
深度学习在图像识别中的研究与应用
2021-01-08 07:58李铧
无线互联科技 2020年23期
李 铧
(无锡科技职业学院,江苏 无锡 214028)
0 引言
计算机技术的深度学习,就是通过计算机对大部分人类大脑神经动态过程进行模拟,并对数据得出相应结论的学习方式。该种方法在计算机方面合理应用,可以有效地加强计算机技术对数据信息的处理能力,并为计算机技术构建更为高效的数据检索能力。
1 深度学习的定义
所谓的深度学习,即是从一个输入中产生一个输出所涉及的计算可以通过一个流向图(flow graph)来表示,考虑这样一个计算集合,它可以被允许在每一个节点和可能的图结构中,并定义了一个函数族。
这种流向图的一个特别属性是深度(depth):从一个输入到一个输出的最长路径的长度[1]。所谓的深度学习,是为机器学习构建一个模拟人脑运作方式的思维网络,同时,不同的深度学习方法也存在着不同的学习模型。广为人知的深度学习所应用到的领域就是飞机上的黑匣子,黑匣子中记载的数据以及信息往往是抽象的,无法直接从黑匣子上记录的数据得知飞机的飞行情况,但是经过计算机深度联结计算,就可以将黑匣子中的数据以音频或者图像的方式展现出来。
2 图形识别的定义
图像识别,是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对象的技术,是应用深度学习算法的一种实践应用[2]。 现阶段图像识别技术一般分为人脸识别与商品识别,人脸识别主要运用在安全检查、身份核验与移动支付中;商品识别主要运用在商品流通过程中,特别是无人货架、智能零售柜等无人零售领域。
图像的传统识别流程分为4个步骤:图像采集→图像预处理→特征提取→图像识别。图像识别软件国外代表的有康耐视等,国内代表的有图智能、海深科技等。另外在地理学中指将遥感图像进行分类的技术。
传统的前馈神经网络能够被看作拥有等于层数的深度(比如对于输出层为隐层数加1)。SVMs有深度2(一个对应于核输出或者特征空间,另一个对应于所产生输出的线性混合)。目前的图像识别技术主要使用卷积算法,在接收到图像信息后,通过对图像中的各个关键信息进行记录,并通过对图像的具体特征进行比对,以实现图像识别活动。
图像识别的方法包括贝叶斯分类法、模板匹配法等,所谓的贝叶斯分类法,就是通过图像中特定的信息与模板信息进行比对,并且观察其中的相同点与不同点,如果两者的信息能够完全重合,则算法正确,如果其中存在不吻合的数据,则算法错误,再从其他的模板信息中进行比对,值得一提的是,由于当下电子信息技术的发展,比对效率往往较快,甚至在短短数十秒就可以完成上千万数据的比对。模板匹配法,就是在贝叶斯分类法的基础上研发出的图像识别技术,该方法可以有效提高贝叶斯分类法对图像识别的效率,在收到图像信息时,迅速对图像信息中的显性信息以及隐性信息进行确定,并且迅速找到模板中该类显性信息以及隐性信息的位置,进行比对。
3 图像识别技术的优缺点
目前,我国图像识别技术已经逐渐融入人们的日常生活中,当下的图像识别技术,可以为警务人员提供良好的侦察方式,为医护人员提供一定的医疗保障。尤其是当下的疫情期间,可以通过人脸识别技术将自身的信息以及近期出行状态记录在吉祥码中,对吉祥码进行扫描,即可获得自己的行程记录,为我国的疫情防控做出了重大贡献。不仅如此,图像识别技术也逐渐与其他技术相结合使用,尤其是当下的疫情期间,图像识别技术可以与测温技术相结合,在部分关卡中设立相应的测温设备,并且将人的体温直接录入反映到大数据之中。
4 深度学习在图形识别中的应用
4.1 卷积神经网络
所谓的卷积神经网络(CNN),就是由一个或者多个二维卷积层以及顶端的全连接层组成的,并在其中囊括了激活函数和池化层,以此为图像识别系统提供对二维图像的处理能力。
所谓的卷积层,就像是利用二维卷积滤镜,对输入的图像信息进行提取,并总结图像特征,公式如下:
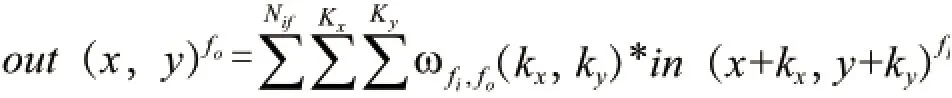
其中,in(x,y)f代表着输入方特征的所在位置(x,y)的输入数据,而out(x,y)fo代表着输出方特征图的所在位置(x,y)的输出数据;其中,卷积核(kernel)大小为kx*ky,在其中,穿插着统一特征图的所有神经元。
池化层,求解卷积核内的最大值以及平均值,同时,对输入层进行下采样,缩小特征图,降低网络计算的难度;除此以外,还要将二维图像中的特征进行压缩,并挑选图像中的主要特征。这么做的目的是模糊图像,减少二维图像中包含的各项参数,降低解析难度。
激活函数,是在图像识别系统运作的过程中,引入非线性因素,以此加强神经网络在识别过程中的表达能力[3]。目前,较为常用的激活函数分别为sigmoid函数以及tanh函数,具备较高的饱和性以及非线性特征。同时,由于神经网络中具备较高的非饱和性以及非线性特征,在运转的过程中,加快了神经网络的收敛作用,目前,ReLU激活函数被广泛地应用于深度学习的模型当中,公式如下:
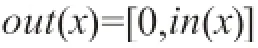
结构化处理可以让CNN能够直接对二维图像做出反应,在识别的过程中,保留二维图像本身的各项数据以及特征,不仅如此,还可以有效避免图像识别算法中过于复杂的特征提取和数据重建的过程。这样的网络结构对二维图像的平移、比例缩放乃至倾斜,都拥有较高的处理能力,具备着高度的稳定性。
4.2 AlexNet模型
第一个典型的CNN网络结构是LeNet5网络结构,值得一提的是,第一个让人熟知的网络却是AlexNet网络结构,AlexNet网络结构在整体上更类似于LeNet,都是事先进行卷积,而后达成全面连接,但是在细节方面两者仍然有较大的差距。值得一提的是,AlexNet在ILSVRC—2012的竞赛中获得了top—5测试的第一名15.3%error rate,而位于第二名的网络结构仅达成了26.2%error rate。差距尤为巨大,而AlexNet网络结构也为学数据带来了巨大冲击。
ImageNet数据集中包含着高达1 500万张带有明确分类标签的二维图像,这1 500万张二维图像在数据集中大约分为22 000类[4]。ILSVRC在此基础上,使用其中的1 000个类别(每个分类中大概存在1 000张二维图像,也就是总共包含大约100万张二维图像),AlexNet网络结构则使用120万张图片作为训练集,5万张验证集图片以及12万张测试集图片。AlexNet网络结构是一个八层的深度神经网络,每个卷积神经网络在完成卷积操作后,便由relu函数进行激活,在第一层以及第二层卷积层激活时,还要包含局部响应归一化层(LRN),然后再在第一、二、五层卷积层后面增加最大池化层。
4.3 DeConvNet模型
DeConvNet网络使用VGG作为其backbone框架,第一部分为卷积网络,类似于FCN,具有卷积层和池化层。而第二部分则是反卷积网络。卷积是为了让二维图像同比转换为更小的尺寸,而反卷积则是将小尺寸的图像同比转换回初始尺寸。通过对象检测方法EdgeBox检测2 000个区域建议region proposals中的前50个(边界框)。然后,DeconvNet应用于每个区域,并将所有建议区域的输出汇总回原始图像。使用proposals可以有效地处理各种规模的图片分割问题。
4.4 ResNet模型
在一般的印象当中,深度学习越是复杂,参数越多,其表达能力就越强[5]。凭借这些基本准则,CNN分类网络字AlexNet的7层逐渐发展到了VGG的16甚至19层,而后,甚至出现了高达22层的GoogleNet。有趣的是,在后续的研究发现,CNN网络深度对表达能力的影响具备峰值,一味地叠加层数不但无法提高性能,甚至会降低网络收敛的速率。
而ResNet网络则是利用常规计算机视觉领域常用的residual representation的概念,进一步将其应用到了CNN模型的构建之中。于是就产生了最基本的residual learning的block。通过使用多个参层来学习输入输出之间的残差表示,而非像一般CNN网络(如AlexNet/VGG等)那样使用有参层来直接尝试学习输入输出之间的映射。经过不断的实验表明,使用一般意义上的有参层来进行直接学生残差比直接学习输入、输出间影射要容易得多,且效率更高。当下ResNet已经成功替代VGG作为一般计算机视觉领域问题中的基础特征提取网络。
5 结语
目前,我国的图像识别技术得到了广泛的应用并切实的融入了日常生活之中。但图像识别技术发展较为完善的内容仍然停留在人脸识别技术,无法在更多的领域得到良好的应用。深度学习就是将大数据融入图像识别技术,利用图像识别技术将图像中的信息进行检索总结,并且在大数据中筛选相对应的内容,反馈给图像提供方,以保障图片识别技术的准确性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年16期)2019-09-27
中国交通信息化(2019年4期)2019-07-13
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
电子制作(2018年14期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
