
萤火虫算法改进支持向量机的高校就业率预测
2020-12-31 06:20:08
广东通信技术 2020年11期
1 引言
近年来,国内高等教育由精英式教育逐渐迈向大众式教育,那么高校毕业生的就业情况就变成了高校教育领域研究的重点,同时也成为了全社会重点关注的领域。随着高校招就处的不断扩大招生,高校毕业生的毕业人数也随之不断增加,从1999年的84.76万增加到2019年的834万,增长了将近10倍左右,从而导致高校毕业生的初次就业率的普遍下滑[1]。同时,高校就业率的高低,不仅是国家和社会评判大学生就业形势最直接的工具,也是评判一所高校教育质量好坏和办学水平高低的尺标[2]。因此,高校学生初次就业率的有效评估成为了教育领域亟需解决的重要问题,而高校就业率的评估模型通过分析历年高校毕业生的初次就业率,去预测将来的高校学生的就业情况[3]。以此为依据,建立高校就业率评估优化算法[4-5],对评估高校教学质量及当前大学生就业工作有着极为重要的意义,引起了众多专家、学者的广泛关注。
目前各高校都累计了多年的就业数据,但缺少对就业情况的深入研究和分析,从而不能进一步地为高校大学生的就业率提供高效的预测和有价值的决策数据[6]。因此,有研究者采用基于时间序列的预测方法[7-8]对高校大学生的就业情况进行分析,便于找到就业率与时间序列算法的关系,从而建立就业预测模型,例如灰色系统模型、神经网络模型等[9]。灰色系统模型[10]是将高校就业情况比作一个灰色系统,通过灰色系统算法对就业率进行模型建模,从而实现预测大学生的就业率情况,然而该算法只适用于一直增长的就业数据进行分析,但是高校学生就业数据量有时会出现下降的趋势,导致获得高精度的就业率有一定的难度[10]。神经网络算法[11]对于非线性数据预测具有较好的拟合能力,尤其适用于对非线性的有波动的高校就业率数据进行分析,可以得到比灰色系统模型分析更好的预测结果。但由于神经网络结构复杂,并且需要高校就业率数据较多,容易出现“过拟合”结果,增加就业率预测的成本。
2 支持向量机
支持向量机(Support vector machine)是在1995年由Vapink和Corinna Corte等人首次提出。SVM算法的提出是要在特征空间中最大化地实现线性分类的效果,其机器学习的根本目的是要通过找到一个超平面实现最大化间隔数据,从而将回归问题转化成二次规划问题,解决陷入局部最优的问题,很适合处理小样本回归的情况。
SVM算法[12]核心是计算支持向量机与输入空间向量间的内积核。SVM算法是将训练集中的N维数据作为输入,同时利用非线性映射函数将其输入映射到高维空间中,并且依据要最小化结构类风险的原则在高维空间中建立起相对应的高维空间线性回归函数。其中回归方程的公式如式(1)所示。

通过拉格朗日乘子得到拉格朗日函数,然后将其参数求偏导,可得原问题的对偶问题:
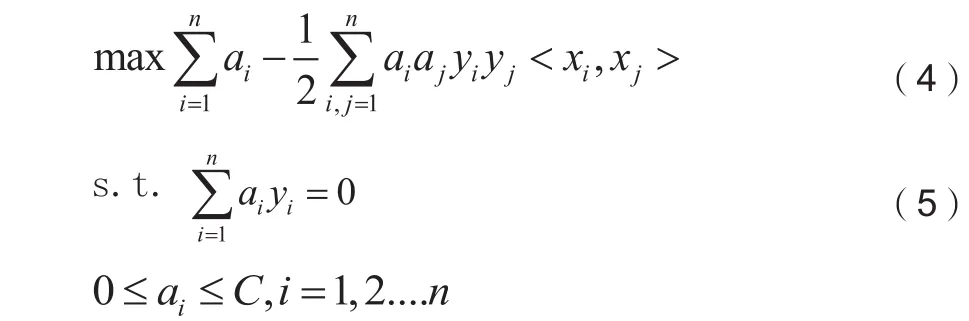
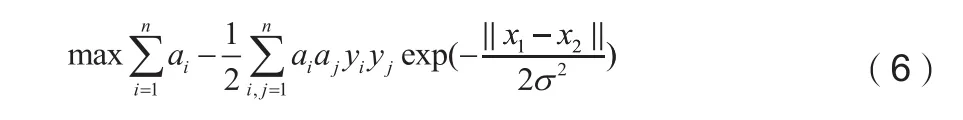
因此支持向量机的训练效果受惩罚因子、核函数的影响较大,本文将采用萤火虫算法改进支持向量机的参数。
3 基于萤火虫算法改进支持向量机的预测算法
在经典的萤火虫算法中,萤火虫的移动方向和移动距离分别由发光的强弱和吸引力的大小决定,因此利用发光的强弱和吸引力来持续改善萤火虫所处位置,最后达到最佳位置,获得支持向量机中最优的惩罚因子以及核函数,得出最优预测结果。
在利用 SVM 进行高校就业率预测时,需要得到惩罚因子、核函数参数的最优解,它们的取值会直接影响最终预测结果的精确度。因此,为了提高就业率预测的准确性,本文利用萤火虫算法优化支持向量机中的核函数参数和惩罚因子,建立基于萤火虫算法改进支持向量机IPPFA-SVM的就业率预测模型。具体步骤为:
(1)收集某高校连续20年的大四毕业生就业率作为机器学习数据。


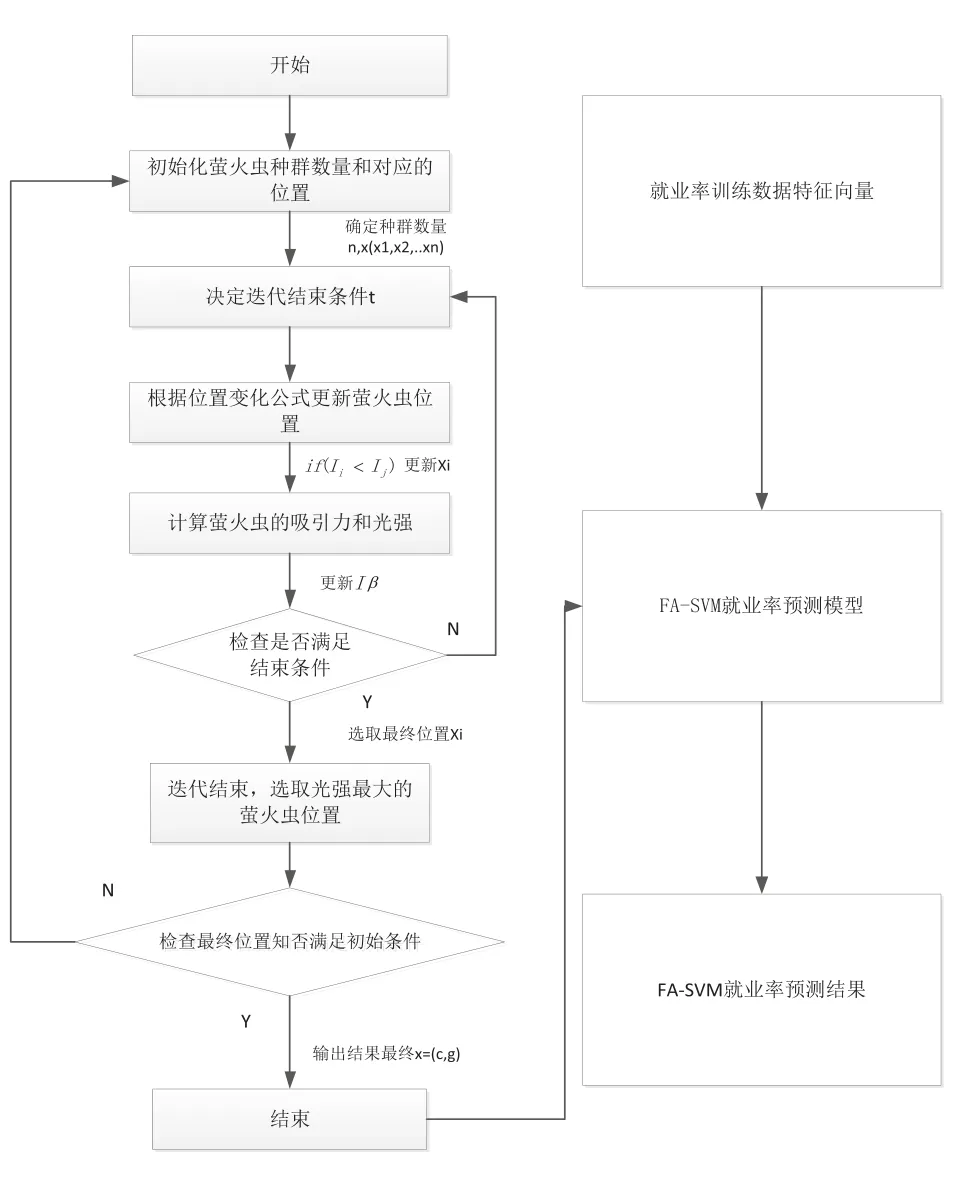
图1 就业率预测流程图
4 预测结果对比与分析
4.1 数据来源
本文以某普通高校的就业率为研究对象,选择1998—2017年该校就业率数据进行建模预测,来验证本文提出的基于萤火虫算法优化支持向量机的高校就业率模型的性能,就业率数据具体如图2所示。

图2 就业率数据
4.2 参数优化结果
利用优化后的萤火虫算法对高校就业率预测的SVM模型进行调优,设置合适的迭代次数。
然后在同一实验数据下,与BP算法预测、灰色系统算法预测、SVM算法进行预测并对比,就业率预测值对比结果值如3所示,其预测误差对比结果如图4所示。

图3 就业率预测值
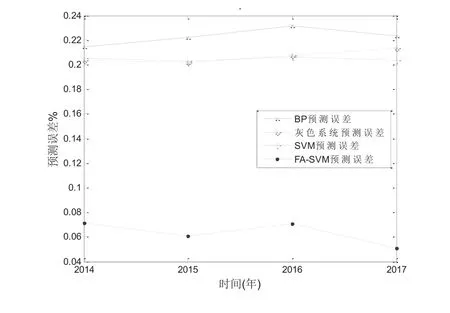
图4 预测误差
4.3 预测结果分析
由对比结果可知,在所有预测模型中,本文提出的FA-SVM方法预测准确率最高,达到99%以上,而BP神经网络模型最低,主要是因为由于神经网络的结构较复杂,同时要求的历就业数据较多,容易出现“过拟合”的预测结果。灰色预测算法的预测结果较神经网络算法有一定的提升,但缺乏自我学习和自适应的能力,对于非线性数据的处理能力不足。SVM算法的预测精度要优于BP神经网络,是由于SVM算法可以解决神经网络在小样本清况下过拟合、欠学习的缺陷,预测准确度相应提高。然而单一的SVM算法预测准确度要低于本文的预测算法,主要是本文采用的是萤火虫算法对支持向量机算法中的核函数参数和惩罚因子进行不断改进,提高了算法的预测准确性。实验结果表明,本文中的预测算法相比于其它预测算法具有一定的优越性。
5 结论
为了对高校大学生的就业率提供更加高效的预测和有价值的决策,提出萤火虫算法来优化SVM的高校就业率模型。因为高校学生就业率数据具有非线性化的特性,所以采用萤火虫算法对核函数参数和惩罚因子进行迭代计算,得到较为精确的就业率结果。本文研究的高校就业率预测误差比当前其他预测算法要小,预测效果得到了显著的改善,有利于未来中国高校就业情况的预测,有利于国家对于高校就业相关制度的制定提供有效的参考意见。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
小天使·一年级语数英综合(2018年7期)2018-09-12 10:13:26
小天使·一年级语数英综合(2017年6期)2017-06-07 23:44:03
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
为了孩子(孕0~3岁)(2016年1期)2016-01-16 20:42:21
新高考·高二数学(2015年11期)2015-12-23 18:17:44
小天使·一年级语数英综合(2015年8期)2015-07-06 06:31:24
新闻前哨(2014年11期)2014-12-25 09:12:29
职业技术教育(2014年9期)2014-07-08 18:08:19
