
基于神经机器翻译的文本隐写方法
2021-01-04 06:23尉爽生杨忠良江旻宇黄永峰
应用科学学报 2020年6期
尉爽生,杨忠良,江旻宇,黄永峰
1.清华大学电子工程系,北京100084
2.莱斯大学计算机科学系, 美国得克萨斯州77005
Shannon 在1949 发表的《保密系统的通信理论》中描述了解决安全问题的3 种技术方案:加密系统、隐私系统和隐藏系统[1].虽然加密系统和隐私系统至今依然是网络系统中的主要安全方案,但它们在保护信息安全的同时也暴露了信息的重要性和存在性,因此容易遭受各种针对性攻击.信息隐藏利用载体数据的信息冗余空间[5]进行秘密信息嵌入,掩盖了信息的存在性,从而减少被攻击的风险.
自然语言文本是人们日常生活中使用最广泛的信息载体,基于文本的信息隐藏存在广阔的应用空间.文本信息隐藏的方法主要有基于文本格式[2-4]、基于文本语法、语义[5-6]和基于文本生成[7-11]的方法.基于文本格式的方法主要是通过修改文本文件的一些格式属性实现信息的嵌入,例如使用不可见字符(空格、制表符等)在单词间增删[2],还有对格式化文本(WORD 等)通过行移编码和字移编码[3-4]对文本的行间距或字符间距做微小改变来进行信息嵌入.这类方法主要出现在早期的研究中,鲁棒性较差,重新排版或者清除格式后隐藏的秘密信息也会丢失.基于语法、语义的信息隐藏方法结合语言学、统计学理论以自然语言处理(natural language processing, NLP)技术为基础,通过对文本进行词汇、语法、语义变换来实现秘密信息的嵌入,在这类方法中相对成熟的有同义词替换算法[5-6].
基于自然语言文本生成方法的目标是利用自然语言处理技术生成符合自然语言统计特征的载密文本.文献[7]提出了一种基于马尔可夫链模型和DES(data encryption standard)的文本信息隐藏系统,通过计算语料库训练集中单词出现的频率得到转移概率,利用转移概率对单词进行编码,然后在文本生成过程实现秘密信息的嵌入.文献[8]利用一阶马尔可夫模型构建生成宋词的语言模型,提出了将信息隐藏融入到宋词生成过程的方法.近年来,深度学习在自然语言处理领域得到广泛应用,使自然语言处理能力得到了较大的提升,随之出现了较多的基于神经网络模型的文本隐写方法.文献[9]以神经网络模型为基础设计了基于中文古诗生成的信息隐藏方法,并通过模版约束的生成方法以及依据互信息的大小排序候选词的方法提高含秘诗词语句的质量.文献[10]使用长短期记忆网络(long short-term memory, LSTM)模型在生成的tweets 和emails文本中嵌入秘密信息.文献[11]提出一种基于RNN 的文本信息隐藏方法,根据需要隐藏的秘密信息生成高质量的载密文本,并对单词的条件概率分布进行定长编码和变长编码处理,在隐蔽性和信息嵌入率方面都表现了良好的性能.然而这些方法只在生成较短文本或对话时具有较好的性能,难以生成主题明确且语义完整的长文本.
当今NLP 技术能力快速提升,基于文本生成的信息隐藏方法取得了不错的成果,表现出了巨大的潜力.机器翻译可以根据源语言文本来生成同样意义的目标语言文本,因此本文通过研究机器翻译的技术特点,提出了一种基于神经机器翻译的文本信息隐藏方法.
1 相关研究
1.1 基于翻译的信息隐藏方法
统计机器翻译模型在预测翻译结果的过程中通常会为每个源语句翻译出多个候选语句.通过对该候选语句进行编码,并根据待嵌入秘密信息选取其中一个候选语句作为翻译语句输出,便可以将秘密信息嵌入到翻译语句中.文献[12]首次提出这种思路并设计了Lost in Translation(LiT)算法,LiT 算法使用多台翻译机对载体文本中的句子进行翻译,则每个语句可获得不同的翻译结果.对不同的翻译机进行Huffman 编码,根据需要隐藏的信息位选取对应编码的翻译机所产生的翻译文本,从而实现信息隐藏.文献[13]针对文献[12]存在的安全性问题,提出了不需要传输载体文本的改进算法LiJtT(Lost in Just the Translation).该算法使用通信双方共享的密钥和散列函数计算不同翻译结果的哈希值,指定每个哈希值的某些位(称为隐藏信息位)表示其对应的翻译结果的携带信息,选取哈希值中隐藏信息位与当前需要隐藏的信息相同的翻译结果作为载密文本.信息接收方计算出载密文本的哈希值即可提取隐秘信息,但该方法实现起来较为复杂,信息嵌入率很低.文献[14]提出了改进的方案Lost in n-best List(LinL),与其他使用多个翻译模型的方法相比,该方法只使用一个统计机器翻译模型,因此产生的候选结果差异小,使得该方法具有更好的抗隐写分析能力.但是上述方法都存在信息隐藏容量较低以及算法过于复杂的问题,因而实用性较差.
1.2 神经机器翻译
使用神经网络模型来完成机器翻译任务的神经机器翻译(neural machine translation,NMT)是2013年以后快速发展起来的.Google 在2014年提出了编码器-解码器(Encoder-Decoder)模型框架[15],该模型框架包括2 个循环神经网络(recurrent neural network, RNN),分别作为Encoder 和Decoder,主流的NMT 模型都以这种框架为基础.之后文献[16]提出了在NMT 中引入注意力(Attention)机制,进一步提升了翻译质量.目前,NMT 的很多性能都超过了统计机器翻译模型(statistical machine translation, SMT),已成为主流的机器翻译技术.
典型的编码器-解码器框架如图1所示,假设输入序列为X={x1,x2,···,xt},在时间步t,RNN 根据当前时刻的输入向量xt和上一时间步的隐藏状态ht−1得到当前的隐藏状态ht=f(xt,ht−1),随后编码器将各时间步的隐藏状态变换为表示输入序列语义编码的向量c=q({h1,···,ht}),其中的f和q被称为激活函数,它们对编码器中相应层的输入进行非线性的映射.

图1 编码器-解码器框架Figure 1 Encoder-decoder framework
解码器在解码过程中的时间步根据语义编码的向量c和已经生成的单词y1来预测单词,最终生成整个输出序列Y={y1,y2,···,yt},输出序列的概率可以表示为
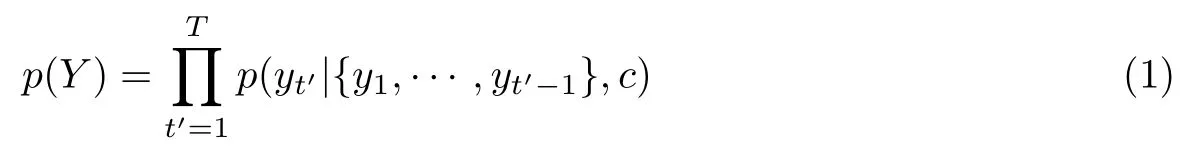
解码器最终目标是得到最大概率的序列,也就是使用搜索算法求解arg maxp(Y).通常不使用穷举搜索法,因为它复杂度太高,效率很低.更常用的是Beam Search.
1.3 集束搜索解码器
Beam Search 的主要策略是在每个时间步都选取条件概率最大的K个候选序列,最终得到K个候选语句并从中选择最佳语句作为输出结果.这里K称为集束宽度(Beam Size).在第1 个时间步选取了条件概率最大的K个单词,分别作为K个候选序列的首位.之后每一时间步都基于上一步的K个候选序列,分别找出条件概率最大的K个,得到K*K个候选序列,然后分别计算其评分,只保留评分最高的K个单词.
序列的评分计算式如下:

对于机器翻译,不同的候选序列长度可能不一样,因此评分需要进行归一化处理
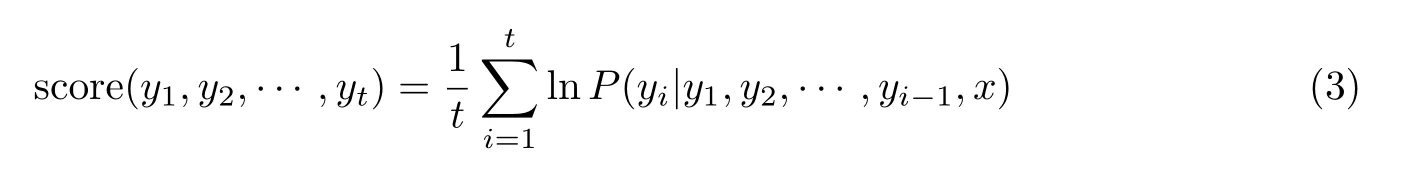
Beam Search 具有更加丰富的搜索空间,可以得到较好的结果.当然K越大,得到全局最优的可能性就越大,但是计算代价也会很大.通常选择合适的大小满足实际需要即可.
2 基于神经机器翻译的文本信息隐藏方法
神经机器翻译模型通过编码器对源语言文本进行编码得到语义向量,然后通过解码器生成目标文本.本文设计的信息隐藏方法利用这种翻译机制在Beam Search 解码器中添加信息隐藏模块,在解码输出目标语言文本的过程中实现信息隐藏.
2.1 信息隐藏模块
信息隐藏模块的结构如图2所示,翻译模型的解码器使用Beam Search 搜索算法可以得到每一步输出的候选单词.首先对当前位置进行可嵌入性检测以减少信息嵌入对文本生成质量的影响,对于可嵌入信息的位置,依据候选词的概率排序进行编码,然后根据需要嵌入的信息选择对应编码的单词作为输出.
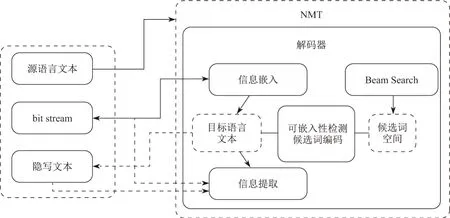
图2 信息隐藏模块Figure 2 Information hiding module
本文设计了一种依据候选词概率的“自适应”的判别方法,可用来评判当前位置是否适合信息嵌入.每个单词生成位置的候选词概率分布都会有差异,首先将当前位置的候选单词按概率大小进行排序,然后计算前两个候选单词概率的比值,当这个比值大于一定的阈值(阈值大小可根据实验效果进行调整)时,就可以判断该位置不适合信息嵌入.如果限定每个位置只嵌入0 或者1,那么只检测前两个单词的概率比值即可.如果希望尽可能嵌入更多的信息,那么可继续依照概率排序检测相邻单词概率的比值是否大于阈值,在不超过Beam Search 搜索宽度的前提下,得到当前位置最多可选的候选词.
候选单词需要先按照一定的规则进行编码,只有这样信息隐藏模块才能根据需要嵌入的二进制比特流来选择对应编码的候选词.在进行信息隐藏与信息提取时,也需要根据同样的编码规则解码出单词对应的编码.在通信系统中,典型的编码方式有定长编码和变长编码.定长编码可用满二叉树的叶子节点来表示,需要当前候选单词至少有2n个,假设当前位置有5 个可用的候选词,那么可以根据概率大小排序取前4 个编码为{00、01、10、11}.变长编码实际是依据候选词的概率排序,使用哈夫曼树(Huffman tree)的叶子节点进行编码.变长编码依据当前可用候选词的概率排序依次编码为{0,10,110,111,···}.
对于相同数量的候选词来说,变长编码可以有更长的编码长度,使得在单个位置嵌入的信息位数更多.然而,长编码意味着所选单词概率较低,生成文本质量较差.文本质量应该优先于信息嵌入率考虑,因此本文使用定长编码方式.
2.2 信息隐写算法
信息嵌入过程如图3所示,神经机器翻译模型使用Beam Search 解码器.在目标文本逐词解码过程中,对Beam Search 搜索的候选单词进行编码,然后根据需要嵌入的bit stream 选择对应编码的单词.

图3 神经机器翻译及隐写模型Figure 3 Neural machine translation and steganography model
在翻译过程中,解码器在某些位置会输出占位符ε,它会在整个目标语句生成后清除,这种占位符所在的位置是不可进行信息隐藏处理的.还有一些位置上候选词空间中相邻排序的候选词概率差异较大,这些位置通常只有概率最大的那个候选单词是唯一合适的选择,如图3中的lauter.这个位置就不能进行信息嵌入,因为只有一个有效的候选单词而未达到本算法的编码要求.这些检查工作由可嵌入性检测单元执行.
隐藏算法具体步骤描述如下:
步骤1输入源语言序列X={x1,x2,···,xt},以及完成二进制编码的秘密信息序列B={b1,b2,···,bn},例如{1,0,···,1}.
步骤2翻译模型开始执行翻译任务.
步骤3产生目标语句的第1 个词语y1时使用贪婪搜索选取目标候选词中最大概率的单词,第1 个单词位不能嵌入信息.
步骤4产生通过Beam Search 算法搜索目标语句序列的下一个单词yt,得到目标单词的候选词空间P(yt−1,yt|xt).每一步都根据目标语句序列的概率评分进行排序,保留Beam Size 个评分最优的结果.本文暂存目标词语的候选单词及对应的概率Ci={c1i,c2i,···,cmi},然后生成下一个目标单词.
步骤5重复步骤4 直至目标语言生成完,并得到Beam Size 个评分最优的候选翻译,选取一个评分最高的翻译序列并提取其搜索路径上各时间步上的候选单词及对应概率的集合,按照候选单词的概率排序得到整个目标语句的候选词集合C={C1,C2,···,Ci}.
步骤6根据步骤5 得到的候选单词及对应概率的集合,依次对序列各位置的候选单词进行可嵌入性检测并完成候选单词编码.在可嵌入信息位,根据秘密信息序列B中的二进制位流选取候选单词中对应编码的单词进行解码输出,不可嵌入位则直接使用最大概率的候选单词解码输出,最终得到目标语句单词序列的输出
二进制秘密信息全部嵌入完成后,剩余文本将继续翻译但不进行信息嵌入.秘密信息的长度以及信息嵌入的开始和结束位置等信息统一编码在二进制比特流中.
2.3 信息提取算法
秘密信息的提取过程如图4所示,信息提取时采用与信息嵌入相同的模型及模型参数.对源语言文本执行翻译,获取最大概率的目标语句序列及其搜索路径上的候选词集合C={C1,C2,···,Ci}.接着对各位置的候选词使用与信息嵌入方法一致的可嵌入性检测并对候选单词进行编码.最后查找隐写文本中各单词所对应候选词中的编码,这些编码即为嵌入的二进制序列.
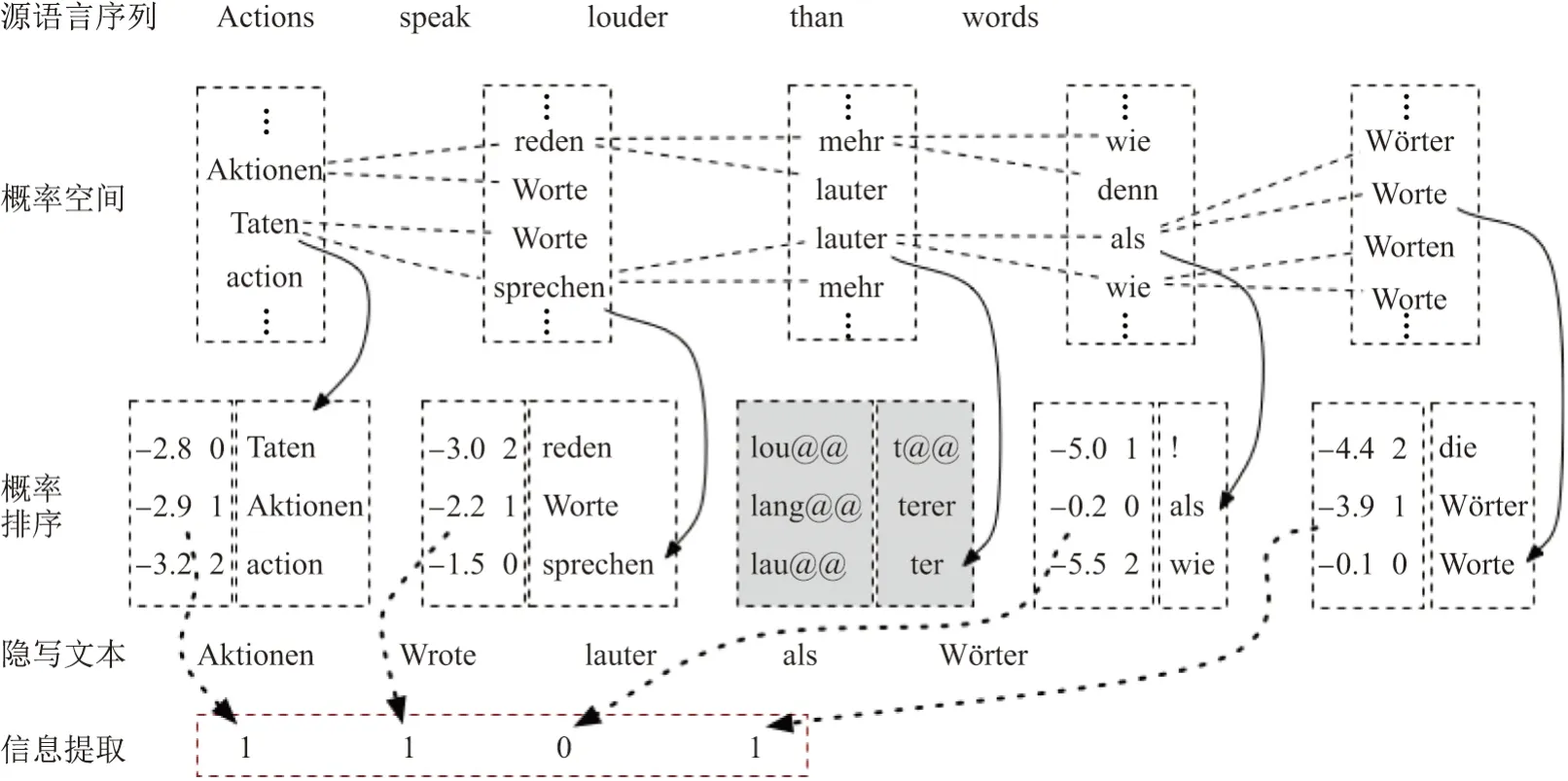
图4 秘密信息提取Figure 4 Secret information extraction
隐藏信息提取算法可用如下步骤来描述:
步骤1输入源语言序列X={x1,x2,···,xt},及待提取信息的隐写文本
步骤2使用翻译模型对源语言序列X进行翻译得到概率评分最大的目标语言序列Y={y1,y2,···,yt},提取其搜索路径上各位置的候选单词及概率集合C={C1,C2,···,Ci}.
步骤3对候选词集合中各位置上的单词进行可嵌入性检测并进行编码.
步骤4对隐写文本中的每个单词位yt重新进行信息提取,查找yt对应的候选词编码,这个编码即为嵌入的隐藏信息bi.
步骤5重复步骤4 直至遇到隐写语句的结束符.
3 实验及结果分析
3.1 模型训练及数据预处理
本文设计的信息隐藏模块可以很方便地集成到神经机器翻译模型中,虽然当前使用Attention 机制的神经翻译模型较为普遍,但是Attention 机制需要较大的内存和计算开销.文献[17]通过与统计机器翻译的对比总结了当前神经机器翻译的一些不足之处,指出了Attention 机制对于长语句翻译的作用有限,同时指出了Attention 机制和统计机器翻译中词对齐的相关性.
文献[18]提出了一种不使用注意力机制的即时翻译模型,以文献[16]的研究为基础来移除Attention 机制,并且使用多层LSTM网络实现编码和解码的功能,其翻译质量与参考模型相近,并且在长语句翻译时效果更好.于是本文以这种模型为基础进行实验,在解码器中添加本文的信息隐藏模块.
实验中使用WMT 2014 数据集进行模型训练,该数据集包含450 万行英语/德语的平行文本.用于训练的平行语料库按照文献[18]的方式进行预处理,首先使用文献[19]提出的fast_align 方法进行对齐处理,然后在目标语句和源语句中插入占位符使它们长度相同.测试数据选用WMT newstest 2014.
3.2 隐写实验
在隐写实验中使用随机序列作为秘密信息,设定“自适应”信息可嵌入性检测的阈值t=0.5.为了评估本方法的最小信息嵌入率,各信息嵌入位只选择概率最大的两个候选单词进行编码,编码长度为1 bit.经过多次重复实验得到了不同隐写序列对应的隐写文本,测试集中的一行测试语句实验结果如表1所示.

表1 隐写实验样本Table 1 Steganography experiment samples
在机器翻译领域评价翻译质量时通常会用文献[20]提出的BLEU(bilingual evaluation understudy)评价指标,BLEU 值越高,表示文本翻译质量越高.对于实验所用的NMT 模型,当不嵌入隐蔽信息时,其生成的翻译文本的BLEU 均值为16;当嵌入隐蔽信息时,其生成的翻译文本的BLEU 均值为9.6.考虑到BLEU 指标的结果表示翻译结果与参考翻译的相似程度,评价方法主要是计算N 元模型(N-gram)的匹配数量.对于参考翻译中的同义词或相似的翻译结果,可能得到较低的评分,而隐写文本会经常出现同义词,因此该指标对于评估隐写文本的质量有一定的局限性.本文抽取部分隐写结果进行了人工分析,在信息嵌入率适中的情况下,语义及语句的流畅性较好,如表1中的实验样本.
3.3 隐藏容量
隐藏容量(embedding rate)是评估隐写算法性能的一个重要指标,它用于衡量在文本中嵌入信息的多少.隐藏容量Re的计算方法是将实际嵌入的比特数除以整个生成文本的比特数,其表达式为
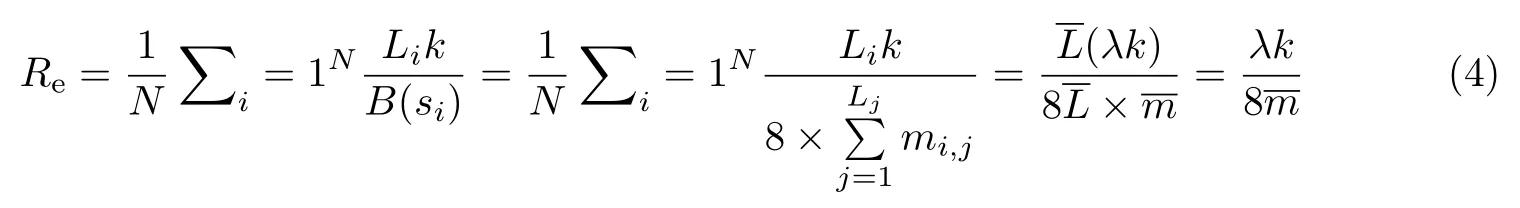
式中,N为语句的总数,Li表示第i行语句的长度,k表示每个单词嵌入的信息编码位数,B(si)表示在第i行语句的总位数,本文的原英文语句中单词的每个字母在计算机系统中占8 bit,因此其中mi,j表示第i行语句中第j个单词所包含的字母总数.和分别为语句的平均长度和每个单词包含的平均字母数,λ为可嵌入信息位置的比例.
评估相对嵌入率(bits per sentence)时只需把前文计算的隐藏容量Re与语句的平均比特位数相乘即可,即
实验产生的隐写文本,统计实验产生的隐写文本中不同长度语句的平均信息嵌入位数,结果如表2所示.其中,整个测试集共2 737 条语句,平均每条语句包含17 个单词,信息嵌入位数均值10.5 bit,隐藏容量均值1.32%.

表2 隐藏容量统计结果Table 2 Hide capacity statistics
实验数据表明本文的隐写算法在不同的语句长度下都有稳定的隐藏容量.实验中每个可嵌入信息的位置嵌入信息编码长度为1 bit,即k=1,语句信息嵌入能力达到了10.5 bit/sentence.文献[9]提出的LiJiT 算法取得的最大信息嵌入率为0.33%,达到2.2 bit/sentence.文献[10]中的LinL 算法信息嵌入率比LiJiT提高了20%,约为2.8 bit/sentence.对比数据如表3所示.

表3 相关算法隐藏容量对比Table 3 Comparison of hidden capacity by related algorithms
3.4 抗隐写检测实验及安全性分析
文本隐写分析的实质是区分隐写文本和正常文本的二分类问题,主要方法包括针对特定信息隐藏算法的方法和盲检测方法.文献[21]提出了针对基于机器翻译模型的信息隐藏的检测方法,并指出该检测方法有以下缺点:一是需要了解隐藏算法的一些私密信息,而这些信息事实上第3 方很难窃取;二是需要对检测文本做大量的机器翻译,检测效率较低.因此针对性的检测方法难以实用,当前隐写分析主要研究通用性的盲检测方法.盲检测方法不需要了解信息隐藏系统的详细信息,只需根据载体特征来判断是否包含隐藏信息.文献[22]提取文本的单词频率和二元组频率特征后使用支持向量机(support vector machine, SVM)进行文本分类,该方法本质是区分不同翻译机的翻译特征,而对只使用一台翻译机的方法无效.
文献[23]提取文本中单词的相关性特征后使用Softmax 分类器设计了一种高效的文本隐写分析方法,该方法表现出比其他检测方法更高的检测效率和准确率.本文使用该检测方法进行隐写检测实验,首先在隐写文本和非隐写文本中分别随机抽取80%作为训练样本,其余的作为测试样本.实验测试对隐写样本检测的正确率只有0.57,精度只有0.68,并且召回率只有0.26.
实验结果中的正确率和召回率说明该隐写检测方法难以区分正常文本和隐写文本,表明本文的隐写方法具有较高的抗隐写检测能力.
在当前的互联网中,网络用户发布多语种文本的现象比较普遍,因此网络空间中多语言文本的数量急剧增大.无论进行自动的隐写分析检测还是仅筛选可疑文本,均大大增加了检测时间和计算量.如果利用人工跨语言分析来进行隐写检测,将会面临难以想象的工作量和难度.更进一步地,如果进行秘密信息传递的双方灵活地约定传输形式,如在极端的时间段、载体文本语种的切换或者发布渠道的切换等,那么检测方就更难以搜集到足够的含秘样本来进行隐写分析.
需要注意的是使用本文所提算法进行秘密信息传输的双方共享模型参数,因此模型及参数的分发和更新都需要通过可信信道完成.综合以上分析,本文的方法具有一定的安全优势.
4 结 语
本文提出了一种基于神经机器翻译模型的文本信息隐藏方法,根据神经机器翻译模型的工作原理和技术特点选择Beam Search 解码器,在解码器中添加信息隐藏模块.依据相邻候选词概率比值关系设计了“自适应”的可嵌入性监测单元,在信息嵌入之前先对各候选词集合进行可嵌入性检测,然后对候选词进行编码,有效降低了信息嵌入对目标语言文本质量的影响.实验结果表明,本文方法在隐藏容量和抗隐写检测性方面均表现良好.在接下来的研究中,我们将使用更为先进的神经机器翻译模型和预训练模型进行实验,并且通过进一步研究文本翻译的特点寻找更适合的信息隐藏位置,优化隐写算法,提高隐写文本质量.
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
新世纪智能(语文备考)(2020年4期)2020-07-25
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
小学生·多元智能大王(2014年6期)2014-07-09
