
公共交通乘客个体活动链的日相似性研究
2021-01-04 09:35林鹏飞翁剑成荆云琪尹宝才
交通运输系统工程与信息 2020年6期
林鹏飞,翁剑成,胡 松,荆云琪,尹宝才
(北京工业大学交通工程北京市重点实验室,北京100124)
0 引 言
作为国家层面的城市交通发展战略,通过“公共交通优先发展”缓解中国城市交通拥堵已经成为共识.掌握公共交通出行者的出行时空规律对于公共交通运营管理,提升公共交通服务品质具有重要意义.公共交通刷卡数据记录了出行者带有时空标记的数字脚印,为精细粒度的出行行为研究奠定了良好的数据基础.Ma 等[1]利用北京市一个月的刷卡数据,提取出行天数、常用出发时间、常用路径和站点数4个指标刻画个体出行行为的时空重复性,利用ISODATA 聚类和TOPSIS 算法评价乘客通勤强度.李军等[2]以出行频次与出发时间的标准差作为分类标准,将公交乘客的出行划分为通勤出行、普通类出行和随机类出行.何兆成等[3]基于刷卡数据提取乘客出行链,应用DBSCAN 聚类算法识别居民出行模式,基于出行模式划分结果分析出行周期性;并结合月出行次数,常规出行所占比例,周期性强度,利用Kmeans++算法对居民出行规律性进行聚类.Goulet-Langlois[4]等利用熵率模型从出行频率和时间顺序的角度衡量乘客出行行为的规律性.
现有研究主要基于刷卡数据,提取反映个体出行行为时空相似性的指标,通过聚类算法进一步将乘客划分为不同群体,而出行作为活动的衍生物,从活动角度挖掘乘客出行规律的研究较少;卡类型信息有助于推断用户的活动属性,但多数研究缺乏对卡类型信息的有效利用;现有研究主要将个体多天的出行数据集计分析,忽视对个体日维度出行行为相似性的分析.从日维度的角度分析不同卡类型乘客的长期出行活动规律有助于更精细地划分乘客,并针对不同出行群体制定有针对性的公交服务政策.
本文拟基于乘客刷卡数据,通过提取乘客活动地,推断居住地位置和识别活动类型3个步骤构建乘客个体活动链,并通过PrefixSpan序列挖掘算法提取普通卡、老年卡、学生卡这3 类用户活动链的频繁序列模式,采用Levenshtein距离分别度量3类用户活动链的日维度相似性.
1 数据基础
采用2018年4~5月北京市公共交通刷卡数据,包括每位乘客乘坐地铁或者公交出行时的卡号、卡类型、上下车刷卡时间及站点信息.刷卡数据中包括普通卡、老年卡和学生卡3 种卡类型.由于乘客出行时存在换乘情况,参考文献[5],将同一出行目的且存在换乘关系的多个出行阶段合并构建出行链,结果如表1所示.删除分析周期内出行天数少于20 d 同时出行日期最大间隔大于7 d 的乘客,最终获取约169 万名乘客的出行链数据,其中,普通卡、老年卡和学生卡乘客的占比分别为80.1%,17.1%和2.8%.

表1 出行链数据样例Table 1 Samples of trip chain data
2 个体活动链构建方法
活动链是将乘客每天的所有活动按活动发生的时间顺序相连接.出行链数据构建活动链主要包括活动点提取,居住地位置推断和活动类型识别3 个步骤.如图1所示,某乘客1 d 中存在3 次出行,根据每次出行的起终点,上下车时间,以及乘客用户类型等可推断乘客的出行链为“居家—工作—其他—居家”.
2.1 活动地提取
提取每位乘客所有出行链数据的上、下车站点位置信息,构建活动地站点集合.由于城市中心区域的公交可达性较高,乘客可选择多条路径抵达活动地,故需要将活动地附近的公交站点聚合处理.本文采用DBSCAN 算法将站点集合聚类为若干个簇并作为乘客的活动地,将DBSCAN 算法中邻域距离阈值设为700 m,最小样本点数设为1.统计每个活动地的访问频率,并按访问频率由高到低进行排序.
2.2 居住地位置推断
根据Zou 等[6]研究发现:大多数乘客每天最后一次出行的终点通常与第一次出行的起点相同,并分布在其居住地附近;大多数乘客当天第一次出行的起点与前一天最后一次出行的终点相同.基于上述规则,将每位乘客周期内的所有出行链数据按出发时间排序,如果乘客某天有多次出行,则直接提取第一次和最后一次出行;如果乘客某天只有一次出行,则假设出发时间早于中午12:00的为第一出行,晚于中午12:00 为最后一次出行.提取每位乘客每天第一次出行的起点和最后一次出行的终点,将频率最高的活动地设置为乘客的居住地.

图1 个体活动链Fig.1 Individual activity chain
2.3 活动类型识别
假设当前行程为t,结合相邻下一次出行(t+1)的起点,以及相邻上一次行程(t-1)的终点判断活动状态,按如下步骤遍历乘客所有行程.
Step 1 如果行程t是乘客周期内第一次出行,或者行程t与行程t-1 的间隔大于1 d,则认为乘客在行程t开始前在行程t的起点处于活动状态.
Step 2 如果行程t和行程t-1 在同一天,或者在行程t-1之后的第2天,并且行程t-1的终点与行程t的起点相同,则认为乘客处于活动状态;如果不同,则乘客在该期间采用了非公共交通方式出行.
Step 3 如果行程t与行程t+1 在同一天,或者在行程t+1的前一天,则按Step 2处理.
Step 4 如果出行t与t+1 间隔大于1 d,或者行程t是乘客在周期内最后一次出行,则认为从行程t的结束时刻到当天结束,乘客在行程t的终点处于活动状态.
根据卡类型,活动地访问频率和活动的起止时间,进一步推断乘客的活动类型.将居住地以外访问频率最高的活动地,记作第一活动地.如果活动地位于居住地,则活动类型为居家(home);如果活动空间位置为第一活动地且活动时间在05:00-23:00,对于普通卡、学生卡和老年卡乘客,该活动分别对应工作(work)、上学(study)、生活外出(main);将05:00-23:00 在其他活动地发生的活动,如休闲娱乐等统一归为其他(other).乘客活动类型的推断规则如表2所示.
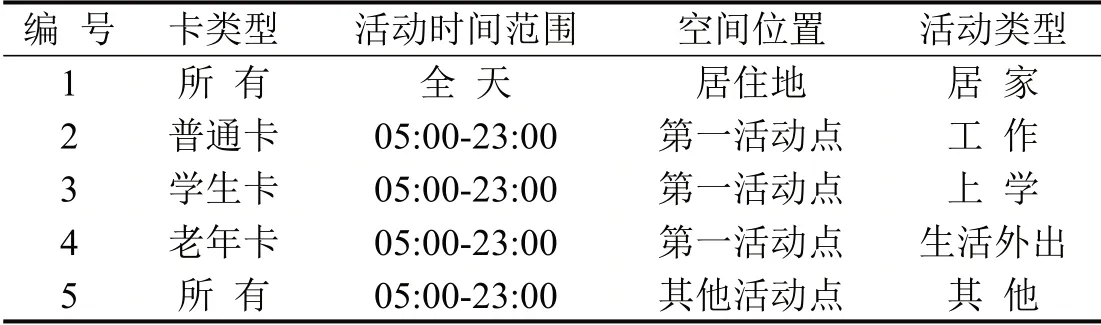
表2 乘客活动类型的推断规则Table 2 Inference rules of passenger activity type
个体活动链的构成包括活动地序号,活动类型及活动时长,采用下划线连接,按发生的时间顺序排列.为便于计算活动链的相似度,将活动时长离散化处理,划分为(0,3]h、(3,8]h和>8 h这3个区间,分别记作短(short)、中(middle)和长(long).活动链的样例如表3所示.

表3 活动链样例Table 3 Sample of activity chain sequence
3 活动链相似性判别
3.1 活动链的频繁序列模式挖掘
频繁序列模式挖掘是从乘客活动链序列中找到频繁出现、有规律的活动序列,本文采用PrefixSpan算法挖掘频繁序列,该算法通过前缀和投影实现挖掘序列模式,已被广泛应用于生物序列、轨迹序列等序列挖掘研究中[7].算法的相关概念定义如下.
定义1活动链序列.假设某乘客的活动链序列S由L个元素按时间顺序排列组成,S=<s1,s2,…,sL>,其中,si表示活动链中的第i个活动,1≤i≤L,例如S=<0_home_long,1_work_long,0_home_long>,每位乘客周期内所有活动链序列构成活动链序列集合SSET,记为SSET=<UID,D,S>,其中,UID为乘客卡号,D为日期.
定义2子序列和超序列.对于活动链序列α=<a1,a2,…,an>和β=<b1,b2,…,bm>,其中,au(1≤u≤n)和bv(1≤v≤m)分别为α和β的一个活动,且存在递增下标序列j1,j2,…,jn(1≤j1<j2<…<jn≤m)使 得a1⊆bj1,a2⊆bj2,…,an⊆bjn,则序列α为序列β的子序列,序列β为序列α的超序列.
定义 3支持度.对于给定序列集合SSET=<UID,D,S>,序列α是序列S的子序列,则序列α的支持度为在SSET中包含α的序列的比例.
定义4频繁序列.给定最小支持度θ,若子序列α在序列集合SSET中支持度大于θ,则序列α即为序列集合SSET的频繁序列.
定义5前缀及投影.对于序列α=<a1,a2,…,an>和β=<b1,b2,…,bm>(m≤n),如果bw=aw(w≤m-1),则β是α的前缀.对于活动链S,α,β,且α,β是S的子序列,同时β是α的前缀,且不存在α的超序列也有前缀β,则称α为β在S上的投影.
定义6后缀.假设序列α=<a1,a2,…,an>和β=<b1,b2,…,bm>(m≤n),β是α的前缀,则序列γ=<am+1,am+2,…,an>为α关于前缀β的后缀.
定义7投影数据库.假设α为序列数据库SSET的一个序列模式,则投影数据库是以α为前缀的所有后缀的集合.
PrefixSpan算法采用分治思想,求解频繁序列模式的步骤如下.
Step 1 查询所有长度为1的前缀和对应的投影数据库.
Step 2 计算对应投影数据库中各项支持度,保留所有满足最小支持度的项.
Step 3 在前缀的投影数据库中,将满足支持度的候选序列与当前前缀相连,根据上述步骤递归生成投影,直到不满足最小支持度或投影数据库为空.
为加快频繁序列的检索效率,将频繁序列的最小长度和最大长度分别设置为2、5,最小支持度设为0.2,同时频繁活动序列第一个或者最后一个元素的活动类型为居家.
3.2 基于Levenshtein距离计算活动链相似性
Levenshtein 距离又称为编辑距离,是指将字符串S变换到目标字符串所需最少编辑次数,编辑操作包括插入、删除、替换操作.Levenshtein 距离的优点是可以用于度量长度不同的2 个符号序列之间的相似性,计算公式为

式中:S,T分别代表乘客的两个活动链序列;Sp,Tq分别表示S、T中的第p、q个元素;为示性函数,当Sp≠Tq时为1,否则为0.
基于Levenshtein距离任意两个活动链序列的相似性为

式中:LS和LT分别为活动序列S和T的长度.SS,T的值越大,两个序列越相似.
4 结果分析
4.1 活动链频繁序列模式分析
基于出行链数据构建活动链,利用Prefixspan算法挖掘每位乘客的频繁活动序列模式,统计3类乘客频繁活动序列的频率分布,结果如表4所示.表4中仅展示活动类型,其中,H、M、S、M、O 分别代表居家、上班、上学、生活外出、其他.每类用户中约70%乘客的频繁活动序列是对称模式,即每天乘坐公共交通往返于居住地与活动地,表明大部分乘客对公共交通的依赖性较高;约30%乘客为非对称模式,即部分出行采用非公共交通,其对公共交通的依赖性较低.

表4 不同类型乘客的频繁活动序列模式Table 4 Frequent activity sequence patterns of different types of passengers
普通卡用户中“居家—工作—居家”活动链比例最高,占比为69.8%.普通卡乘客的频繁活动序列模式更加多样,存在“其他”活动的频繁序列有5 种类型,相应乘客占所有普通卡乘客的17.1%,0.4%的普通卡乘客每天两次往返于居住地和办公地.
学生卡乘客中最典型的频繁序列模式是“居家—学习—居家”,频率为68.0%;非对称活动频繁序列包括“学习—居家”“居家—学习”,占比约21.7%.10.4%的学生卡用户每天存在第二活动,典型的频繁序列包括“居家—学习—其他”“其他—学习—居家”.
老年卡乘客的活动序列模式主要为“居家—生活外出—居家”,占比为61.0%;非对称活动序列模式包括“居家—生活外出”“生活外出—居家”两种频繁活动序列,占比为27.2%.10.8%的老年卡乘客频繁活动序列中存在第二活动.
4.2 活动时长分析
分别统计5种活动类型的活动时长,结果如图2所示.居家、工作、学习是乘客每天的主要活动,所占时间相对较长,3 种活动的平均时长分别为12.5,9.9,9.2 h.老年人生活出行活动的平均时长为3.9 h,相对较短,其他活动类型的平均活动时长为4.4 h,生活出行和其他活动类型的活动时长分布相对分散.

图2 5 种活动的活动时长分布Fig.2 Activity duration distribution of five activities
4.3 活动链的日相似性分析
将每位乘客每天的活动链序列与其自身的频繁序列模式相比较,利用Levenshtein 距离计算活动链序列相似性,将每位乘客周期内每天的相似性计算平均值,用于表征乘客活动链的日相似度,不同类型乘客的相似性分布如图3所示.普通卡和学生卡用户的相似性整体较高,平均值分别为0.645 和0.649,老年卡用户的相似性较低,平均值为0.530,说明通勤(学生)群体活动链结构的相似性高于老年人群体.学生群体相似性分布较普通卡和老年卡群体更集中,说明学生群体整体的相似性较高.
计算不同类型乘客周期内任意两天活动链的相似性,按卡类型对相似性取平均值,即可得到不同类型乘客活动链序列的日维度相似性,结果如表5所示.3类用户均表现出工作日活动链序列与非工作日具有明显差异,而工作日内、非工作日内各天差异较小;星期五与其他天的活动链相似性相对较低,可能原因是临近周末乘客的休闲娱乐等弹性出行需求增加,使活动链结构发生变化.普通卡用户和学生卡用户的活动链序列相似性高于老年卡用户,表明普通卡和学生卡用户的活动更规律,同时对公共交通的依赖性更强.

图3 不同类型乘客的平均相似性Fig.3 Average similarity of different types of passengers

表5 不同类型乘客活动序列日维度相似性Table 5 Day-to-day similarity of activity sequences of different types passenger
5 结 论
本文提出公共交通乘客的活动链构建方法,基于Prefixspan算法挖掘3类乘客活动链的频繁序列模式,利用编辑距离度量个体活动链的日相似性.结果表明:每类用户中约70%乘客的频繁活动序列是往返于居住地和第一活动地的对称模式,对公共交通具有较强依赖性.普通卡和学生卡用户的日相似性高于老年卡用户,3类乘客均表现出工作日间或非工作日间活动链相似性较高,而工作日与非工作日相似性较低的特点.未来将结合公共交通站点周边的用地属性对乘客活动类型进行更精细地辨识.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
自我保健(2020年10期)2021-01-15
河北画报(2020年8期)2020-10-27
时代邮刊(2020年8期)2020-06-22
英语文摘(2019年2期)2019-03-30
智能城市(2018年7期)2018-07-10
大科技·百科新说(2018年2期)2018-03-19
小学生时代·综合版(2017年6期)2017-07-05
自动化学报(2017年1期)2017-03-11
浙江大学学报(工学版)(2016年2期)2016-06-05
