
基于神威太湖之光的AMBER软件移植与优化
2020-12-16 02:18陈俊仕
计算机工程 2020年12期
彭 龙,陈俊仕,安 虹
(中国科学技术大学 计算机科学与技术学院,合肥 230031)
0 概述
我国自主研发的神威太湖之光超级计算机[1]共配置40 960个SW26010异构众核处理器[2],内部包括1 040万个计算核心,整机性能位居世界前列。SW26010异构众核处理器由我国自主设计,采用主从硬件架构,共有4个核组,每个核组包含1个控制核心和64个从核组成的加速阵列,峰值性能高达每秒12.5亿亿次。由于神威太湖之光超级计算机特殊的硬件架构和编译环境,现有商用平台上的软件需要经过重新实现与优化才能充分利用其计算资源。AMBER[3-4]是主流分子动力学(Molecular Dynamics,MD)模拟软件之一,能够有效描述蛋白质、核酸以及药物小分子之间的相互作用,软件自带势能模型,具有一系列与分子动力学模拟软件相关的工具链。由于每个分子的相互作用都由分子力场描述,而AMBER包含60多个程序,根据模拟需要协调使用,因此其从AMBER11开始支持GPU平台,并利用GPU加速卡加速软件非键力的计算,同时支持Intel的MIC平台。目前,AMBER在神威太湖之光超级计算机上的研究工作还处于空白状态,并且国内对AMBER模拟软件的并行化研究较少。中国科学院上海药物研究所在开展老药新制的过程中,使用AMBER软件进行药物分子的动力学模拟,为能更快地完成药物分子的模拟计算,缩短新药研制周期,对AMBER软件性能的优化成为亟待解决的问题。
本文基于神威太湖之光国产超级计算机,开展AMBER分子动力学模拟软件的移植与优化研究。通过调整AMBER软件中热点函数的数据结构,建立主从加速模型,并利用SW26010处理器从核阵列加速热点函数计算。同时,结合SW26010众核处理器的硬件特性,提出主从异步流水方案,使主核与从核协同计算,解决从核阵列访存带宽受限和从核访存速度过慢的问题,以提升AMBER软件性能。
1 相关工作
1.1 分子动力学模拟
分子动力学模拟[5-6]通过计算分子体系结构中原子的受力情况,利用经典牛顿力学或量子力学更新原子位置,从而得到原子运行轨迹的模拟过程。通过指定模拟步数不断进行迭代计算,而单位迭代的时间步长通常在飞秒尺度上。一般科学研究或者实验需要在微秒甚至更长的时间跨度上进行分析,因此需要上千万甚至上亿次的迭代计算,而且在每一次迭代过程中需要计算系统中每个原子的受力情况,计算量非常庞大[7-9]。在整个流程中需要先进行系统原子数据初始化,然后根据各原子位置等信息计算系统势能,从而求出每个原子的受力情况,再由牛顿力学求出加速度进行速度和坐标更新,最后进行下一次迭代计算。AMBER力场势能计算如式(1)所示:
(1)
在式(1)中:等式右边的前3项表示通过键力项求键力势能,分别为键的伸缩项、键角的弯曲项和二面角项,其中,Kr、req、Kθ、θeq、Vn和γ为力场相关参数,r、θ和φ为键长、键角和二面角;等式右边的后2项表示范德华作用项和库伦作用项,代表非键力项,其中,Rij为原子对之间的距离,qi和qj为原子i、j携带的电荷量,ε为介电常数。此处范德华作用项采用Lennard-Jones势(简称为L-J势),又称12-6势能[10],当Rij非常大时,该势能趋近于0,因此在求得各原子i在该位置上的势能Utotal后,通过对该势能求梯度i得到原子i的受力情况,如式(2)所示:
Fi=-iUtotal
(2)
由牛顿第二定律得到原子i的加速度,如式(3)所示:
(3)
根据加速度al及原子初始位置和速度,在经过单位时间步长t下求出原子速度和位置(如式(4)和式(5)所示),更新速度和坐标后可以进行下一次的迭代计算。
(4)
(5)
经过不断循环迭代计算,直到满足迭代终止条件时为止。在不断迭代计算的过程中,能得到每个单位时间步长下所有原子运动的势能、位置和速度等信息。
1.2 神威太湖之光与SW26010处理器
神威太湖之光计算机系统是一台10亿亿次量级的超大规模并行处理计算机系统。神威太湖之光的整体系统结构如图1所示,其中整机包含40×4个超级节点,每个超级节点包含64个插件板,每个插件板包含4个计算节点,超级节点内部采用全连接的模式,可实现高效的消息广播。每个计算节点内集成1个SW26010处理器,每个SW26010处理器包含256个核,因此共有40 960个SW26010处理器。SW26010处理器由我国自主研发,采用片上计算阵列从核和分布式共享存储相结合的异构众核系统结构。
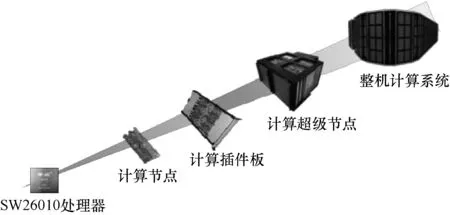
图1 神威太湖之光系统结构
如图2所示,1个处理器由4个核组组成,每个核组包含1个主核和64个从核,核组间支持缓存(Cache)一致性。主核和从核的工作频率为1.5 GHz,其中主核拥有32 KB的一级指令和数据Cache以及512 KB的二级Cache,从核拥有16 KB的指令Cache和64 KB的可重构局部数据存储。SW26010集成了4路128位DDR3存储控制器、8通道PCIe3.0和千兆以太网接口。
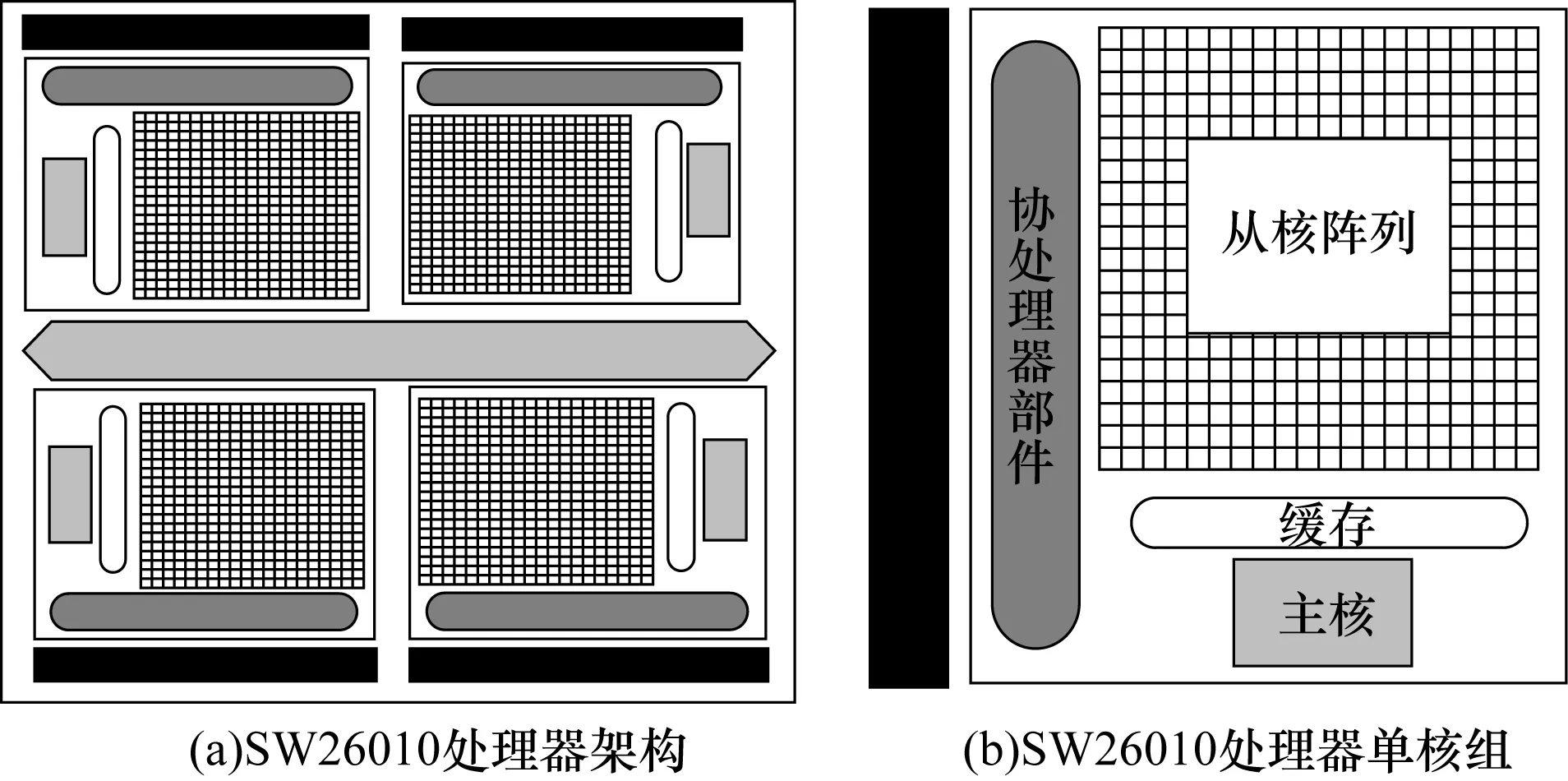
图2 SW26010众核处理器架构
1.3 AMBER软件
AMBER是由加利福尼亚大学的KOLLMAN教授专门针对生物分子系统模拟而开发的分子动力学应用软件。从1975年到现在,最新版本为AMBER2019。AMBER软件由60多个程序组成,这些程序可以分类成模拟前的处理程序、模拟程序和模拟后的处理分析程序。此外,AMBER还包含多种分子的势能力场,用来描述大分子或者小分子之间的相互作用。
AMBER软件从AMBER2011开始支持GPU加速[11-13],由LEGRAND等人[14-16]共同开发和维护,从AMBER2014开始支持Intel Xeno Phi架构[17-19],由BHUIYAN等人基于MPI和OpenMP双重分解策略进行研发,将计算热点部分放置于Intel协处理器中进行加速,从而提升AMBER软件性能[20-21]。AMBER2018的pmemd版本增强了整体性能,相比基于Pascal架构的AMBER2016性能提升25%~42%。截至2018年10月,AMBER2018已提供对Turing架构(RTX2060、RTX2070、RTX2080和RTX2080TI)的支持。
2 商用平台上的热点分析与测试
在移植与优化AMBER软件前需先对其进行测试与分析,找出sander模拟程序的热点计算部分[22]。本文通过在Intel商用平台上模拟二氢叶酸还原酶(DHFR)得到热点函数执行时间占比如表1所示。

表1 AMBER_sander模拟程序中热点函数计算时间占比Table 1 The proportion of hotspot function calculation time in AMBER_sander simulation program
可以看出,sander模拟程序中模拟计算时间runmd占整体计算时间的92.05%,计算系统原子之间非键力的nonbond热点函数占模拟计算时间runmd的93.11%,计算短程非键力的get_nb_energy热点函数占非键力计算时间的77.06%,该函数调用short_ene函数来计算原子与其邻居原子的短程非键力。因此,本文先将AMBER整个程序集移植到SW26010主核上,然后利用SW26010处理器的主从硬件特性来加速AMBER模拟软件中短程非键力的计算部分,从而提升软件整体性能。
3 AMBER在SW26010主核上的移植
本文移植工作是将AMBER软件及其在编译过程中依赖的第三方库均移植到神威太湖之光超级计算机的主核上。SW26010主核能够独立执行完整的进程,而从核阵列作为加速核心,只能执行由主核进程创建的加速线程。因此,在将热点函数的计算任务加载到从核前,需要先将AMBER移植到主核上,具体的编译步骤为:1)修改configure,重新设置编译器及相关参数,配置相关库;2)设置并运行configure参数,生成环境配置脚本和configure头文件;3)执行Makefile完成编译安装过程。由于SW26010处理器的架构和编译环境与商用CPU有较大的区别,因此在configure时需要对代码及若干参数进行调整。此外,AMBER在编译过程中需要NETCDF、FFTW等第三方库的支持,因此可提前将这些第三方库进行交叉编译移植到神威太湖之光超级计算机的主核上,以供AMBER编译使用。
4 AMBER在SW26010从核上的并行实现
本文利用从核对get_nb_energy热点函数的计算过程进行并行实现,首先应用OpenACC将热点函数从核化,然后采用Athread线程库设计主从加速和主从异步流水方案,最后通过从核访存优化进一步加速AMBER模拟软件热点函数的计算。
4.1 算法数据结构调整
通过对AMBER模拟程序sander热点计算部分的分析可知,计算短程非键力的get_nb_energy热点函数需要并行加速热点部分,其中get_nb_energy热点函数会在循环中调用short_ene函数,然后计算每个系统原子i受到的短程非键力,具体算法如下:
算法1短程非键力计算算法
输入系统原子及其邻居原子的参数信息
输出系统原子短程非键力
1.do cell index = myindexlo to myindexhi
2.计算原子索引ncell_lo and ncell_hi
3.do i = ncell_lo to ncell_hi
4.计算原子i的邻居原子个数ntot;
5.对ntot为原子i的所有邻居原子分配存储中间结果的内存空间;
6.调用shor_ene函数计算原子i对其所有邻居原子的非键力作用;
7.释放为原子i的邻居原子分配的内存空间;
8.更新邻居列表ipairs的偏移指针numpack
9.end do
10.end do
如算法1所示,整个计算过程由两重循环组成。在外层循环中,所有网格单元index通过内层循环遍历每个网格单元中的所有原子i,并对遍历到的每个原子i调用short_ene函数计算其与所有邻居原子的非键力,同时释放已为原子i分配的内存空间且更新邻居列表ipairs的偏移指针numpack。在内层循环中,根据原子i的邻居列表大小为该原子申请临时内存空间存放中间数据,为减少内存消耗,AMBER软件自身维护一个stack模块,用于在计算原子i与其邻居原子的非键力前动态分配内存,在数据更新后释放已分配的内存空间。在申威编译器支持下的Fortran语言中,使用SW26010处理器从核并行时需要将核心计算相关的数据通过Common区进行共享,即主核和从核均可以直接访问和修改共享存储空间的数据。然而,通过该方式实现数据共享需要确保Common区的数组大小固定,而AMBER采用动态内存分配方式,根据原子参数的不同分配不同大小的内存空间,显然该内存空间分配方式并不适用于从核并行化。
另外,在计算原子非键力时,由于某些原子的邻居原子存在重叠,如果使用从核并行计算就会产生写写数据依赖,导致错误的计算结果,因此在并行计算前需要解决动态内存和写写依赖的问题。本文通过调整数据结构的方式来解决这两个问题,首先将stack动态内存分配方式调整为固定内存分配方式,将分配的内存设置为Common区以供从核并行计算访问,然后分配一个全局force_sw数组用来存放并行计算时所有邻居原子的非键力信息,在从核计算结束后,通过主核串行的方式更新到全局force数组中,从而解决相同邻居原子的写写依赖问题。采用固定内存分配方式的主存Common区和Global区数据分配如图3所示。
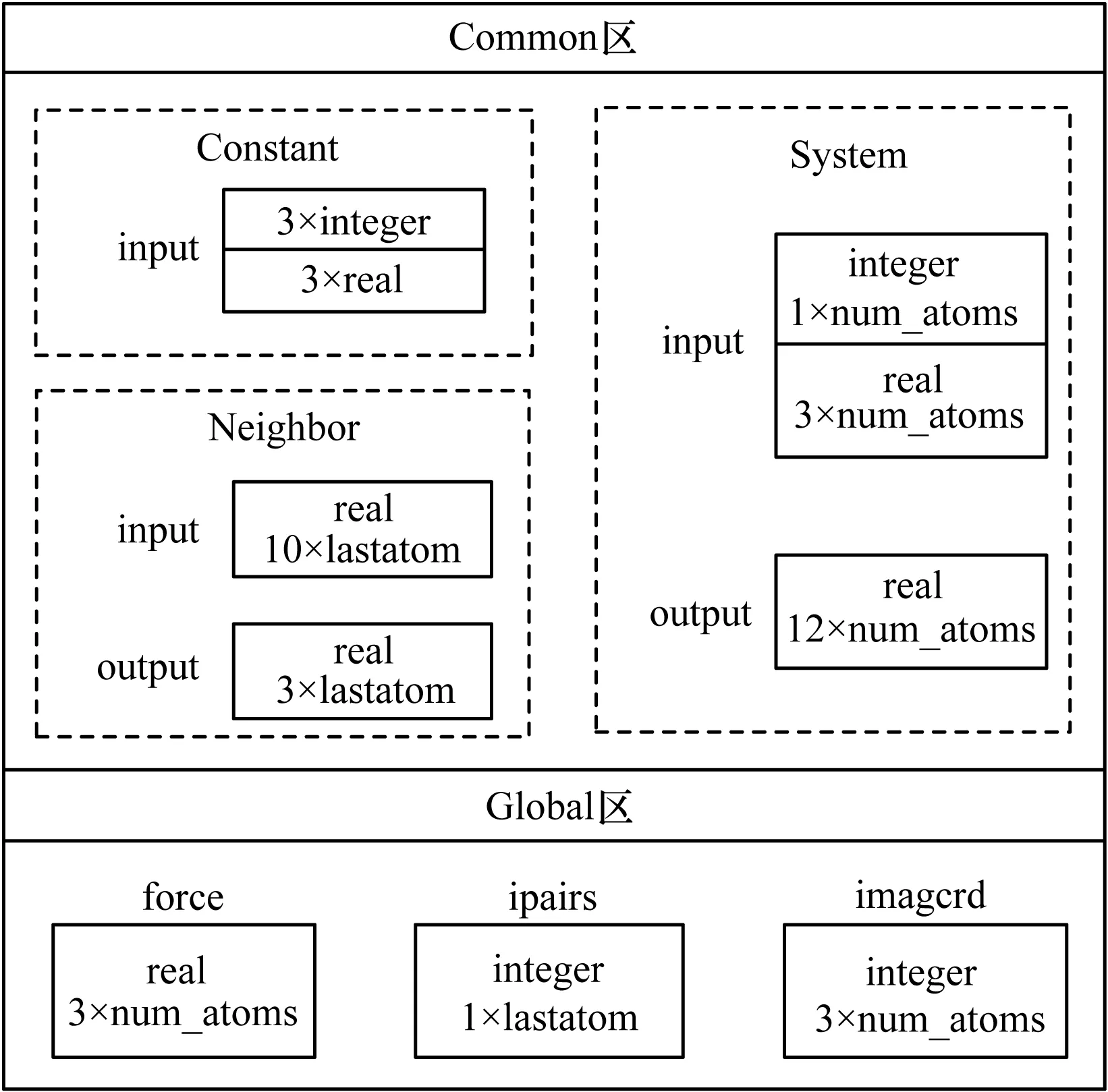
图3 主存数据分配
由图3可以看出,在计算非键力前,首先将AMBER自身维护的动态内存分配方式改为固定内存分配方式,分为存放常量参数的Constant区(包含用于输入的3个整型(integer)数据和3个实型(real)数据)和存放系统原子参数的System区以及存放邻居原子参数的Neighbor区(包含系统总原子个数(num_atoms)和ipairs邻居列表长度(lastatom)的若干integer和real数据,用于相关输入和输出),这些内存空间均被标识为Common,以供从核计算访问。在从核并行计算前,由主核访问主存中的Global区从而对input标记的Common区的部分内存进行数据初始化,Global区中包含存储最后结果的force数组、邻居列表ipairs及其他相关参数信息。在从核并行计算完成后,从核将计算结果更新到output标记的Common区。在调整算法中的数据结构后,将进行热点计算部分的从核并行化。
4.2 OpenACC从核并行实现
在调整热点函数的数据结构后,使用OpenACC实现主核与从核协作计算的执行模型,从而充分利用SW26010的主从硬件资源加速热点函数。基于OpenACC编写程序将数据管理和传输设置为隐式,由编译器根据编译指示信息,自动生成空间管理、数据传输等控制代码,并且通过调整数据结构解决热点函数并行时产生的写写依赖问题后并行计算原子之间的短程非键力,OpenACC实现算法具体如下:
算法2OpenACC并行化短程非键力计算算法
输入Common区数据参数
输出系统原子短程非键力
1.主核进行Common区数据初始化
2.!$ACC parallel loop/local/copyin/copyout/reduction/annotate(参数变量)//从核化
3.do atom i = gstart to gend
4.!$ACC data copyin/copy//加速数据区指示
5.从Common区/LDM中获取原子数据
6.从核并行计算ki与其邻居原子的非键力
7.Update force_sw data
8.!$ACC end data
9.end do
10.!$ACC END parallel loop//从核计算结束
11.Update nonbond force data
将整个系统原子的短程非键力计算循环外加OpenACC指示,当主核运行到该函数时,按照相关指示将整个循环交给从核并行完成,从核完成计算后,按照相关指示将计算结果拷贝或者归约到主存Common区。在从核局部数据缓存(Local Data Memory,LDM)中为循环中的一些变量分配存储空间,主要是从核计算过程中需要用到的存储中间数据的变量,这些变量要足够小且在从核计算过程中被频繁访问,如原子电荷、相对距离等,通过local指示在LDM中分配存储空间。
local中的部分变量需要作为结果在计算完成后拷贝到主存中,这些变量通过copyout指示。copy和copyin指示变量在计算前由主存读入LDM中,在默认情况下根据循环划分方式将对应数据进行分割拷贝到LDM中,主要为原子索引数组、存储结果的非键力数组以及原子坐标数组等全局数组。copy指示的变量在计算结束后需要将LDM中的值拷贝到主存中,而copyin指示的变量在计算结束后并不将值拷贝到主存中。在循环中通过加速数据区指示data定义加速计算的数据区,用来描述变量在LDM内的属性,指示在计算完成后是否需要将值从LDM中更新回主存,其中使用reduction规约子句完成部分变量在各从核计算结束后的加法规约操作,具体代码如下:
reduction(+:vxx_si,eelt,evdw,vzz_si,vyz_si,vyy_si,vxz_si,vxy_si,ee_vir_iso_si)
编译器会在每个线程上为reduction指示的变量创建一个私有副本,并根据加法操作以及变量数据类型对该私有副本进行初始化。在循环结束后,使用加法操作对同一变量的所有私有副本进行一次并行规约的加法操作,并将规约结果写回原始变量中。至此,根据循环中的变量及其计算特点通过添加OpenACC编译指示使得整个循环计算在64个从核中并行执行,完成热点函数在从核上的并行计算。
4.3 Athread主从加速实现
本文通过调用神威定制的Athread加速线程库函数接口编写从核代码,利用主从加速模型加速AMBER软件的热点函数计算。根据SW26010处理器特殊的主从硬件架构,并将从核作为加速核心,用于加速AMBER软件热点函数的计算,通过64个从核的并行计算提升软件整体性能,主从加速模型的计算流程如图4所示。
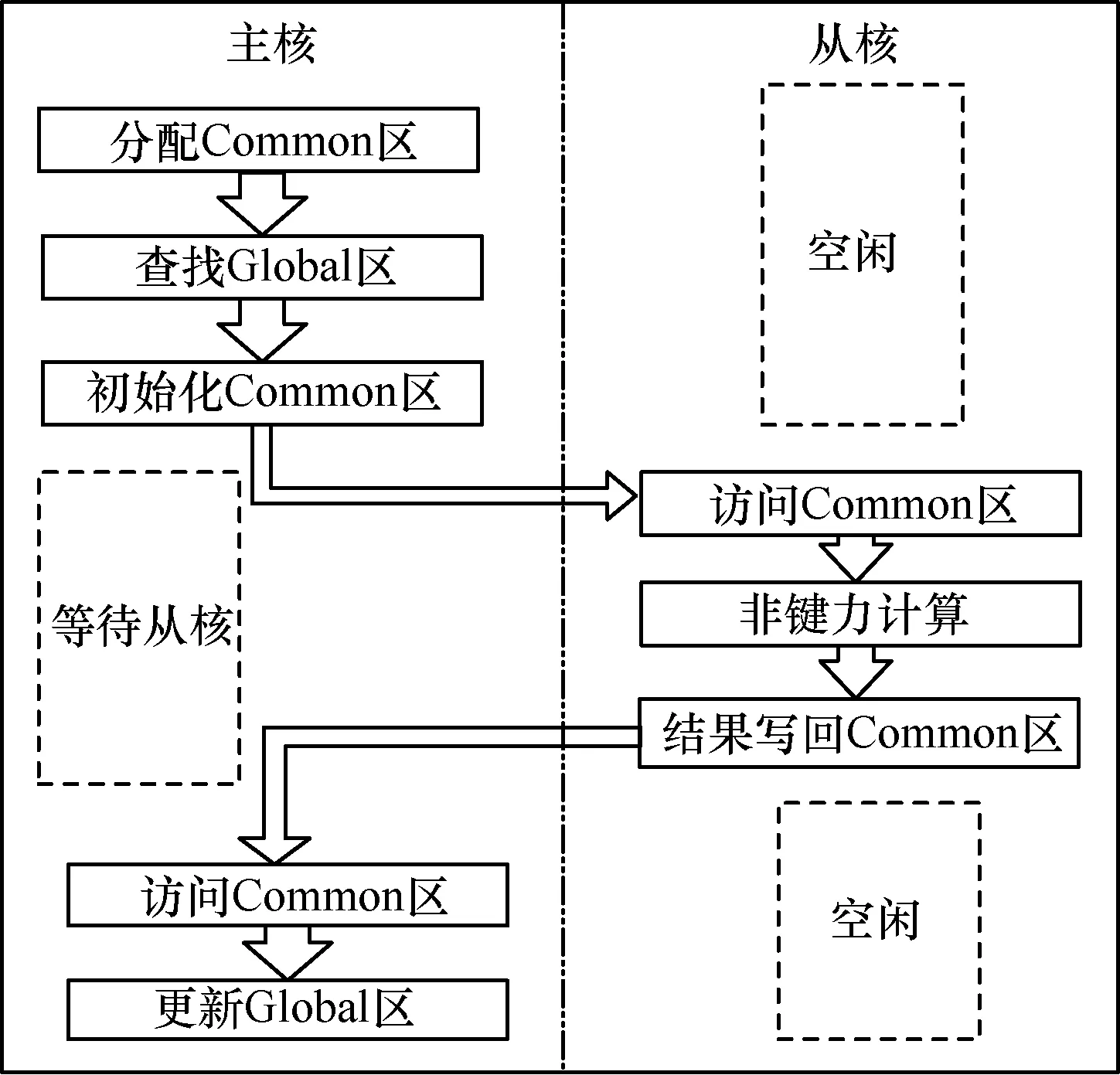
图4 热点函数的主从加速模型
主核在完成Common区内存分配后,循环遍历系统中所有原子,由原子索引号访问Global区获得原子及其邻居原子的参数信息,进而对Common区的部分内存进行数据初始化。Common区常量参数部分包括系统原子的索引号、第一次分配的标志号以及短程力的截断半径等。系统原子参数部分包括该原子的邻居原子个数、电荷量以及在全局邻居列表中的偏移量等。邻居原子参数部分包括原子间的相对距离、evdw参数和用于存储中间计算结果的force数组等。主核在完成Common区数据初始化工作后,会通过Athread接口函数来调用从核代码,64个从核通过访问Common区分配的数据,并行计算原子的短程非键力。
本文将系统原子均匀地分配给64个从核进行计算,保证每个从核的计算量相同,这样在若干计算周期后所有从核能同时完成数据计算。在从核计算过程中主核处于阻塞状态,等待全部从核完成计算后,主核开始进行最终数据的更新,此时从核处于空闲状态,通过访问Common区的output部分更新Global区的force数组。至此,利用Athread完成热点函数计算的从核化。在主从加速并行方案下,从核计算过程中的主核处于阻塞状态,需要等待从核计算完成后才能进行数据更新。另外,主核在从核并行计算前需要循环遍历系统原子进行Common区数据初始化,增加了额外的时间开销。因此,本文将利用主从异步并行方案,最大限度地减少额外的时间开销,实现热点函数的性能加速。
5 并行化AMBER的性能优化
5.1 主从异步流水设计
本文采用主从异步并行方案实现主核和从核并行计算,通过流水化设计隐藏主核Common区数据初始化带来的额外时间开销。该流水化方案是在从核进行并行计算的同时,使主核不等待,而是进行数据初始化。流水化前后的主核算法具体如下:
算法3流水化前的主核算法
功能主从加速方案
1.内存分配allocate(参数)
2.do i = gstart,gend
3.查找Global区
4.Common区数据初始化
5.end do
6.call athread_spawn(sw_fun,1)//调用从核代码
7.call athread_join()//从核计算结束
8.全局数据更新force
算法4流水化后的主核算法
功能主从异步方案
1.内存分配allocate(参数)
2.Call athread_spawn(sw_fun,1)//调用从核代码
3.do i=gstart,gend//主核循环遍历系统原子
4.查找Global区
5.Common区数据初始化
6.标志Flage()更新//设置全局标记
7.end do
8.call athread_join()//从核计算结束
9.全局数据更新force//主核进行全局数据更新
在流水化前的主核算法中,由主核分配Common区并对其进行数据初始化,然后调用从核代码执行从核计算。在流水化后的主核算法中,在主核进行数据初始化前,使用athread_spawn函数接口创建从核线程组开始执行从核代码。与此同时,主核进行主存Common区的数据初始化,接着调用athread_join等待所有从核完成短程非键力的计算,最后由主核进行数据更新。为实现主核数据初始化与从核计算的并行化,本文设置一个Flage全局数组作为标志放在Common区,用来判断为原子i分配的Common区数据是否初始化完成。主核循环遍历系统所有原子,通过原子索引访问主存Global区为原子i的Common区初始化,同时从核检测到原子i-1初始化完成后开始计算短程非键力,具体流程如图5所示。
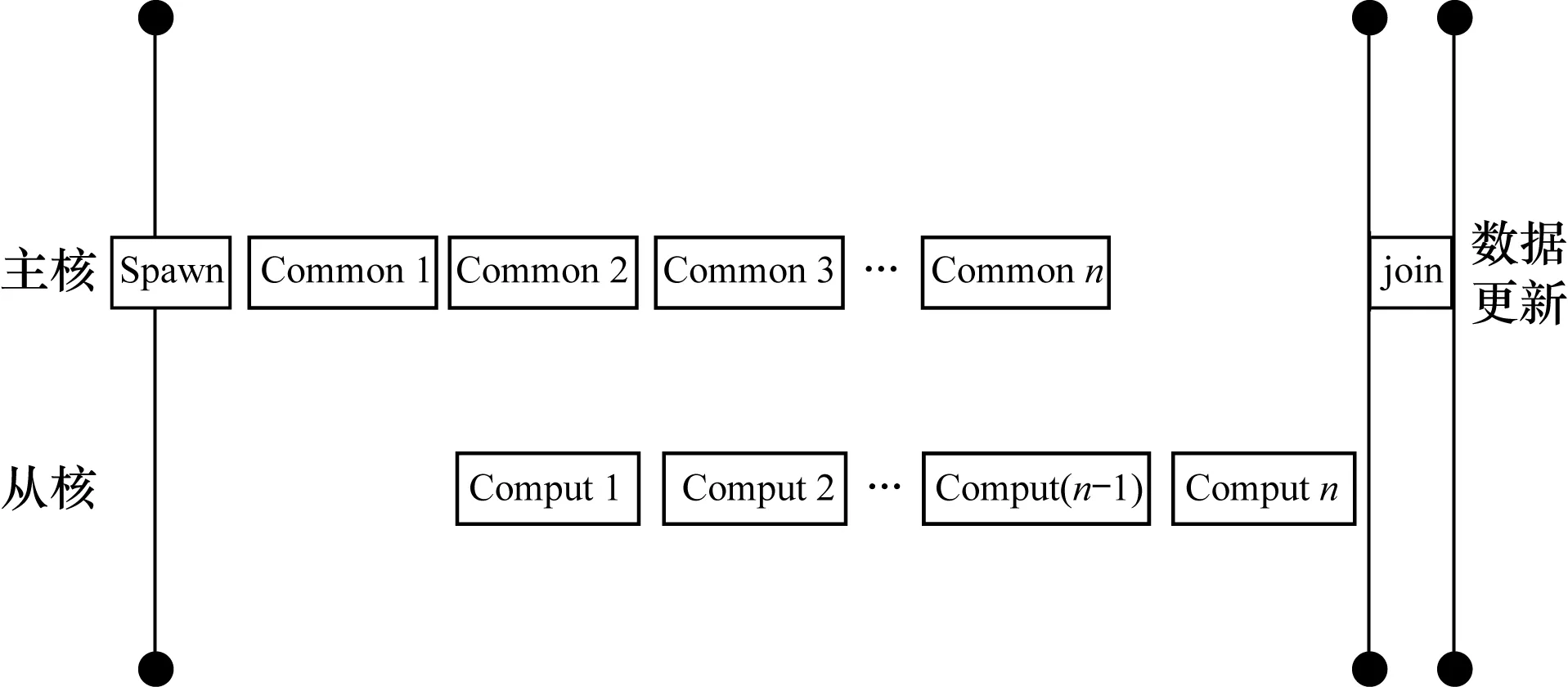
图5 主从流水化并行执行
当主核为原子i的Commoni区初始化完成后,该区标志为真,从核检测到标志为真即可开始计算Computei,而当从核计算Computei时,主核进行Common(i+1)区的数据初始化。因此,主核Common(i+1)区数据初始化可与从核计算Computei并行执行,实现主核数据初始化与从核计算两个模块的流水化操作,从而消除部分等待时间。
5.2 从核访存优化
在进行主从异步流水化设计后,使主核和从核并行工作,从而消除主从加速方案导致的额外时间开销,进一步提升热点函数的性能加速。下文将针对从核访存进行测试与分析,由于AMBER_sander模拟程序在模拟分子时,根据模拟步数不断迭代计算,因此需要不断地从内存中读取和更新数据。在从核并行计算时,64个从核并行访存主存,这样会导致主存带宽压力过大,而且在上述实现中,从核通过Global方式直接访问主存,访存速度很慢,因此本文针对访存带宽和访存速度进行以下优化:
1)针对从核访存速度过慢的问题,本文选择将从核计算中需要用到的部分数据暂存在从核LDM中。首先这些数据要在从核计算过程中被频繁访问,从核访问LDM要比直接访问主存快很多,如果被频繁访问的数据放到从核LDM中,则在从核计算过程中可以直接从LDM中读取数据,无需多次访问主存。其次这些数据要足够小,从核LDM只有64 KB,不足以存储从核计算过程中的所有数据,因此选择数据量较小且在计算过程中被频繁访问的数据存放到从核LDM中,从而加速访存时间,提升程序性能。这些数据主要包括原子电荷(cgi和cgj)和系统原子坐标参数(Xk、Yk和Zk),其中电荷以real类型、坐标以integer类型存储在Common区,在计算短程非键力的过程中被访问的次数与系统原子总个数(atoms)成正比,如表2所示。

表2 存放在从核LDM中的数据Table 2 Data stored in the LDM of slave core
2)针对从核并行访存的带宽竞争问题,采用直接内存存取(Direct Memory Access,DMA)通道的方式实现主存与从核LDM间的数据交换。一方面,由于DMA可以控制主从与从核LDM之间的数据交换,在数据交换的同时从核可以分配一些与所传输数据无关的计算操作,实现从核通信与计算的重叠。另一方面,由于AMBER_sander在求解短程非键力时需依次遍历系统中所有的原子,数据空间局部性大,而在DMA数据传输时是将一块连续数据段从主存读取到LDM中,在数据更新时也是更新一块连续的数据段到主存中,因此通过DMA的异步性和连续性可以加快从核访问主存的速度。
5.3 SIMD优化
神威太湖之光超级计算机支持256 bit向量指令,1次可以加载4个double类型。为进一步提升热点函数的加速性能,本文使用向量指令集对从核计算过程中的部分无依赖且规整的代码进行手动向量化操作。在计算从核的原子非键力作用后,得到原子在x、y和z方向上的作用分量dumx、dumy和dumz,利用这3个部分的作用分量更新临时变量force_sw。这部分计算是一个3×3的双重循环,为对其进行向量化操作加速,需要为dum和force_sw数组添加一个维度,该维度的值没有意义,其不进行主核的全局force数组更新,但参与从核计算。通过添加一个维度将该迭代计算变为4×4的两层for循环,然后使用4个向量取代两层for循环。基于向量化实现,从核的执行效率得到进一步提升,其中参与向量化的部分从核代码的运行速度在理论上能达到4倍的线性加速,对于整个程序的计算性能也有所提升。
6 测试与性能对比
6.1 测试平台与测试算例
本文完成AMBER软件在神威太湖之光平台上的并行实现与性能优化工作。本节将针对神威太湖之光平台上移植与优化后的AMBER软件与Intel商用平台上的AMBER软件做性能测试对比。测试平台的配置信息如表3和表4所示。

表3 神威太湖之光测试平台配置信息Table 3 Configuration information of Sunway TaihuLighttest platform

表4 Intel商用测试平台的配置信息Table 4 Configuration information of Intel commercial test platform
测试算例选择AMBER软件的DHFR测试基准,结构如图6所示,包含23 558个原子,单位迭代时间步长为2 fs,短程非键力截断半径为8 angstrom。

图6 DHFR结构
6.2 测试结果与分析
本文测试了AMBER软件的热点函数在神威太湖之光平台的SW26010处理器上采取不同优化方案后的执行时间,并对比其在Intel Xeon Platinum 8163上的执行时间,具体测试数据如表5所示。
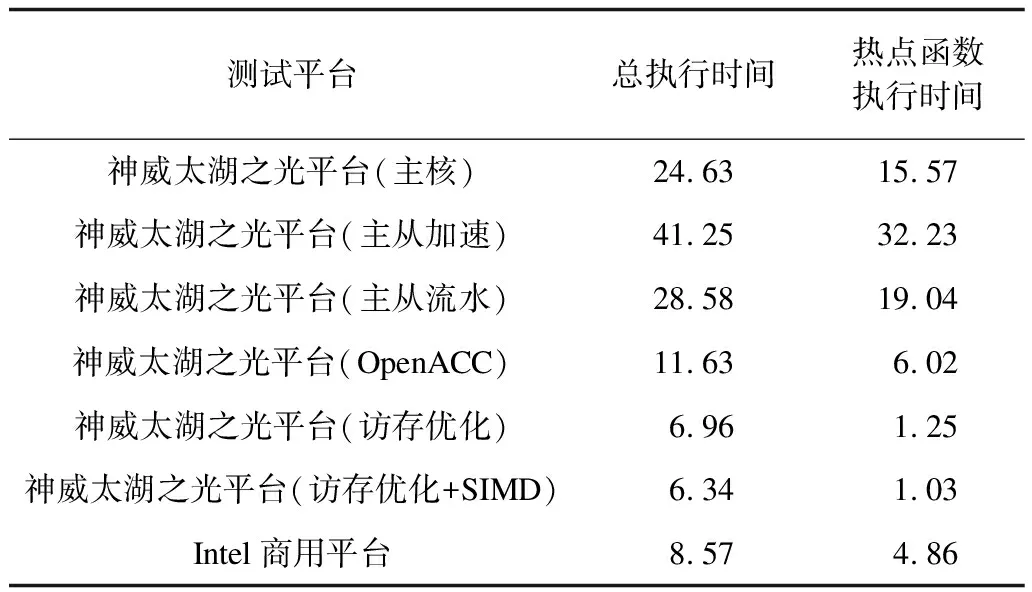
表5 AMBER热点函数在神威太湖之光与Intel商用平台上的测试数据Table 5 Test data of AMBER hotspot function on theSunway TaihuLight and Intel commercial platform s
在神威太湖之光平台的SW26010处理器上采取不同优化方案后的热点函数加速情况,如图7所示。可以看出,优化前AMBER_sander热点函数在主核上的执行时间为15.57 s。在实现热点函数主从加速并行方案后,由于未进行访存优化且在从核计算过程中主核处于阻塞状态,因此函数执行时间增加至32.23 s。在实现主从异步流水并行方案后,由于主核和从核之间存在并行协作计算,使得热点函数的执行时间下降至19.04 s,然后进行访存优化后,热点函数的执行时间下降至1.25 s。通过上述所有优化方案后,本文使用SW26010单核组的64个从核将AMBER_sander的热点函数计算性能约提升了15倍。
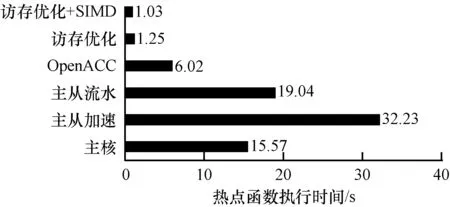
图7 热点函数性能加速
由于不同优化方案对AMBER_sander有不同的优化效果,因此本文统计了不同优化方案对热点函数性能加速的执行时间占比,测试数据如表6所示。在实现主从加速并行化后,采用主从异步流水、访存优化(LDM和DMA通道)以及SIMD向量化对并行化版本的AMBER做性能优化,使得AMBRE软件的热点函数执行时间降低至31.20 s(主从+访存+SIMD)。
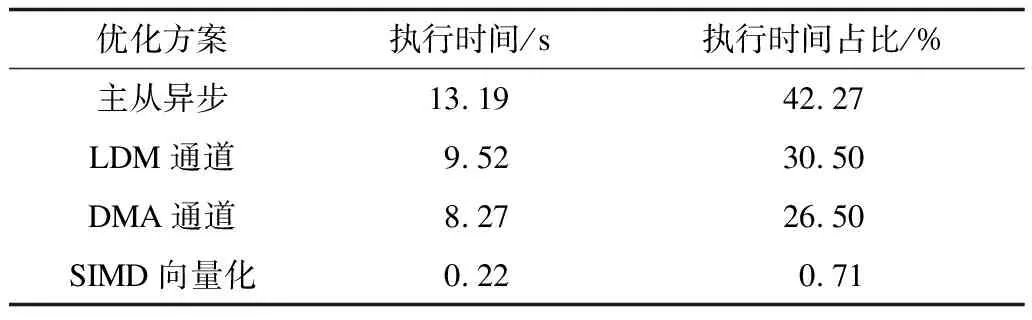
表6 优化方案对AMBER_sander的性能加速情况Table 6 Performance acceleration of AMBER_sander by optimization schemes
可以看出,不同优化方案对性能的加速效果不同,如图8所示,针对从核访存(LDM+DMA)的优化占了总优化时间(31.20 s)的50%以上,通过测试分析可以为后续在神威太湖之光平台上移植与优化其他软件提供借鉴与指导。
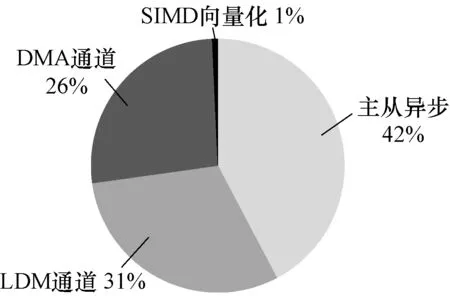
图8 优化方案对AMBER_sander的性能加速占比
本文将AMBER_sander在神威太湖之光平台上单核组的单进程性能与Intel商用平台上单进程性能进行对比,如图9所示。
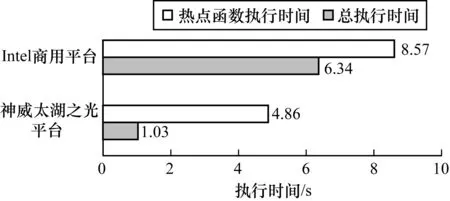
图9 AMBER_sander在神威太湖之光与Intel商用平台上的性能对比
可以看出,AMBER_sander热点函数在SW26010单核组上优化后的性能相比Intel Xeon Platinum 8163上约提升了4.6倍。值得注意的是,优化后AMBER_sander热点函数在单核组上的整体性能略高于Intel商用平台上的性能。这是因为随着优化过程的不断深入,热点函数的执行时间越来越短,非热点函数的执行时间在程序总执行时间中所占的比重越来越大,根据Amdahl定律热点函数执行效率提升所带来的整体性能收益也变得越来越小。
7 结束语
本文基于神威太湖之光处理器的主从硬件结构,建立主从加速模型,并实现AMBER软件的从核并行化设计。在并行化版本的基础上,提出主从异步流水化方案,针对从核的并行访存进行一系列性能优化,极大提升AMBER软件在神威太湖之光平台上的计算性能。应用所有优化方案后,AMBER热点函数性能较优化前约提升15倍,其单核组性能相比Intel Xeon Platinum 8163约提升4.6倍。随着计算节点的增多,节点间的数据传输将成为性能瓶颈,因此后续将开展AMBER软件在神威太湖之光平台上的强扩展性研究,解决节点间的消息传输带宽限制问题。
猜你喜欢
加油站服务指南(2022年6期)2022-07-28
今日农业(2020年18期)2020-10-27
车迷(2019年10期)2019-06-24
快乐语文(2018年7期)2018-05-25
制造技术与机床(2017年6期)2018-01-19
自动化学报(2016年5期)2016-04-16
探测与控制学报(2015年4期)2015-12-15
中国卫生(2014年12期)2014-11-12
组合机床与自动化加工技术(2014年12期)2014-03-01
中国记者(2014年6期)2014-03-01
