
基于深度森林的视网膜血管分割算法
2020-12-16 09:23李志强吴臣桓
云南民族大学学报(自然科学版) 2020年6期
李志强,杨 欣,吴臣桓
(南京航空航天大学 自动化学院,江苏 南京 211100)
眼底视网膜血管的形态是相关眼科疾病和心脑血管疾病诊断的重要依据,但由于眼底视网膜血管结构分布十分复杂,而且受噪声和器械成像质量的影响,医护人员难以高效地从眼底视网膜图像中正确分离出血管,这给相关疾病的诊断带来了极大的困难[1].因此,视网膜血管自动化分割成为了现代医学图像处理领域内的研究热点.目前的视网膜血管分割算法主要分为非监督方法和监督方法2类,非监督方法主要是基于血管跟踪、匹配滤波、形态学处理和形变模型的方法[2],文献[3]利用图像的混合区域信息通过主动轮廓模型来解决血管分割问题,文献[4]利用二维匹配滤波增强血管灰度,并用灰度-梯度共生矩阵的最大熵阈值化方法对视网膜血管进行分割,文献[5]提出一种基于形态学的分割方法,有效提高了分割结果对光照变化的鲁棒性.监督方法将视网膜血管分割视为像素级分类问题,通过分类算法对像素点进行分类.近几年基于机器学习的视网膜血管分割算法得到了很大的发展,这类方法需要人工提取视网膜图像特征再通过分类器区分血管和非血管像素.文献[6]提取视网膜图像的梯度矢量场信息,并通过集成决策树系统进行视网膜血管分割;文献[7]提出了一种利用灰度级特征和不变矩特征,通过神经网络进行视网膜血管分割的算法;文献[8]提出了一种利用Gabor滤波和不变矩特征,采用多层感知器进行视网膜血管分割的算法.基于机器学习的方法的分割性能整体要比非监督方法好,但手动提取医学图像的特征非常依赖研究人员的领域先验知识.此外,基于机器学习的方法一般需要大量数据进行训练,但在医学图像处理领域内,大量的医学图像数据很难获取,给实现训练高效稳定的视网膜血管分割模型带来了很大的困难.深度森林是Zhou等[9]提出的一种新型集成机器学习方法,相比于经典机器学习模型超参数要少很多且模型性能对超参数设置不敏感.更重要的是,深度森林对小样本数据集非常有效.考虑到深度森林的这些优良特性,本文提出了一种基于深度森林的眼底视网膜血管分割方法,首次将深度森林算法应用到医学图像分割领域,在公开眼底视网膜图像数据集上的分割效果取得了显著提升.
1 本文算法
1.1 整体框架
视网膜血管分割算法整体框架如图1所示,模型整体结构由预处理模块(preprocessing module)、多粒度扫描模块(multi-grained scanning module,MGS模块)和级联森林模块(cascade forest module,CF模块)3部分组成.3个模块分别负责特征增强、特征提取和像素点分类,这样既增加了模型的可解释性也降低了超参数调节的难度.

图1 算法整体框架
模型运行过程可表示为:
y=F(M(P(x))).
(1)
式(1)中,x为输入数据,y为预测结果,P表示预处理过程,M表示MGS模块的特征提取过程,F表示CF模块的类别预测过程.首先预处理模块对原始数据进行噪声抑制和特征增强操作并以待分类像素点为中心提取图像块;然后将图像块输入MGS模块进行特征提取;最后将MGS模块提取到的特征向量输入到CF模块进行中心像素点类别预测.
1.2 预处理模块
为抑制噪声和提高血管与背景的对比度,需要先对图像进行预处理.彩色眼底视网膜原始图像的RGB 3个通道中,绿色通道的噪声相对较少且细节信息明显,能够很容易定位出血管的轮廓.而其余两个通道对比度太低,饱和效应明显,无法提供有用的前后景分辨信息.为抑制光照不均匀带来的影响,进一步使用限制对比度自适应直方图均衡算法(CLAHE)做增强处理.
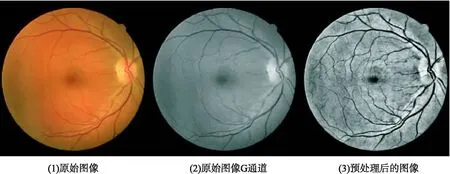
图2 预处理可视化结果
图2以DRIVE数据集中的1张图像作为示例,分别展示了原始RGB图像、原始图像绿色通道以及CLAHE增强处理后的绿色通道可视化结果.可见经过CLAHE增强处理后的绿色通道图像,血管边缘和末梢的对比度得到了进一步加强.
1.3 多粒度扫描特征提取模块
深度森林(gcForest)是Zhou等2017年提出的1种新型集成机器学习算法.深度森林以决策树作为基学习器,整体结构由多粒度扫描(multi-grained scanning,MGS)和级联森林(cascade forest,CF)2部分组成,其中多粒度扫描的作用是对原始输入数据进行特征学习,即特征抽取过程.级联森林是1种可自主生长的级联结构,用于将多粒度扫描得到的特征进行分类预测.
多粒度扫描模块通过多尺度滑窗扫描原始输入图像,每个尺度的扫描结果都送入1个随机森林和1个完全随机森林进行类向量提取,最后将所有森林得到的类向量拼接作为变换后的特征向量(如图3所示).所以多粒度扫描得到的特征向量维度可以表示为:
(2)
式(2)中,m和n表示输入图像的长和宽,s表示正方形滑窗移动的步长,{x1,x2,…,xi,…,xn}是滑窗的边长集合且必须满足max{x1,x2,…,xi,…,xn}≤min{m,n},C是输入数据类别个数.V是多粒度扫描从原始数据中提取的特征向量维度.
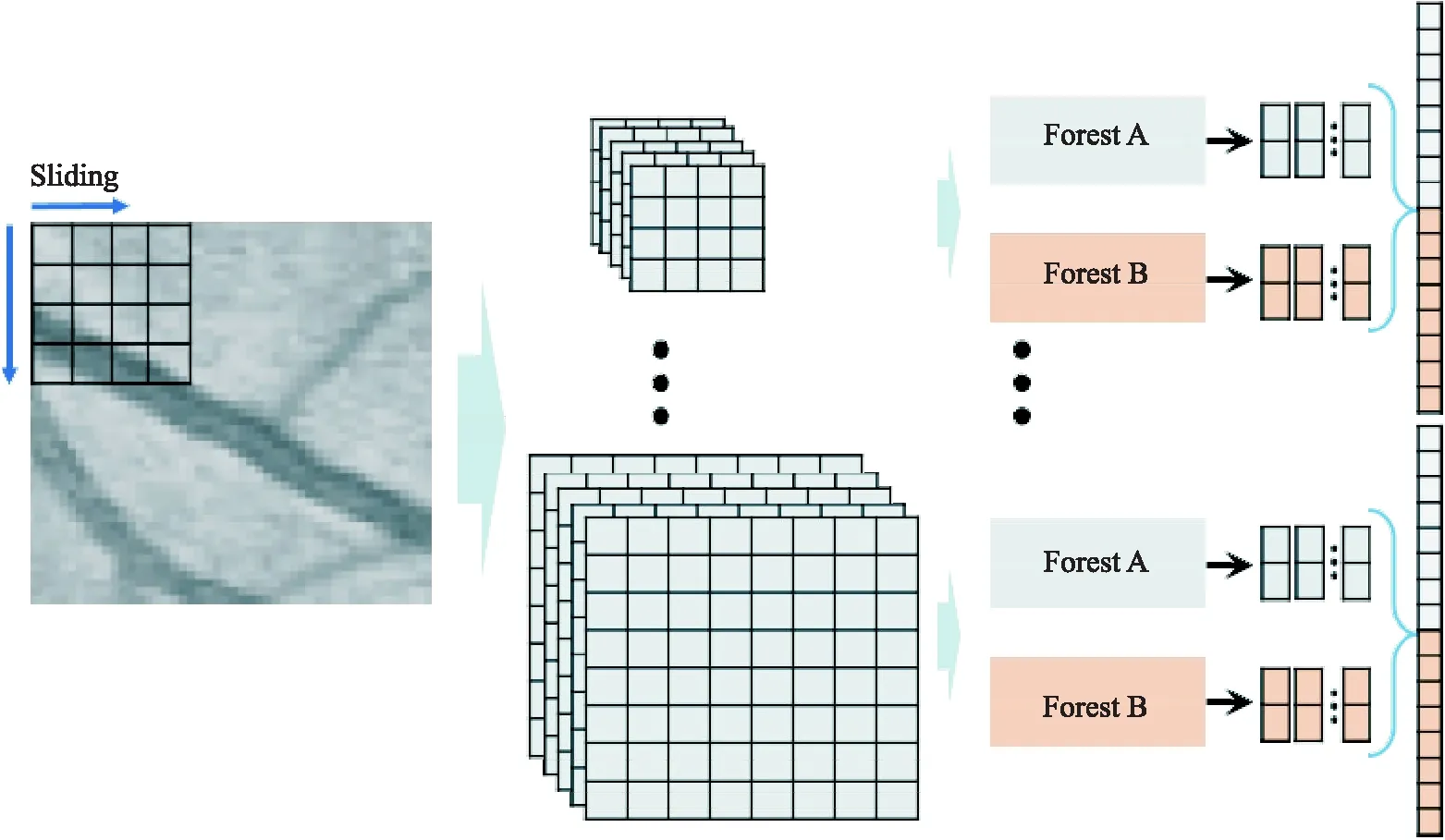
图3 多粒度扫描模块
1.4 级联森林分类模块
级联森林模块采用了Bagging和Stacking集成学习思想,将基学习器决策树进行集成,构造了1种可自主生长的级联结构,且对超参数和数据量不敏感,模型可解释性更强.级联森林的结构与神经网络类似,原始特征向量输入到级联森林浅层,将输出类向量结果与原始特征向量拼接作为下一层的输入,直到级联森林性能不再提升或提升小于某一阈值时停止生长,在级联森林最后一层将所有森林类向量取平均作为模型预测的类别概率.这种结构不仅可以通过增加模型深度来提高模型性能,还可以通过自适应调节模型复杂度,使其更好地拟合数据集.如图4所示,级联森林的输入向量维度为N,每层由x个随机森林和y个完全随机森林组成,且每个森林都包含m棵决策树,那么对于C分类问题,级联森林每增加一层,将产生1个(X+Y)×C维的增强特征,然后用增强特征与输入特征拼接(维度为(X+Y)×C+N)作为下一层的输入,自适应生长直到模型性能不再提升或提升小于某一阈值,并将级联最后一层每个森林的输出类向量取平均得到C维预测向量作为模型最终的预测概率,并以最大预测概率对应的类作为模型的最终预测结果.

图4 级联森林模块
2 实验验证与分析
2.1 数据集介绍
本文使用DRIVE和STARE眼底视网膜数据集验证了算法的有效性.DRIVE数据集[11]包含40张眼底视网膜彩色图片,其中有7张有轻微糖尿病视网膜病变迹象,并且每张图片的分辨率均为565×584,该数据集已将所有图片分为20张训练图片和20张测试图片,所以可以直接在训练集上训练模型,在测试集上评估模型.STARE数据集[12]包含20张眼底视网膜彩色图片,其中有10张显示出轻微病变迹象,并且每张图片的分辨率为700×605.但STARE数据集并未区分训练集和测试集,为了更准确地评估模型性能,需要在STARE数据集上做k-fold交叉验证,本文选择k=4的交叉验证来进行模型性能评估.以上2个数据集都包含由2位专家手动标记的血管分割标签,本文采用第1位专家标记的结果作为标准结果进行模型训练和评估.此外,DRIVE数据集已经提供了视野范围的二值掩模,但STARE数据集并未提供,本文已手动提取了视野范围的掩膜以备模型训练和评估使用.
2.2 参数设置
在预处理后的训练数据中随机选取20万个大小为25×25图像块,并以图像块中心位置对应的标签作为图像块的标签,其中正负样本比为1∶4,并取其中10%作为验证集.MGS模块的滑窗尺度集合设为{7,14,21},滑窗步长设为3,每个尺度对应的2个森林均包含101个决策树.CF模块能够根据训练数据的复杂度自主生长,本文设置级联森林每层包含4个随机森林,其中2个为完全随机森林,2个为随机森林,每个森林的决策树个数均为121.为限制决策树生长,当决策树节点与根节点样本数的比值低于 0.000 1 或节点只包含一类样本时终止节点分裂.为限制级联森林生长,当验证集准确率提升低于 0.000 01 时停止级联森林生长.此外,实验程序全部使用python3.6在Windows10系统上运行,深度森林模型使用Scikit-learn库编写并在Intel i5-9400f CPU上进行训练.
2.3 评估指标
本文采用准确度(accuracy,ACC)、灵敏度(sensitivity,SE)、特异性(specificity,SP)以及AUC(area under the ROC curve)这4个指标来评估模型性能,其中灵敏度衡量模型区分前景(血管)的能力;特异性衡量模型区分背景(非血管)的能力;ACC和AUC衡量模型整体分割性能.这4个指标都是数值越大表明性能越好.计算公式如下:
其中,TP表示分类正确的前景(血管)像素,TN表示分类正确的后景(非血管)像素、FP表示背景(非血管)像素错误分类为前景(血管)像素,FN表示前景(血管)像素错误分类为背景(非血管)像素.此外,AUC通过计算ROC曲线下的面积得到.为保证评价的合理性,所有的评价指标均在视野范围内(即掩膜内部)进行计算.
2.4 实验结果
本文在 DRIVE和STARE数据集上进行算法性能评估,且均将数据集中第1位专家标记结果作为标准结果,表1展示了模型在每个数据集上的测试结果.

表1 本文算法测试结果
从表1可知,本文算法的SE、SP、ACC和AUC指标,在DRIVE数据集上分别达到了 0.694 5、0.972 9、0.937 5 和 0.932 0;在STARE数据集上分别达到了 0.745 6、0.969 3、0.946 1 和 0.952 4.深度森林的级联层数在DRIVE和STARE数据集上训练时,分别自适应设置为7层和8层(交叉验证的均值).为更直观地评估分割模型的鲁棒性,作出模型在每个数据集上测试得到的ROC(receiver operating characteristic)曲线如图5所示,并给出样例分割结果如图6所示.
由图5、图6可知,本文算法的分割概率图非常接近标准图,对于较细的血管也具有良好的区分性.分割二值图是用0.5为阈值进行二值化得到的结果,可以观察到主干血管都能被正确的分割出来,表明本文算法对视网膜血管分割问题的有效性.表2将本文算法和其他视网膜血管分割算法进行了性能对比,综合本文算法在2个数据集上的测试结果可知,本文算法的整体性能要优于部分其他视网膜血管分割算法,尤其在SE和AUC指标上表现突出.实验结果表明本文算法具有优异的视网膜血管分割能力,具有一定的应用价值.

图5 模型预测结果ROC曲线

图6 模型分割结果示例
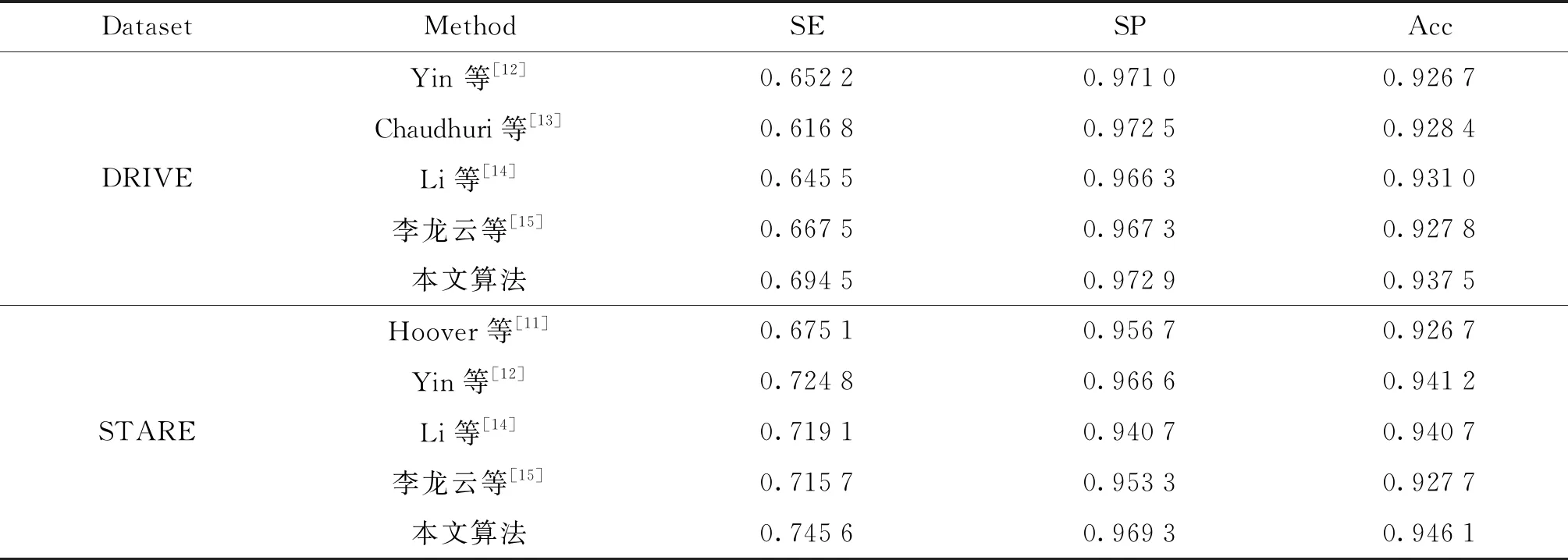
表2 本文算法与其他算法的性能比较
3 结语
本文提出的基于深度森林的视网膜血管分割方法,首先通过多粒度扫描对预处理过的图像块进行特征提取,然后用级联森林对图像块中心像素进行分类,进而完成对视网膜血管的分割.本文首次将深度森林算法引入到图像分割领域,并通过实验证明了其在眼底视网膜图像分割任务中的有效性,具有一定的应用价值.本文算法还有进一步改进的空间,由实验结果可知,主干血管分割效果较好,但存在血管边缘分割边界不明显、血管末端误分和断裂问题,其主要原因是视网膜血管边缘和末端相比于主干血管中心像素的前后景区分度较低.下一步工作计划引入深度学习模型来加强模型的上下文感知能力,以及增加后处理来解决这些不足之处.
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
核安全(2022年3期)2022-06-29
四川大学学报(自然科学版)(2021年6期)2021-12-27
中医眼耳鼻喉杂志(2021年1期)2021-07-22
中医眼耳鼻喉杂志(2021年2期)2021-07-21
世界最新医学信息文摘(2021年12期)2021-06-09
—— “T”级联
同位素(2019年1期)2019-03-14
唐山师范学院学报(2018年6期)2018-12-25
文苑(2015年9期)2015-09-10
原子能科学技术(2015年12期)2015-07-07
