
基于最优学习的社交网络JPEG图像敏感数据挖掘方法①
2020-12-28 02:37陈小永
佳木斯大学学报(自然科学版) 2020年6期
陈小永
(安徽电子信息职业技术学院 信息与智能工程系,安徽 蚌埠 233000)
0 引 言
社交网络中存在大量沟通时产生的JPEG图像敏感数据,此类敏感数据有可能包含用户性别、地区、职业、兴趣爱好、身份证及年龄等信息,涉及到用户的个人信息及隐私等[1],若不重视此类敏感数据,将导致用户个人信息与隐私的泄露,严重危害用户个人财产安全的问题[2]。故需对社交网络JPEG图像敏感数据实施有效的保护,避免用户个人信息泄露,保障社交网络沟通的安全性,而保护此类敏感数据的基础即对其实施有效的数据挖掘[3],数据挖掘算法可通过某对象的先验概率,运算出此对象的后验概率,鲁棒性较高[4]。
综合以上分析,研究一种基于最优学习的社交网络JPEG图像敏感数据挖掘方法,将朴素贝叶斯算法作为该挖掘方法的核心算法,深入、有效地挖掘出社交网络数据中的JPEG图像敏感数据,并提升挖掘的精度与实时性。
1 最优学习的社交网络JPEG图像敏感数据挖掘方法
1.1 基于朴素贝叶斯算法的数据挖掘平台构建
以朴素贝叶斯算法作为社交网络JPEG图像敏感数据挖掘方法的核心算法[5],基于此算法构建社交网络JPEG图像敏感数据挖掘平台。朴素贝叶斯算法定理如下:
朴素贝叶斯算法属于一类分类算法的总称,此类分类算法的基础均为朴素贝叶斯定理,所以也可统称为朴素贝叶斯分类[6]。朴素贝叶斯定量能够合理解决实际生活中时常发生的事件,假如两事件分别以C和D表示,其中事件C和事件D出现的概率分别以Q(C)、Q(D)表示,两事件同时出现的概率以Q(CD)表示,在事件C已经出现的情况下,事件D出现的概率以Q(D/C)表示,同时有:
Q(D/C)=Q(CD)/Q(C)
(1)
事件C与事件D无论是否属于彼此独立的事件,均有:
Q(CD)=Q(D)Q(C/D)=Q(C)Q(D/C)
(2)
设样本空间Ω的一个划分为D1,D2,…,Dn,能够符合Di两两互斥,且DiDj=φ(i≠j),∑Di=Ω(i=1,2,...,n),那么有全概率公式:
Q(C)=Q(C∩Ω)=Q(C∩∑Di)=
Q(∑CDi)=∑Q(CDi)=∑Q(Di)Q(C/Di)
(3)
假设Y∈Ω属于一个未知类型的数据样本,aj属于某个类型,如果数据样本Y为一个特定的类型aj,则分类问题即为确定Q(aj|Y),也就是在获取数据样本Y时,将数据样本Y的最佳分类确准。在给定数据集B内各类型aj先验概率的条件下可能性最大的分类即为最佳分类。运算此种可能性的一种较为直接的方法可通过贝叶斯定理提供。基于假设的先验概率、设定假设下所观察到的各类数据概率,贝叶斯定理提供一种运算假设概率的方法[7],可表示为:
Q(aj|Y)=Q(Y|aj)Q(aj)/Q(Y)
(4)
式(4)属于贝叶斯公式,其中先验概率、后验概率及联合概率分别以Q(aj)、Q(aj|Y)、Q(Y|aj)表示。
(1)先验概率Q(aj):aj的先验概率即为Q(aj),有关aj属于准确分类机会的背景知识可通过先验概率反映出。若无此先验知识,则可将同等的先验概率赋予给各个待选类型,但一般而言,可通过样例内属于aj的样例数|aj|与总样例数|B|的比值实施近似运算,也就是:
(5)
(2)联合概率Q(Y|aj):联合概率也成为条件概率,即在已知为aj类型的情况下,数据样本Y所出现的概率。如果设定Y=〈c1,c2,...,cm〉,那么有:
Q(Y|aj)=Q(c1,c2,…,cm/aj)
(6)
(3)后验概率Q(aj|Y):aj的后验概率即为Q(aj|Y),是指当数据样本Y给定时,aj成立的概率,可反映出数据样本Y出现之后aj的成立置信度。
逻辑性较强的数据挖掘平台,由特征数据萃取层与概率数据构建层共同构成。其中特征数据萃取层是在朴素贝叶斯算法的特征涵盖性基础上创建而成,概率数据构建层是基于朴素贝叶斯算法的概率条件引入广泛性而创建的,通过创建两个层面,实现数据挖掘平台的构建,产生立体化社交网络JPEG图像敏感数据挖掘平台。数据挖掘平台整体结构图见图1。

图1 数据挖掘平台整体结构图
1.2 平台功能层设计
1.2.1 特征数据萃取层设计
在互联网空间中建立社交网络数据模型,可以提高对社交网络JPEG图像敏感数据的数据类别和数据趋势的理解,为特定类型数据的概率深度挖掘提供方便,从而提高数据挖掘的速度和准确性。通过基于朴素贝叶斯算法优化的tbht拓扑特征逻辑算法,该层可以根据数据之间的拓扑关系实现特征捕获,并通过概率逻辑转换各种数据特征,从而形成数据挖掘的必要条件,提高了社会网络JPEG图像敏感数据挖掘的准确性。Tbht拓扑特征逻辑算法继承了朴素贝叶斯算法的概率运算,也具有独立的逻辑处理性能。故TBHT拓扑特征逻辑算法的关系式为双子集合式,可表示为:
(7)
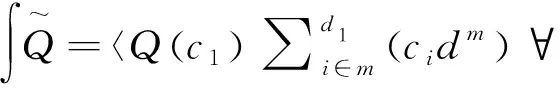
(8)
式(7)、式(8)中,社交网络JPEG图像敏感数据类型集合以c表示,数据类型系数与特征类型量系数分别以i和m表示,概率常量与数据挖掘特征限制要素集合分别以k和d表示。当式(7)能够满足以式(8)为引入常量时,表示完成特征数据萃取层的数据模型构建。特征数据萃取层结构见图2。
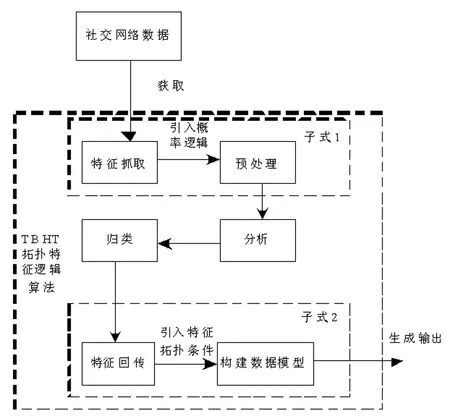
图2 特征数据萃取层结构图
为了提升数据挖掘的精度,需创建更加优质的数据模型,而优质数据模型的创建则需通过优质精准归类的特征数据实现。所抓取的社交网络特征数据中包含文字记录数据、出错记录数据、请求记录数据以及JPEG图像敏感数据等各类数据,且数据质量不一致,故为提升之后分析归类的精度、可伸缩性及有效性,应对抓取的特征数据实施预处理。
1.2.2 概率数据构建层设计
为实现对各种特征关系下社交网络JPEG图像敏感数据的有效挖掘,需提升引入的特征量,令初始社交网络JPEG图像敏感数据挖掘逻辑具备衍生性和包容性。OWF-RV集列算法具有庞大的数据逻辑量,其关系式内包含数组概率逻辑式,对相应概率逻辑式的调用及运行可采用逻辑对接触发关系式实现。在此以六组概率逻辑式及逻辑对接触发式为例,实施集合式运算。具体如下:
六组概率逻辑式为:
(9)
式(9)中的六组概率逻辑式相互之间为逻辑条件递增关系,各关系式均可单独成立,同时均包括上个关系式引入的特征条件值。集合化运算六组概率逻辑式能够获得集合式为:
Q(ie)
(10)
逻辑对接触发式为:
(11)
动态概率分离器可以快速调用由概率特征条件检索到的数据流,提高下游挖掘数据的潜力,并与大数据社交网络JPEG图像敏感数据中的深层数据源相关联,从而实现对社交网络JPEG图像敏感数据的深度挖掘。
在业务资源有限的情况下,动态概率分离器可以自动提取其运行资源的5%,从而建立大数据资源的交互通道规则。社会网络JPEG图像敏感数据挖掘通过获取小资源的大数据来提高挖掘精度。利用数据本身的特征信息,比较数据对接的挖掘精度,自动偏移挖掘误差数据的节点信息,保留准确的节点信息,快速生成数据挖掘返回信号。实现了JPEG社交网络图像敏感数据的高精度深度挖掘。动态概率分离器中分离算法为:
X|m|=e|q(c)|∑g/∬(q(c))∀
(12)
概率数据构建层结构图见图3。
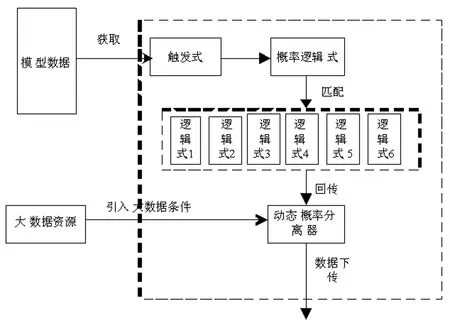
图3 概率数据构建层结构图
2 实验结果分析
以某微博平台内的历史大数据资源集作为检验本方法性能的实验数据集,大数据资源集内包含文字记录数据、出错记录数据、请求记录数据以及JPEG图像敏感数据等各类数据共88546条,分别采用本文方法、全局相似度的社交网络数据挖掘方法(文献[5]方法)以及基于影响力的社交网络数据挖掘方法(文献[6]方法)挖掘实验数据集内的社交网络JPEG图像敏感数据,对比并分析各方法的挖掘性能及效果。
2.1 整体可靠性对比分析
2.1.1 分类结果对比分析
在实验数据集的JPEG图像敏感数据中,实际包含五种不同类别的敏感数据,分别为性别、职业、兴趣爱好、社交情况及所在地区五种类别,现将各方法挖掘过程中对实验数据集实施预处理并分类之后所获得的JPEG图像敏感数据模型内的数据类别分别与实际数据类别进行对比,检验各方法的分类性能,对比结果如表1所示。

表1 各方法分类性能对比情况
由表1能够看出,对比实验数据集内JPEG图像敏感数据实际所包含的五种类别数据,文献[5]方法分类后所得的数据模型内存在职业类别数据的缺失,而文献[6]方法与本方法分类后所得的数据模型内五种类别数据均包含在内,未出现缺失问题,可见文献[6]方法与本方法挖掘过程中的分类性能更优越。
2.1.2 挖掘结果对比分析
在各方法的分类结果基础上,继续运用三种方法分别对各自分类后所得的数据模型内各类别JPEG图像敏感数据实施挖掘,依据挖掘结果对比各方法的挖掘性能,对比结果如表2所示。
三种方法的整体JPEG图像敏感数据挖掘结果误差中,文献[5]方法的误差显著高于其它两种方法,原因是文献[5]方法在挖掘过程中实施分类时缺失职业类别数据,由此导致此方法最终挖掘结果误差大大降低;而本方法与文献[6]方法对比,本方法的JPEG图像敏感各类别数据挖掘结果误差均低于文献[6]方法,由此可见,本方法的挖掘结果误差最低,结果更加精准可靠,具有较高的挖掘性能。
综合以上两组实验结果分析可知,相比其它两种方法,本方法的整体性能更优越,挖掘结果更可信,实际应用价值更高。
3 结 论
提出一种基于最优学习的社交网络JPEG图像敏感数据挖掘方法,以朴素贝叶斯算法最为最优学习方法,构建社交网络JPEG图像敏感数据挖掘平台,通过平台内两个功能层实现对社交网络数据中JPEG图像敏感数据的深入挖掘,并通过实验检验了本方法的整个挖掘过程,验证了本方法的分类精度、挖掘精度及较高的时效性,能够精准高效地挖掘出社交网络数据中的JPEG图像敏感数据,为社交网络用户的安全沟通提供有效保障。
猜你喜欢
上海电机学院学报(2022年4期)2022-08-29
法律方法(2021年4期)2021-03-16
大众投资指南(2021年35期)2021-02-16
科技经济导刊(2021年1期)2021-01-18
中国交通信息化(2020年1期)2020-07-27
网络安全和信息化(2020年6期)2020-06-20
周口师范学院学报(2019年5期)2019-10-16
中国生物医学工程学报(2019年6期)2019-07-16
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
郑州大学学报(理学版)(2014年2期)2014-03-01
