
基于人工智能的网络安全管理关键技术
2020-12-28 10:13邱宏
通信电源技术 2020年17期
邱 宏
(中国人民警察大学 智慧警务学院,河北 廊坊 065000)
0 引 言
随着互联网技术在各行各业的广泛应用和移动网络技术的普及,电视商务等网络活动越来越多,网络空间处理并存储的敏感信息不断增加。因此,网络安全管理成为一个亟待解决的问题。在分布式系统出现后,以防火墙、网络安全监控以及入侵检测等为代表的传统网络安全技术手段逐渐不能满足安全管理的需求。首先,目前的认证机制是基于用户身份认证的,但在大规模分布式系统中,系统不一定熟知所有用户。其次,传统的安全管理机制对新的访问条件无效,也没有委托机制。最后,传统的安全机制多是服务器实现所有的访问控制,如果服务器层面安全失效,那么整个访问控制策略会受到影响[1]。目前,人工智能技术在很多领域获得了深入应用。网络安全管理技术和人工智能技术的结合,对网络安具有重要作用,如基于聚类的入侵检测和基于模糊聚类的信任模型等。
1 文献综述
林果园等使用一种借助合法数据集对网络进行重复训练的方法,降低了网络安全攻击的效果,提高了网络抗攻击的能力[2]。汪洋等利用公开的API重建网络安全信任模型,证明重建的模型对各种人工智能算法都有效,可以有效防止网络攻击[3]。郭惠听等在网络结构中引入一个附加层,并且增加了一个扰动噪声,既能够保持用户网络行为的准确性,又可以检测网络中的异常行为[4]。Wonhyung Park提出以数据融合模型为基础的网络安全架构,增加一个措施层,在面临网络攻击时能够提供可选择的防护措施,从而帮助决策[5]。赵鹏飞提出一个层次化的网络安全评估模型,在面临网络安全问题时采取先局部后整体的评估方法,有效结合了网络性能、网络架构以及海量报警信息,但其信息来源只有入侵检测报警信息一种,缺乏防火墙和系统日志等信息[6]。符江鹏构建一种多层次多角度的网络安全量化模型,采集入侵检测和防火墙等多种信息源的数据,保障了数据源的全面性和准确性[7]。
2 人工智能技术
人工智能的一个重要应用分支是模式识别。在具有已知模式类别和样本数据属性的情况下,分类训练所有非样本数据,以达到正确的分类效果。模式识别要求对分类的问题有足够的先验知识,预先设定的类别要足够准确,否则在没有先验知识的前提下对数据进行分类需要借助无监督的分类技术,也就是聚类分析。
聚类分析根据最大化同类的相似性和最小化不同类的相似性原则,把所有的数据分成多个类别。同类别的数据具有较高的相似度。传统的聚类分析方式是硬划分,即数据样本要么属于A类,要么属于B类或其他类,不存在哪个类别也不属于的情况。这种非此即彼的划分存在一定的缺点,因为多数对象并没有严格的类别属性,在类属方面可能存在中介性。传统的聚类分析方式割裂了样本间的联系,导致样本数据分类时的偏差较大,容易出现局部最优解的情况。
模糊聚类方法克服了传统聚类分析在类别硬划分上的缺陷,把数据样本隶属于不同类别的隶属度扩展到一个区间。当数据样本的隶属度在此区间时,认为属于某一类别,而不是根据绝对的属于或不属于来判断。模糊聚类方法在对不同类别间的数据集进行分类时更加有效,分类效果远远优于传统的硬分类。
在聚类比较密集且不同类别间有明显区别时,K-均值聚类算法有较好的效果。K-均值聚类算法在分类初始时选择一个参数K,将所有的数据分成K个簇,每个簇内有较高的相似度,而簇间的相似度较低。首先,随机选择K个对象,将其作为K个簇的初始平均值或中心。其次,计算剩余的每个对象与K个簇中心的距离,并将对象的类别设置为距离它最近的簇。再次,重新计算每个簇的平均值,并再次划分剩余对象的类别。最后,不断重复这一过程,直到收敛函数达到设定的阈值[8]。
3 人工智能应用于网络安全的技术架构
将人工智能技术应用于网络安全时,常见的主要有数据搜索、行为建模和构建画像3层架构。网络安全中的人工智能技术架构如图1所示。
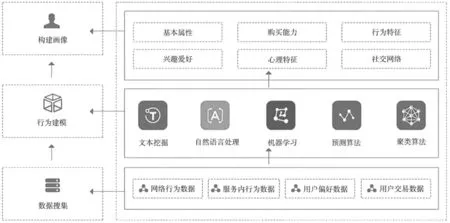
图1 网络安全中的人工智能技术架构
数据搜集阶段需要搜集的数据包括网络行为数据、用户偏好数据以及交易数据等。这些数据经过如聚类算法、自然语言处理以及机器学习等人工智能技术的处理后,可以得到网络用户的行为模型。
行为模型的建模过程中,常用的人工智能技术包括聚类算法和机器学习等,对网络安全管理具有重要作用。
用户画像是根据网络用户的行为习惯等信息,抽象得到一个标签化的用户模型。构建用户画像的过程实际上是给用户打标签的过程。这些用户标签代表了用户使用网络过程中的各种信息特征。
4 网络安全检测方法
均值聚类算法的优点是计算简单,收敛速度较快,因此在网络安全领域得到了广泛应用,尤其是网络入侵检测方面。然而,K-均值聚类算法对初始值要求较高,如果参数K设置不恰当,容易出现局部极值点。
为了解决K-均值聚类算法初始化参数要求高的问题,可以借助克隆选择算法优化目标函数。使用基于克隆选择的聚类方法进行网络异常行为检测时,需要满足两个条件:一是正常的网络行为数目需要远远大于入侵网络行为;二是入侵网络行为的特征与正常网络行为特征间需要存在较大差别。利用基于克隆选择的聚类算法进行入侵检测时,需要先使用克隆选择算法进行聚类,将所有的网络行为分成两大类别,然后基于入侵网络行为和正常网络行为存在较大差别且数目相对少的原则,从所有网络行为中检测出异常。
基于克隆选择的聚类算法在进行聚类时,主要操作步骤如下。
步骤1:需要先随机生成初始群体,将初始群体每个个体解码为对应的二进制编码特征组合;
步骤2:在新样本集合中计算各个个体的亲和度;
步骤3:检查是否满足迭代终止条件,如果达到迭代次数或者收敛函数满足收敛条件,则将当前个体确定为最优解,否则继续;
步骤4:执行克隆操作,并将克隆出来的二进制特征编码进行变异,然后再次计算亲和度;
步骤5:重复步骤2~步骤4,直到收敛函数收敛[9]。
使用基于克隆选择的聚类算法聚类后,再统计所有类别包含的数据量,并根据数据量从多到少进行排序。由于正常数据形成的聚类包含的数据量要远远大于异常数据聚类包含的数据量,根据预先设定的阈值,可以将包含的数据量多于此阈值的分类设定为正常类,而数据量小于此阈值的分类设定为异常类。
克隆选择算法是群体搜索策略,具有并行性和搜索变化的随机性,不会导致局部最优解的问题,且收敛速度较快。因此,基于克隆选择的聚类算法在入侵检测中应用广泛,完全适用于大数据集的聚类分析。
5 网络安全信任管理模型
网络范畴中的信任指的是能够根据证据或经验,判断参与通信协议的实体是否遵守预先设置的规则集。顾名思义,信任模型是用于计算或判断网络节点可信任度的模型,主要作用是建立并管理网络间的信任关系。常见的信任模型包括Beth信任模型和Josang信任模型。
Beth信任模型将经验定义为实体完成任务的情况记录。如果实体完成任务成功,则增加其肯定经验,否则增加其否定经验。Josang信任模型引入证据空间和逻辑空间对信任关系进行描述,是一种基于主观逻辑的信任管理模型。每个实体产生的事件被分成肯定事件和否定事件。证据空间表示为多个实体产生的可观测事件,并根据二项分布得到观测的肯定事件数目和否定事件数目决定的概率密度函数,计算实体产生某个事件的可信度。
可以将推荐机制引入信任模型管理,如果请求节点i发起对节点j的信任度查询,则网络中和节点j曾经存在直接交互的节点(称为推荐节点)收到信息后,会将其保留的节点j的交互性信息发送给节点i。节点i收到所有推荐节点的交互性信息后,汇总推荐节点的认知信息,从而得到节点j的信任度集合。
节点i随后计算节点j的信任度。首先,计算局部信任度,即两个节点交互完成后,请求节点i根据节点j为其提供的服务进行评价。其次,计算聚合局部信任度。节点i根据得到的信任度集合计算信任度均值。最后,信任度评价。根据局部信任度和聚合的局部信任度,计算每个推荐节点与聚合局部信任度的方差。信任度方差高的节点标记为正常节点,而信任度方差低的节点标记为恶意节点。
为验证信任管理模型,可以使用Query Cycle Simulator仿真包,在模拟P2P共享网络的同时,实现信任管理模型的改进。仿真过程由多个查询周期组成,每个查询周期内网络节点的状态是不一定的,可能处于在线状态或离线状态。网络仿真设置如表1所示。

表1 网络仿真设置
在分析仿真结果前,可以先进一步划分恶意节点。简单恶意节点在网络系统中并不主动发起危害网络安全的行为,但是在有网络安全行为时可能会提供错误的信息。诋毁节点在评价其他节点的信任度时,会提供不真实的负面评价[10]。
对信任模型进行抗攻击性仿真实验后,对比不同信任机制下的成功率,并将成功率作为仿真的评价标准,可以得到如下结论。一方面,在系统没有恶意节点时,网络系统的成功率几乎在95%以上。随着网络中恶意节点数目的增加,各种信任模型的成功率都会呈现下降趋势。相比之下,Beth信任模型下降更快。另一方面,随着诋毁节点的增加,Josang信任模型比Beth信任模型的成功率下降得更快,尤其是在网络系统中诋毁节点的比例超过30%时。正如前文所言,Josang信任模型是一种基于主观逻辑的信任管理模型,更易受到主观因素的影响。
6 结 论
本文研究了基于人工智能的网络安全管理技术,介绍了聚类分析技术和常见的聚类方法,并将其应用于网络安全常见的异常行为检测,同时阐述了信任管理模型并进行了仿真。结果表明,基于人工智能的网络安全管理技术对网络安全管理具有重要作用。
猜你喜欢
陶瓷学报(2021年4期)2021-10-14
少儿画王(3-6岁)(2020年4期)2020-09-13
现代计算机(2018年27期)2018-10-25
环球时报(2018-01-23)2018-01-23
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
汽车维护与修理(2015年5期)2015-02-28
IT经理世界(2014年5期)2014-03-19
微型计算机(2009年4期)2009-12-23
