
基于强化集成学习的配变日负荷曲线预测模型
2021-01-08 02:41:34王艳龙陈雪圆
安徽电气工程职业技术学院学报 2020年4期
陈 朔, 王 尉, 章 柯, 王艳龙, 张 照, 陈雪圆
(1.国网合肥供电公司, 安徽 合肥 230022;2.国网肥西县供电公司, 安徽 合肥 231200)
0 引言
负荷预测是保障电力系统安全、稳定与经济运行的一项重要的基础性工作,其以电网运行历史数据为基础,通过挖掘负荷序列变化规律,关联分析负荷影响因素,实现对电网负荷提前感知[1]。
因为负荷变化受到天气温度、节假日、区域分布等多因素影响,会表现出不同的变化规律,所以本文综合天气、节假日、区域差异等多影响因素,基于相似日[2]数据簇构建了配变负荷曲线预测模型[3]。相比单一极值短期负荷预测,该模型能够预测未来2日内每间隔15分钟一个数据颗粒度的负荷曲线,准确刻画各配变全时段负荷变化,全景展示各配变不同区间负载率时长占比,为电网调度管理、运行检查工作提供依据[4]。
1 多因素相似日判断
配变负荷变化影响因素有很多,其中由于用户用电需求受气象条件、节假日信息等因素影响,从而不同气象条件、周末与非周末之间的负荷变化呈现不同规律,因此基于气象因素、节假日信息实现的相似日判断,针对不同相似日单独开展负荷变化分析,有助于更好挖掘负荷变化规律[5,6],提高模型预测准确度。本文选取待预测日前30日的多因素数据,使用kmeans与轮廓系数组合的方法生成多个相似日簇。

表1 多因素数据示例
依据多因素数据,相似日判断方法如下:
步骤1:初始化相似日簇数范围,并按照选择得聚类数K1,随机选取一个样本作为第一个聚类中心C1。计算每个样本与当前已有类聚中心最短距离(即与最近一个聚类中心的距离),其中距离D(X)计算原理如下,这个值越大,表示被选取作为聚类中心的概率较大。并计算每个样本被选为下一个聚类中心的概率P(Xi),用轮盘法选出下一个聚类中心,最终获得K个聚类中心点。
(1)
(2)
步骤2:对数据集中每一个点,计算其与每一个质心的距离D(X),离哪个质心近,就划分到那个质心所属的集合。把所有数据归好集合后,一共有k个集合。然后重新计算每个集合的质心。如果新计算出来的质心和原来的质心之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),可以认为聚类已经达到期望的结果,算法终止。如果新质心和原质心距离变化很大,则重复步骤二,待质心变化收敛后停止。
步骤3:使用轮廓系数评估聚类簇数为Ki条件下的聚类效果,其中dismeanin为该点与本类其他点的平均距离,dismeanout为该点与非本类点的平均距离。该值取值范围为[-1,1],越接近1则说明分类越优秀。轮廓系数计算原理如下:
(3)
(4)
循环步骤一、步骤二、步骤三,选择轮廓系数最大的聚类结果,获得各相似日簇。基于相似日簇开展不同类型日负荷曲线分析,可更加有效的挖掘负荷曲线变化规律,为模型构建过程中的流程优化、特征选择和权重优化提供支撑。
2 负荷日曲线预测模型构建
负荷日曲线变化受多种因素影响,除不同气象、日期条件下日负荷曲线呈不同变化规律外,日负荷曲线还存在很强的周期性和连续性,日负荷曲线各点变化受其临近的各个时间节点负荷值影响。故本文选择2020年待预测日前10天同一时刻点值、相似日曲线同一时刻点前6点(1.5 h)数据,以及节假日信息、天气信息作为模型输入,日负荷曲线预测模型特征输入字段如表2所示。

表2 模型输入特征
针对配变日负荷曲线存在的周期性和连续序列变化规律,本文选择强化集成学习梯度提升决策树回归(Gradient Boosting Regressor)方法构建日负荷曲线预测模型,其相比传统机器学习方法,独有的强化集成学习机制可有效抑制日负荷曲线部分点值异常所带来特征干扰,提高模型准确度。Gradient Boosting Regressor方法每轮训练会迭代生成一个弱学习器,这个弱学习器拟合损失函数关于之前累积模型的梯度,然后将这个弱学习器加入累积模型中,逐渐降低累积模型的损失。即参数空间的梯度下降利用梯度信息调整参数降低损失,函数空间的梯度下降利用梯度拟合一个新的函数持续降低损失,当模型训练收敛后会获得一个由多个弱分类器组成的集成强分类器。
F0(x)=argminLoss(yi,h(xi))
(5)
(6)
(7)
Fm(x)=Fm-1(x)+vh(x)
(8)
上式中Fm(x)为累积模型,h(x)为迭代生成弱学习器,yi为函数目标值,Loss函数为评估弱学习器在给定输入yi条件下输出结果与真实值的差距,gm为第m轮弱学习器训练损失函数的负梯度,v为最佳模型迭代学习率。构建完成的配变日负荷曲线模型对预测日曲线各点依次进行预测,输出未来2日负荷曲线,模型预测流程如图1所示。

图1 模型预测流程
3 模型应用
负荷过低易导致配变设备轻载运行,降低电网运营效率。负荷过高易导致配变设备重过载运行,增加设备故障风险。因此使电网运行在合理的负荷区间,是维持电网安全经济运行的有效保障。通过开展负荷曲线预测,提前感知配变运行状态,是使配变运行在合理负荷区间的重要途径之一。模型在2020年7~8月期间,针对合肥地区25 000个配变进行了应用验证,如图2所示,其为随机选取的15天200个配变间,对应点平均实际日负荷曲线与模型预测各对应点平均日负荷曲线拟合效果。依据配变日负荷曲线值预测结果可计算配变每日不同负载率区间时长占比,全息预感知配变日运行负荷状态。
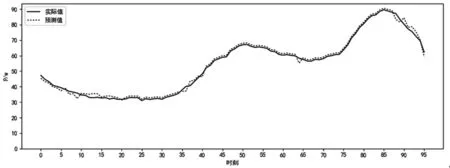
图2 预测效果拟合效果
在验证过程中模型选择数据总量(150万条)的70%作为训练样本,30%作为测试样本,过程中数据样本量和模型效果如表3所示,模型曲线预测准确度计算原理如式(9)所示。式中tvi为单点预测准确度,avgt为日曲线预测准确度。对所有日曲线预测准确度求平均可得日曲线预测平均准确度,经计算本文模型平均准确度为91.33%,如表3所示。

(9)

表3 模型验证参数
4 结论
本文首先基于气象、节假日等信息利用特征工程和相似聚类实现相似日判断,在此基础上使用强化集成学习方法建立了一个配变日负荷曲线预测模型,相比传统回归类算法,使用强化集成学习方法训练构建模型,能够基于强化集成学习方法独有的强化集成投票融合学习机制,使模型对于数据波动具有更好的拟合预测效果。同时通过开展配变负荷曲线预测可数据量化配变负荷不同区间占比,实现配变日负荷全景感知,更好地助力电网精益化管理。经验证该模型可以有效预测未来2日配变负荷曲线,有效支撑电网调度运行方式安排和设备运维检修工作。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30 06:24:26
数学物理学报(2021年6期)2021-12-21 06:24:38
北京航空航天大学学报(2021年4期)2021-11-24 01:13:12
应用数学(2020年2期)2020-06-24 06:02:50
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
建筑科技(2018年6期)2018-08-30 03:40:54
中国交通信息化(2016年5期)2016-06-06 03:51:43
航天器工程(2014年5期)2014-03-11 16:35:53
天津冶金(2014年4期)2014-02-28 16:52:58
机电信息(2014年35期)2014-02-27 15:54:30
