
基于时序相似性搜索的设备状态预测
2021-01-07 10:51张蕾
上海电机学院学报 2020年6期
张 蕾
(上海电机学院 机械学院, 上海 201306)
设备状态预测就是根据设备运行参数的历史数据预测设备在未来时刻的运行状况,估计设备的剩余寿命并预防可能发生的故障,是实现设备智能维护的关键[1]。状态预测的实质是由状态参数构成的时间序列的预测,比较经典的方法是建立时序模型,例如自回归移动平均(ARMA)模型或自回归(AR)模型[2-5]。时序模型主要适用于平稳时间序列,而且要求模型的参数必须估计准确。随着信号处理技术的发展,逐渐出现了一些新型且适用于非平稳时间序列的预测方式,例如小波变换、灰色模型和支持向量机等[6-8]。但这些方法主要适合于单个状态参数时间序列的预测。在复杂系统中,多个状态参数之间往往相互影响,而且影响规律不能明显地用公式表达。根据多个状态参数的历史数据对某个参数进行预测时,神经网络成为比较理想的工具[9-12]。
训练模式的选择是神经网络预测过程中不可轻视的重要环节,模式繁多的训练样本会导致神经网络训练过程的无所适从,使神经网络收敛缓慢,甚至不收敛,影响了其实际应用。本文提出一种利用时序相似性搜索选择训练样本的方法,这种相似性搜索是在待预测序列的历史序列中进行的,是一种“纵向”的相似性。搜索的目的是找出与待预测序列具有相同变化趋势的序列,如果序列只受自身因素的影响,趋势相同的序列,其下一刻的取值也必然存在相似性。但其下一刻的值由于受其他因素的影响,往往会不同。考虑其他因素的影响,本文选择所有相似序列中与待预测序列下一刻相对应时刻的模式作为训练样本,这组样本集中反映了待预测序列在具有一定趋势的条件下,其他因素的变化对预测值的影响,是一类规律的反映。这种样本选择方式充分发挥了神经网络的非线性学习能力,同时剔除了不相干的样本,达到提高神经网络的收敛速度和预测精度的目的。本文通过某发电机主蒸汽流量的预测验证了该方法的可行性。
1 基于时序相似性搜索的预测模型
1.1 时序相似性搜索
时间序列相似性搜索就是在时间序列数据库中发现与给定序列模式相似的序列或查找库中相似的序列对,相似性搜索是目前时间序列数据挖掘中一个重要的分支[13-15]。首先给出如下定义:
定义1给定阈值ε≥0和时间序列距离公式D,如果对于序列X和Y,有D(X,Y)≤ε,则称序列X和Y在阈值ε内相似,简称序列X和Y相似。
距离公式D可有多种方式,最常用的是欧氏距离定义。
定义2等长序列X和Y的欧氏距离为
式中:n为序列长度。
对于一段长度为n的序列X,要在其历史序列Z(X⊂Z)中搜索所有与其相似的序列,可以采用滑动窗口的方法,搜索算法为
算法search_similar_timeseries(X,Z,ε)。
输入序列X,待搜索序列Z,相似阈值ε。
输出与X相似的序列及每个序列起始时刻的索引值。
步骤从序列Z初始时刻开始依次搜索,每次下移一个时间单位,直到整个序列搜索完毕。
以某发电机主蒸汽流量时间序列为例,假设序列记为gasflow,要预测某时刻t下一时刻的值gasflow(t+1),则t时刻与前面的n-1个时刻的值构成待预测时间序列,主蒸汽流量历史序列构成待搜索序列。由于在一定长度上具有相似的时间序列,其发展趋势必然存在相似性,因此,可以利用所有相似序列后继时刻的值来预测当前序列将来时刻的取值。假设所搜索到的p组相似序列的起始时刻为ti(i=1,2,…,p),则与当前时刻相对应的时刻便为ti+n-1。可见,搜索过程是以一段序列进行的搜索,更能体现发展趋势的相似性。如果不考虑其他因素的影响,各个gasflow(ti+n-1)(i=1,2,…,p),及待预测值gasflow(t+1)应该比较相似。但是由于受其他因素的影响,实际上这些值各不相同,甚至有较大差异。本文通过构造一个神经网络模型来学习其他因素对主蒸汽流量的影响规律。
1.2 神经网络模型的构造
主蒸汽流量与进水流量及发电机功率有很大的关系,因此,应同时考虑这两个状态参数对主蒸汽流量的影响,这两个序列分别记为waterflow和power,神经网络预测模型采用3层BP网络,结构为:5×5×1,其中输入为:主蒸汽流量当前时刻值gasflow(t)、进水流量当前时刻值waterflow(t)、发电机功率当前时刻值power(t)、进水流量下一时刻值waterflow(t+1)、发电机功率下一时刻值power(t+1);输出为主蒸汽流量下一时刻值gasflow(t+1)。神经网络的结构如图1所示。隐层神经元个数根据经验公式确定,激活函数都选用Sigmoid函数。

图1 用于预测的神经网络模型结构
神经网络的训练样本根据1.1节相似性搜索的结果,由所有t=ti+n-1(i=1,2,…,p)时刻上述输入输出构成的样本对组成。由于要预测的主蒸汽流量序列先进行了相似性搜索,因而主蒸汽流量序列本身的因素对预测值的影响大大减小,神经网络主要学习了进水流量和电机功率对预测结果的影响规律。同时,由于相似性搜索保证了训练模式是某一类规律的反映,在本例当中,当主蒸汽流量具有某种发展趋势时,进水流量和电机功率的变化对主蒸汽流量有影响。因而神经网络只要学习这一类规律即可,这与所有样本不加选择地都参与训练,神经网络要适应复杂多变的规律相比,显然神经网络能更快、更好地收敛,从而使得其预测速度和精度都有所提高。神经网络预测算法如下:
算法ann_predict(X,gasflow,waterflow,power)。
输入待预测主蒸汽流量序列X,主蒸汽流量序列,进水流量序列,发电机功率序列(后3个序列长度相同)。
输出主蒸汽流量序列t+1时刻的值X(t+1)。
步骤(1)对序列X,根据相似性搜索算法搜索出所有相似序列;
(2)根据搜索结果,构造训练样本集;
(3)初始化神经网络;
(4)对神经网络进行训练;
(5)利用训练好的神经网络预测X(t+1)时刻的值。
2 发电机主蒸汽流量的预测实例
某发电机运行时,测得主蒸汽流量、进水流量及发电机功率共3个时间序列,采样间隔为10 min,序列的长度为1 800,第1~1 650个点用来训练神经网络或建立时序模型,对1 651~1 800共150个点进行预测检验第1节模型的有效性。待预测序列长度n=20,即预测第1 651个点时,利用1 631~1 650个点构成待预测序列,在历史序列中进行相似性搜索,其他点依次类推。最小相似距离ε=140。神经网络训练时的最大允许误差为0.001。为了便于比较,采用时序模型和神经网络方法对序列进行预测。这两种方法的实现过程如下:
时序模型法对主蒸汽流量序列进行了预处理,即去除周期项,然后零均值化,得到平稳系列后,建立了其AR(5)模型;根据模型的预测值,依次加均值再加周期项,得到最后的预测值。
神经网络方法神经网络的结构如1.2节所示。采用3个序列1~1 649个采样时刻的样本对网络进行训练。最大允许误差为0.001。
3种方法的预测结果如图2所示,预测误差如表1所示。
由图2和表1可见,基于相似性搜索的预测明显优于其他两种方法。对于非平稳序列,时序模型法首先需要通过一定的处理方法,将其转换为平稳序列,在这个转换过程中必然存在误差,而且ARMA(或AR)模型的参数估计也会存在误差,因此,时序模型的预测误差较大,尤其是在曲线有折点的地方,误差很大。神经网络方法由于其处理非线性问题的优越性,可以同时考虑多个因素对待预测参数的影响,预测精度大大提高。但随着历史数据库的不断增大和训练样本模式的繁多,神经网络在训练时,必然面临收敛速度问题。本例中,利用1 649个样本进行训练,神经网络的收敛速度变得非常缓慢,一般要经历300~500个循环才收敛到允许误差,有时甚至不收敛;而提出的基于相似性搜索的预测算法,待预测序列的相似序列的个数大都在20~100之间,而且得到的训练样本是某一类规律的反映,因此神经网络的收敛速度非常快,一般在5~10个循环内即可收敛到允许误差,而且其预测误差非常小,即使在曲线出现转折的地方,也非常吻合。

图2 不同预测模型的预测结果比较
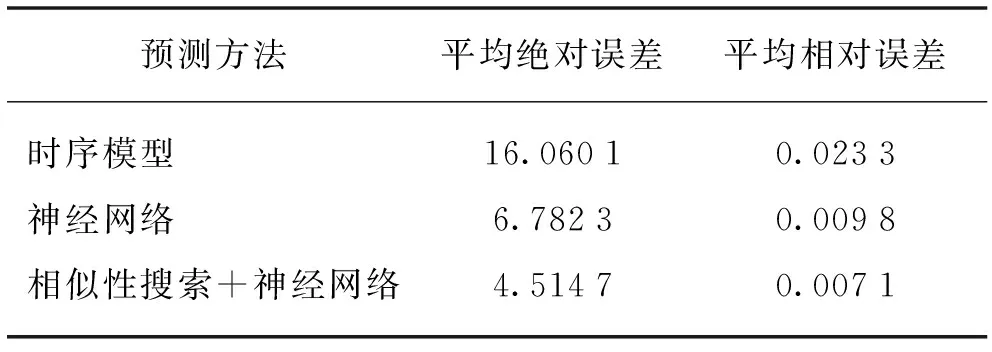
表1 3种预测方法的误差比较
在相似性搜索算法中,有两个参数比较重要,一个是待预测序列的长度,另一个是相似性阈值。序列太短不能反映其在时间上的发展趋势,太长则会增加计算的复杂性。本文认为,可以粗略地估计历史序列ARMA(或AR)模型的阶数q,依次作为指导,进行相似性搜索的序列的长度n=(2~5)q即可,也可以采用试凑的方法,将长度在一段范围内取值,然后取预测误差最小的那个值。相似性阈值可根据序列的长度和实际情况进行选取,要保证所有待预测序列所搜索到的相似序列的平均个数,即神经网络的平均训练样本数不能太少。
3 结 论
本文提出了一种在设备状态参数预测时,采用时序相似性搜索来选择神经网络训练样本的方法。通过相似性搜索,保证了训练样本模式集中反映某一类规律,从而克服在样本不加选择的情况下,神经网络由于要适应多种规律而导致的学习过程不收敛或收敛缓慢问题,提高了神经网络的学习速度和精度,并通过对发电机主蒸汽流量的预测证明了该方法的有效性。通过与时序模型、普通神经网络预测结果的比较,证明了该方法在预测精度和速度上有了很大提高。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
河北画报(2020年8期)2020-10-27
科技创新与应用(2020年6期)2020-02-29
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
