
基于强化学习的多时隙铁路空车实时调配研究
2020-12-24 07:39张小强石红国成嘉琪
交通运输工程与信息学报 2020年4期
谭 雪,张小强,2,石红国,2,成嘉琪
基于强化学习的多时隙铁路空车实时调配研究
谭 雪1,张小强1,2,石红国1,2,成嘉琪3
(1. 西南交通大学,交通运输与物流学院,成都 611756;2. 综合交通运输智能化国家地方联合工程实验室,成都 611756;3. 上海市政工程设计研究总院(集团)有限公司,上海 200000)
铁路空车调配计划是进行运输组织的基础和重要条件,空车供求关系的时空变化特性和运输生产的动态性,使求解多时隙空车实时调配最优策略变得困难。强化学习中的Q-learning时序差分算法能较好地解决不完全信息下的大规模序列决策问题,故本文将决策周期划分为若干个时隙,提出多时隙空车实时调配模型:首先利用空车实际调配的局部马尔科夫特性改进Q-learning算法,进行“单一空车调配策略评估”以量化单一空车在决策周期内所有时空状态下采取不同行动的长期回报;然后提出空车实时优先调配算法,求解决策周期全局最优的调配策略。算例表明模型可以兼顾实时调配长期回报最大、空走距离小、即时需求响应程度高,求解出每时隙下最优且决策周期全局最优的实时调配策略,以使运输部门快速适应变化的货运市场需求、提供科学合理的空车实时调配策略是可行的。
铁路运输;空车实时调配;强化学习;空车;多时隙
0 引 言
空车调配计划是铁路技术计划的重要组成部分,合理确定空车调配数量和调配方向,减少空车走行公里对铁路降本增效至关重要。铁路空车调配受运输生产动态性、路网结构复杂性和空车供需不确定性等复杂因素的影响,属于不完全信息下的时变决策问题,因此优化决策周期内的空车实时调配策略较为困难。
空车调配算法分为静态调配模型和动态调配模型,模型目标一般是决定调配起讫点、空车数量和输送路径。静态调配模型是依据已知的空车供需确定性信息优化当前调配策略[1-4],直观性强且容易实施,但不适合处理实际中空车供求状况随时空动态变化的实时调配过程。动态调配以基于时空网络的实时调配模型为主,指在一个决策周期内,依据当前和未来时隙的空车供求信息来优化调配策略。比如文献[5]同时考虑了决策周期内的固定需求及各时隙新产生的空车需求,分两阶段求解实时调配策略;文献[6]从动态优化的角度构建多时点调配模型。上述两种实时调配模型降低了空车调配时变系统研究复杂性,可为决策周期内每一时隙调整调配策略提供依据。但是由于铁路空车供求关系的时空不匹配性和不确定性,按上述方法求解出的实时调配策略从调配决策周期全局看不一定是最优解。
综上所述,对铁路空车调配决策周期内建立全局最优的实时调配模型研究很少。Q-learning是强化学习[7-11]中应用最为广泛的一种时序差分算法:智能体通过状态观测值、行动和即时回报序列与环境持续交互学习,构建对环境的认知,完成策略评估—策略改进—迭代收敛,进而求解马尔科夫决策过程(Markov Decision Process, MDP)的最优决策序列。空车实时调配本质属于不完全信息下的MDP问题,所以Q-learning算法可以量化单一空车在决策周期内所有时空状态下的调配动作价值函数,并用之优化实时调配策略。因此,本文将铁路空车实时调配转化为多时隙大规模序列决策问题,应用强化学习构建多时隙空车实时调配模型,求解时空动态变化和不完全空车供需信息下,兼顾决策周期全局最优和各时隙最优的多时隙铁路空车实时调配策略,最后通过仿真算例验证模型的有效性。
1 多时隙空车实时调配模型
针对铁路空车需求时空变化特征和实际调配过程的马尔科夫特性,将决策周期拆解为多时隙,提出多时隙空车实时调配模型:(1)以实际空车调配的局部马尔科夫特性,改进Q-learning算法,进行“单一空车调配策略评估”以量化单一空车在决策周期内所有时空状态下采取不同行动(站内停留或站间调配)的长期回报;(2)在每个时隙下的实时调配阶段,将所有空车视为多智能体系统,在综合考虑货主即时需求响应程度高、空车走行距离小、铁路运输企业长期回报最大的基础上,使用优先调配算法求解该时隙下最优且决策周期同样最优的站间空车调配数量和调配方向。
1.1 基于局部MDP的单一空车调配模型

当智能体不能提前获知状态转移概率时,该过程是不完全信息下的MDP(又称局部MDP)。显然,单一空车调配为局部MDP模型,针对空车需求时空变化特征和实际调配过程,合理构建该局部MDP是基于Q-learning的单一空车调配策略评估和求解实时调配策略的基础。




② 当空车执行一次完整调配时,奖励计算方法如式(1)-(3)所示:

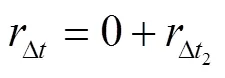
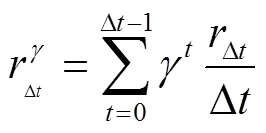
以下提供单一空车调配局部MDP模型构建的算例。
1.2 基于Q-learning的单一空车调配策略评估

表1 局部MDP下单一空车调配Q-learning策略评估伪代码
Fig.1 Pseudocode for pail empty wagon distribution evaluation in local MDP
1.3 空车实时优先调配算法
从强化学习的角度分析,每一辆空车是相互独立的,每一时隙也是相互独立的,分而治之,将决策周期内每一个时隙的所有空车(下称空车)调配拆解为单一空车的实时调配合集,调配系统的目标函数是最大化多时隙初始状态下所有单一空车调配动作价值:

为降低求解复杂度,确保空车调配系统全局最优,对传统运输问题的目标函数加以改进。建立空车实时优先调配算法,为防止对流,假定在每个时隙满足本站空车需求基础上,再确定剩余空车站间优先调配量和调配方向,具体模型如下:




2 模拟计算分析
2.1 算例设计
站间运行时间、重走货运收益以及折扣货运收益见表2,站内等待和空车站间走行不产生货运收益。在每个时隙,6个站点中既有已满足本站装车的可参与站间调配的剩余空车站点,又有空车不足需要其余站调拨的站点。各站点剩余空车数、空车需求数见表3。


表2 站间运行时间(天)/货运(重走)收益(元·辆/天)/折扣货运收益(元/辆)

表3 每个时隙下站点空车剩余数和空车需求数
2.2 实验结果及对比试验
采用空车实时优先调配算法对模型求解,部分时刻的空车调配量、调配方向结果节选见表4。求解结果显示所有时刻的站点空车需求均可满足,站内空车利用总数分别为64/281/257/255/131辆,站间调配剩余空车总数分别为45/106/48/71/62辆,且均在2天内完成站间调配,空车需求响应效率高。
Tab.4 Excerpts from the results of empty wagons and distribution when//




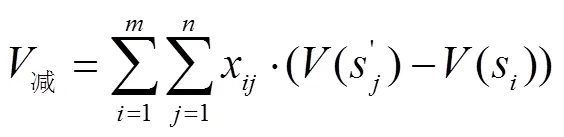
上式中各变量含义同前。
三种模型在所有时隙下的指标结果如表5所示。

表5 指标对比表
由表5可知,在多时隙铁路空车实时调配问题上,所提实时优先调配算法(M)总体比空走距离最小化(M1)和调配结束状态价值最大化(M2)模型性能要优。
结果直接说明了实时优先调配算法中优先函数(式(8))的合理性。即实时调配时,剩余空车优先从状态价值低的起始站点向调配结束站状态价值高且空走距离短的方向调配,以期获得最大调配长期回报、低空走距离和高响应效率。
3 结 论
本文研究了不完全信息下的铁路空车调配问题,建立了基于强化学习的多时隙空车实时调配全局最优模型,首先,将决策周期划分为若干时隙,再通过“基于Q-learning的单一空车调配策略评估”和“空车实时优先调配”两阶段求解每一时隙的实时调配策略,最后通过算例与空走距离最小化和调配结束状态价值最大化模型对比。实验结果表明:所提模型可兼顾实时调配预期回报、调配后状态价值和空走距离求解出每个时隙下最优且决策周期全局最优的调配策略,从而方便铁路运输部门快速适应变化的货运市场需求、进行科学合理的运输组织。后续研究中,可以进一步引入车种代用,分析其对空车调配的影响。
[1] HOLMBERG K, JOBORN M, LUNDGREN J T. Improved empty freight car distribution [J]. Transportation Science, 1998, 32 (2): 163-73.
[2] 程学庆. 铁路空车调配综合优化模型及求解[J]. 中国铁道科学, 2012, 33 (6): 115-119.
[3] 薛锋, 孙宗胜. 铁路空车调整模型的D-W分解算法[J]. 交通运输工程与信息学报, 2019, 17 (4): 43-48.
[4] 朱健梅, 谭云江, 闫海峰. 铁路空车调整优化模型及其蚁群算法[J]. 交通运输工程与信息学报, 2006 (3): 8-15.
[5] 陈胜波, 何世伟, 刘星材, 等. “实货制”下铁路空车动态调配两阶段优化模型与算法研究 [J]. 铁道学报, 2015, 37 (5): 1-8.
[6] 王波, 荣朝和, 黎浩东, 等. 铁路空车调配的多时点优化模型研究 [J]. 交通运输系统工程与信息, 2015, 15 (5): 157-163, 171.
[7] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning [J]. Nature, 2015, 518 (7540): 529-533.
[8] ZHU M, WANG X, WANG Y. Human-like autonomous car-following model with deep reinforcement learning [J]. Transportation Research Part C: Emerging Technologies, 2018, 97: 348-368.
[9] MAO C, SHEN Z. A reinforcement learning framework for the adaptive routing problem in stochastic time- dependent network [J]. Transportation Research C: Emerging Technologies Partc: 2018, 93: 179-197.
[10] XU Z, LI Z, GUAN Q, et al. Large-Scale Order Dispatch in On-Demand Ride-Hailing Platforms: A Learning and Planning Approach [C]// 24th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) . London: Assoc Computing Machinery, 2018: 905-913.
[11] WANG Z, QIN Z, TANG X, et al. Deep Reinforcement Learning with Knowledge Transfer for Online Rides Order Dispatching [C]// 2018 Ieee International Conference on Data Mining. New York: IEEE Press, 2018: 617-626.
Reinforcement-learning-based Multi-slot Rail Empty Wagon Real-time Distribution
TAN Xue1, ZHANG Xiao-qiang1, 2, SHI Hong-guo1, 2, CHENG Jia-qi3
(1. School of Transportation and Logistics, Southwest Jiaotong University, Chengdu 611756, China;2. National United Engineering Laboratory of Integrated and Intelligent Transportation, Chengdu 611756, China;3. Shanghai Municipal Engineering Design Institute Co., Ltd., Shanghai 200000, China)
Rail empty wagon distribution is critical to a transportation enterprise. The spatio-temporal characteristics of the supply and demand of empty wagons and the dynamics of transportation generate difficulties in developing an optimal strategy for multi-slot empty wagon real-time distribution. A Q-reinforcement-learning algorithm can solve large-scale sequence decision problems using incomplete information. In this study, the decision period is divided into multi-slots, and a multi-slot empty wagon distribution model is proposed. First, based on local Markov characteristics of empty wagon distribution, an improved Q-learning algorithm is designed, and a single empty wagon strategy evaluation is performed to evaluate a single wagon’s long-term gains under all spatio-temporal states during the decision period. Second, an empty wagon real-time priority distribution algorithm is proposed to solve the strategy for each slot. A case study of multi-slot empty wagon real-time distribution shows that our proposed model can maximize long-term gains as well as minimize unloaded distances of a real-time distribution. Thus, providing rail transportation enterprises with scientific real-time empty wagon distribution strategies is feasible.
railway transportation; empty wagon real-time distribution; reinforcement learning; empty wagon; multi-slot
1672-4747(2020)04-0053-08
U292.8
A
10.3969/j.issn.1672-4747.2020.04.007
2020-06-07
国家铁路局科技开发项目(KF2019-101-B)
谭 雪(1997—),女,汉族,安徽亳州人,硕士,研究方向:机器学习、数据挖掘,E-mail:779495316@qq.com
张小强(1975—),男,汉族,江西石城人,副教授,博士后,研究方向:铁路运营管理,人工智能与智慧物流,E-mail:xqzhang@swjtu.edu.cn
谭雪,张小强,石红国,等. 基于强化学习的多时隙铁路空车实时调配研究[J]. 交通运输工程与信息学报,2020, 18(4): 53-60
(责任编辑:刘娉婷)
猜你喜欢
铁道运输与经济(2022年8期)2022-08-11
铁道运营技术(2021年4期)2021-11-08
舰船电子对抗(2020年2期)2020-06-23
经济研究导刊(2018年26期)2018-11-14
铁道通信信号(2018年9期)2018-11-10
减速顶与调速技术(2018年2期)2018-11-09
铁道通信信号(2018年3期)2018-04-19
舰船电子对抗(2016年3期)2016-12-13
铁道通信信号(2016年6期)2016-06-01
铁道通信信号(2016年3期)2016-06-01
