
基于双向注意力机制的多文档神经阅读理解
2020-12-16 02:18唐竑轩武恺莉朱朦朦
计算机工程 2020年12期
唐竑轩,武恺莉,朱朦朦,洪 宇
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 概述
多文档机器阅读理解(Multi-document Machine Reading Comprehension,MMRC)的核心任务是在多篇文档中寻找线索,辅助答案的推理并抽取答案的描述语言。目前,面向MMRC构建的国际公开语言学资源包括TriviaQA[1]、DuReader[2]、HotpotQA[3]等。其中HotpotQA问答集作为相关分析与实验的语料,包含112 779条多文档抽取式问答样本。
“多跳”和“桥实体”现象的学习与处理,是优化MMRC模型的重要条件,也是HotpotQA问答集中分布最为广泛的语言现象。如自然问句“卡斯帕·施梅切尔的父亲在1992年获得了IFFHS授予的什么奖项”中,“父亲”是最为关键的桥实体,先寻找“父亲是谁”的解,再探寻“父亲所获奖项名称”的解,即构成了问题多跳求解过程。在HotpotQA问答集中,“卡斯帕·施梅切尔”与其“父亲”的父子关系表述,以及其“父亲”与“奖项”的关系表述,并未置于同一自然语句中,甚至分别出现于不同的相关文档中,所以现有针对单一段落或单一语篇的阅读理解模型,并不能在MMRC场景下得以直接应用。因此,面向MMRC的研究不可避免地需要面向如下挑战:以问句为目标的相关文档判别,其核心任务是从文档集合中获取直接相关于当前问题的文档,如在上例中,预先精确获取相关于“卡斯帕·施梅切尔的父亲”的文档,并屏蔽无关文档,是辅助后续抽取答案的前提;基于“虫洞”的相关文档判别,假设自然问句Q包含两个子问题Qα和Qβ(回答Qα为一跳求解,回答Qβ为二跳求解),Qα和Qβ的答案表述共享同一个桥实体,但两者分别出现于文档α和β,那么以桥实体为“虫洞”,在一跳推理后突破文档α的束缚,阶跃进入文档β进行二跳推理,即为“虫洞”驱动的MMRC策略,从所有相关文档中唯独寻找“虫洞”连通的α和β,则是辅助MMRC的关键步骤;多文档答案求解,对“虫洞”联通的推理依据(如不同相关文档中共享桥实体的两句话)进行综合的语义学习,并在此基础上,利用抽取模型或生成模型输出答案。
现有研究往往采用较为刚性的方式解决上述相关性判别的难题(即问题与文档的相关性求解难题,以及虫洞联通的文档级相关性求解难题)。此外,虽然多种计算语言学方法和自然语言处理技术可借助流水线式(Pipeline)的问题求解框架,逐步递进地解决上述难题,但其在整体上往往缺乏通用性和复用性。如首先利用检索技术解决问题与文档的匹配[4]问题,从而获取相关文档;然后利用命名实体链接(Entity Linking)[5]和指代消解[6]方法探索桥实体,并进而锁定虫洞联通的相关文档;最后利用已有的阅读理解模型在虫洞联通的文字片段上抽取答案。但是,这样一种流水线式的MMRC系统,很可能因为形成虫洞的信息不是桥实体(例如桥属性、桥行为、桥状态、关系桥和上下位桥),使得原有的中间环节(文档级关联计算)不可复用,而更换虫洞必然在各个环节之间引起模型的再次集成与重新协作的问题。
针对上述问题,本文提出一种多文档的联合神经阅读理解(Joint Neural MMRC,JNM)模型。JNM是由一组功能各异的神经网络构成的联合学习模型,包含基于双向门控循环单元[7](Bi-directional Gated Recurrent Unit,BiGRU)的循环神经网络[8](Recurrent Neural Network,RNN)、单向和双向注意力网络[9]以及指针网络[10]。JNM将相关性、虫洞、答案抽取等各个独立的学习环节纳入统一且唯一的深度学习框架,构建一种新的普适性阅读理解网络结构。
1 任务定义、数据及相关工作
1.1 MMRC定义
MMRC的输入是未经加工的纯文本文档集合S,以及一条特定的自然问句Q。MMRC的输出是Q的答案a。从概率的角度分析,在给定Q和S的前提下,能够使得条件概率P(a|Q,S)最大化的字符串即为答案a,其公式表示如下:
a=argmaxP(a|Q,S)
(1)
其中,argmaxP(*|*)是最大似然概率。
值得注意的是,当MMRC被用于抽取式问答的求解过程时,Q并未被预先给定或限定于任何候选答案,其唯一的答案需要从集合S内的某一相关文档中自行抽取。因此,这一相关文档中出现的所有命名实体、词、短语和子句,都可能成为问句q的候选答案。相对地,如果MMRC被用于求解“是非”问题时,每个问句的候选答案已得到预先的限定,即“是”或“非”。此外,在MMRC的实验环境中,用于估计答案的线索并未集中于一篇文档,而是离散在不同文档之中,这也是MMRC多文档求解的特色之一。
图1给出了MMRC在抽取式问答场景下的应用实例。这一实例显示,MMRC针对给定的问题,需要从文档集合S中识别两篇相关文档α和β,并结合α和β中各自蕴含的线索(如下划线标记的斜体文字),进行答案的抽取(如文档β内加粗的斜体文字)。

图1 HotpotQA数据样例
1.2 MMRC数据资源及评测
可用于MMRC研究的英文数据资源包括TriviaQA[1]和HotpotQA[3]。其中,TriviaQA指出,其问题求解需要结合多篇文档中的文字线索,但人工观测显示,大量目标问题可通过单文档实现答案抽取;相比而言,HotpotQA显得较为纯粹,其蕴含的目标问题几乎全部需要依赖多篇文档中的线索进行求解,多跳和桥实体(或桥事件)现象出现于全部问答样本中。本文在HotpotQA上展开实验,并对其进行概述。
HotpotQA是推动阅读理解模型可解释性研究的重要语料之一,其包含的文档来自维基百科,自然问句与答案通过众包进行收集。HotpotQA中的每个问句对应10篇相关文档、1个答案以及人工标记的句子级支持性事实。该语料共含有112 779条有效数据。评价标准除了答案的EM值和F1值之外,还有对支持事实的EM值和F1值以及答案与支持事实的联合得分。
1.3 相关研究与分析
MMRC问题是现有机器阅读理解(MRC)问题的延伸。在探讨MMRC研究之前,本节首先简要回顾MRC的最新研究进展。
随着大规模监督数据的发布和神经阅读理解模型的发展,使得机器阅读理解研究取得了显著的进步。目前,谷歌语言人工智能研究院发布的BERT模型[11],在SQuAD数据集[12]上取得了较高性能,EM值和F1值分别为85.08%和91.83%。其相比于人工答疑结果,呈现出较优的能力(注:这一论断仅参考SQuAD相关评测的已有性能报告,不具备普适性和绝对性)。尽管如此,现有MRC模型的优势在更为复杂的问答场景下,并不能得以有效延续,其在蕴含“多跳”和“桥实体”等语言现象的多文档答案抽取中,欠缺直接予以应用的条件。
以目标问句为参考,度量文档中词项的注意力,是利用指针网络进行答案抽取的主要方法之一[13-15]。然而,图1中的例子说明,问句中作为约束条件的表述“在约瑟夫·班尼特担任中校的那场战斗中”,并未在答案所在的文档β中出现。从而在本质上,注意力计算无法将这一约束中蕴含的语义信息传递到答案的发现过程中,形成了低约束条件下的问题求解。这一不足将在大规模数据和开放域应用场景下引起争议(如“历史上领导德克萨斯军队”的领袖不止一个,为什么答案一定是“萨姆·休斯顿将军”,没有前提约束,答案显然灵活且多变)。
当前现有的单文档MRC模型大多无法完成多跳推理或对长文本进行答案抽取的任务,如基于BERT的MRC模型必须将文本长度限制在512字以内,因此建立一种专门针对长文本或多段落求解的MRC模型显得意义重大。MMRC即是针对这种问题提出的新型阅读理解任务,其核心在于将自然问句蕴含的多方面因素或前提条件引入计算范畴,尤其是要求问答系统不能回避约束因素(或前提)离散于多篇文档的客观事实,形成趋近于真实应用场景下的问答研究课题。比如,图1中的例子显示,“圣哈辛托战役”是连接前提“在约瑟夫·班尼特担任中校的那场战斗中”和正确答案“萨姆·休斯顿将军”的重要桥梁(即“桥事件”),且这一桥梁横跨文档α和β。针对这一情况,阅读理解需在综合考虑α和β中的关联线索,并经过多跳求解才能获得可靠的答案,推理过程如图2所示。

图2 HotpotQA数据样例推理过程
针对MMRC的研究,文献[16]提出一种基于候选挖掘的推理模型。其首先抽取候选答案,然后利用推理机制对候选答案逐个验证,择优输出。文献[17]提出一种管道式方法,先从多文档中筛选出最相关的文档,再使用阅读理解模型从中进行答案抽取。在此基础上,文献[18]提出了基于重排序的相关文档获取方法,借以避免文档选择错误产生的损失,文献[19]提出了一个端到端的模型,对所有文档进行答案抽取,最后比较并选择最终答案,文献[20]提出了一种语义分析的阅读理解模型,先进行答案句检索,再进行答案抽取,文献[21]提出了一种针对中文的多文档多答案阅读理解模型,在真实的多文档中文阅读理解数据集上表现优异。
联合学习模型(JNM)是针对本文目标任务形成的一种综合神经网络架构,并配以一套新型的联合学习方法。本文侧重解释注意力机制的使用,包括:1)如何将双向注意力网络应用于问题-多文档的关联性表示;2)如何将双向注意力网络投入虫洞的识别与表示,并将虫洞两端的文字线索应用于答案抽取过程。本文的贡献总体上包含如下3个方面:
1)提出一种面向多文档阅读理解的联合学习模型,用于克服现有流水线推理模型的低复用性和重用性问题。JNM将各个独立的学习环节(相关性、虫洞和答案抽取)纳入统一且唯一的深度学习框架,降低了建模、训练和开发的操作难度。
2)JNM是由一组简单的神经网络模型构建而成,旨在尝试新的普适性阅读理解网络结构,并未包含复杂度较高或网络层数较深的模型,从而避免了较高的计算复杂度。如其引入的指针网络仅为两层的全连接层。在这一情况下,JNM获得了优于现有前沿MMRC模型的性能,在HotpotQA测试集上产生了约2.0个百分点的精度(Exact Match)优势。
3)JNM可用作基本框架,以支撑更为复杂的神经问答模型开发。其可通过局部模型的优化和一体化训练,获得更高的性能优势。如使用谷歌发布的BERT模型[11]替代现有的表示层或答案抽取环节。
2 MMRC“剥洋葱皮”式求解方法
根据MMRC定义,直观的问题求解方式可以归结为文字片段(或“是非”论断)作为正解的最大似然估计。本节对这一求解过程进行分解,并解释网络设计思路和联合学习的必要性。
MMRC涵盖多文档关联分析、多跳推理和桥实体识别等问题,因此其解决思路不能局限于传统的单文档阅读理解方法。本文受人类解决MMRC问题的启发,提出了一种“剥洋葱皮”式的解题方法,其包括如下关键环节,可类比人类阅读理解的略读、精读和确定答案的3个步骤:
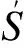
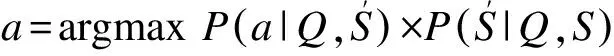
(2)
a=argmaxP(a|Q,Dα,Dβ)×
(3)
3)MMRC依赖的文字线索(如图1中下划线标记的语句)分别出现于相关文档Dα和Dβ,且缺一不可。假设文档Dα和Dβ中蕴含的线索分别为Cα和Cβ,则MMRC的求解过程可进一步细化为给定Cα和Cβ条件下的最大似然估计:
a=argmaxP(a|Q,Cα,Cβ)×P(Cα,Cβ|Q,Dα,Dβ)×
(4)
由于虫洞的识别直接影响相关文档Dα和Dβ的选择和线索Cα和Cβ的判定,从而词项(含实体)作为虫洞的概率计算也应融入总体的答案似然估计。由此,“剥洋葱皮”式的MMRC将形成如下更为繁琐的概率计算过程:
a=argmaxP(a|Q,Cα,Cβ)×P(Cα,Cβ|WH,Q,Dα,Dβ)×
(5)
其中,WH表示作为虫洞(WormHole)的词项或实体。
上述概率计算形成了递进式的MMRC模型,具有较强的逻辑性,但是却欠缺可操作性。其中,线索文档Dα和Dβ、文字线索Cα和Cβ、虫洞WH都是有待识别的未知因素,其概率估计往往依赖多样的前提条件。在这一情况下,较难判定哪一种或多种条件应在概率计算中发挥主导作用。尤其是文字线索Cα和Cβ的文字形式较为灵活,文字块、子句或句子都可以形成文字线索,从而概率计算P(Cα,Cβ|WH,Q,Dα,Dβ)缺少文法确切的候选目标。下一节将通过建立涵盖“剥洋葱皮”各个环节的神经网络,对上述问题予以解决。
3 基于联合学习的多文档阅读理解

图3 模型总体框架
下文概述4个子模块的具体功能:

3)P(Cα,Cβ|Q,Dα,Dβ)求解:旨在挖掘文字线索Cα和Cβ。取出Dα与Dβ在第2步之后的分布式表示结果{GDiQ,GDjQ},与上一步类似,使用文档双向注意力机制获取两篇线索文档间的关系。与文档选择模块的双向注意力不同,答案抽取模块中的文档双向注意力的学习旨在挖掘与答案相关的文字线索Cα和Cβ,而不是找寻虫洞。
4)P(a|Q,Cα,Cβ)求解:旨在预测最终答案a。对Dα与Dβ的高维语义特征表示{RDαQ,RDβQ}分别使用指针网络进行答案抽取,获得候选答案{Ansα,Ansβ}。再通过打分函数进行答案选择,判断最终答案出自文档Dα还是文档Dβ。
3.1 文档选择
文档选择主要包括以下2层:
1)BiGRU层。JNM对问题Q以及N篇文档{D1,D2,…,DN}使用预训练的300维Glove词向量[22]进行词嵌入。同时使用通过卷积神经网络[23]对单词中的字符进行卷积获得单词的字符级词嵌入,以此解决未登录词的问题。此外,引入EM特征[24],该特征是一个二进制特征,将问题与文档中同时出现的词标记为1,未同时出现的词标记为0,并将0和1映射成n维向量,与词向量和字符级向量拼接。按照上述方式得到单词的分布式表示W。接着使用隐层数量为h的BiGRU对具有q个单词的问题Q和具有di个单词的文档Di进行编码,得到问题与文档的分布式表示HQ∈q×h和HDi∈di×h:
HQ=BiGRU(Q)HDi=BiGRU(Di)
(6)
2)注意力矩阵层。在得到了问题和文档的分布式表示HQ和{HD1,HD2,…,HDN}后,JNM分别使用两种形式的注意力机制来进行高维特征表示和信息的交互与融合。JNM首先使用类似文献[14]提出的双向注意力机制,挖掘文档中与问题相关的部分:
(7)
其中,WDi,WQ∈h×1为可训练参数,S∈di×q表示文档词与问题词的注意力得分,A∈di×h表示问题对文档的注意力,max(*)表示对S按列取最大值,rep(*)表示按行复制h次。由此得到结合问题信息的文档表示GDiQ∈di×4h。本文将上述计算文本A与文本B间注意力的方式记作GAB=BiAtt(A,B)。
如第1.3节相关研究与分析中所述,正确答案需要联合两篇文档推理获得,因此JNM构建了一个文档注意力矩阵M用于辅助线索文档的选择,旨在捕获文档间可能存在的联系,找寻虫洞WH。对于N篇文档,该矩阵M是一个N×N的方阵,其中Mij表示第i篇文档对第j篇文档的注意力,如图4所示。
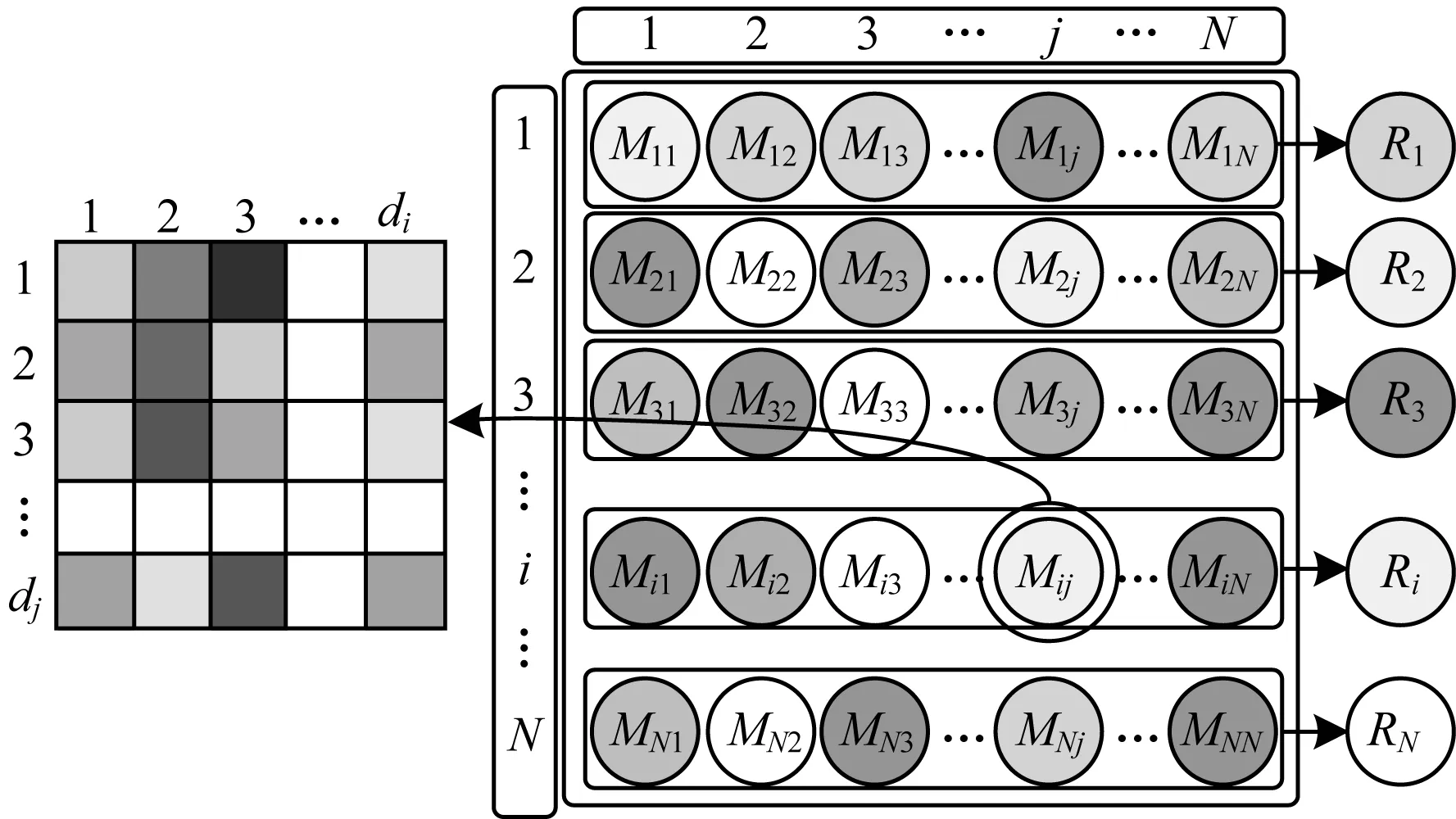
图4 文档注意力矩阵
据此,计算得到Mij和第i篇文档的表示RDi:
(8)
其中,Mij∈di×h,M∈N×N×di×h。JNM通过文档注意力矩阵得到新的文档表示Ri∈di×Nh。对获得的10篇文档的分布式表示{R1,R2,…,RN}通过BiGRU解码,使用全连接层进行二分类,判断其是否为线索文档,具体如下:
yi=W2×max(BiGRU(Ri))+b2
(9)

3.2 答案抽取
答案抽取主要包括以下2层:
1)语篇注意力层。在筛选出线索的文档Dα与Dβ后,为降低参数量级以及简化训练,保留文档选择模块中的问题编码表示HQ,并且从{HD1,HD2,…,HDN}中取出线索文档的编码表示{HDα,HDβ}。与3.1节中的注意力矩阵不同,这里使用更加精细的语篇注意力交互,旨在挖掘文字线索Cα和Cβ。JNM分别计算文档与问题的双向注意力以及两篇文档之间的双向注意力,并且利用残差网络[25]进行信息融合,获得结合问题与另一篇线索文档信息的表示RDα∈dα×h与RDβ∈dβ×h:
(10)

(11)
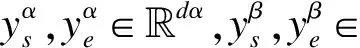

(12)
3.3 联合训练
JNM使用联合训练的方法训练文档选择和答案抽取两个模块。文档选择模块的损失记为Lsele,答案抽取模块的损失记为Lans。其中Lans由抽取损失Lex和答案源推理选择损失Lclf构成,并且在抽取损失Lex前添加一个指示函数I(i),当答案源选择错误时不产生损失。
当模型答案源选择正确时loss=Lex+Lclf,由于答案源选择为二分类任务,在分类正确的情况下二分类交叉熵损失远小于答案抽取的损失,答案抽取可看作两个多分类,分别是文档中每个词作为答案开头的概率和答案结尾的概率。因此,Lclf远小于Lex,即loss≈Lex,当答案源选择错误时loss=Lclf。为了避免做出错误选择时模型损失loss的情况发生,在答案源选择损失Lclf前添加损失调和系数λ,用于平衡答案源选择损失与答案抽取损失,保持Lex与λ×Lclf相近。
(13)
其中,K表示答对总数,N表示一个问答对对应的文档规模,Lex与Lclf均为交叉熵损失。
4 实验结果与分析
4.1 实验配置
预训练词向量为300维的Glove词向量[22],并在训练过程中反向传播更新词向量,使词向量更加适配任务。EM特征维度为100维,学习率设为0.000 6。由于在HotpotQA数据集上进行实验,每个问题均提供10篇候选文档,因此最大文档数为10。模型的编码层BiGRU隐层数与解码层RNN隐层数一致,设为120。模型使用Adam优化器[26],其中除学习率外的参数均为默认值,模型训练的参数如表1所示。由于答案抽取模块对于文档选择模块的强依赖性,在文档选择模块尚未完全训练时,答案抽取模块的训练会变得非常缓慢。这是因为当模型未从正确文档抽取答案时抽取损失Lex为0(在线索文档定位错误的情况下答案源选择不可能正确),答案抽取模块无法进行反向传播更新参数。为解决这一问题,JNM在训练时始终使用正确的两篇线索文档训练答案抽取模块,在预测时使用文档选择模块预测的线索文档进行预测。
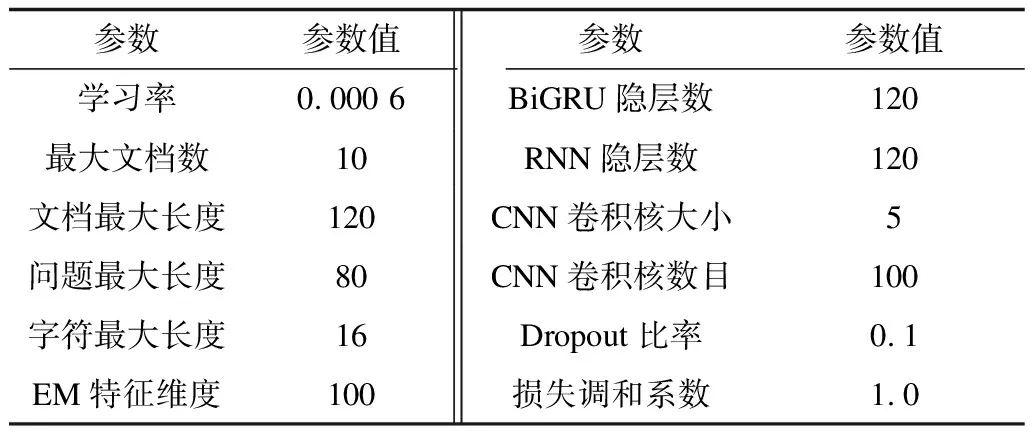
表1 模型参数Table 1 Model parameters
4.2 评价指标
在文档选择部分,JNM将该部分看作一个二分类任务,本文使用两篇线索文档均定位正确的性能accuracy(简称ACC)和F1值对筛选出的线索文档进行评估。在答案抽取部分,本文使用文献[12]在SQuAD任务中的评估方法,即利用EM值和F1值对预测答案进行评估。具体而言,EM值表示预测值与标准答案是否完全匹配,匹配为1,不匹配则为0。F1值则将预测值与真实值分别视为一个词袋,通过预测值与真实值之间的平均重叠单词计算F1值。
4.3 实验结果与错误分析
实验的对比对象为HotpotQA提供的标准基线模型[3],模型架构如图5所示。模型将N篇文档进行拼接构成长度为M的长文本,并采用BiGRU对长文本D和问题Q进行编码,并通过双向注意力机制进行信息融合,得到融合问题的文档表示G,最后使用指针网络作为模型的输出层,输出答案的开始位置start和结束位置end。

图5 基线模型框架
在HotpotQA的测试集上,JNM获得了60.75%的F1值和47.07%的EM值,高于基线模型获得的59.02%的F1值和45.02%的EM值。JNM的文档选择模块能够召回91.24%的答案,使用BERT进行向量表示则可召回92.36%的答案。相比之下,基线模型使用线索文档进行答案预测的F1值为63.58%。由于测试集并未给出问题类型标签,并且官方禁止实验模型的反复提交。因此,本文使用HotpotQA的开发集进行实验分析。
对于文档选择模块,JNM的F1值为88.47%,ACC值为78.99%,具体性能如表2所示。

表2 文档选择模块的性能Table 2 Performance of document selection module %
若进一步使用BERT进行向量表示,性能可以提升至90.43%的F1值和79.66%的EM值。其中比较类问题的文档选择性能明显高于桥类。针对比较类问题,两个比较对象往往对应着两篇线索文档,如图6中的问题“上海和衡阳,哪座城市具有更多的人口?”,比较对象“上海”和“衡阳”各自对应一篇线索文档,从文章的标题即可完成定位,因此定位难度较低。在比较类问题的文档选择方面,无论是JNM还是基线模型均获得了远高于桥类问题的性能。针对图1中给出的桥类问题“在约瑟夫·班尼特担任中校的那场战斗中,谁领导了德克萨斯军队?”,模型需要先定位到第一篇线索文档“约瑟夫·班尼特”,从中找寻虫洞WH,“圣哈辛托战役”,据此定位到另一篇线索文档“圣哈辛托战役”,因此桥类问题的文档选择更具挑战。

图6 比较类问题错误样例
同样,答案抽取模块(模型的总体性能)针对两种问题类型的EM值、F1值如表3所示。

表3 答案抽取模块的总体性能Table 3 Overall performance of answer extraction module %
若进一步使用BERT进行向量表示,JNM性能可以提升至67.91%的F1值和53.27%的EM值。其中基线模型性能为使用官方提供的经过多次实验所得到的最高性能源代码。发现无论是JNM还是基线模型,针对桥实体类问题都有着较高的答案定位能力(预测值与真实值有交集)和较差的边界定位能力。但比较类问题则相反,模型的答案定位能力较差,边界定位能力较强。如对图1中给出的问题“在约瑟夫·班尼特担任中校的那场战斗中,谁领导了德克萨斯军队?”,模型的预测答案为“萨姆·休斯顿”,与真实答案“萨姆·休斯顿将军”不完全匹配,但从语义角度两个答案均正确,属于答案定位准确但答案边界不准确的情况。而对图6中给出的比较类问题,分析问题即可将答案锁定在“上海”和“衡阳”之间,若答案源定位正确,答案边界几乎不可能有误。因此,比较类问题的最大挑战是答案源的定位。如图6中的错误样例,模型需要获取知识“上海人口超过2 400万”和“居住着1 075 516名居民”,假设模型已经通过文档双向注意力层挖掘到文字线索“1 075 516名”与“2 400万”,模型任然面临着“1 075 516名”与“2 400万”的值比较问题。不仅如此,还需结合问题中的“更多的人口”这一信息,进行比较结果与问题方向的异或判断。这对现有的神经阅读理解模型具有极大挑战。
不过JNM仅是一套MMRC框架,可将内部功能模块替换成任意神经网络模型,如将BERT替代现有表示层后,JNM文档抽取的F1值上升了2个百分点,答案抽取性能上升了5.9个百分点。融合BERT表示的模型性能如表4所示。
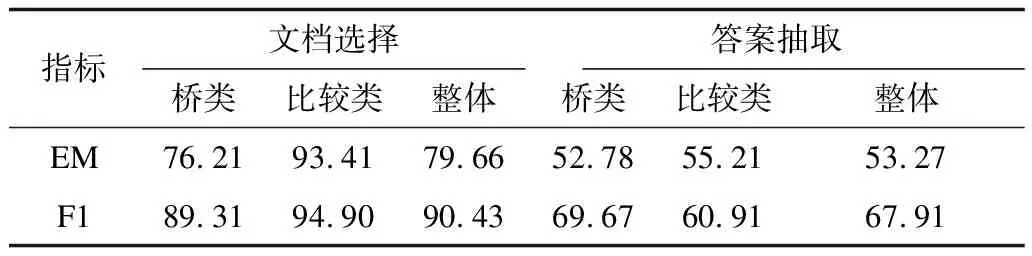
表4 融合BERT表示的JNM各模块性能Table 4 Performance of each JNM module expressed by BERT %
4.4 消减实验
为更细致地分析JNM模型,本文在HotpotQA的开发集上进行了消减实验,分别移除文档选择模块的文档注意力矩阵和答案抽取模块的文档双向注意力,并分析其对文档选择性能、答案抽取性能和联合性能的影响。
消减实验结果如表5所示,首先去掉EM特征,无论是文档选择模块还是答案抽取模块,性能都略有损失,证明EM特征对两个模块均有帮助。但损失值并不明显,尤其是文档选择部分,ACC和F1值损失均在1%之内,表示EM特征并没有在本文的模型中起决定性作用。去掉文档选择模块的文档注意力矩阵,模型在文档选择部分的性能损失的F1值为10.06%,答案抽取性能下降2.79%,证明文档注意力矩阵对JNM性能起到决定性作用,尤其是对文档选择模块。去掉答案抽取模块的文档双向注意力,不仅导致答案抽取部分的F1值下降2.38%,同时导致文档选择部分的F1值下降2.30%。实验结果表明,无论消减文档选择模块中的子模块还是消减答案抽取模块的子模块,均会对两个模块以及总体性能产生影响,证明本文提出的联合学习方法有助于在解决答案抽取问题的同时解决文档选择问题,并且文档选择对答案抽取(总体性能)有辅助作用。

表5 消减实验结果Table 5 Ablation experimental results %
5 结束语
本文针对多文档推理问题提出一种“剥洋葱皮”式的解决方案,并通过面向多文档的联合学习模型JNM对该方案进行实现,同时针对虫洞现象,利用文档注意力矩阵来辅助线索文档的挖掘,并运用文档双向注意力使答案抽取和答案源选择更加准确。实验结果表明,与基线模型相比,该模型的EM值和F1值在HotpotQA测试集中获得了2.1%和1.7%的提升。理想的阅读理解模型不仅需要提供问题的预测答案,还应给出推理答案所使用的支持事实,使模型具有更好的可解释性,下一步将对此进行研究。
猜你喜欢
客联(2022年3期)2022-05-31
小雪花·成长指南(2022年1期)2022-04-09
中国新闻周刊(2021年26期)2021-07-27
家庭影院技术(2019年8期)2019-08-27
传媒评论(2017年3期)2017-06-13
信息安全研究(2016年4期)2016-12-01
第二课堂(课外活动版)(2016年2期)2016-10-21
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
