
Comparison of the local pivotal method and systematic sampling for national forest inventories
2021-01-11 06:54MinnatyMikkoKuronenMariMyllymkiAnnikaKangasKaikisaraandJuhaHeikkinen
Forest Ecosystems 2020年4期
Minna Räty ,Mikko Kuronen,Mari Myllymäki,Annika Kangas,Kai Mäkisara and Juha Heikkinen
Abstract
Keywords: Auxiliary data, Bias,Local pivotal method, Matérn estimator, National forest inventory, Sampling efficiency, Simple random sampling, Spatially balanced sampling, Systematic sampling, Variance
Background
National Forest Inventories (NFI) commonly use systematic sampling where the random location of one sample plot defines the locations of the other sample units according to the chosen design. As a result, the sample units are arranged according to a predefined pattern(such as a square grid) over the inventory region(Tomppo et al. 2010; Vidal et al. 2016). Further, for cost efficiency reasons, the sample plots are typically arranged in clusters. The uniform coverage of the inventory region achieved with systematic sampling is generally anticipated to yield more efficient estimators of the mean or total values of forest variables than simple random sampling (SRS) of clusters (e.g. Magnussen et al.2020). In addition, SRS may result in large gaps without sample plots, which is particularly problematic when estimating means or totals for small sub-domains of the inventory region.
The utilization of remote sensing data has a long tradition in forest inventories (Kangas et al. 2018). Satellite images have been applied for the Finnish multi-source National Forest Inventory (MS-NFI) since the 1990s to produce wall-to-wall maps of forest resources and municipality-level statistics (Tomppo et al. 2008). MSNFI maps produced as a result of earlier NFI campaigns offer spatial information which can be utilized as prior information in the sampling design and estimation for a new NFI.
Most of the recent efforts to enhance NFIs with auxiliary data have concentrated on the estimation phase.Both model-based and model-assisted methods, including post-stratification as a special case, have been developed (Särndal et al. 1992; Opsomer et al. 2007; Gregoire et al. 2011; Tipton et al. 2013; McRoberts et al. 2013;Magnussen et al. 2015; Saarela et al. 2015; Kangas et al.2016; Ståhl et al. 2016; Myllymäki et al. 2017; Haakana et al. 2019). However, the emergence of the local pivotal method (LPM, Grafström et al. 2012), enabling approximately balanced sampling in a multidimensional data space (Grafström and Lundström 2013), has also stimulated attempts towards the direct use of auxiliary data for more efficient sampling designs (Grafström and Ringvall 2013; Grafström and Schelin 2014; Grafström et al. 2017). MS-NFI maps have been used in Finnish NFI since the1990s to specify the details of a systematic cluster sampling design, such as the number of plots in a cluster and the distance between them. In addition, it has been used to implement double sampling for stratification in the sparsely forested northernmost part of the country (Tomppo et al. 2011).
Promising results have been reported concerning the potential of LPM to improve large-scale inventories, but the data used in these studies has caused some limitations. In Grafström et al. (2017), for instance, no independent auxiliary data were available, but the target variables were sampled utilizing other variables of the same remote sensing material. In Räty et al. (2018) the auxiliary data was independent, but the population was limited to the real NFI sample plot positions in the target data, which meant that clusters could not be closer than about 7 km from each other. Furthermore, LPM was not compared to systematic sampling in these studies.
Methods for improving the efficiency must be equipped with a proper, practically applicable estimator of uncertainty in order to be able to report the inventory results with the improved precision. Design-unbiased estimators of variance, the most commonly accepted measure of uncertainty (e.g. Gregoire 1998), are not available for either systematic sampling (e.g., Magnussen et al. 2020) or LPM (Grafström and Schelin 2014). Many NFIs use the variance estimator associated with SRS,based on the argument that it should “safely” overestimate the uncertainty due to sampling. However, this means that the improvement achieved by applying a more efficient sampling design will not be reflected in the reported uncertainties.
A variance estimator associated with SRS is based on the differences in the values of the target variable in the individual sampling units from the overall mean. The idea of reducing the overestimation by replacing these differences with local differences computed within groups of adjacent sampling units was already adopted in the first Nordic NFIs (Lindeberg 1924; Langsaeter 1926). Wolter (1984) gives a review of the later development of such approaches and a recent application can be found in Ene et al. (2013). A generalization of onedimensional local difference estimators to spatially systematic sampling was introduced into forest inventories by Matérn (1947) and has been routinely used in the Finnish NFI since the 5th NFI (Salminen 1973;Heikkinen 2006).
The approximate variance estimator for the LPM, proposed by Grafström and Schelin (2014) and Grafström and Matei (2018) is similar to the local difference estimators used with systematic sampling. In previous studies, the approximate variance estimator has worked well(Grafström and Schelin 2014; Grafström and Matei 2018). However, the study areas have been small and generalization of results for NFI estimation where results are reported at regional level has not been shown. Nor have these studies utilized auxiliary data that would be available in a modern NFI.
Simulated sampling from actual or artificial populations is the only practical approach for evaluating the efficiency of a sampling method and the reliability of the associated variance estimator (Magnussen et al. 2020).However, such simulations can never fully imitate the actual inventory. If we use the “actual population” of direct measurements of an earlier NFI, then only subsets from the whole design can be sampled and the spatial arrangement of plots in the simulated samples will be different (sparser) than in the actual NFI. Possible artificial populations include (i) those generated as realizations from probability distributions that are designed to capture important spatial features of actual forests (e.g.Magnussen et al. 2020) and (ii) wall-to-wall maps of forest resources produced by an MS-NFI. The disadvantages of option (ii) are that MS-NFI methods tend to smooth out some of the spatial variation in the actual forests and that the correlation between the target and auxiliary variables may be smaller in MS-NFI populations consisting of spatial predictions than in actual forests. Then again, the spatial features of populations for option (ii) can resemble those of the target population of the NFI much more closely than (i), because they are based on (earlier) NFI measurements, numeric maps,and satellite images of that specific region. Another advantage of MS-NFI populations is that they can faithfully reproduce the dependencies between different target variables, in particular, if they are based on most similar neighbor or one nearest neighbor(1-nn) imputation.
The aims of this study were to compare LPM with systematic sampling and to assess the reliability of the variance estimators in a context which closely follows the sampling design phase of an operational NFI. SRS was also included in order to facilitate comparisons with other studies. The main results are based on simulated sampling from a wall-to-wall 1-nn forest resource map constructed for this study from the most recent NFI measurements. The auxiliary data for the LPM were derived from the MS-NFI of the previous inventory campaign. Such information would be available when designing a new inventory. We considered several NFI target variables, because an NFI is a multi-target inventory. The impact of using the 1-nn population as a proxy to actual forests was gauged with supplementary sampling simulations from populations of real NFI field plots, contrasting results based on the actual measurements to those based on 1-nn predictions at the same locations.
Methods
Study region
The study region covers a 60,000 km2land area in Southern Finland (Fig. 1). It was chosen to be within one Sentinel-2 image. For the assessment of variance estimators, the region was divided into four subregions so that the area of these subregions was of the same order as that of a typical target region(province)in the Finnish NFI.
MS-NFI forest resource maps
The Finnish MS-NFI of Finland has produced thematic forest resource maps over three decades. Currently the new raster maps are published biannually (http://kartta.luke.fi/index-en.html) and include themes for 44 forest variables. The MS-NFI predictions are computed using satellite data, NFI field data, map data and other digital data sources (Tomppo et al. 2008). The field data are currently computationally updated to the set date, and satellite images as close as possible to the date are used.For each pixel, a prediction is computed using the iKNN method (Tomppo and Halme 2004). The iK-NN method finds the k NFI field plots for each pixel where the feature vectors formed at the field plot locations are closest to the feature vector formed at the pixel regarding the chosen distance measure. The feature vectors include the satellite image spectral radiances, largearea mean volume estimates and other numeric data available at each pixel. The weights of the features in the distance measure are determined by a genetic algorithm.The predictions are computed as a function of the corresponding variables at the k nearest field plots. In this study two independent sets of MS-NFI forest resource maps were utilized. The first map was used as auxiliary data (MS-NFI-2011) and the second as target data (MSNFI-2015).
The auxiliary variables were derived from MS-NFI-2011 (Tomppo et al. 2014), where the set date was July 31, 2011. To produce these maps, the value k=5 was used for mineral soils and peatlands and the value k=3 for open mires (Tomppo et al. 2014; Mäkisara et al.2019). The satellite data was from the Landsat-5 TM images. The area used in this study included parts of several satellite images. The pixel size in the MS-NFI-2011 was 20 by 20 m. The construction of these maps utilized the NFI field data from the years 2007-2011.
The target variables were derived from MS-NFI maps specifically produced for this research. These maps were produced using the value k=1 and based on the materials and methods of MS-NFI-2015 (Mäkisara et al.2019). The choice k=1 was made in order to match the marginal distribution of the predictions with the distribution of the field data as well as possible (Mäkisara et al. 2019). The set date was July 31, 2015, and the satellite data were mostly OLI data from Landsat-8, but it also included some data from the MSI instrument onboard the Sentinel-2 satellite. The pixel size in the MSNFI-2015 was 16 by 16 m. The NFI field data were collected during years 2012-2016.
Field plot data
In a supplementary study, the analyses were limited to the locations of 16,608 NFI sample plots from 1718 clusters measured within the study region during the same period as the training data of MS-NFI-2015,i.e.the years 2012-2016(Fig.2).The study region intersects three different NFI sampling regions. In all of them the sampling design was based on systematic cluster sampling, but the cluster configurations and cluster-to-cluster distances varied between them. Generally, the clusters and distances were smaller in the south than in the north. The distance between the sample plots in a cluster was 300 m in the central and northern part of the study region,while in the southernmost region it was 250 m. The cluster dimensions varied from 1.2 km×1.2 km to 1.5 km×1.5 km. The clusters were organized in five cluster groups which were replicated over the area. In this part of the study, we utilized both the NFI measurements from these plots and the 1-nn predictions (MS-NFI-2015) at their locations.
Target populations
Our sampling simulation aimed to imitate, the operational cluster sampling design of the Finnish NFI and some practically relevant alternatives to it. Thus, our sampling units were clusters of sample plots. To avoid unnecessary complications due to two-phase sampling(see, e.g., Grafström et al. 2017), we also defined the target populations to consist of clusters.
The field plot population of the supplementary study is already a collection of 1718 clusters. In the primary sampling simulations from the 1-nn map, we decided to mimic the NFI cluster of the southernmost part of the study region. Each cluster consisted the locations of eleven sample plot centers arranged in an L-shape with 250 m intervals between neighboring plots. The primary 1-nn population was defined as a dense grid of such clusters over the study region with 50 m×50 m intervals between the corner points of neighboring clusters in the population, and the cluster-level values of the target and auxiliary variables were computed as means over the pixels containing the plot center points.
Population characteristics
The target variables considered in this study include both growing stock characteristics and area proportions(Table 1). The tree species groups in which the growing stock volumes were estimated were spruce, pine and broadleaves. The pine group included mainly Scots pine trees (Pinus sylvestris) but also all other conifer species than Norway spruce (Picea abies). Most of the broadleaf volume consisted of birch trees (Betula pendula and Betula pubescens). Following the convention of the Finnish NFI, the estimation of stock variables was confined to the national forestry land classes: “forest land”and “poorly productive forest land” (Tomppo et al.2011).In this study,the combination of these two classes is called “forested land”; it is close to the forest land as defined by the United Nations Food and Agriculture Organization (FAO 2012). The forested land comprised 71% of the study area and 85% of land area.
In addition to the geographic coordinates, five auxiliary variables were considered: the volume of all trees,volumes by tree species groups, and the forested land proportion of pixels in a cluster (Table 1). This set of auxiliary variables was chosen based on the experience gained in the previous studies (Räty et al. 2018; Räty and Kangas 2019). Spatial autocorrelation in the target datasets, as well as correlations between the target and auxiliary data were quite similar in the 1-nn population and the field plot population (Fig. 3, Tables 2 and 3). Already between the closest sample plots at about 300 meters distance the spatial autocorrelation was of an order of 0.2 or less and decreasing with distance. The mean volume target variables, mean diameter, mean height, basal area, age as well as the area of mineral soils correlated strongly with the auxiliary data. The remaining area proportion variables included two rare classes with shares of~1% of the study region, namely the proportion of forests older than 140 years and open mires,which had negligible correlations with the auxiliary data. Further, the proportion of pine and spruce dominated mires had weak correlations with the auxiliary data(Tables 2 and 3).
Sampling designs
In the context of cluster sampling, simple random sampling (SRS) refers to selecting a completely random subset of clusters in the target population. The sample size n is fixed, each set of n clusters has an equal probability of being selected, and each cluster has the same probability of inclusion in the sample. No auxiliary information or predefined limitations are involved.
In systematic sampling, one random cluster is first selected from the target population and thereafter all the other sample clusters are spread over the study region at predetermined distances from each other. Hence the auxiliary information utilized in (spatially) systematicsampling are the geographic cluster coordinates. In our systematic sampling design, a systematic square grid of clusters was selected at 6 km intervals, yielding a sample size of n=1,678 clusters on average.
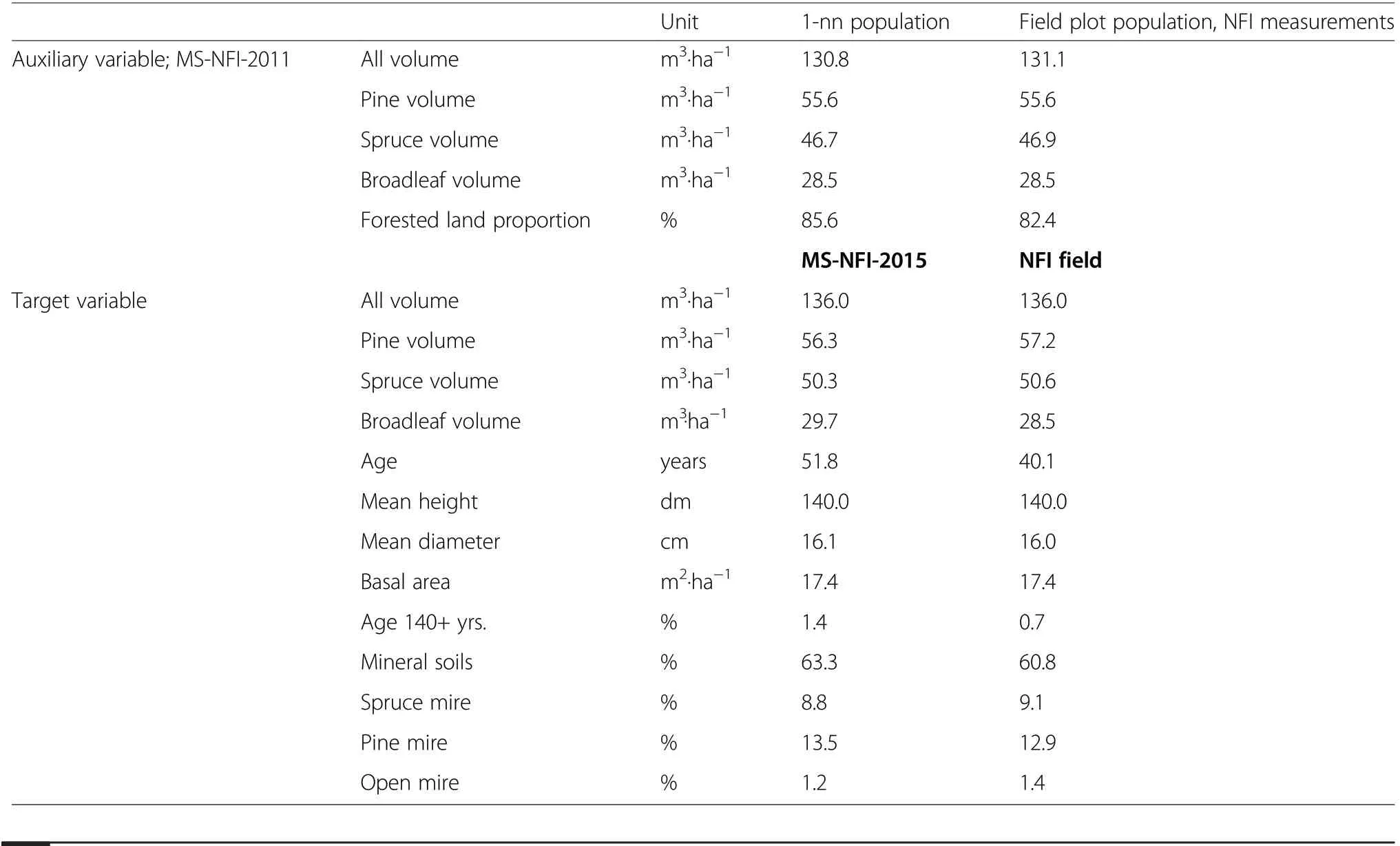
Table 1 Population values for auxiliary and target variables in the study region in the 1-nn population and the field plot population.The target is derived from the MS-NFI-2015 map for the 1-nn population and from the NFI field measurements for the field plot population
The local pivotal method (LPM, Grafström et al. 2012,2017) aims at samples where the empirical distributions of auxiliary variables are similar to the corresponding population distributions. This is implemented by promoting one unit in the sample selection at the expense of the unit closest to it in the auxiliary variable space.The closeness of population units i and j are measured by the Euclidean distance metric between the units’standardized auxiliary variables.
In LPM, an iterative selection algorithm is used to select the sample. We used equal-probability sampling giving a fixed inclusion probability for each observation. In the iterative algorithm, these initially non-zero inclusion probabilities are first assigned to all population units and later they are updated and act as inclusion indicators. In each selection round one population unit, the state of which is not yet determined (i.e., the unit is neither excluded nor included to the sample), is randomly chosen and its closest unit in the group of units with an undetermined state is found. The two units i and j are then compared, and their inclusion indicators updated according to the equation:
In the SRS and LPM the sample size was matched to the same density per land area as in the systematic design. The total number of all possible different samples for the systematic design was (6,000 m/50 m)2=14,400.Results were calculated for each of these. The total number of samples drawn by the SRS and all the LPM designs was at least 56,700.
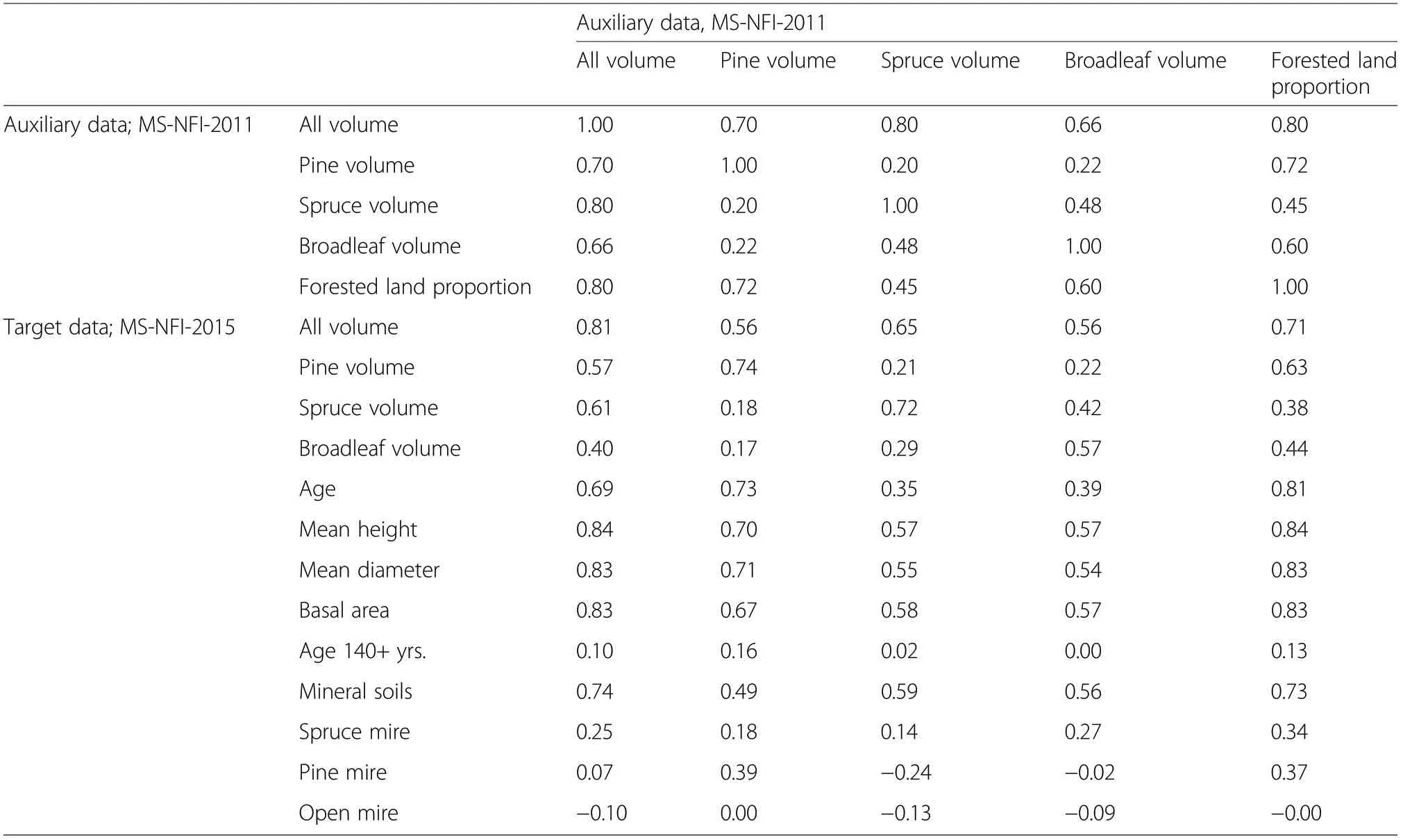
Table 2 Cluster-level correlations between each auxiliary variable with the other auxiliary variables and the target variables in the 1-nn population study

Table 3 Cluster-level correlations between each cluster-level auxiliary variable and the other auxiliary variables in the data itself and the auxiliary data and the target variables in the field plot data study
The supplementary sampling simulations from the field plot population were carried out with a set-up similar to Räty et al. (2018). The sample size in these simulations was 130 clusters. This set-up enabled a comparison of only the SRS and LPM sampling methods. Because the initial NFI population was already a sparse systematic design selecting an even sparser systematic design from it was out of the question. Each sampling design was replicated 100,000 times and results were calculated for each of them.
Evaluation of sampling designs and variance estimators
As a result of the sampling simulations, we thus obtained T samples of clusters from the target populations with each of the sampling methods. Let St, t ∈1, 2, …, T be the set of clusters included in the t’th sample by one of the methods. Following the convention of the Finnish NFI, both the growing stock characteristics and area proportions were estimated from each sample using ratio estimators of the general form
Consequently, REi>1 identified the designs that were more efficient (i.e., with a smaller MSE) than the reference sampling design.
The empirical variance over the replications,
where the sum extends over all groups g of four neighboring clusters of the square grid so that at least one point in the group belongs to the sample St.The z-values corresponding to grid points outside the study region were set to 0(c.f. Matérn 1960, sec 6.7).
For the empirical variance we used the formula (Rao 1973):
All the simulations of the two studies were performed with freely available open software R (R Core Team 2018) and Julia (Bezanson et al. 2017). The function used to perform the LPM was ‘lpm2_kdtree’of the R package ‘SamplingBigData’ (Lisic and Grafström 2018).
Results
Comparison of sampling designs
The MSEs of the target variable estimates for the whole 1-nn population were calculated over all repetitions defined in section sampling designs (Table 5). The means of the target variables coincided with the population values in Table 1 and the estimates were approximately normally distributed around the means.
The REs of SRS for single target variables varied between 0.5 and 1.0 in comparison to the systematic design (Fig. 4).The mean RE of SRS was 0.77.
When considered over all target variables, the mean RE of LPMxy was close to the systematic method and was 0.97. The other LPM designs resulted in slightly larger overall REs than the systematic method on average.However, the differences between the different LPM designs were small: the mean REs varied between 1.06 and 1.09. In addition, the Monte Carlo error associated with the target variable estimation was negligible(Fig. 4).
Examining the results with the all target variables separately, the most efficient sampling design and its efficiency varied (Fig. 4). For the mean volume of all tree species, all the LPM designs including some information on the forest resources had REs close to 1.1. For tree-species-specific mean volumes the largest enhancements were gained with the LPM designs which included auxiliary information on that specific tree species. The maximum REs reached for the mean spruce and broadleaves volume were ~1.1 and for the mean pine volumes ~1.2.
For the variables associated and generally known to correlate with volume, namely the mean diameter, mean height, age and BA, the REs of the LPM designs (other than LPMxy) were between 1.0-1.2. For the main site type class variables, the results differed (Fig. 4, third row): For the class of mineral soils, which encloses the most productive forests, the LPM designs had larger REs than for the poorly productive mires. Further, all the LPM designs including LPMxy were poor for the treeless open mires. In estimations of the area proportion of old forests aged over 140 years all the sampling designs had the same efficiency.
Supplementary field data study
When the population was limited to the field sample plot locations and the efficiencies were estimated against LPMxy, in all cases SRS was the least efficient sampling method(Fig.5).Enhancements at individual target variable level were from 1.2 to 1.4 for the mean volume and stand variables for the LPM designs. For the land class variables all REs were less than 1.2. The REs were typically a bit larger for the target variables derived from the real field data than for the targets derived from the MS-NFI-2015 maps.
Reliability of variance estimators
In simulations of LPMxy, averages of both the Grafström-Schelin estimates ^Vsband conventional variance estimates ^Vsrswere never smaller than the empirical variance over the replicated samples, Vsim(^μ). Taking into account the Monte Carlo error of Vsim(^μ), both^Vsrsand ^Vsbwere significant overestimates in most cases, but ^Vsbmuch less so (Fig. 6). The average deviation from the empirical variance was 7.2% for ^Vsband 24% for Vsim(Additional file 1:Table S1).
In the simulations of systematic sampling, the averages of the ^Vsb(^μt) and the Matérn estimates ^VMat(^μt) over the replications t were practically identical to each other(Fig. 7). The most common result was that they overestimated the empirical variance (they were significantly greater than Vsim(^μ)), but less so than ^Vsrs.However, we also observed underestimation in some cases, most notably for the area of mineral soils in subpopulation 4.
In LPM simulations utilizing other auxiliary variables in addition to the coordinates, ^Vsbunderestimated the sampling variance in several cases. For example, when all auxiliary variables were used in LPM, significant underestimation occurred in almost all the subpopulation results (Fig. 8). For the whole population, the Monte Carlo error of Vsimwas always so small that the error bar ostensibly reduced into a point (Fig. 8),and ^Vsbagreed with it so well that the points are hardly visible.
Discussion
To the best of our knowledge, this is the first study that has compared LPM with systematic sampling in NFI. In previous studies (Grafström and Ringvall 2013;Grafström and Schelin 2014; Grafström et al. 2017; Räty et al. 2018), SRS or LPMxy has been used as the reference when assessing the efficiency of LPM with additional auxiliary variables. We found that for some target variables, LPMxy was markedly less efficient than systematic sampling. This is one reason why our observed REs of LPM designs that are relative to the systematic design were smaller than the REs in previous works relative to SRS or LPMxy.
Several studies have observed enhancements in the estimation efficiency when LPM has utilized auxiliary data correlating with the target variables in addition to the geographic coordinates, (e.g. Grafström and Ringvall 2013; Roberge et al. 2017; Grafström and Matei 2018; Räty et al. 2018). As in Grafström and Ringvall (2013), also in our data, the correlations which we used to explore the explanatory power between the auxiliary and target variables were strong between the mean volume related target and auxiliary data (Tables 4-5). However, compared to the previous studies the improvements in estimation efficiency were modest. In the previous studies (Grafström and Ringvall 2013; Roberge et al. 2017; Räty et al. 2018),the REs were on the level of 1.5-3 relative to LPMxy and 1.1-7.5 relative to SRS depending on the target variable. In our study the overall REs of all designswere markedly smaller, 1.07-1.11 compared to LPMxy and 1.3-1.45 compared to SRS.

Table 4 Combinations of cluster-level auxiliary variables utilized with the LPM designs. The ‘+’ sign indicates the variables included to the design
Our 1-nn target population was a map based on modelling, which adds uncertainty to the pixels in the target maps (Magnussen et al. 2009) compared to earlier studies where, for example, the target has been inventory field data (Räty et al. 2018). In addition, the spatial pattern might be different in the maps than in reality. We gauged the impacts of such deviations from directly observed forest variables in a supplementary study, in which both field observations and 1-nn predictions were available to all population units. The REs of LPM with additional variables vs. LPMxy were larger with the field data than with the map and these larger REs were in line with the previous study by Räty et al. (2018). This implies that the above-mentioned map uncertainty or the spatial differences had some impact on the results. However, the differences were small (Fig. 4).
NFI is a multi-target inventory, which places demands on the considered sampling methods. Therefore, the LPM should also be examined using several variables. In the previous studies the efficiencies have been studied mostly with variables related to the growing stock(Grafström et al. 2017; Räty et al. 2018). One could argue that this is not enough because NFIs deal with dozens if not hundreds of variables (Tomppo et al. 2010;Vidal et al. 2016) and not all of them correlate with the chosen auxiliary variables. For continuous variables, for instance, the mean diameter, mean height, age, and basal area, which are known to correlate with the auxiliary data (volumes), the REs were similar to those for the mean volume of all tree species when compared to the systematic design. Additionally, the area estimates for the main site type classes, which correlated with the auxiliary data, improved with LPM even though more modest REs were detected. On the other hand, if the target variable was a rare and uncorrelated phenomenon, there were two possible outcomes: 1) in the area proportion estimation of old forests, all the sampling methods were equal; and 2) in the area proportion estimation of the open mires, all LPM designs were significantly less efficient than the systematic design (Fig. 4). In the first case,the variable was visually observed to be evenly spreadover the study region and,in the second case, oppositely,the open mires were spatially clustered and more concentrated in the northern part of the study region.Hence, we conclude that efficiency of LPM depends on the chosen auxiliary and target variables and their spatial pattern. Thus, caution should be retained if applied in the NFI for many target variables.
Another concern, when applying LPM in practice, is that gaps or areas of more sparsely placed sample plots in the middle of the inventory region are possible even though the geographical spread is also used besides the other auxiliary data. The NFI results are estimated in many different spatial scales which such gaps may affect.Even though NFIs were originally designed for largescale estimation, the demand for reporting results for smaller and smaller areal units is growing. In Finland,based on the field sample plots the inventory result estimation is solely possible for 3000-5000 km2with the current systematic design (Tomppo et al. 2008), but by combining remotely sensed and other spatial data results can be calculated for municipalities with areas from 6 km2upwards. With the systematic design approach there is no risk of gaps,which may be regarded as its advantage over the LPM.
This and previous studies (e.g. Grafström et al. 2017;Räty et al. 2018)have been based on simulating a sample selection with different sampling methods and designs.However, we observed that the response depended both on the target variable and target dataset. In the 1-nn population the average distance between the clusters was markedly smaller than in the field plot population,which gives another explanation to the differences on the observed levels of the REs in the different study setups. In fact, if in the 1-nn-population we would have sampled using the same average distance as in the field plot population, we would have obtained rather similar results, at least for the mean volume target variables. Besides the cluster distance, we assume that REs also depend on the study region; its size and variability in conditions and forest characteristics. Even though our observations are not generalizable as such, it is worth noticing and considering these aspects in similar types of studies.
In agreement with many previous studies (e.g., Stevens Jr and Olsen 2003; Grafström and Schelin 2014;Magnussen et al. 2020), our results demonstrate that the SRS variance estimator fails to reveal improved precision due to spatially balanced sampling and that local difference estimators are much less biased. In the case of LPMxy, local difference estimators never underestimated the true sampling variance. A guarantee against variance underestimation is important from the practical point of view: we do not want to end up claiming our estimators to be more precise than they really are.
For systematic sampling, the Grafström-Schelin variance estimates were practically identical to the Matérn estimates. This finding lends support to the use of Grafström-Schelin estimator for spatially systematic samples other than rectangular grids, for which the Matérn estimator is not directly applicable. This is relevant, for example, in Finnish NFI, where the sampling design has evolved from a square grid of clusters to a combination of two different grids, one for permanent sample plots and another for temporary plots. Irregular designs also occur, when the estimation is needed over period with partial samples from two consecutive inventories with different systematic designs.
In LPM designs with further auxiliary variables in addition to the geographic coordinates, we found that the Grafström-Schelin estimator tended to underestimate the sampling variance for the subpopulations. This phenomenon may be associated with the domain estimation context (LPM sampling was conducted at the level of the whole population). Some support for this hypothesis was obtained from a spot test, where we generated LPM samples with all auxiliary variables from subpopulation 2. The Grafström-Schelin variance estimates for the ‘All volume’ were at the same level as those computed from the whole-population LPM samples, but the empirical variance of volume estimates was so much smaller that significant underestimation did not occur.
In the case of cluster sampling designs such as here,there is potential for improvement in the definition of the neighborhood for LPM sampling and the Grafström-Schelin variance estimator. The Euclidean distance metric based on cluster-level mean values of the auxiliary variables could be replaced by another metric that would also reflect within cluster variation. For example,cluster-level quantiles of auxiliary variables could be used to identify the most similar cluster. This could affect the efficiency of the LPM algorithm, as very different plot combinations could produce exactly the mean volume within the cluster.
Conclusions
According to our simulation study, LPM designs utilizing auxiliary data can be more efficient than systematic sampling for specific target variables, but it appears to be difficult to make gains in efficiency simultaneously for all target variables of an NFI. In our study, we included thirteen different target variables and for some of them the LPM designs were less efficient than the systematic sampling design. All in all, to make gains in efficiency using LPM, for some target variables it might be necessary to accept smaller efficiencies for other target variables. Nevertheless, even though the use of LPM as a general tool in an NFI seems challenging, it enables unequal probability sampling and fixed-size samples with an approximate spatial balance, which may be useful when designing a special inventory.
In the systematic design, the Grafström-Schelin estimator of variance was practically equivalent to the Matérn estimator applied in the Finnish National Forest Inventory. Both are easy to implement in an operational NFI, but the Grafström-Schelin estimator is more flexible, since it is also directly applicable to geographically balanced designs other than rectangular grids. However,we found that the Grafström-Schelin estimator can underestimate true sampling variance in subpopulation estimates when LPM is applied with other auxiliary data in addition to the coordinates.
Supplementary information
Supplementary informationaccompanies this paper at https://doi.org/10.1186/s40663-020-00266-9.
Additional file 1:Table S1.Simulation results in national forest inventory field plot populations (field) and multi-source national forest inventory populations(1-nn) with different sampling designs and variance estimators.
Abbreviations
LPM: Local pivotal method; MS-NFI: Multi-source national forest inventory;NFI: National forest inventory; NFI11: The 11th national forest inventory;
RE: Relative efficiency;SRS: Simple random sampling;vsb: Grafström-Schelin variance estimator
Acknowledgements
Not applicable.
Authors’ contributions
All authors participated in planning the study. KM constructed the 1-nn forest resource map. MK implemented the analysis. MR prepared the original draft. All authors reviewed and edited the draft and approved the final manuscript. JH and MM supervised the work. AK and MM handled the project administration and funding acquisition.
Funding
The financial support for this study was provided by the Ministry of Agriculture and Forestry key project “Puuta liikkeelle ja uusia tuotteita metsästä” (“Wood on the move and new products from forest”)and Academy of Finland (project numbers 295100 and 306875).
Availability of data and materials
Parts of the data that support the findings of this study are available from the corresponding author upon reasonable request.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Author details
1Natural Resources Institute Finland (Luke), PO Box 2,FI-00791 Helsinki,Finland.2Natural Resources Institute Finland (Luke), Yliopistokatu 6,FI-80100 Joensuu, Finland.
Received: 4 March 2020 Accepted: 25 August 2020

- Forest Ecosystems的其它文章
- Evaluating the impact of sampling schemes on leaf area index measurements from digital hemispherical photography in Larix principis-rupprechtii forest plots
- Discovering forest height changes based on spaceborne lidar data of ICESat-1 in 2005 and ICESat-2 in 2019:a case study in the Beijing-Tianjin-Hebei region of China
- Effects of firewood harvesting intensity on biodiversity and ecosystem services in shrublands of northern Patagonia
- The Siberian moth(Dendrolimus sibiricus),a pest risk assessment for Norway
- Hydrological functioning of forested catchments,Central Himalayan Region,India
- Selective logging enhances ecosystem multifunctionality via increase of functional diversity in a Pinus yunnanensis forest in Southwest China