
一种面向Fabric区块链应用软件的体系结构演化算法
2020-12-24 08:01赵会群张隆龙
软件 2020年7期
关键词:区块链
赵会群 张隆龙

摘 要: 针对联盟链Fabric中,orderer节点一旦发生异常,只能在下一个时间间隔继续,而当前时间间隔浪费的问题,本文对Fabric体系结构进行了演化,提出了一种新的思路,使得orderer节点产生异常后,系统可以在当前间隔内正常工作,不必等到下一个时间间隔。最后通过实验对算法在吞吐量、资源利用率等性能指标上进行了对比分析,表明了Fabric软件软件体系结构演化算法的有效性。
关键词: 区块链;Fabric联盟链;体系结构演化;容错机制
中图分类号: TP311 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.07.001
本文著录格式:赵会群,张隆龙. 一种面向Fabric区块链应用软件的体系结构演化算法[J]. 软件,2020,41(07):01-10+60
An Architecture Evolution Algorithm for Fabric Blockchain Application Software
ZHAO Hui-qun, ZHANG Long-long
(North China University of Technology, Information Institute, Beijing 100144, China)
【Abstract】: In order to solve this problem: at the alliance chain Fabric, if the orderer node has an exception, it can only continue at the next time interval and the current time interval is wasted, this paper proposes a new idea to evolve the fabric architecture, so that after the orderer node has an exception, the system can work normally in the current interval without waiting for the next time interval. Finally, the algorithm was compared and analyzed through experiments on performance indicators such as throughput and resource utilization, which showed the effectiveness of the evolutionary algorithm of the Fabric software architecture.
【Key words】: Blockchain; Fabric alliance chain; Architecture evolution; Fault tolerance mechanism
0 引言
区块链技术兴起于2008年,化名为“中本聪”(Satoshi nakamoto)的学者发表了一篇奠基性论文《Bitcoin: a peer-to-peer electronic cash system》[1],具有去中心化、不可篡改和数据本地化存储等特性。
區块链技术的开源项目有很多,目前使用最广泛的是超级账本(Hyperledger)项目[2]。该项目成立于2015年12月,由开源世界的旗舰组织Linux基金会牵头成立。项目为透明、公开、去中心化的企业级分布式账本技术提供开源参考实现,并推动区块链和分布式账本相关协议、规范和标准的发展[3]。其中子项目Fabric最早由IBM和DAH发起,目标是作为区块链的基础核心平台,定位是面向企业的分布式账本平台,创新地引入了权限管理支持,是首个面向联盟链场景的开源项目[4]。
Fabric是一个开源的企业级许可分布式账本技术平台,相比于传统的公有链,有着更好的性能[5],其最重要的特点就是可插拔性。没有任何一个区块链平台能够满足所有需求,但是Fabric 可以通过配置来尽可能的满足多样化需求。
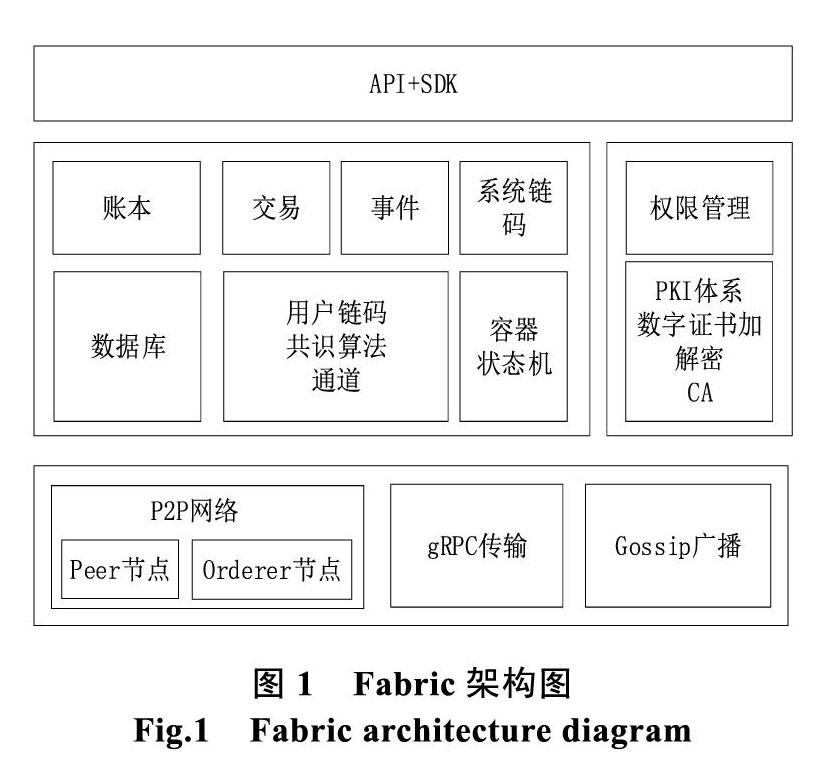
底层由peer节点和orderer节点组成了P2P网络,通过Google开源的RPC框架-gRPC进行交互,客户端把用户输入的数据构建成交易提案,发送给背书节点(背书策略指定的peer节点),背书节点模拟执行交易后,将结果集返回给客户端,客户端根据结果集构建交易,发送给orderer节点,在orderer节点中,对于收到的交易,进行排序,打包生成块后,返回给peer节点,peer节点验证后,写入本地帐本,并利用Gossip广播协议同步数据。
中间使用通道技术(channel)进行隔离,每个通道都是一个独立的网络,拥有自己的账本(ledger)。账本的底层是数据库,fabric中采用goleveldb,对账本的操作,追根溯源,还是对数据库的操作。账本记载了一系列交易,完成交易依赖于共识算法,交易会触发事件。交易是由SDK发起的,其底层是应用链码(Application chaincode,简称ACC),除了ACC外,还有系统连码(System chaincode,简称SCC),主要用来管理ACC,不管是ACC还是SCC,都是链码(chaincode),都依赖于容器技术和状态机(finite state machine,有限状态机,简称FSM)技术。权限管理是独立出来的,使用了PKI体系,由CA(Certificate Authority,即颁发数字证书的机构)节点负责颁发证书,底层是fabric封装好的MSP(Membership Service Provider)服务。
Fabric向上层应用提供了gRPC API以及把API进行封装的SDK, 应用可以通过SDK访问账本、处理交易、管理链码、注册事件、管理权限等多种资源。SDK的实现有多种,目前支持最完整的版本是Java和nodejs。整个框架的核心就是账本,负责记录框架上所有应用的信息,而应用通过SDK发起交易来向账本记录数据,交易执行的逻辑通过ACC来承载。
Fabric中的orderer节点负责对交易排序、打包成块,依照共识算法在一个时间间隔内,选择一个节点完成,该节点称之为主节点,当主节点因为异常停掉时,整个网络就会停滞,节点之间会一直询问,阻塞,直到该间隔结束,下一个间隔重新选择主节点。当网络初步启动,节点和交易较少时,Fabric网络处理迅速,选举间隔极短,但是,当节点数目和交易次数很多时,网络处理变得缓慢,选举间隔增加,每一次的阻塞时间都是很大的浪费。orderer节点选举的主节点遭受异常坏掉,造成该间隔内整个系统阻塞的问题,属于容错问题,Fabric系统需要有一个支持主节点容错的机制。
故本文在Fabric的基础上,针对现阶段系统不支持主节点容错的问题,对Fabric系统架构进行演化,提出了一个支持主节点容错的演化算法。
本文研究部分分为四部分:第一部分是引言,第二部分是相关工作;第三部分是算法设计;第四部分是实验分析;第五部分是总结。
1 相关工作
中本聪的奠基性论文[1]中,指出了区块链的典型结构,对关键术语交易、时间戳服务器、工作量证明、网络、激励、回收硬盘空间、简化的支付确认、价值的组合与分割、隐私进行了详细叙述,最后进行计算,验证了区块链网络的可行性。在这个设计中,巧妙地将节点容错能力转化为对于系统中算力的掌握程度,只要掌握的算力不超过系统总算力的50%,就不会系统造成影响。实质上是依赖于共识算法-Pow算法,但是该算法耗费资源极高,节点是否异常需要有6个区块上链才能确定,时间间隔长,不适用于一般系统[6-7]。
袁勇、王飞跃[8]以比特币为例,说明了区块链的基础架构模型,由数据层、网络层、共识层、激励层、合约层和应用层组成:
数据层:封装了底层数据区块以及相关的数据加密和时间戳等技术;
网络层:包括分布式组网机制、数据传播机制和数据验证机制等;
共识层:主要封装网络节点的各类共识算法;
激励层:将经济因素集成到区块链技术体系中来,主要包括经济激励的发行机制和分配机制等;
合约层:主要封装各类脚本、算法和智能合约,是区块链可编程特性的基础;
应用层:封装了区块链的各种应用场景和 案例。
邵奇峰、金澈清等[9]结合了比特币、以太坊、fabric等区块链平台,提出了另外一种相似但更为简洁的区块链架构模型,整体上可划分为网络层、共识层、数据层、智能合约层和应用层五个层次,其中不同之处在于数据层,这种结构中的数据层包括数据结构、数据模型和区块存储,激励层并入共识层中。在论述区块链劣势时,提及了区块链吞吐量、事务和并发处理、查询统计、访问控制以及可扩展性问题,没有提及容错方面。
徐晓冰、戚枭宏等[10]把区块链技术应用到物联网上,部署智能合约为设备管理操作提供接口,把物联网设备独立于区块链网络之外,进而实现网络的可伸缩性。后续之中还改进了PBFT算法,使之更有效率地替换拜占庭节点,实验验证了其有效性,但是容错功能依然是作为共识算法的一部分,没有改进。
甘俊、李强等[11]针对拜占庭容错共识算法的静态网络结构和主节点选取随意,通信开销较大的问题,进行改进,使节点可以动态地加入或退出,并且以最长链为选举原则进行选举,对选举出来的节点增加了可信度和吞吐量,降低了时延,提高了安全性。该算法检测出节点异常后,迅速结束当前周期,开启新一轮选举,降低了节点切换时间,但是没有支持主节点容错功能。
蔡维德、郁莲等[12]详述了北航链,提出了账户区块链模型和交易区块链模型,满足通信量巨大、快速响应、账户信息隐私等需要,并且可扩展性高,但是这个链的重点在于提高建块速度、并行计算、节省算力方面,强调区块链应用系统的开发,没有关注主节点容错。
朱立、俞欢等[13]提出了新的高性能联盟区块链技术,通过业务逻辑与共识分离、存储优化和数字签名验证优化等手段来提高联盟链系统的交易性能,并且验证了有效性。在此架构之中共识算法分离了出来,但是依然没有摆脱容错功能,整个系统还是依赖于共识算法进行处理。
Sara Saberi、Mahtab Kouhizadeh等[14]将区块链技术用于解决一些全球供应链管理的问题。全球的供应链系统和区块链系统在结构上具有相似之处,都是分布式,现在的供应链管理严重依赖一些大型组织,具有集中式的特点。文章中提出把区块链技术应用在供应链管理中,使得供应链不在集中于某几个组织,具有更好的健壮性。文章指出在基础的区块链系统之上,更好的管理还得依靠智能合约,通过对其的严格审查,来确保安全。
关于区块链的研究较少,大部分重点在于区块链结构,把支持主节点容错放在了共识算法中,少部分对共识算法进行了改进。本文提出的支持主节点容错的orderer节点演化算法独立于共识模块,当主节点异常时,在当前周期内直接支持容错,保证系统正常工作。
2 算法研究
2.1 需求分析
在Fabric系统结构中,数据传输过程如图2。
(1)客户端根据用户输入的数据、需要调用的chaincode函数和参数、时间戳和客户端的签名等信息,构建交易提案,依据設定好的背书策略发送给指定的Endorser节点;
(2)Endorser节点收到提案后,首先校验签名,保证合法性,然后进行背书操作,即根据提案中的信息,基于当前账本状态,调用chaincode函数模拟执行交易,生成结果并签名,发送给客户端。注意,此时只是模拟执行,并没有更改当前的账本状态;
(3)客户端收到回复后,验证结果的签名是否属于给定的背书节点,保证合法性。然后,对模拟执行的结果进行校验,若有多个回复信息,检查是否一致。检查通过后,对背书结果进行签名,生成交易(transaction),发送给主orderer节点;
(4)主orderer节点是orderer节点列表依照Raft共识选举出来的,在收到客户端发送的交易后,首先会校验签名,保证合法性,然后对交易按照指定规则排序,并且打包生成块,然后对生成的区块签名,之后发送给peer节点;
(5)peer节点中的Leader角色,负责与orderer节点通信,在收到区块后,会广播给组织内其余的peer节点,也就是Commit节点,在验证通过后,会真正的执行交易,更新本地的数据库。
由上述过程中,可看出,主orderer节点在起到了至关重要的作用,需要对主orderer节点进行容错处理,但是在fabric系统中没有,因此对fabric系统中orderer节点的结构进行演化,确保在主orderer节点产生异常的情况下,系统仍然可以正常工作。
相比于图3,把orderer节点分为两部分,新拿出的一部分作为备份orderer节点列表,时刻进行维护,按顺序选取第一个节点作为备份orderer节点,时刻备份着主orderer节点的数据。当主orderer节
点异常时,备份orderer节点可以立即接管主orderer节点的业务,维护系统的正常运行。
2.2 演化模型
在原来的Fabric结构中,orderer节点与peer节点关系如下(假设此时主orderer节点已经收到客户端发来的交易信息,為了简洁,用户、客户端、背书节点和提交节点略去):
主orderer节点收到客户端发来的交易,对交易进行校验、排序,然后按照一定规则打包成块,发送给leader peer节点。此时的系统架构上,不具备容错能力。
依照前面分析,在图3-2的基础上,添加了备份orderer节点来完成容错。备份orderer节点需要知道主orderer的状态,来及时的进行接管服务。本文参照观察者模式[15],完成消息传递机制。
将主orderer节点作为被观察者,备份orderer节点和leader peer节点作为观察者,主orderer节点通过attach方法和detach方法来注册、删除具体观察者,具体观察者对象存储在主orderer节点的concreteObservers字段中。主orderer节点就可以调用继承的notify方法,在此方法中通过存储的观察者对象来调用它们自身的update方法,继而完成对观察者的通知。同时,主orderer节点需要把区块发送给leader peer节点,也可以通过此机制来完成,使得两者之间的耦合性降低。
备份orderer节点收到主orderer节点异常信息后,会启动接管服务,利用备份好的数据,恢复主orderer节点的服务,去除Observer接口的方法,新添加Subject接口的方法,此时原来的备份orderer节点就变成了新的主orderer节点,在当前的时间间隔内继续工作;原来的主orderer节点会进入检测列表中,检测正常,就会进入备份orderer节点列表;此时备份orderer节点列表中的第一个orderer节点,会自动成为新的备份orderer节点。
2.3 算法设计
在调整后的结构中,相对于被观察者leader peer节点和备份orderer节点来说,其收到的消息是主orderer节点推送过来的,是被动接受的。这一般适用于主orderer节点在工作过程中陷入阻塞状态,阻塞时间大于waitTime(等待时间)时,来通知备份orderer节点和leader peer节点。
算法1:异常感知算法(被动)
输入:backupIP——备份orderer节点的IP地址
输出:异常状态信息
主orderer节点端:
1. backupOrderer=getOrderer(backupIP) // 得到备份orderer节点对象
2. attach(backupOrderer) // 注册观察者,存入观察者列表中
3. IF 进入阻塞状态 && 阻塞时间 > waitTime THEN
4. notify(异常状态信息) // 通知观察者
5. END
备份orderer节点端:
1. exceptionInfo=update() // 主orderer节点端的notify方法,本质上就是调用观察者自身的update方法进行通知
2. print(exceptionInfo)
leader peer节点端:
1. exceptionInfo=update()
2. print(exceptionInfo)
观察者模式是典型的被动感知,有其局限性,当主orderer节点断网时,就无法向观察者备份orderer节点和leader peer节点推送消息,即备份orderer节点无法被动感知。此时就需要备份orderer节点主动感知主orderer节点异常的算法。
算法2:异常感知算法(主动)
输入:主orderer节点的IP地址
输出:主orderer节点异常信息
主orderer端:
1. 读取本地IP,监听本地端口
2. WHILE
3. IF 收到连接请求 THEN
4. 建立连接
5. Send(状态信息)
6. END
备份orderer端和leader peer节点端:
1. 读取主orderer的IP地址
2. WHILE
3. 向主orderer节点发送连接请求
4. IF 连接成功 THEN
5. Receive(状态信息)
6. ELSE
7. print(主orderer节点异常)
8. END
9. sleep(intervalTime)
假设此时主orderer节点产生异常,已经无法正常工作,备份orderer节点已收到异常信息,准备接管其业务。
图7是用一个正常工作的状态,此时主orderer节点产生异常,备份orderer节点通过算法1被动感知或者算法2主动感知,得到其无法正常工作的消息,就会启动自身的数据恢复服务和接管服务,代替主orderer节点工作,同时从备份orderer节点列表中,取出首位的备份orderer节点,进行数据备份服务。
算法3:orderer节点演化算法
输入状态:主orderer节点异常,无法工作
输出状态:备份orderer节点接管主orderer节点业务,正常工作
备份orderer端:
1. data=updateData() // 把数据从本地备份中恢复
2. Tx=receiveTx(data[sender]) // 通过备份的交易发送方,启动接收交易服务,接受新的交易
3. getService(data[Tx]/Tx) // 对备份中的交易和收到的新交易进行排序,打包成块
4. sendBlock(data[receiver]) // 通过备份的区块接收方,启动发送区块服务,把生成的区块发送给指定的接收方
5. 监听本地端口
6. WHILE
7. IF 收到连接请求 THEN
8. 建立連接
9. Receive(新的备份orderer节点已经准备好)
10. attach(新的备份orderer节点) // 注册新的观察者,必须确保新的备份orderer节点已经准备好
11. WHILE
12. sendData(data) // 循环发送数据,以便备份
13. END // 若产生异常,跳出循环
14. END
在备份orderer节点列表中,选择当前第一个节点,成为新的备份orderer节点。
新的备份orderer节点端:
1. 向现在的主orderer节点(原备份orderer节点)发送请求
2. IF 建立连接 THEN
3. Send(备份节点已经就绪)
4. WHILE
5. data=Receice(data) // 循环接收当前主orderer节点发来的数据
6. saveData(data) // 保存
7. END // 若产生异常,跳出循环
8. END
备份节点接管之后,原来的主orderer节点有可能恢复正常,不能直接废弃,此时备份orderer作为主orderer,要测试原来的orderer信息,如果正常,就放入后备orderer列表,等待使用。
算法4:orderer节点管理算法
输入:主orderer的IP地址
输出:备份orderer节点列表
主orderer端:
1. 监听本地端口
2. WHILE
3. IF 收到连接请求 THEN
4. 建立连接
5. Send(状态信息)
6. END
备份orderer端:
1. 读取主orderer的IP地址
2. WHILE
3. 向主orderer发送连接请求
4. IF 建立连接 THEN
5. Receive(状态信息)
6. IF 状态良好 THEN
7. backupOrderers.add(主orderer節点)
8. END
9. END
10. IF 共识节点数量<3 THEN // 共识算法至少得需要3个节点
11. orderer= backupOrderers.remove()
12. normalOrderers.add(orderer)
13. END
14. sleep(intervalTime)
3 实验分析
3.1 实验数据
本实验所用到的数据是英特集团的2018年和2019年的交易数据,股票代码:000411,数据来自于网易财经。
在2018年和2019年中,共有488天进行过股票交易。实验中,建立两个账户,一个是英特集团账户,初始金额为2018/1/2的流通市值,即418226.9万元,另一个账户代表股民,初始金额设定为10000万元,每次进行两笔交易,分别代表资金流入和资金流出,执行488次,代表488天的交易,合计976笔交易。
3.2 实验环境
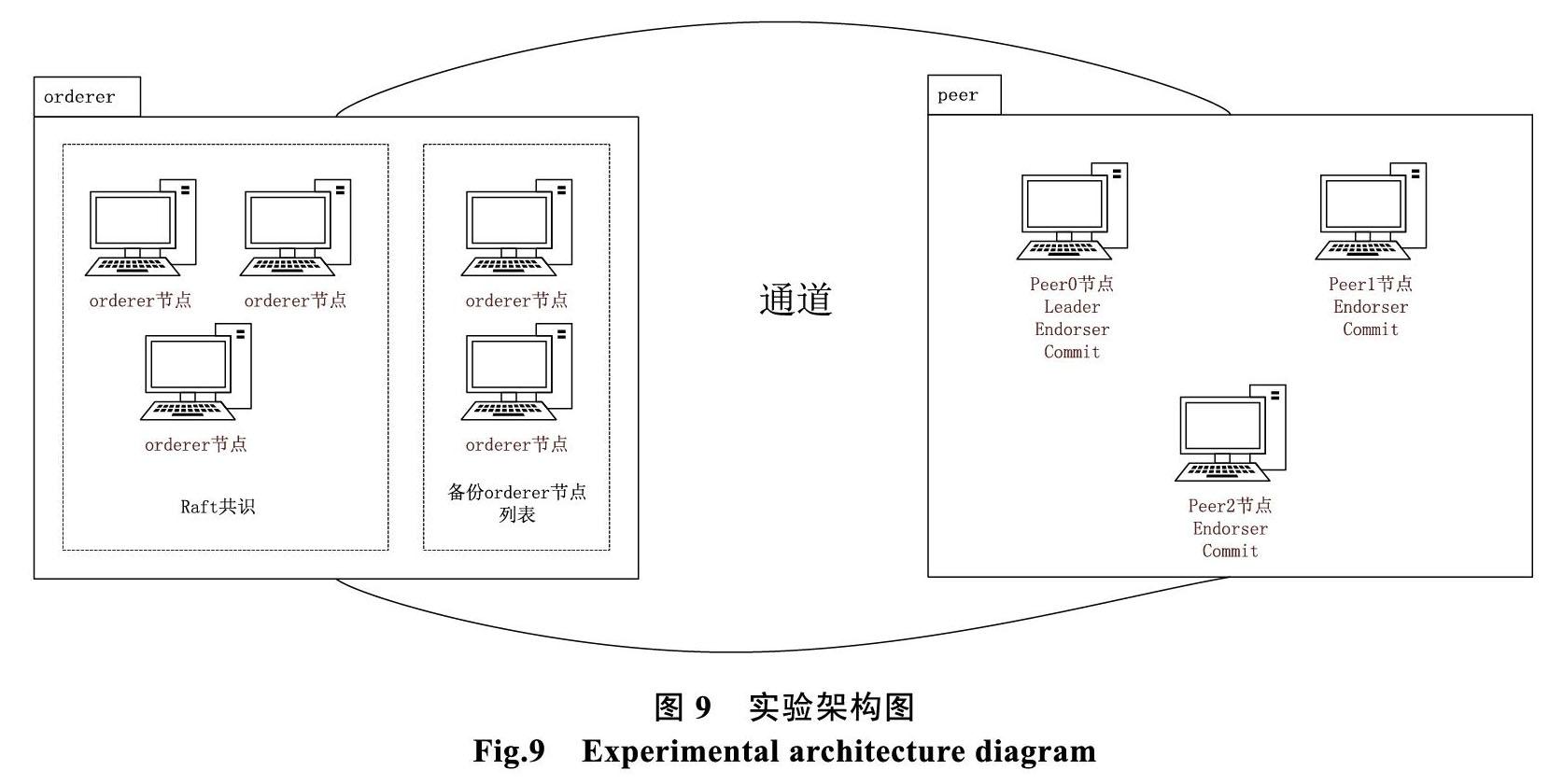
实验基于官方测试样例fabric-samples/first- network,对其进行了修改,由5个orderer节点和3个peer节点构成,5个orderer节点中,其中3个orderer节点要通过Raft共识进行选举,2个orderer节点作为备份orderer节点列表;3个peer节点中,指定peer0担任leader角色,负责与orderer组织通信,3个peer节点都担任Endorser角色和Commit角色,负责背书和写入区块。
3.3 实验分析
仿造主orderer节点陷入阻塞状态,备份orderer节点被动感知异常的情况下,对应用演化算法前 后系统的业务吞吐量、资源利用率和延遲,进行了分析。
3.3.1 业务吞吐量
在吞吐量方面,fabric中对于读和写的处理效率是不同的,读的效率要高于写的效率,因此对读写分开进行测试。
由图10可看出,随着吞吐量的增加,读操作和写操作都出现了失败案例,这是fabric本身的性能瓶颈。读操作的TPS在500左右,写操作的TPS在300左右,在这两个界限之下,可保证交易的有效性。
相比于演化前的吞吐量,演化后的系统在读操作上的TPS提高到520上下,写操作的TPS提高到310上下。整体上,在吞吐量指标上,有了3%-4%的提升。
3.3.2 资源利用率
通过自动化脚本对应用演化算法前后的数据进行采集,主要采集CPU和硬盘的使用数据,其中读写操作的比例是2∶1,CPU采用百分比,硬盘采用万分比,结果如图12。
由图中可看出,在CPU的利用率上,当交易次数较少时,采用演化算法的系统使用的CPU资源要少一些,随着交易次数的增加,无论是否采用演化算法,CPU的利用率都会达到100%,陷入瓶颈;在硬盘的利用率上,采用演化算法的系统比原系统使用的硬盘资源少,而且随着交易数量的增加,会越来越明显。
3.3.3 延迟
在fabric系统中,主orderer节点作用是对收到的交易进行排序、打包,当收到的交易数量大于主orderer节点的处理能力时,多余的交易会进行排队等待,继而会造成延迟。实验测量交易的平均等待时间,结果如图13。
由图中可看出,随着交易次数的增加,平均每个交易的延迟会显著降低,说明了演化算法中,orderer节点替换的时间要小于Raft共识重新选举的时间。
3.4.4 小结
应用演化算法的fabric系统,最主要的突破是降低了延迟。采用备份orderer节点接管主orderer节点的业务,是有效的,其花费的时间开销小于共识算法重新选举的时间开销。
延迟降低后,单位时间内的交易吞吐量就会提高,但是本质上吞吐量取决于fabric系统内部的运算复杂度,交易的等待时间并不是决定性因素,因此系统吞吐量提高的幅度不大。
共识算法的选举过程,需要进行安全校验,即加解密操作,需要CPU运算;而orderer节点演化算法要求备份orderer节点恢复交易数据,对交易排序、打包,需要磁盘读写,因此,当交易次数少的时候,应用演化算法的系统需要的CPU资源就会降低。随着交易次数的增加,限于硬件环境,CPU资源耗尽,进入瓶颈。
对于硬盘资源,延迟的降低,使得等待处理的交易减少,进而降低了这部分交易的存储,同时也减少了日志信息。
4 结论
本文通过对fabric架构中的orderer节点进行演化,把orderer节点分出一部分,作为备份orderer节点,解决了主orderer节点异常问题。实验表明,该算法能有效地降低延迟,进而提高fabric的运行效率。
参考文献
- Satoshi Nakamoto. Bitcoin: a peer-to-peer electronic cash system[OL], available: https://bitcoin.org/bitcoin.pdf, 2008.
- Hyperledger Chinese document[OL]. https://hyperledgercn. github.io/hyperledgerDocs.
- 杨保华, 陈昌. 区块链原理、设计与应用[M]. 北京: 机械工业出版社, 2017. 8.
- 张增骏, 董宁, 朱轩彤, 等. 深度探索区块链: Hyperledger技术与应用[M]. 北京: 机械工业出版社, 2018. 1.
- 朱立, 俞欢, 詹士潇, 等. 高性能联盟区块链技术研究[J]. 软件学报, 2019, 30(6): 1577-1593.
- 叶聪聪, 李国强, 蔡鸿明, 等. 区块链的安全检测模型[J]. 软件学报, 2018, 29(05): 1348-1359.
- Mauro C, Kumar E S, Chhagan L, et al. A Survey on Security and Privacy Issues of Bitcoin[J]. IEEE Communications Surveys & Tutorials, 2018: 1-1.
- 袁勇, 王飞跃. 区块链技术发展现状与展望[J]. 自动化学报, 2016, 42(4): 481?494.
- 邵奇峰, 金澈清, 张召等. 区块链技术:架构及进展[J]. 计算机学报. 2018(5), 5(41): 969-988.
- 徐晓冰, 戚枭宏, 王建平, 等. 基于区块链的物联网可伸缩管理机制[J]. 计算机应用研究. 2019(6).
- 甘俊, 李强, 陈子豪, 等. 区块链实用拜占庭容错共识算法的改进[J]. 计算机应用, 2019, 39(07): 2148-2155.
- 蔡维德, 郁莲, 王荣, 等. 基于区块链的应用系统开发方法研究[J]. 软件学报, 2017, 28(6): 1474-1487.
- 朱立, 俞欢, 詹士潇, 等. 高性能联盟区块链技术研究[J]. 软件学报, 2019, 30(6): 1577-1593.
- Sara Saberi, Mahtab Kouhizadeh, Joseph Sarkis & Lejia Shen. Blockchain technology and its relationships to sustainable supply chain management[J], International Journal of Production Research, 2019.
- Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides. 设计模式: 可复用面向对象软件的基础[M]. 李英军, 马晓星, 蔡敏等译. 北京: 机械工业出版社, 2007. 1.
猜你喜欢
水运管理(2016年11期)2017-01-07
商情(2016年40期)2016-11-28
现代国企研究(2016年10期)2016-11-18
环球时报(2015-12-21)2015-12-21
