
A note on the estimation of variance for big BAF sampling
2021-01-11 07:07JeffreyGoveTimothyGregoireMarkDuceyandThomasLynch
Forest Ecosystems 2020年4期
Jeffrey H.Gove,Timothy G.Gregoire,Mark J.Ducey and Thomas B.Lynch
Abstract
Keywords: Bitterlich sampling,Delta method,Double sampling,Forest inventory,Horizontal point sampling,Variance of a product
Introducti on
Double sampling is a method employed in forestry that samples a population in two phases over a set of sample units. The primary sample includes all sample units and trees that meet the criterion for selection, on which one or more measurements related to the main attribute of interest are recorded to be further assessed on the second phase sample.The second phase normally includes more detailed measurements on a subset of whole sample units or a subset of individual trees within all primary sample units (e.g. Bruce 1961; Bell et al. 1983; Odewald and Jones 1992).For example,in point double sampling,trees are counted on a large number of sample points using a relascope to estimate basal area per hectare, but measurements of individual trees needed to compute other variables (such as volume per hectare) are confined to a subsample of the points. More details on double sampling in forestry can be found in Gregoire and Valentine(2008, p. 262) and de Vries (1986, p. 104). Big BAF sampling (Marshall et al. 2004) is a simple form of double sampling that can be used in a horizontal point sampling(HPS)inventory.The target attributes are frequently basal area and volume, though more measurements could be taken to estimate the density as well; and recently Chen et al.(2019)have demonstrated its use for the estimation of carbon rather than volume.The big BAF method uses two basal area factors(BAFs)on the same full set of sample points in a forest inventory: the smaller BAF is used to select a sample for the estimation of basal area (the BAFcsample),while the larger BAF is used to select trees on which to take more detailed measurements for volume estimation (the BAFvsample). Therefore, the relation to double sampling comes about not through a second phase subsample of individual points, but by using the larger BAF to select a subset of trees from the full set of inventory points as the second phase sample.
The big BAF method has evidently been suggested several times prior to its actual adoption as a form of double sampling. Iles (2012) notes that in the United States Grosenbaugh(1952,p.35)may have been the first to suggest something that resembles big BAF when he somewhat casually noted,in reference to horizontal point sampling, that “An obvious adaptation is to use a larger critical angle to obtain a smaller sample of the average ratio,while using a smaller critical angle to obtain a larger sample of average basal area per acre.” Iles (2012) also notes that Grosenbaugh mentioned the use of two prism factors in an earlier letter to Wheeler in 1949. The next published mention of using two prism factors in a double sampling context was the suggestion by Bell et al. (1983 p.702),but was not formalized until Marshall et al.(2004)described the method in detail.Since that time it has also been included in several texts on forest mensuration and sampling (e.g., Gregoire and Valentine 2008, p. 268 and Kershaw et al.2016,p.377).
In addition to the aforementioned papers,several other studies have used big BAF sampling. Corrin (1998),Crowther (1999) and Desmarais (2002) all give practical examples of the use of big BAF in operational field inventories in both the eastern and western forest types of the U.S. and Canada. Brooks (2006) followed with a more detailed analysis of sampling an even-aged Appalachian hardwood forest with the big BAF method that used 13 different “big” BAFs paired with 6 different “small”BAFs, all of which were compared against a fixed-radius plot inventory. In a more recent study, Rice et al. (2014)evaluated several different sampling schemes including fixed-area plots, various BAFs under HPS, big BAF, and horizontal line sampling.Sampling was conducted in partial harvests in the Acadian mixedwood forest type in northern Maine.In each case a second phase sample was chosen with either a fixed number of trees or a second large BAF. Only the smallest BAF under HPS turned out to be better than big BAF in terms of standard error.In a comprehensive study on an Acadian forest in New Brunswick, Canada, Yang et al. (2017) analyzed how the interplay between sample size and choice of BAFs affects the costs of a big BAF sample, and determined optimal sampling plans under cost-constraints.A follow-up study by Chen et al. (2019) used a suite of simulations and the cost models of Yang et al. (2017) to show how big BAF sampling could be readily applied to the estimation of carbon.
Big BAF background
Here mvsis the number of BAFvtrees measured for volume on the sth point; it follows that the total number of trees sampled for volume is therefore mv=∑ns=1mvs.It is important to realize that in(2)the total number of VBAR trees(those trees on the BAFvsample for which volumes have been measured)must include replicates for any tree sampled on more than one point.The double sum ensures that the summation over the n sample points will include multiple counts on the point-wise tallies.
The full set of counts with BAFcon all n points provides an estimate of the average basal area given by the designunbiased(Palley and Horwitz 1961)estimator
The product of the mean VBAR and basal area gives an estimate of the volume under big BAF leading to the familiar estimator
Because this estimator is the product of two random variables—in this case derived from the above estimators—its variance is estimated by the variance of a product. As noted by Iles (2012), the usual double sampling variance can not be applied because of the design of the big BAF method.That is,the second phase sample is carried out on all sample points(with the larger BAFv)so the first and second phase sample sizes are equivalent in terms of the number of sample points.In addition,Lynch et al. (2021, in press) point out that the big BAF estimator in (4) is a ratio estimator and thus contains a bias(see also Palley and Horwitz(1961)for a double sampling application).These authors derive the bias,which in most practical cases should be small and can safely be ignored.
The exact variance of a product was popularized by Goodman(1960),who also presented an unbiased estimator of the variance that is applicable to big BAF sampling as follows
Historical background
It has been noted(e.g.,Marshall et al.2004;Gregoire and Valentine 2008, p. 259) that Bell and Alexander (1957)were the first to employ a version of the product variance in the calculation of standard error for(4).Their familiar form for the estimator was written in terms of standard error as a percent;viz.,
Somehow, perhaps simply through the Bruce (1961) reference being better known to foresters (alternatively,perhaps Bruce had popularized it in unpublished works that were used by Bell and Alexander (1957)), (8) has become commonly known in the United States as“Bruce’s method,” even though the latter was not published until several years after Bell and Alexander (1957). Additional attribution for (8) is often shared between Bruce (1961)and Goodman(1960)in these references as well as others(e.g.,Chen et al.2019;Iles 2012;Yang et al.2017),where it is sometimes also noted that Bruce’s method derives from the first two terms of(5)(e.g.Marshall et al.2004).
Of course there is a small problem here, because (8)was known to foresters(Bell and Alexander 1957)before the Goodman(1960)paper was ever published.Therefore,attributing (8) to the first two terms of (5), for example,while mathematically correct,can not possibly be chronologically true. Clearly the above authors know this; thus,their statements linking the two derive from this recognition of the mathematical relationship,and are not meant to suggest lineage. Where then did Bell and Alexander(1957)come up with(8)?There are two obvious possibilities that are plausible answers to this question. First, it turns out that Goodman(1960)was not the first author to publish the exact variance of a product.In fact,in a reference that would probably have been rather obscure at the time,Barnett(1955)published a succinct derivation of the exact product variance for two independent random variables. Thus, it is possible that Bell and Alexander (1957)were aware of this reference and considered the third term small and extraneous, therefore dropping it. However, given that the reference appeared in the actuarial literature, this seems the less likely of the two explanations. A second and perhaps more plausible explanation lies in the fact that an approximation to the exact variance of a product had been known in statistics and used in published studies for decades prior to the 1950s.This variance approximation is derived through a Taylor series expansion and is commonly known as the Delta Method(see the“Methods”section and Supplementary Material for more details).
The motivation for this study then is two-fold. First,we will demonstrate that the Delta method yields Bruce’s method when the covariance terms in the first-order Taylor series expansion are truncated, leaving only the variance terms when independence of (2) and (3) is tenable.The second objective is to illustrate just how close the approximation and the exact variances are using a small simulation study. The close agreement between the two has been pointed out before (e.g., Gregoire and Valentine 2008,p.259;Marshall et al.2004;Iles 2012),where it has been noted that the third term in(5)is quite small in relation to the first two,which dominate.In concert with these objectives, we demonstrate that the ratio variance estimator may provide a useful alternative to the normal sampling variance for the variance of ¯V. Much like the recent paper by Kerr(2014),who cleared up some misconceptions in the literature about the historical attribution of “de Liocourt’s q” distribution, our intent is chiefly to clarify the possible lineage of Bruce’s method in a historical context. Again, much like the paper by Kerr (2014)where it is almost assuredly true that others had recognized the missattibution of q to de Liocourt but never published the observation,we also acknowledge‘up front’that much of this material may be already known and understood by those who are students of the history of forest biometrics,but have never written these results up,perhaps feeling they were‘universally’known within the discipline.
Methods
The variance of a product
A careful reading of Goodman’s 1960 paper presents a detailed, though somewhat abstruse description of the derivation of the exact variance of a product of two random variables. Formulas for the case of independent random variables and independent estimators (i.e., the sample mean)are given as well as associated forms when independence can not be assumed. The notation can be difficult in places. We present a slightly different derivation (Supplementary Material Section S.3.1) that may be somewhat easier to follow.In a companion paper,Goodman(1962)extended the results to more than two random variables.This followed with a paper on the exact covariance for products of random variables by Bohrnstedt and Goldberger (1969). All of the authors mentioned previously who have used big BAF sampling have assumed independence either implicitly, or explicitly by citing a small correlation between ¯V and ˆBc. In such cases, the exact variance of the product estimator given in(5)should be used; a somewhat more tractable version of the full variance is presented in Eq. (S.12) of the Supplementary Material.
The Delta method
Goodman(1960,p.708)refers to“the usual formula”for the variance of a product as an“approximation”and cites“Yates(1953,p.198)”as one source for this formula.This edition of Yates(1953)is unavailable to the authors,however, in both Yates (1949, p. 198) and in a later edition(Yates 1981,p.189-190)we find what we assume to be the same approximation referred to by Goodman(1960)along with an extension when the random variables can not be assumed independent.The exact same wording is used in each of these editions;therefore,it is reasonable to assume that the presentation in the edition cited by Goodman is identical or nearly so. The genesis of the approximation is unfortunately not given in the Yates reference either;however,it is indeed the Delta method.
The Delta method was evidently well known in statistics at the time, though it was not always referred to as such and sometimes the results were simply stated as in the Yates (1981) reference. Ver Hoef (2012) presents an interesting history of the Delta method and traces its roots back to Dorfman (1938). In a comment on this paper, Portnoy (2013) suggests that its origins go back further and found the earliest reference was a paper by Friedrich W. Bessel (who also gave us the unbiased correction to the sample variance estimator) published in 1838.In twentieth-century statistics,Portnoy(2013)again mentions Doob(1935)who notes“There is a well-known δ-method used in statistics to find limiting variances of statistics” (p. 167) and goes on to cite two earlier works that employed it.A perhaps more popular source that covered the Delta method and was certainly available in the 1950s was Cramér(1946,p.353)who also provides a proof of the Delta method for the mean and variance.
As noted previously, the Delta method is a first-order approximation to the variance using a Taylor series expansion. The derivation for the sample variance approximation is given in Supplementary Material(see Section S.2).The Delta method yields an approximate estimator for the variance of the mean for big BAF sampling under the assumption of independence from Eq.(S.7)as
The ratio variance estimator
There is another method by which the variance of ¯V may be estimated as an alternative to using the usual sampling variance of the mean presented in(6).Gregoire and Valentine(2008,p.259)have suggested that because ¯V is actually a ratio estimator,then the ratio variance estimator would be an appropriate alternative to(6).They note that this may be worth considering if the actual variance of ¯V is of interest in and of itself.However,a comparison of the two variance estimators in the context of their use in the product variance estimator for big BAF sampling may be of some interest as well if there is reason to favor one over the other.
It is straightforward to show (Gregoire and Valentine 2008,p.258)that the big BAF estimator for volume(4)can be written as
Simulation experiments
The simulation experiments were conducted on two different small populations of trees.The simulator used was the sampSurf package(Gove 2012),which was developed for the R statistical analysis system (R Core Team 2020).The sampSurf simulator employs the simple model of a“sampling surface” (Williams 2001a; 2001b) in which a raster tract with area A is tessellated into square grid cells of fixed area.Trees are added to the tract,and their inclusion zones are created based on the sampling method—in this case horizontal point sampling. Each grid cell has a conceptual sample point at its center,the total for the cell is accumulated for all trees whose inclusion zone includes the grid cell center.The surface itself therefore,is the total attribute value of interest over all grid cells. The tracts used here are square with a grid cell size of 1 m2for both of the simulated populations.
The experimental design employed nine sets of simulations using all combinations of the BAF pairs (Fc,Fv)with Fc∈{3,4,5} and Fv∈{10,20,30} for each population. For each simulation, four sampling surfaces were constructed: one each for total volume and basal area using each of the two BAF sets. This yielded 36 total sampling surfaces on each of the two populations. For each of the 9 simulation sets in each population,random samples of size n = 10,25,50,and 100 were drawn in a Monte Carlo experiment that was replicated 1,000 times.For each sample on each sampling surface the requisite summary statistics for HPS and big BAF sampling were computed.Thus,because both basal area and volume surfaces were created for each pair of big BAF factors (e.g.,(Fc,Fv)=(3,10))various quantities that are not available in a typical field big BAF inventory,such as individual tree VBARs for all selected trees on the count sample(from the BAFcvolume sampling surface),were available in the simulations.This allows,for example,the comparison of the big BAF results with that of a full HPS inventory where all trees are measured on the BAFcsample.The simulations conducted here are modest in extent when compared with e.g., Chen et al. (2019), but they serve to illustrate the similarities in variance estimators.
The mixed northern hardwood population
The mixed northern hardwood tree population is a somewhat larger version of the population used in Gove(2017);it is completely synthetic and is contained on a tract with a total area A = 3.17 ha (31,684 grid cells). An external buffer with width 18 m encloses the internal stand with an area of 2 ha.The internal portion of the tract was populated with m = 667 trees having a total basal area of 48.4 m2(approximately 333 trees·ha−1with a basal area of 24.2 m2·ha−1)giving a quadratic mean stand diameter of ¯Dq=30.3 cm.This places the stand in the fully stocked region of the northern hardwoods stocking guide (Leak et al. 2014). Tree diameters at breast height were generated from a three-parameter Weibull distribution(Bailey and Dell 1973) with location, shape, and scale parameters α = 10 cm, γ = 2, ζ = 20 cm, respectively. The associated tree heights were generated using a metric version of the all species equation for northern hardwoods in New Hampshire(Fast and Ducey 2011)augmented by an additive Gaussian perturbation with standard deviation of 2.5 m.The trees were distributed throughout the internal tract area using a spatial inhibition process with inhibition distance of 3 m(Venables and Ripley 2002,p.434).Boundary overlap was corrected by allowing the inclusion zones to penetrate into the buffer region(Masuyama 1953;Gregoire and Valentine 2008,p.224).Individual point samples drawn according to the Monte Carlo scheme described above are allowed to fall anywhere within the entire tract region A, thus preserving the full inclusion probabilities for each tree.
The sampSurf simulator requires taper data for each tree,either from direct measurements or generated from an appropriate taper function. The following built-in default taper function(Van Deusen 1990)for diameter at height 0 ≤h ≤H was used in the generation of each tree
The eastern white pine population
The eastern white pine(Pinus strobus L.)population was created from Barr & Stroud FP-12 dendrometry data taken over a 20-year period in various pure, even-aged white pine stands in southern New Hampshire(see Gove et al. 2000 for more details). The dendrometry measurements were processed using the R Dendrometry package(Gove 2011a). The population is composed of m = 316 white pine trees,some of which were measured more than once during this period. This population is set within a tract of 1 ha in size with an 18 m buffer surrounding it to fully contain the inclusion zones,yielding a total tract size of A = 1.85 ha(18,496 grid cells).The total basal area for the population is 47.2 m2, yielding ¯Dq= 43.6 cm. This places the stand well within the range of full stocking on the eastern white pine stocking guide (Leak and Lamson 1999).The trees,having been measured in multiple stands without location information,were distributed within the internal tract area using a spatial inhibition process with inhibition distance of 3 m, similar to the northern hardwood stand. Boundary overlap was again handled using Masuyama’s method in the simulations by allowing sample points to fall in the buffer outside the internal 1 ha tract area containing the trees. Because the white pine population was dendrometered, these measurements provide the taper data for the sampSurf simulator rather than a taper equation.Within sampSurf,such data are modeled using a cubic spline fitted to the raw measurements for each individual tree (Gove 2011b), though calculation of volumes is via Smalian’s method (Kershaw et al. 2016,p. 141). Histograms of the white pine DBH and height distributions are shown in Figure S.5.
Results
The sampling surface results from the population specifications given in the previous section are found in Table 1.Note that the resulting surface estimates of volume and basal area are quite close to the population values for each species. An example set of sampling surfaces with Fc= 3 and Fv= 30 is presented in Figures S.1 and S.4 for the northern hardwoods and white pine populations, respectively. The surface results in Table 1 clearly illustrates the higher stocking of volume and basal area in the white pine stand than for the hardwoods, which mimics what would often be found in practice when comparing fully-stocked stands of these forest types in New England. The species histograms also indicate that the northern hardwoods diameter distribution(Figure S.2)is more positively skewed than the white pine distribution(Figure S.5), and the tree heights are shorter in general for the hardwoods, which, combined with the synthetic taper equation used for the hardwood volumes accounts for much of the difference in total volume between the two populations. Thus, the white pine, while on a tract half the size of the hardwood tract,and with half the population size,still carry much higher volume per tree than the hardwoods.
The coefficients of variation in percent(CV%)(see,e.g.,Freese 1962, p. 13) are given in Table 1 for both volume and basal area.The results clearly demonstrate that as the BAF increases, the population variance increases, yielding a larger CV%. This is a natural phenomenon of the variance that is related to a smoothing of the sampling surface itself as the inclusion zone size(or plot size)expands.In this case, the related BAFs for both volume and basal area demonstrate that the larger inclusion zones produce smaller variance. This phenomenon is a consequence of the so-called ‘empirical law’ of the variance first recognized by Smith(1938).In forestry it was applied in terms of the CV(Freese 1961)and extended to the variable plot method by Wensel and John (1969) (see, e.g., Gove 2017 or Lynch 2017 for recent literature reviews). The CV%for the northern hardwoods is consistently lower (with the exception of Fv= 30) for both volume and basal area, presumably due to the shorter, smaller diameter trees compared to the white pine population. The sampling efficiency is defined as the percentage of surface grid cell centers—or sample points—that are covered by one or more inclusion zones. Of course, this must decrease with increasing BAF in accord with the process behind the prior observations on the inclusion zone size in relation to overall surface variance.
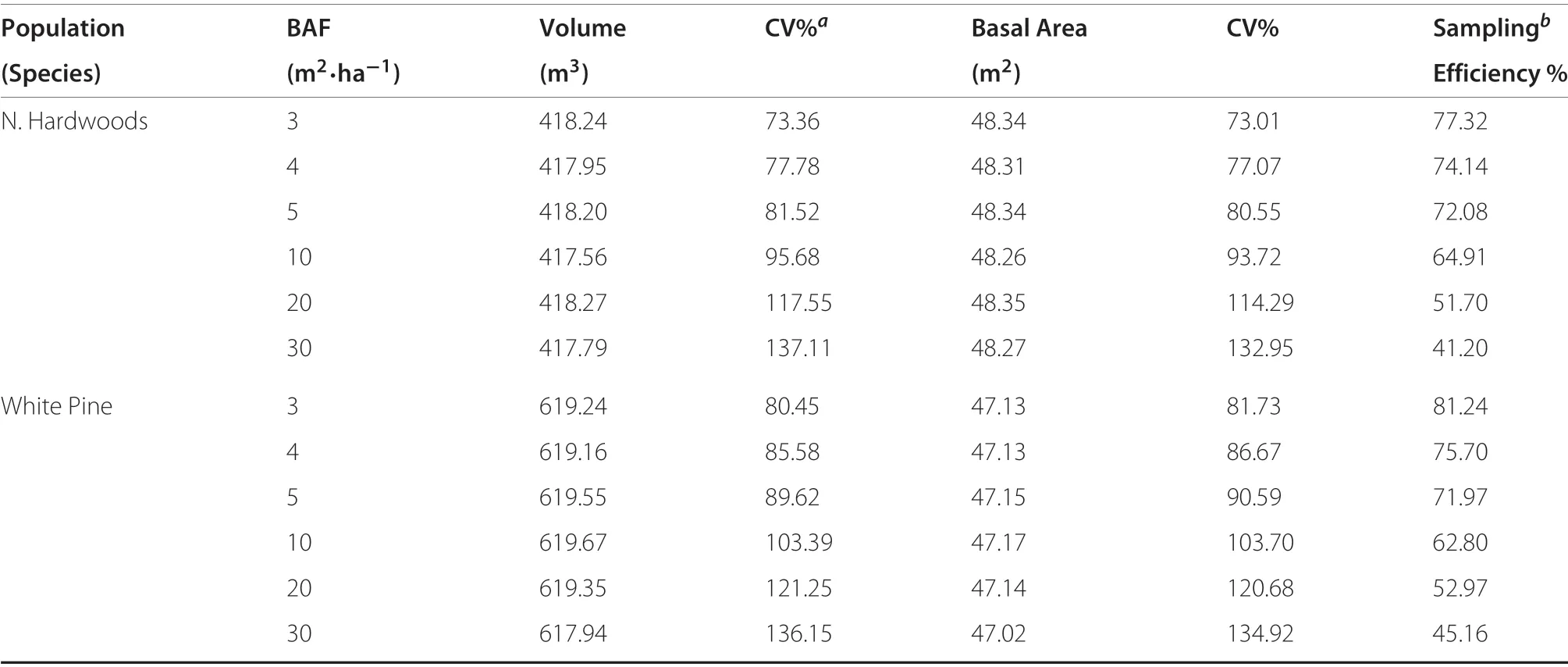
Table 1 Sampling surface statistics for the northern hardwoods and white pine simulated populations.The northern hardwood population of 667 trees had a total basal area of B=48.4 m2,with volume of 418.5 m3.The white pine population of 316 trees had total B=47.2 m2 and volume of 619.6 m3
Monte Carlo simulations
Observed sample ratios
Tables S.1 and S.3 illustrate that there are several combinations of BAFs that produce similar population sample ratios. For example, BAF pairs of (Fc,Fv) = (3,20)and (5,30) both yield approximately six count trees per volume tree. The companion results in Tables S.2 and S.4 present the standard deviations for individual Monte Carlo replicate sample ratios by sample size. Note that the (3,20) BAF pair tends to have smaller variation in observed sample ratios than the larger (5,30) pair over all sample sizes for both populations. One might argue that this could be due to the fact that the (3,20) pair samples almost one more count tree per volume tree than the (5,30) pair. However, this trend seems to hold for other similar combinations, where the sample intensity is reversed. For example, the(3,10) and (5,20) pairs have sample ratios of three to four count to volume trees,respectively, and again the smaller pair of BAFs has the smaller variation in observed sample ratios, even though the larger pair samples relatively more count trees on average for both populations. However, this trend is not universal.It is quickly observed that within a given BAFvgauge and sample size, n, the variability in sample ratio decreases with increasing BAFc. Similarly, the variability increases with increasing BAFvfor a given BAFc.The increase in this latter case is much larger than for the former. Evidently a plausible explanation for this phenomenon is that as the BAFs converge,the target sample ratios also decrease; and in the limit, this decrease simply yields a sample taken with one BAF as under traditional HPS.Thus,it appears that the larger the difference between the BAFs, the larger the variation in hitting the target sample ratio.Finally,as expected,the Monte Carlo sample ratio variability decreases within a given BAF pair as sample size increases in accord with the convergence to Gaussian distributions(e.g.,Figures S.3 and S.6).
Standard error comparisonssee the magnitude of the difference),though convergence increases as BAFcincreases.
Confidence interval capture rates
The confidence interval capture rates for the white pine population are found in Figure S.10.The rates are again all nominally 95%and range within the Monte Carlo experiments from 93.2%-96%.This slightly wider range for capture results, as compared with the northern hardwoods,may reflect the marginally higher degree of variability in individual tree size within the white pine population as compared to the northern hardwoods. Indeed, even the HPS intervals vary from 93.2%-95.9%, covering essentially the full range of variability in the big BAF results.However,none of the capture rate results is unreasonable for a variable population in comparison to the nominal level. And in general, the degree of concordance between each of the different variance estimator combinations for big BAF sampling is remarkable and more consistent than in the less variable northern hardwoods population.
Correlation
The reason for examining the correlations between VBARs and basal area relates to the question of whether the simple Delta method or Goodman’s method variance estimators in Eqs. (9) and (5) are relevant, or whether more terms are required to account for covariances in the case where independence is untenable. However, as discussed in more detail later,the question of how exactly to calculate the relevant correlations is not a straightforward one—in fact it is a bit of a conundrum.For now,we present the results for three approximate estimators for the correlation.In addition,the population correlation,ρ(Vi,bi),i = 1,...,m, was computed on an individual tree basis over all trees in each population.
Discussion
The Delta method has been suggested here as the potential antecedent to what foresters call “Bruce’s method.”In addition, the suggestion has been advanced that the Delta method was a well-known method for approximating the variance of a product of two random variables at the time when Bruce’s method evidently first appeared in the American literature on forest sampling by Bell and Alexander (1957). It can be conjectured that their application was either adopted by Bruce (1961) (though not cited there), or alternatively that Bruce (1961) may have known about it independently. However, another source contemporary to these authors that covers various aspects of forest sampling is that of Freese (1962).It is interesting to note that Freese (1962) evidently also knew about the Delta method approximation and advocated its use(Goodman’s method was published a couple years earlier, though Freese may not have been aware of its existence at the time). In fact, he gives a version(i.e., Freese 1962, p. 17) of the full first-order expansion that includes the covariance and is equivalent to Eq.(S.10).Similar to the aforementioned authors,however,he gives no source for this equation. Again, we are left with the conjecture that the Delta method was a well-known method in use in statistics at the time, in fact, so much so, that it was unnecessary to give citations when it was used.
The ramifications of the previous discussion are that if a correlation is computed based on aggregation,it is bound to be misleading at best. In addition, the covariance on which it is based,and which is the real basis for the problem because of its need for commensurate support, will also be incorrect no matter how the tree-wise VBARs are aggregated. Thus, there seems to be little possibility of using either the Delta method or Goodman’s method in the extended case(i.e.,either Eqs.(S.10)or(S.12))where there may be correlation since neither the indicator of such, ˆρ, nor the covariance itself can be properly formulated.This seems to be a peculiarity in the application of either the Delta method or Goodman’s method to big BAF sampling(via Bruce’s method)that does not manifest itself in other applications of these methods.This is because in general applications the sample support will normally be the same for both components of these composite variances.There appears to be no immediate solution to this dilemma with the problem as traditionally formulated. It is suggested that the only reasonable application of(9)or(5)is where no aggregation procedure is used to approximate the correlation or covariance in big BAF sampling.Fortunately,as noted in the simulation results,both methods appear to work well as judged by confidence interval capture rates in the big BAF setting.
In the simulations, we compared the results of using two different methods for calculating the standard error of tree VBARs, the normal theory (6) and ratio (12)estimators. In general, the results were indistinguishable between the two estimators, with the exception of the combination of the smallest sample size and largest BAFvs.In such cases,there was a small but operationally insignificant difference between the two.Thus,we can not recommend one over the other in general, other than to use the one that is most appealing.However,there is one interesting (but hopefully unnecessary in practice) case where the ratio variance is clearly superior. In the case where only one tree(mv= 1)is sampled with BAFvover all points, the standard estimator (6) fails because of the sample size of one.The ratio estimator,however,is based on the number of sample points;therefore,the only time it can not be used to estimate a variance for VBAR trees is when no trees at all are sampled(or n = 1).Again,this is simply pointed out here as a curiosity and we caution against using this little observation in practice for obvious reasons.
There are other variance estimators that can be applied to big BAF sampling. Two nonparametric approaches are the jackknife and bootstrap estimators. Some simulations were run using these estimators, but there was no apparent advantage to their use in terms of standard error or confidence interval coverage rate. In addition,the usual HPS estimator for variance in volume was calculated in the simulations for the BAFvsample, similar to that presented here for the BAFcsample (the target variance estimate in the simulation results).However,predictably,the results of these estimates were much higher than those reported in the standard error comparisons.In addition, the confidence interval capture rates were also consistently higher than the nominal level, on the order of 95.3%-99.9%,with the rates increasing with increasing BAFv.
Conclusions
The origins of Bruce’s method as a variance estimator in double sampling designs, and specifically the big BAF method, appears to be unknown as it was used in early publications with no citation given. A plausible explanation for Bruce’s method has been given through the derivation of the Delta method, which was known and used in the statistics literature and popular texts prior to the use of Bruce’s method. The relationship of the Delta method approximation to Goodman’s method is quite well-known and was mentioned by Goodman (1960),who post-dates the original use of Bruce’s method in forestry.The simulation results show that there is no practically important difference between the approximate and exact methods,as would be expected based on the small variance cross-product difference between the two. Furthermore, our results have demonstrated that one has a choice between two different methods for calculating the variance of the tree VBARs,again with no discernible difference in practice,except when very few trees are chosen with the BAFvgauge in the second phase sample. We caution that there does not seem to be an exact method for the determination of the covariance or correlation between tree VBARs and basal area point counts because of the disparity in sample support under the usual interpretation of(4)used here;however,there is an alternative interpretation under development that will accommodate a true point-wise covariance and correlation interpretation (Lynch et al. 2021, in press). This suggests that using an approximate correlation from aggregation to determine whether the corresponding covariance approximation term is required should not be recommended.The simple Bruce’s method(Delta method)appears to be robust enough based on the capture statistics that it is probably a good approximation in most cases.
Supplementary Information
The online version contains supplementary material available at https://doi.org/10.1186/s40663-020-00272-x.
Additional file 1:Supplementary Material:A Note on the Estimation of Variance for Big BAF Sampling.
Abbreviations
BAF:Basal area factor;BAFc:Count sample basal area factor;BAFv:Volume sample basal area factor;HPS:Horizontal point sampling;VBAR:Volume to basal area ratio
Acknowledgements
In recognition of his many contributions and insights in areas relating to forest inventory,and his influential teaching and mentoring of many students,professionals and inventory scientists,we dedicate this paper in memory of our esteemed colleague Dr.John F.Bell.The authors also thank two anonymous reviewers for their helpful comments.
Authors’contributions
JHG designed the study,contributed to the derivations,wrote the majority of the manuscript,wrote the R code and conducted the simulations.TGG contributed to the derivations,and with MJD and TBL assisted in the study design in addition to contributing ideas,text,and comments to the manuscript.The findings and conclusions in this publication are those of the authors and should not be construed to represent any official USDA or U.S.Government determination or policy.All author(s)read and approved the final manuscript.
Funding
MJD:Support was provided by Research Joint Venture Agreement 17-JV-11242306045,“Old Growth Forest Dynamics and Structure,”between the USDA Forest Service and the University of New Hampshire.Additional support to MJD was provided by the USDA National Institute of Food and Agriculture McIntire-Stennis Project Accession Number 1020142,“Forest Structure,Volume,and Biomass in the Northeastern United States.”TBL:This work was supported by the USDA National Institute of Food and Agriculture,McIntire-Stennis project OKL0 2834 and the Division of Agricultural Sciences and Natural Resources at Oklahoma State University.
Availability of data and materials
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Author details
1USDA Forest Service,Northern Research Station,271 Mast Road,Durham NH,03824,USA.2School of Forestry&Environmental Studies,Yale University,360 Prospect St,New Haven CT,06511,USA.3Department of Natural Resources and the Environment,University of New Hampshire,114 James Hall,Durham NH,03824,USA.4Professor Emeritus,Department of Natural Resource Ecology and Management,Oklahoma State University,Ag Hall Room 008C,Stillwater OK,74078,USA.
Received:8 April 2020 Accepted:13 October 2020ReferencesArvanitis LG,O’Regan WG(1967)Computer simulation and economic efficiency in forest sampling.Hilgardia 38(2):133-164 Bailey RL,Dell TR(1973)Quantifying diameter distributions with the Weibull function.Forest Sci 19:97-104 Barnett HAR(1955)The variance of the product of two independent variables and its application to an investigation based on sample data.J Inst Actuar 81(2):190 Bell JF,Alexander LB(1957)Application of the variable plot method of sampling forest stands.Research Note 30,Oregon State Board of Forestry,Salem,OR.22 pages Bell JF,Iles K,Marshall DD(1983)Balancing the ratio of tree count-only sample points and VBAR measurements in variable plot sampling.In:Bell JF,Atterbury T(eds).Renewable resouce inventories for monitoring changes and trends,College of Forestry.Oregon State University,Corvallis.pp 699-702 Bohrnstedt GW,Goldberger AS(1969)On the exact covariance of products of random variables.J Am Stat Assoc 64(328):1439-1442 Brooks JR(2006)An evaluation of big basal area factor sampling in appalachian hardwoods.North J Appl Forest 23(1):52-65 Bruce D(1961)Prism cruising in the western United States with volume tables for use therewith.Tech.rep.,Mason,Bruce&Girard Consulting Foresters,Portland,Oregon Chen Y,Yang TR,Hsu YH,Kershaw,Jr JA,Prest D(2019)Application of big BAF sampling for estimating carbon on small woodlots.Forest Ecosyst 6(13):1-11 Corrin D(1998)A very efficient sampling method for cruising timber.Tech.rep.,John Bell Associates.http://www.john-bell-associates.com/guest/guest43a.htm.Accessed 08 Apr 2020 Cramér H(1946)Mathematical methods of statistics.Princeton University Press,Princeton,NJ Crowther R(1999)Eagle lake ranger district and the“big/little BAF”concept.Tech.rep.,John Bell Associates.http://john-bell-associates.com/guest/guest46.htm.Accessed 08 Apr 2020 de Vries PG(1986)Sampling theory for forest inventory:A teach yourself course.Springer-Verlag,Berlin Heidelberg Desmarais KM(2002)Using BigBAF sampling in a New England mixedwood forest.Tech.rep.,John Bell Associates.http://www.john-bell-associates.com/guest/guest58b.htm.Accessed 08 Apr 2020 Doob J(1935)The limiting distributions of certain statistics.Ann Mathemat Stat 6(3):160-169 Dorfman R(1938)A note on the δ-method for finding variance formulæ.Biom Bull 1(4):129-137.Memorial Foundation for Neuro-Endocrine Research and Research Service of the Worcester State Hospital,Worcester,MA
Fast AJ,Ducey MJ(2011)Height-diameter equations for select New Hampshire tree species.North J Appl Forest 28(3):157-160
Freese F(1961)A relationship of plot size to variability.J Forest 59:679
Freese F(1962)Elementary forest sampling.Agricultural Handbook No.232,US Department of Agriculture,Forest Service.Superintendent of Documents,U.S.Government Printing Office,Washington,D.C.91 pages
Goodman LA(1960)On the exact variance of products.J Am Stat Assoc 55(292):708-713
Goodman LA(1962)The variance of the product of k random variables.J Am Stat Assoc 57(297):54-60
Gove JH(2011a)The dendrometry package.https://r-forge.r-project.org/projects/dendrometry/.Accessed 08 Apr 2020
Gove JH(2011b)The“Stem”Class.http://CRAN.R-project.org/package=sampSurf.Accessed 08 Apr 2020
Gove JH(2012)sampSurf:Sampling surface simulation.https://r-forgerprojectorg/projects/sampsurf/.Accessed 08 Apr 2020
Gove JH(2017)Some refinements on the comparison of areal sampling methods via simulation.Forests 8(393):1-24
Gove JH,Valentine HT,Holmes MJ(2000)A field test of cut-off importance sampling for bole volume.In:Hansen M,Burk T(eds).Integrated tools for natural resources inventories in the 21st century,General Technical Report NC-212.U.S.Department of Agriculture,Forest Service,North Central Forest Experiment Station,St.Paul.pp 372-376.https://www.srs.fs.usda.gov/pubs/10276
Gregoire TG,Valentine HT(2008)Sampling strategies for natural resources and the environment.Applied environmental statistics.Chapman&Hall/CRC Press
Grosenbaugh LR(1952)Plotless timber estimates,new,fast,easy.J Forest 50:32-37
Iles K(2012)Some current subsampling techniques in forestry.Math Comput For Nat Resour Sci 4(2):77-80
Kerr G(2014)The management of sliver fir forests:de Liocourt 1898 revisited.Forestry 87:29-38
Kershaw JA,Ducey MJ,Beers T,Husch B(2016)Forest mensuration.5th edn.Wiley-Blackwell,Chichester;Hoboken
Leak WB,Lamson NI(1999)Revised white pine stocking guide for managed stands.Tech.Rep.NA-TP-01-99,USDA Forest Service,Northeastern Area State and Private Forestry
Leak WB,Yamasaki M,Holleran R(2014)Silvicultural guide for northern hardwoods in the northeast.General Technical Report NRS-132,USDA Forest Service,Northern Research Station
Lynch TB(2017)Optimal plot size or point sample factor for a fixed total cost using the Fairfield Smith relation of plot size to variance.Forestry 90:211-218
Lynch TB,Gove JH,Gregoire TG,Ducey MJ(2021,in press)An approximate point-based alternative for the estimation of variance under big BAF sampling.In review,Forest Ecosystems
Marshall DD,Iles K,Bell JF(2004)Using a large-angle gauge to select trees for measurement in variable plot sampling.Can J Forest Res 34:840-845
Masuyama M(1953)A rapid method for estimating basal area in a timber survey-an application of integral geometry to areal sampling problems.Sankhy¯a 12(3):291-302
Oderwald RG,Jones E(1992)Sample sizes for point,double sampling.Can J Forest Res 22:980-983
Palley MN,Horwitz LG(1961)Properties of some random and systematic point sampling estimators.Forest Sci 7(1):52-65
Portnoy S(2013)Comment on“Who invented the delta method”.Am Stat 67(3):190
R Core Team(2020)R:A language and environment for statistical computing.R Foundation for Statistical Computing,Vienna,Austria.https://www.Rproject.org.Accessed 08 Apr 2020
Rice B,Weiskittel AR,Wagner RG(2014)Efficiency of alternative forest inventory methods in partially harvested stands.Eur J Forest Res 133:261-272
Smith HF(1938)An empirical law describing heterogeneity in the yields of agricultural crops.J Agr Sci 28:1-23
Van Deusen P(1990)Critical height versus importance sampling for log volume:does critical height prevail?Forest Sci 36(4):930-938
Venables WN,Ripley BD(2002)Modern applied statistics with S.4th edn.Springer,New York.http://www.stats.ox.ac.uk/pub/MASS4,iSBN 0-387-95457-0.Accessed 08 Apr 2020
Ver Hoef JM(2012)Who invented the delta method?Am Stat 66(2):124-127
Wensel LC,John HH(1969)A statistical procedure for combining different types of sampling units in a forest inventory.Forest Sci 15(2):307-317
Williams MS(2001a)New approach to areal sampling in ecological surveys.Forest Ecol Manag 154:11-22
Williams MS(2001b)Nonuniform random sampling:an alternative method of variance reduction for forest surveys.Can J Forest Res 31:2080-2088
Yang TR,Hsu YH,Kershaw Jr,McGarrigle E,Kilham D(2017)Big BAF sampling in mixed species forest structures of northeastern North America:Influence of count and measure BAF under cost constraints.Forestry 90:649-660
Yates F(1949)Sampling methods for censuses and surveys.1st edn.Charles Griffin and Co.Ltd.,London
Yates F(1953)Sampling methods for censuses and surveys.2nd edn.Charles Griffin and Co.Ltd.,London
Yates F(1981)Sampling methods for censuses and surveys.4th edn.Charles Griffin and Co.Ltd.,London

- Forest Ecosystems的其它文章
- Evaluating the impact of sampling schemes on leaf area index measurements from digital hemispherical photography in Larix principis-rupprechtii forest plots
- Discovering forest height changes based on spaceborne lidar data of ICESat-1 in 2005 and ICESat-2 in 2019:a case study in the Beijing-Tianjin-Hebei region of China
- Comparison of the local pivotal method and systematic sampling for national forest inventories
- Effects of firewood harvesting intensity on biodiversity and ecosystem services in shrublands of northern Patagonia
- The Siberian moth(Dendrolimus sibiricus),a pest risk assessment for Norway
- Hydrological functioning of forested catchments,Central Himalayan Region,India