
地震科普问答中的语义相似度研究
2020-12-24 03:16张正霞
山西地震 2020年4期
王 宁,张正霞,罗 勇
(1.山西省地震局,山西 太原 030021;2.太原大陆裂谷动力学国家野外科学观测研究站,山西 太原 030025)
0 引言
随着互联网的发展,电子媒介已超越传统媒介,成为当今信息传播的主流方式。地震科普也随之转型,通过微信公众号、微博等多种方式向公众传递科普知识[1-3]。公众通过搜索、自动问答的方式主动获取科普知识,成为学习、了解的重要途径,但根据公众提出的问题,如何在科普问答库中找出相似的问答对,给出理想的答案,是其中的关键。
问答系统的基本技术路线都是文本比较,包括用户问题与库中问题的比较,用户问题与库中答案文本的比较等,在技术实现上主要是句子与句子的比较,实质就是计算句子的相似度。因此,句子相似度计算是自动问答系统的关键技术,直接影响自动问答系统的性能[4]。由于其在自然语言处理领域具有非常广泛的应用,对其相关研究也一直在进行。根据其特点,将句子相似度计算方法分为字面匹配相似度、语义相似度和结构相似度三种类型[5]。字面相似度一般采用最小编辑距离、Jaccard距离等方法;语义相似度包括词频-逆向文档频率(Term Frequency-inverse Document Frequency,TF-IDF)向量方法、余弦相似度等;结构相似度计算的关键在于分析句子的句法结构。
在一般应用中,只计算句子的语义相似度就能够达到要求。该文在地震科普问答库的基础上,分别研究TF-IDF向量方法、余弦相似度、改进的编辑距离等方法在地震科普问答中的应用结果,并根据防震减灾术语制作自定义词典,研究该词典在算法中的有效性。
1 相似句检索的原理及方法
问答系统根据用户输入的问题对问答库进行检索并返回检索结果,其核心技术在于检索与输入问题相似的句子,检索过程分为三步,如图1所示。首先,对输入句进行分词,分词结果的准确性对后续过程有一定的影响;其次,提取相似句子候选集,即从句子库中找出与输入句相似的句子组成集合,可以提高相似句检索的效率;最后,将输入句与候选集中的句子进行相似度计算,选择相似度最大的句子作为最终结果。

图1 相似句检索过程Fig.1 The process of similar sentence retrieval
1.1 相似句子候选集选择
如果一个句子中与输入句相同或者同义的词越多,两个句子相似的可能性就越大,即该句的权重越大。因此,采用倒排文档索引[6]的方法对问题库进行检索,按照句子权重由大到小的顺序选择候选集。
1.2 句子相似度计算
由于只计算句子的语义相似度就能满足研究所需,选取TF-IDF向量方法、余弦相似度、改进的编辑距离等相似度计算方法,研究其在地震科普问答中的应用。
(1) 词频-逆向文档频率(Term Frequency-inverse Document Frequency,TF-IDF)向量方法。
TF-IDF是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。其主要思想是:若某个词或者短语在某个句子中出现的频率高,并且在其他句子中很少出现,则认为该词或者短语可以作为区别该句与其他句子的特征[7]。
TF-IDF = TF * IDF,
(1)
式中:TF表示词条(关键字)在文本中出现的频率;IDF是一个词语普遍重要性的度量。

(2)
式中:nij表示词i在该文本j中出现的次数;分母表示文本j中的总词数。

(3)
式中:分子表示问题库中的句子总数;分母表示包含词语i的句子数,如果该词语不在问题库中,就会导致分母为0,因此一般情况下分母加1。
(2) 余弦相似度算法。
余弦相似度[8]是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异大小的度量。余弦值越接近1,表明夹角越接近0度,表示两个向量越相似。计算过程如下:
句子A:断层是什么意思?
句子B:什么是断层?
第一步:分词。
句子A: 断层 是 什么 意思?
句子B: 什么 是 断层?
第二步:列出所有词。
断层 是 什么 意思
第三步:计算词频。
句子A: 断层1,是1,什么1,意思1。
句子B: 断层1,是1,什么1,意思0。
第四步:得出词频向量。
句子A:[1,1,1,1]
句子B:[1,1,1,0]
第五步:计算两个句子的向量余弦值。
(4)
根据式(4)得到句子A与句子B的向量余弦值为0.85。
(3) 基于编辑距离的算法。
编辑距离是量化不同的字符串如何通过最小数目的操作进行转换[9],编辑操作有“插入”“删除”“替换”三种。例如:
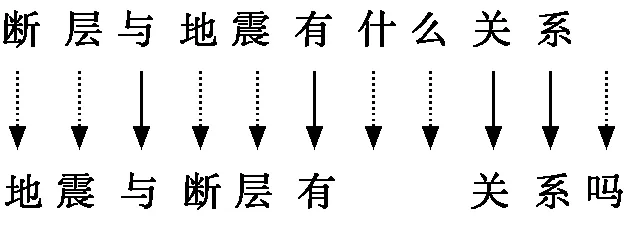
按照传统的以字为单位计算编辑距离的方法,可以看出这例句中两个句子的编辑距离为7。但是,在汉字中,单个的字往往是不具备意义的,词语之间的替换代价不仅局限于字面上,如“喜欢”和“爱”在字面上替换代价大,但在语义层面替换代价很小。因此,车万翔等人[10]提出了改进的编辑距离算法,以词语代替字作为单位来计算编辑距离。
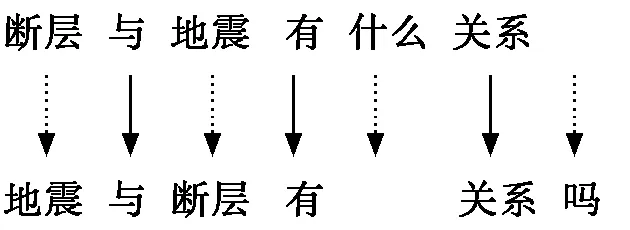
按照改进的编辑距离算法,计算出这两句话的编辑距离为4。因此,该文选用改进的编辑距离算法进行实验。
以上三种方法中,若候选集中多条句子的权重或者编辑距离相同,则选择句子长度与输入句最相近的句子作为最终结果。
2 实验结果与分析
2.1 实验语料与评价标准
赵臻等人[11]曾采用初始数据集结合百度知识库的方法构建问题库,笔者借鉴此方法,选用《地震与防震减灾知识200问答》[12]中的问题与百度知道地震专题中的问题作为初始数据集T。依次选取T中的问句作为百度知道的查询条件,选择查询结果中的前5个标题,筛除相同结果或者无查询结果的句子,最终共采集340条句子作为数据集TS。对TS中的问句与数据集T中的问句依次进行相似度计算。
为了客观评价算法的整体性能,采用准确率(precision)、召回率(recall)、F值来对算法进行评价。其中,F值是综合评价指标,为准确率和召回率的调和平均值。当F值较高时,表明实验方法比较有效。


2.2 实验结果对比
在实验语料的基础上,对TF-IDF算法、余弦相似度算法、改进的编辑距离算法进行对比实验,结果如表1所示。

表1 3种相似度算法的性能比较Table 1 Performance comparison of three similarity algorithms
表1的实验结果表明,在地震科普问答的语义相似度检索中,TF-IDF算法比其他两种算法取得的效果好,准确率、召回率和F值均高于其他两种算法。
2.3 自定义词典对算法的影响
句子相似度算法都是以词为基础进行计算,分词结果准确与否直接影响相似度计算的结果。在地震科普问答中,涉及大量的专有名词,若分词工具的词库中无该专有名词,就会导致在分词时被分开,改变原来的词义。如:
“地震动的衰减关系有哪些?”—>“地 震动 的 衰减 关系 有 哪些 ?”
若分词工具的词库中包含专有名词A,不包含专有名词B,且A和B之间存在包含关系,也可能会导致分词结果不恰当。如:
“震中距指什么”—>“震中 距指 什么”
鉴于以上情况,在分词工具中加入自定义词典,保证较高的准确率。该研究收录中华人民共和国国家标准《防震减灾术语第一部分:基本术语》和《防震减灾术语第二部分:专业术语》及一部分特殊词语,构成防震减灾术语词典,共490个词。将该词典运用到分词工具中,分词结果如下所示:
“地震动的衰减关系有哪些?”—>“地震动 的 衰减 关系 有 哪些 ?”
“震中距指什么”—>“震中距 指 什么”
在加入自定义词典的分词基础上,运用TF-IDF算法在相同的语料中进行相似度计算,研究自定义词典对算法的影响,结果如表2所示。

表2 自定义词典加入前后TF-IDF算法的性能比较Table 2 Performance comparison of TF-IDF algorithms to add custom dictionaries or not
由表2看出,加入防震减灾术语词典后,准确率提高了1.18%,说明自定义词典对算法有一定的影响。
2.4 实验结果分析
上述研究结果表明,在地震科普问答中,TF-IDF算法的F值比余弦相似度算法高2.41%,比编辑距离算法高19.61%,在分词工具中加入防震减灾术语词典,TF-IDF算法的F值提高了1.21%。
对匹配不正确的句子进行分析可知,有部分句子的候选集中已获取正确结果,但是最终结果未取到,是由于该研究选取了候选集中权重最大且句长与输入句最接近的句子作为最终结果,因此会导致选择错误。另外,由于候选集选择时依赖词的精确匹配,可能也会导致正确结果的流失,出现匹配错误。
3 结语
研究时选取三种句子相似度计算的方法,对比其在地震科普问答语料中的性能,选取具有最优性能的算法,加入防震减灾术语词典,研究其对算法性能的影响。实验结果表明,TF-IDF算法在地震科普问答中获得较好的结果,加入防震减灾术语词典可以有效提升算法的性能。
越是相似的句子,就拥有越多相同的词,因此,为了提高算法的性能,今后可以在候选词选择模块和相似度计算模块中加入同义词词林,以Wordnet或者Hownet作为语义资源,计算句子的语义相似度,以再提高算法的准确率和召回率。
猜你喜欢
幼儿100(2022年23期)2022-06-10
校园英语·月末(2021年13期)2021-03-15
云南化工(2020年11期)2021-01-14
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
娃娃乐园·综合智能(2018年23期)2018-12-26
环球时报(2017-11-21)2017-11-21
中学数学杂志(高中版)(2016年6期)2017-03-01
福建中学数学(2016年7期)2016-12-03
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
