
基于分词算法的用户个性化推荐系统设计
2021-01-07 08:36隋在娟
数字通信世界 2020年12期
隋在娟
(三星电子(中国)研发中心,江苏 南京 210012)
近年来,随着电子商务与互联网的发展以及人工智能的发展,用户个性化推荐成为学术研究的热点,它建立在大量的数据挖掘基础之上,会通过用户的个性化需求给他推荐符合其需求和感兴趣的内容。很多产品如:购物网站,音乐网站,读书网站已经实现根据用户每日浏览的内容推送相关的内容供用户浏览,实现千人千面。本文是在分词算法的基础上实现的用户个性化推荐系统,该系统合理稳定,适用于用户浏览文章时的个性化推荐。
1 中文分词
1.1 分词算法
中文文本之间没有界限,所以中文的语义理解的第一步是进行专门的分词处理。由于基于字符串的分词法简单高效,应用较广,所以我们本文使用字符串匹配分词法。该种方法是机械地将文本与一个初始的足够大的字典进行匹配,因此叫机械分词法,它也被称为字典分词法。
MMSeg分词法是一种常用的、效率较高同时错误率较低的中文分词算法,它在传统算法之上加入词长等考虑以解决某些分词歧义问题,算法从句子最开始位置,每次匹配出三个词为一个小组,并且设计了四个新的去歧义的筛选规则:
(1)词块长度最大,即三个词的词长之和最大。
(2)词块平均词长最大,即词长分布尽可能均匀。
(3)词块的词长变化率要最小。
(4)单字的出现词自由度最高。
以上规则符合人们说话的基本习惯,所以四项规则是合理的。下面就“研究生命特征”这个短语展示使用MMSeg进行分词的过程。
首先使用字典匹配会得到7个词块:研_究_生,研_究_生命,研究_生_命,研究_生命_特,研究_生命_特征,研究生_命_特,研究生_命_特征。使用第一个准则,词块长度最大,可以得到最长的两个词块:(a)研究_生命_特征和(b)研究生_命_特征,两者的词块长度都是6,再使用第二个准则:平均词长最大,可以得到经过第一个准则之后的两个候选词块(a)和(b)平均词长都是2(长度6/词块数3),再经过第三个准则:词长变化率最小可以得到(a)词块研究_生命_特征的变化率为(b)词块研究生_命_特征的变化率为词块变化率小于(b)词块,在第三个准则结束,(a)词块胜出,所以第一轮匹配结束,(a)的第一个词“研究”最终成词完成,以相同的方法继续处理“生命特征”。这里每一轮结束只有胜出词块的第一个词完成分词,剩下的词加入句子中后续词语,重复筛选规则,直至最终全部词语分词结束。
1.2 数据清洗
当我们利用MMSeg中文分词时,句子中出现的所有词语都会被划分,事实上有些词语是没有实际意思的,比如“的”“了”这种词,对于后续任务会加大工作量。所以在分词处理以后,我们便会清洗数据,引入一个这样的无意义的词表去优化分词的结果。
该词表叫作停用词表,里面放置所有分词中希望过滤掉的停用词,所谓停用词,就是在文本处理中遇到,就将其扔掉,停止处理他们,这样可以提高分词的效率,且减少后续特征提取的工作量。对于停用词表,我们需要手动创建一个文本文件,内容可以直接导入已有的别人整理好的文本内容,也可以自己手动添加一些我们不需要的词语,以对停用词表进行不断完善,制作出符合自己需求的停用词表。
2 特征提取与TF-IDF
如果想针对用户浏览内容做推荐,需要知道用户浏览的文本的主要特征是什么,然后推荐相似特征的文本内容。推荐的关键点就是相似性的度量,并且这个度量是文本表示的一个基本问题,就是文本特征的提取。即将无任何结构的原始的文本,转化为规律的、计算机能够识别的结构化信息,在此基础上,计算机才能进行文本挖掘等处理。
TF-IDF是一种通过单词权重方法实现的文本特征提取方法,算法公式为其中TF和IDF表示为:
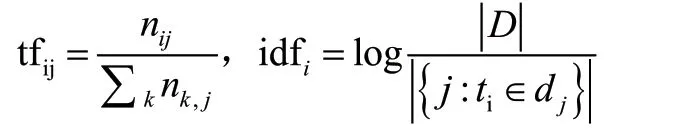
TFIDF算法简单快速,其结果也符合实际情况,是文本挖掘,关键词提取,主题分布等领域的重要方法和手段。
3 推荐系统模型
本系统设计首先需要构建庞大的训练样本,即需要搜集有大量的文本进行学习,该训练集需要足够大,能够包含要闻,娱乐,音乐,军事,体育,财经,历史,健康等内容。假设我们获得的训练样本数是500,即搜集到不同类型500篇文章。
首先,将所有的训练样本去停用词,再对所有500个训练样本使用MMSeg分词算法得到所有样本的分词结果。然后,使用TF-IDF算法计算出每个文本的关键词,比如每篇文章按照TF-IDF值从高到低各抽取20个,合并成一个关键词集合A(集合内关键词因为有重复,所以数量小于500*20个,比如为3000),然后计算出每个样本内容对于这个集合A中词的词频,若文章长度相差较大,则使用相对词频。如文本1为:我喜欢看电影,文本2为:我喜欢看体育。经过合并之后的词语合集A为:我,喜欢,看,电影,体育。因此计算出文本1的词频向量为[1,1,1,1,0],文本2的词频向量为[1,1,1,0,1],此词频向量可以对用户兴趣可以很好地建模,以数字形式展示文本的不同特征。
样本集训练完之后,每个样本文章都获得一个大小为3000维的词频向量,代表着每个样本可以被量化为该向量,这是该样本的重要特征和表示,500篇不同内容的训练样本一共得到500个3000维的向量。这时,当用户浏览一篇文章时,同样对这篇文章数据清洗去停用词,MMSeg分词,之后该篇文章对训练出来的关键词合集A进行词频计算,同样得到一个3000维的向量,之后利用下式计算该向量与样本集中每一个向量的余弦相似度。

该式表示两个向量的相似程度,余弦相似度越大,表示文章越相似,最后取500个训练样本中余弦相似度最大的一个或几个样本作为最相似的内容向用户进行推荐。
当个性化推荐完成后,可以将用户浏览的本文章加入训练样本,这样可以丰富训练样本与关键词集合,优化和更新推荐系统,使之越来越丰富与完善。
4 结束语
本文是基于MMSeg文本分词算法设计的一套个性化推荐系统。本系统关键特征提取算法使用的是较为流行的TF-IDF算法,该算法能够对文本进行数据挖掘,提取出最能代表出本文内容的关键权重矩阵,系统能够考察用户待预测项目与样本库的匹配程度,并在该系统的文本数据库中搜索出和浏览文本类似的、用户感兴趣的相关内容进行推荐。该系统合理且高效,也可适用于用户类别的分析判定。
猜你喜欢
内江科技(2021年8期)2021-09-13
语数外学习·高中版下旬(2020年3期)2020-09-10
科技创新与应用(2020年6期)2020-02-29
亚太教育(2018年5期)2018-12-01
中学生英语·外语教学与研究(2018年2期)2018-03-16
校园英语·上旬(2017年8期)2017-08-04
广东教育·综合(2017年7期)2017-07-27
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
读者·校园版(2015年7期)2015-05-14
