estimation and reduce the saturation problem. The accuracy of model prediction can be further improved by obtaining dependent variables obtained from more accurate sample site measurements in a future study.
Model improvement and map accuracy
This study demonstrated that the RF model combined with kriging provided higher mapping accuracy than the RF models, and on this basis, RFCK was marginally better than RFOK. Table 6 shows the performance of the three models (RF, RFOK and RFCK). In 1992 models,the difference between RFCK and RFOK was very small that it could be ignored. Basically, among the three models each year, the RFCK model was the one with the largest R2, the smallest RMSE, RMSE%, MAE, and the value of bias% and bias was closest to 0. The RI was largest in 1992, followed by 2002 and 2010. Chen et al.(2019a) found that due to the low spatial autocorrelation of the RF-based residuals, the improvement in the accuracy of the RFOK model was limited, and the degree of accuracy improvement was higher in the models that used variables from a single sensor. Hengl et al. (2004)showed that if the model residuals exhibited spatial autocorrelation, the model performance could be improved by interpolating residuals using kriging and adding the components to the RF model. Nothdurft et al.(2009) and Fox et al. (2020) has demonstrated the feasibility of improved accuracy of non-parametric models by including a parametric component. The results of our analysis confirmed these results. The model variables in 1992 were derived from a single remote sensing source,and the RI of the RFOK model was 0.176; in contrast,the 2010 model used a combination of optical remote sensing data and radar data, resulting in the smallest RI of the RFOK model for the 3 years (RI=0.031). In addition, the semivariogram results (Table 5) indicated that the 1992 RFOK model had a large RI because of the strong spatial autocorrelation of the residuals. Studies using similar residual interpolation methods to predict soil organic matter have shown that the accuracy was substantially improved when the nugget/sill values were smaller than 0.6 (Guo et al. 2015; Tziachris et al. 2019).The results of our study confirmed these findings. The spatial distribution of the RF residuals (Fig. 5) showed that there was less spatial autocorrelation, the results of the OK interpolation were more accurate, and the RI in the accuracy of the RF model was larger (i.e., for the 1992 model) when the residual range was relatively narrow, and the spatial distribution was uniform. The validation R2values of the RFOK and RFCK models were both 0.81, and the RMSE of the RFOK model increased by 17.6% compared to the RF model. As shown in Fig.7a and e, there are significant differences in the AGB between the RFOK map and the RF map, and the patches are better defined in the RFOK map.
Previous studies have shown that there is a strong correlation between elevation and biomass in subtropical mountains (Silveira et al. 2019b). Vegetation carbon storage and elevation showed similar spatial variation trends, and carbon storage was closely related to AGB(Yadav et al. 2019). In our study, the residual values of 2002 and 2010 were randomly distributed, and large residual values were observed in the mountain areas. This finding was related to the overestimation and underestimation of the small values in the RF model in 2002 and 2010, respectively. The sample sites in the high mountains are in areas of dense forest with large biomass; the AGB at these sites was underestimated by the RF model,resulting in large residual values. As shown in Table 6,in 2002 and 2010, the RFCK model, which included elevation as a covariable, had smaller nugget and sill values and larger R2values than the RFOK model. This result demonstrated that in regions with an uneven spatial distribution of AGB, the use of elevation as a covariable improved the accuracy of the interpolation results and minimized the saturation effect in areas with high biomass, especially in intersection of mountains and plains. Future studies should consider other covariables, such as fractional vegetation cover (FVC)and precipitation, which are often used for estimating forest AGB with geostatistical methods (Barni et al.2016).
Compared with the RF model that only considered the variables from remote sensing data, the RFCK model included the residuals, resulting in higher accuracy of the AGB prediction because spatial autocorrelation was considered (Table 6). Figure 4 shows the scatter plots of the observed values against the predicted values from the model validation process, different colors are used to distinguish different models. The RFOK scatter points(orange) get closer to the 1:1 trend line than the RF’s(blue), and the RFCK scatter points (green) are closer to the 1:1 trend line than the RFOK’s. Figure 7 shows the interpolation results of the residuals (Fig. 7b and c) and the final AGB maps (Fig. 7d and e) derived from adding the structured components to the maps generated by the RF model (Fig. 7a). The interpolation results of OK and CK exhibit slightly differences, but both results show smaller residual values in areas with less forest biomass,such as valleys and rivers. At the boundary of mountain valleys and plains, errors caused by the sensor angle and solar azimuth cannot be eliminated (Saraf et al. 1996).
The R2of the RCFK model was 0.81 in 1992, 0.41 in 2002, and 0.55 in 2010. The ensemble model used by Zhang et al. (2019) explained 75% of the variance of forest AGB in a Chinese subtropical forest, with an RMSE of 45.5 Mg∙ha−1.Our study demonstrated that the RFCK model provided improved accuracy for forest AGB estimation. Shen et al. (2016) used an RF model with multi-temporal Landsat images for AGB estimation in northern Guangdong in 2011; the RMSE was 39.49 t∙ha−1, and the R2was 0.51. The accuracies of this study are better than those of other studies of modeling AGB in subtropical mountains using a combination of optical and radar data. The RFCK model can deal with nonlinear relationships and eliminate some overfitting in nonparametric estimation. On the other hand, the disadvantage is that it is challenging to interpret the relationships between the response variable and independent variables(e.g., the residuals represented the unexplained variance of the model).
Long-term changes in AGB and their effects on policy
In the study area, significant changes were observed in the AGB values and spatial distribution in the 18 years.Previous studies have shown that extensive deforestation contributes to global climate change, altering hydrological cycle patterns, and resulting in adverse environmental effects, such as soil erosion and degradation(Eckert et al. 2011; Muttaqin et al. 2019). Shen et al.(2018) found increases in the temperature and decreases in the precipitation from 1986 to 2016 of Guangdong Province, and the correlation between climate and AGB decrease was smaller than that between human activities and AGB. In addition, there were interactions between climate and human activities. The changes in the AGB in the study area was primarily the result of afforestation and deforestation. Guangdong Province had limited forest resources in the 1980s, and the forest coverage was only 30.2%; however, the population density was large,and the economy prospered. After the implementation of China’s “Economic Reform and Opening Up” policy,Guangdong’s economy developed rapidly, the population increased, and a large proportion of forest land was used for urban expansion and construction. As a result, the forest area was reduced substantially. In the 1990s, the province implemented forest land protection policies and deforestation projects, and the area of forest land gradually increased.
The afforestation areas in Guangdong Province, China from 1992 to 2010 are shown in Fig. 8 and Table 7; the data were obtained from the Statistical yearbook of Guangdong (http://stats.gd.gov.cn/gdtjnj/). Wang et al.(2016) found that trees planted in the late 1980s grew into medium and near-mature forests between 1992 and 1997, increasing the capacity of the forest for carbon storage and resulting in a substantial increase in forest biomass and carbon density in 1997. Shen et al. (2017)examined forest disturbance and recovery in GuangdongProvince from 1986 to 2015 also identified corresponding abrupt changes. These data are in agreement with our findings that both the AGB data provided by the NFI and the AGB estimates obtained from the proposed model in this study showed a significant increase in AGB from 1992 to 2002. In the decade from 2002 to 2010, the mean and maximum of the biomass also increased slightly. These changes are attributed to harvesting of timber within the scope of forest management practices, as well as the establishment of many nature reserves to develop tourism resources in the mountains in northern Guangdong. In 2012, the proportions of near-mature forests, mature forests, and over-mature forests in the province were substantially larger than those in 2002 and 1992, confirming the effects of afforestation in the past 20 years. The AGB trend of the maps obtained by the RFCK model for the period corresponds well to the data obtained from the Statistical yearbook of Guangdong well, demonstrating the reliability of the model. In this paper, only three time points (1992, 2002 and 2010) of data spanning 20 years were used to explore the improvement of model accuracy. Future research should focus on longer time series data, and establish a year-by-year models to obtain accurate spatial distribution of AGB to discuss the region’s dynamics(such as forest disturbance and recovery), so as to determine the influence of other factors on regional AGB to provide information for administrative departments and forest management.

Table 7 Proportion of forests of different stand ages in 1992-2012 in Guangdong
Conclusions
The results demonstrated that the RFCK model based on Landsat had the best performance for the prediction of AGB in 1992, with an R2value of 0.81. The changes in the spatial distribution of the AGB in the 3 years were confirmed by forest management statistics. Validation with an independent dataset showed that the RFCK model had the highest accuracy for AGB estimation,followed by the RF and RFOK models. The RFCK model also provided a more realistic spatial distribution of AGB than the RFOK model. The saturation effect was minimized by using PALSAR data; the residuals had higher spatial autocorrelation and less heterogeneity in 2010 than in 2002. Overall, the proposed RFCK model provided the best performance for AGB mapping in the subtropical forest with complex terrain. It is our belief that combined geostatistical optimization of the machine learning algorithm is beneficial to create a reliable spatial mapping of aboveground biomass in subtropical forests and provide a critical component for assessing forest management, forest carbon sequestration and protecting forest resources in the region.
Supplementary information
The online version contains supplementary material available at https://doi.org/10.1186/s40663-020-00276-7.
Additional file 1:Table A1.Summary of predictor variables from Landsat-5, SRTM DEM data, ALOS PALSAR for AGB estimation and mapping.
Acknowledgements
The authors would like to acknowledge the United States Geological Survey(USGS), National Aeronautics and Space Administration (NASA),and Japan Aerospace Exploration Agency (JAXA) for providing the image data. Special thanks go to the Guangdong Provincial Center for Forest Resources
Monitoring for sharing their forest inventory data.
Authors’contributions
H.S. designed the study, data preparation,analysis, and wrote the paper.W.S.participated in the conceptual design and provided suggestion of the method. J.W. participated in the data preparation and processing. A.A.provided the paper editing. M.L. provided the project design and paper editing. All the authors read and approved the final manuscript.
Funding
This work was jointly supported by the Natural Science Foundation of China(Nos. 31670552, 31971577),China Postdoctoral Science Foundation (No.
2019 M651842), and the Priority Academic Program Development of Jiangsu Higher Education Institutions (PAPD).
Availability of data and materials
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare no conflict of interest.
Author details
1College of Forestry, Nanjing Forestry University, Nanjing 210037, China.2Co-Innovation Center for Sustainable Forestry in Southern China, Nanjing Forestry University, Nanjing 210037, China.3Shenzhen Academy of
Environmental Sciences, Shenzhen 518000, China.
Received: 27 April 2020 Accepted: 9 November 2020

- Forest Ecosystems的其它文章
- Evaluating the impact of sampling schemes on leaf area index measurements from digital hemispherical photography in Larix principis-rupprechtii forest plots
- Discovering forest height changes based on spaceborne lidar data of ICESat-1 in 2005 and ICESat-2 in 2019:a case study in the Beijing-Tianjin-Hebei region of China
- Comparison of the local pivotal method and systematic sampling for national forest inventories
- Effects of firewood harvesting intensity on biodiversity and ecosystem services in shrublands of northern Patagonia
- The Siberian moth(Dendrolimus sibiricus),a pest risk assessment for Norway
- Hydrological functioning of forested catchments,Central Himalayan Region,India