
基于多元统计和聚类分析的浙江省水质评价
2020-12-28 11:47刘颖
安徽农学通报 2020年22期
刘颖

摘 要:为了评价浙江省地表水质情况,根据2017—2020年浙江省地表水日监测数据,分别用多元分析和聚类分析对水质进行多方位、多因素的研究。结果表明,自2017年开始,浙江水质级别、单因子污染情况等都得到了不同程度的好转,到2020年4月水质级别全部控制在5类以内,且没有污染因子。
关键词:水质级别;多元分析;聚类分析;浙江省
中图分类号 S273.3;X824文献标识码 A文章编号 1007-7731(2020)22-0145-02
2012年浙江省环境公报数据显示,全省地表水总体水质为良,江河干流总体水质量基本良好,部分支流和径流域镇的局部河段仍存在不同程度的污染。浙江省有32个省控地表水断面劣五类,钱塘江、曹娥江、甬江、椒江、瓯江、飞云江、鳌江、苕溪等8大水系以及京杭运河等均受到了不同程度的污染。为此,浙江省政府先后于2013年和2017年分别提出了“五水共治”和“剿灭劣五类水”等政策,對浙江省水质提出了具体的要求。本文通过多元分析和聚类分析法对浙江省地表水质进行了评价分析,找出同类水质的规律和内在相关因素,以期为浙江省水质的检验提供科学依据。
1 数据来源
本研究采用是浙江省2017—2020年地表水日监测数据,这些数据中每个月都会不同程度的缺失一些日期的数据,2019年1—4月的数据则是完全缺失。数据中包含的水质指标有pH值、溶解氧、化学需氧量、氨氮、总磷等监测数值。监测数值的评价标准按照《地表水环境质量标准》(GB3838-2002)的相关规定执行。
2 研究方法
2.1 层次聚类分析法 层次聚类法(HCA)是聚类分析法中使用最多的一种,是把相似或相近的对象归并成类,主要研究如何度量相似性和构造聚类的具体方法,包括“R聚类-指标聚类”和“Q聚类-样本聚类。其中,R聚类可以在某些变量中选择出具有代表性的变量,Q聚类可以在聚类过程中发现具有共同属性的样本[1-4]。本文考虑同一站点的监测指标进行聚类,找出水质的规律和原因。相似程度包括样本间距离和组间距离2类,文中对这2类距离两两组合进行聚类分析,并计算相应的复合相关系数,相关系数越趋于1,说明聚类的效果越好,所以选择相关系数最大的距离组合。本研究采用的是绝对距离(式1)和重心距离(式2)。
3 结果与分析
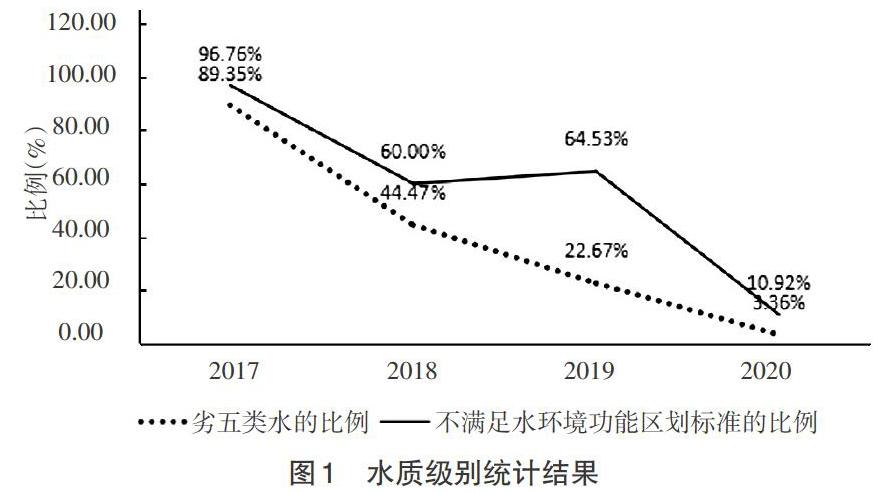
3.1 多元统计水质特征 本文采用的日监测数据包括水质类别、主要污染因子、pH值、溶解氧、化学需氧量、总磷、氨氮、监测日期等指标。数据中水质类别分为1~6类,经过对比和观察发现,水质类别数字越大,水质越差,所以对水质类别为6的监测值进行分析,统计出水质类别为6的站点所占的比例,选择数据比较完整的、6类水质出现频率最高的S1站点做多元统计分析[5-6]和聚类分析[3-5],其中S1站点的水环境功能区划标准为Ⅳ。按年份分别统计出水质级别为6的监测记录,得出2017—2020年劣5类水的比例;按照超出水环境功能区划标准的监测记录,得出2017—2020年不满足水环境功能区划标准的比例,其结果见图1。由图1可知,劣5类水的比例呈逐年下降趋势,且2017年下降的速率最快。不满足水环境功能区划标准的比例从2017—2020年总体在下降,但是在2019年出现了轻微反弹。
3.2 聚类分析水质特征 由于pH值在《地表水环境质量标准》没有具体的水质类别界限,所研究的数据中pH值位于6~9时则满足Ⅴ类水以内,且日监测数据中所有站点的污染因子均为出现pH值和化学需氧量,所以本文研究的水质指标为溶解氧、总磷和氨氮。采用Z-score方法根据式(3-4)对日监测数据进行标准化[3-4]。对S1站点的溶解氧、总磷、氨氮等3个指标的标准化后的数据进行聚类分析。变量之间的距离采用的5种距离和不同类之间的5种距离两两组合进行聚类分析,选择复合相关系数大的一种组合。以S1站为例,得到当选择绝对距离和重心距离时,复合相关系数最大,值为0.8438。对S1站842条有效记录进行聚类分析,当聚类成20类时,大量的数据集中在了3类里,这3类分别含有432条记录(记作G1)、162条记录(记作G2),119条记录(记作G3)。剩下的17类中含有的记录数分别在1~23,与前面3类含有的记录相差甚远,仅对G1、G2、G3这3类中的日监测数据进行分析。
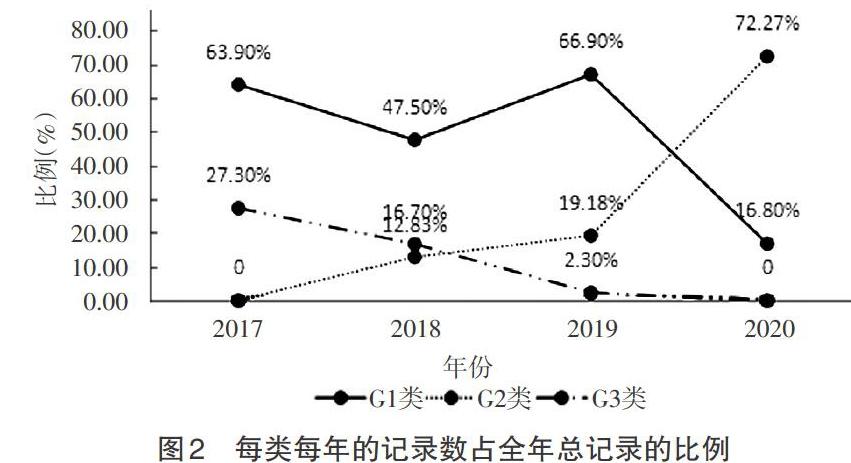
3.2.1 G1类 这一类所对应的水质类别位于4~6,其中水质类别为4的记录有135条,水质类别为5的记录有116条,水质类别为6的记录有181条。从年份来看,这一类的数据遍布于2017—2020年,其中2017年138条记录,2018年159条记录,2019年115条记录,2020年20条记录,分别占全年所有记录数的比例如图2所示。从污染因子来看,这一类中仅有3.9%的数据没有污染因子,剩下的96.1%的数据含有污染因子,几乎3种水质指标全部为污染因子,其中溶解氧为污染因子出现的次数最多。
3.2.2 G2类 这一类所对应的水质类别位于3~6,其中6类水仅为4条记录。从年份来看,这一类的数据全部属于2018—2020年,其中2018年43条记录;2019年33条记录;2020年86条记录,分别占全年所有记录数的比例如图2所示。从污染因子来看,这一类中的监测数据中有62.3%的数据是没有污染因子,剩下的37.7%的数据中污染因子为1种或者2种。
3.2.3 G3类 这一类所对应的水质类别全部为6,即水质全部为劣五类。从年份来看,其中59条记录属于2017年;56条记录属于2018年;仅4条记录属于2019年;属于2020年的记录为0,分别占全年所有记录数的比例如图2所示。从污染因子来看,这一类中的监测数据100%全部含有污染因子,且污染因子为3种水质指标,甚至还出现了高锰酸钾。
从这3类的分析来看,G1类属于水质情况尚可,但是某一项水质的单因子污染情况比较严重的一类,这类水质在治理的过程中出现了反复波动,但总体趋势是逐渐好转的;G2类属于水质较好,且单因子污染几乎没有的一类,随着年份的增加,这一类水质正逐渐增加,且增加的速率在加快;G3类属于水质比较差,且单因子污染情况比较严重的一类,随着年份的增加,这一类水质在逐渐减少。
4 结论与讨论
本研究结果表明,无论是多元统计分析还是聚类分析,都能很好的展示S1站点从2017—2020年水质在不断的好转,水质从2017年有89.35%的水质级别为6的水上升到2020年的3.36%,到2020年90%的水质达到水环境功能区划标准。
将多元统计和聚类分析的方法用于分析拥有大量数据的水质分析,将800多个样本分为20组,在方差分析结果可靠的情况下,多方面、大尺度地分析了S1站点的水质,能够从众多的数据中找出内在的规律和联系。
参考文献
[1]郑泽豪.基于聚类分析水质指标相关性研究[J].广东水利水电,2020(5):59-62.
[2]马振,周密.聚类分析在秦淮河水质指标相关性研究中的应用[J].水文,2018,38(1):77-80.
[3]张旋,王启山,于淼,等.基于聚类分析和水质标识指数的水质评价方法[J].环境工程学报,2010,4(2):477-480.
[4]刘波.基于基于改进的灰色聚类分析方法的区域浅层地下水水质综合评价研究[J].水土保持应用技术,2017(5):1-3.
[5]贾洁.基于多元统计分析方法的湟水质量变化及调控对策[J].能源与环保,2019,41(2):107-110.
[6]唐国平,陈德超,黄振旭,等.基于多元统计和水质标识指数的丹金溧漕河溧阳段水质评价研究[J].苏州科技大学学报(自然科学版),2017,34(4):70-75. (责编:张宏民)
猜你喜欢
老年教育(老年大学)(2022年8期)2022-08-24
浙江国土资源(2019年10期)2019-10-31
中等数学(2018年7期)2018-11-10
中等数学(2018年4期)2018-08-01
——张脆音
数学大世界(2017年35期)2018-01-11
杭州科技(2013年5期)2013-03-11
