
基于机器学习的配电网线损自动计算模型分析
2020-12-28 10:13潘炜,史琳,张卓
通信电源技术 2020年17期
潘 炜,史 琳,张 卓
(广东电网有限责任公司广州供电局,广东 广州 510000)
0 引 言
配电网自动化系统在应用中积累了丰富的数据,如果有效分析这些历史性数据,能够为掌握和控制配电网线损提供数据依据。借助大数据的处理技术,基于机器学习的线损异常分析模型,通过机器学习的自适应和自学习的能力不断优化和处理模型。按照聚类分析和关联分析方法和个别异常之间存在的关联关系,实现对模型分析的准确度和精度的优化,可提高线损问题发现的及时性。结合系统判断的结果和核查确认的情况,系统能够提取被确认异常线路和台区内的数据特征,通过机器学习算法聚焦被确认的同类数据特征的异常情况,同时每月不断排查未确认异常的数据特征,深度剖析问题原因,并跟踪异常数据的整改情况,验证异常的消失时间,从而有效控制配电网的线损。
1 线损自动计算模型概述
目前有很多线损的计算方法,包括均方根电流法、牛顿法以及线性回归分析法等。由于实际中数据的缺失和电力网络的节点较多,电网的运行数据和结构参数的收集和整理比较困难,因此上述方法存在很大弊端。随着人工神经网络的发展和引入,依据神经网络的配电网线损计算法逐渐产生。神经网络模型有着高度非线性处理性能,能够拟合配电线路线损和特征参数间复杂性和非线性的关系,所以提出了一种以机器学习为基础的对配电网线损进行自动计算的模型(ELACM-ML)。此模型主要通过使用无监督的聚类算法自动聚类处理训练样本,然后借助每个类别训练样本对支持向量的回归机实施训练,以获取相应拟合的函数[1]。此模式具有显著的优点,能够自动聚类训练样本,借助无监督的聚类算法聚类处理训练样本。每个类中的样本线损值较为接近,能够提升每个类别内模型拟合的程度,同时线损计算的效率较好、精度较高且误差较小。
2 模型构建
2.1 模型结构
此模型主要包括训练样本集合、无监督的分类器、支持向量的回归机以及线损计算模块4部分。训练样本集合主要包括训练样本、计量电网线路内表计的数据、各个节点属性值以及各相邻节点间的差值等数据,在特征选择和样本标准化后构成训练样本集合。无监督的分类器的主要作用是自动分类整理训练样本集合内的数据,使每个类中的样本具有接近的线损值。无监督的分类器的样本集合的预处理,可提升每个类别内支持向量的回归精度。支持向量的回归机的主要作用是学习无监督的分类器,获取训练样本的子类,从而获取各个子类拟合函数的估计情况。在线损计算的模块中,用支持向量的回归机学习每一类样本,从而获取一组支持向量的回归机仿真机。把某样本按照无监督的分类器实施分类并获取其分类结果,然后把其输入到所在类支持向量的回归机仿真机内,通过计算和输出能够得到线损的计算结果[2]。
2.2 学习样本的构造
配电网中与线路线损有很多相关性的特征参数,主要包括线路有功功率和无功功率的供电量、线路长度、变压器总容量、变压器台数、线路总截断数、流经电流以及线路内自动化的表计所获取运行的参数等。计算配电网的线损时,支持向量的回归机模型内输入节点的数量主要由配电网能够获取线路的参数和运行参数的个数决定。通过分析实际的配电网,发现4个和线损最相关的数量特征参数,同样也可以考虑更多的特征参数。按照4个数量特征的参数对模型内输入的变量X设置维数组(x1,x2,x3,x4),分别代表线路有功功率的供电量值、线路无功功率的供电量值、变压器总容量以及线路总长度值。
对输入值和输出值实施标准化处理,确保计算不会受到量纲影响。输入的变量维数是4个,样本个数是N个,样本数据集为X={x1,x2,…,xN},则对样本某xi的自变量xij要实施标准化处理。
2.3 对样本分类处理
聚类的数目假定是C,通过一种简单无监督的聚类算法对此C类数据实施聚类处理。此方法与传统K-means算法相比,预先指定的类别数不同,是按照预先给定聚类的半径聚类处理数据,聚类速度较快[3]。对于待聚类X={x1,x2,…,xN}的数据集,假定其聚类的半径是R,此算法的描述为:

若Z=0,聚类会停止,否则选择x∈Z样本,在经存在的质心找出和xi最近距离的质心Oj;若dist(xi,Oj)≤R,则要把xi添加到类Cj中,也就是Cj=Cj+{xi};若dist(xi,Oj)>R,增设一新类为cluster_num=cluster_num+1,则:
此算法中,最大的时间开销是O(cluster_num×m),效率较高。
2.4 拟合函数的求解
通过学习样本的构造和对样本分类处理获取某子类训练的样本为(xi,zi),i=1,2,…,N。通过高维特征的空间线性函数来拟合训练样本,此函数表示为:

式中,φ(x)把训练的数据自输入的空间向高维特征的空间映射,从而把输入空间内非线性的拟合问题转变为高维特征的空间线性拟合的问题。考虑协商性问题的实时性要求,本文的模型通过支持向量的回归机学习样本,使得支持向量的回归机内算法回归问题能够表示成约束优化问题,然后通过Lagrange方法将约束优化问题转变为无约束的优化问题,再结合学习样本的构造获取支持向量的回归机具体输出,也就是拟合函数:
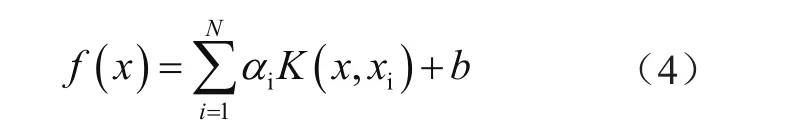
此拟合函数为配电网的线损计算函数,把待计算的样本x输入拟合函数,得到的输出就是线损实际值。
2.5 计算线损
假定存在训练的样本集为X,借助无监督的分类器分类整理样本集,能够获取x1、x2以及x3共3个子样的本集,然后通过此3个子样的本集对支持向量的回归机分别实施训练,获取3个支持向量的回归机。假定各自拟合的函数为f1(x)、f2(x)以及f3(x),在对某被测数据x计算中,要先实施分类,后按照所在的类别计算拟合函数,从而获取此x数据线损的估计值。若x属类别X2,则通过f2(x)拟合函数计算其线损。
3 仿真性实验
选取相应实验室的数据,准确计算68组线路线损,以验证模型的有效性和实用性。本文训练与分析此68组线损样本的数据,其中58组当作训练样本,其余10组当作检验样本。
3.1 实验一:在分类的预处理后对线损计算的实验
先通过无监督聚类算法将这58组线路的样本数据分作4类,对4类样本的数据分别进行支持向量的回归机训练,完成训练后获取相应4种支持向量的回归仿真机。分类处理10组测试样本的相关数据,然后用各自支持向量的回归机SVR仿真并输出,得到相应的结果。
3.2 实验二:对没有分类的预处理线损计算的实验
为进一步验证本文模型算法的有效性,此实验不分类训练样本,直接通过支持向量的回归机实施处理,能够获取一种支持向量的回归仿真机,然后通过此支持向量的回归仿真机仿真计算和输出10组测试样本相关数据得到的相应结果。
3.3 实验结果与分析
实验一和实验二的实验结果如表1所示。
从表1能够看出,支持向量的回归仿真机的线损计算结果具有较高的精度,存在的误差较低,说明此方法对线损的计算效果较好。通过对比表1的实验结果可知,与通过分类的预处理支持向量的回归仿真机实验相比,没有通过分类的预处理支持向量的回归仿真机对配电网的线损计算得到结果的精度较低,且其平均相对误差超过了10%。可见,对训练样本实施分类预处理,可以有效提升线损模型计算的效率。
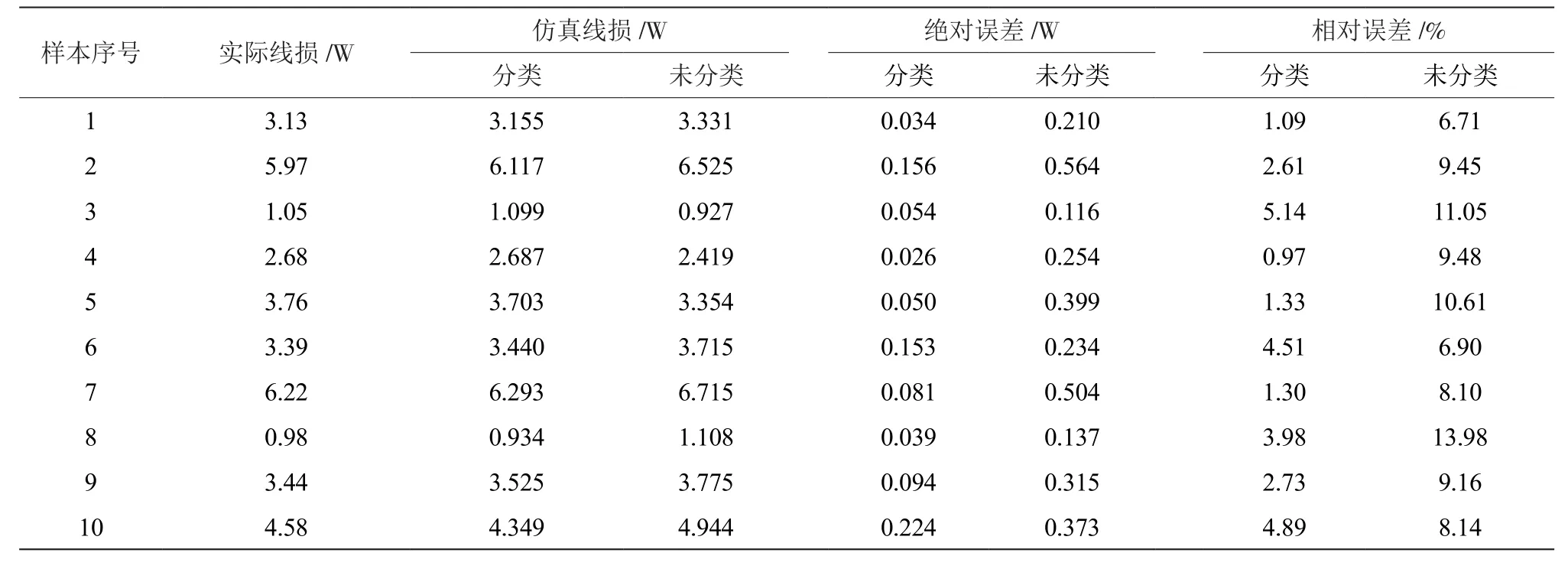
表1 在分类和未分类的预处理后线损计算的结果
4 结 论
本文在配电网线损计算中运用了向量机,构建了相应线损计算模型,然后利用代表性线路线损和特征参数的样本数据,借助支持向量的回归拟合线损和特征参数间的复杂性和非线性关系,从而获取线损与特征参数的变化规律。模型先通过无监督聚类算法分类训练样本,然后按照每类内样本对其实施训练,不仅降低了所有样本的计算复杂度,还能够提高结果的精度。
猜你喜欢
湖南大学学报(自然科学版)(2022年8期)2022-09-02
舰船科学技术(2022年10期)2022-06-17
杭州电子科技大学学报(自然科学版)(2020年6期)2020-12-03
——以某铅锌矿为例
物探化探计算技术(2020年1期)2020-04-09
科技创新与应用(2020年6期)2020-02-29
电子制作(2019年16期)2019-09-27
活力(2019年22期)2019-03-16
电子制作(2018年8期)2018-06-26
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
