
一种基于信息熵的加权聚类算法
2020-12-16 09:04:22李顺勇崔文秀荆鹏霏
云南民族大学学报(自然科学版) 2020年6期
李顺勇,崔文秀,荆鹏霏
(山西大学 数学科学学院,山西 太原 030006)
聚类既可以作为1种寻找数据内在关系及分布结构的工具,也可作为其他工作领域的前期准备,其涉及领域包括数据挖掘、统计学和生物信息学、机器学习等.
针对不同的学习策略,众多学者已经设计出多种类型的聚类算法,并提出了一系列加权聚类算法.对于数值型数据,文献[1]在k-means的基础上,提出了一种带权的聚类算法,定义了加权相异性度量,并通过加权相异性度量计算每一簇中每个属性的属性权重.文献[2]提出了1种基于当前数据划分的变量权重迭代更新方法,可以自动计算可变权重.文献[3]提出了一种处理高维样本的k-means type算法,该算法给出了一种新的维数权重计算公式,并将其作为每次迭代的补充步骤添加到k-means算法过程中.对于分类型数据,文献[4]是k-modes算法的扩展,该算法提出了一种新的分类数据加权技术,在聚类过程中计算每个属性的两个权重.文献[5]在k-modes的基础上,提出了一种加权k-modes算法,利用互补熵计算每个簇的权重.文献[6]也是针对分类型数据加权聚类算法,其权重的计算依赖于总体分布情况.
混合型数据是数值型数据和分类型数据的结合,而真实数据集大部分是混合数据,所以解决混合数据聚类问题显得尤为重要[7-9].文献[7]把k-means算法和k-modes算法进行了集成提出k-prototypes算法(文中简记为Huang-k-prototype),并通过γ反应不同类型属性的重要度.文献[10]在Huang-k-prototype的基础上提出了新的k-prototypes算法(文中简记为Liang-k-prototypes),在计算属性权重中分别考虑了数值型属性个数及分类型属性个数所占属性总个数的比例.文献[11]基于文献[10],提出了1种带权的混合数据聚类算法(文中简记为Li-k-prototypes),权重的计算是通过类内熵[14]给出的,并没有考虑到类间熵对属性权重的影响.而本文在Li-k-prototypes算法的基础上,综合考虑类内熵(WEN)和类间熵(BEN)对属性权重的影响,给出了新的带权聚类算法(文中简记为New-k-prototypes),在5个UCI数据集上,该算法在5个外部评价指标及1个内部评价指标下均优于Liang-k-prototypes算法和Li-k-prototypes算法.
1 预备
本节我们回顾Huang-k-prototypes算法、Liang-k-prototypes算法及Li-k-prototypes算法.
由于日常生活中接触到的大部分都是混合数据,Huang将k-means算法[13]和k-modes算法[14]进行了简单的集成提出Huang-k-prototype算法.其目标函数为:
(1)
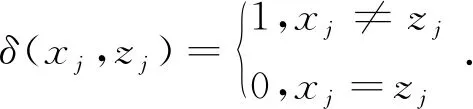
Liang-k-prototypes算法本质上是对γ的变形.其目标函数为:
(2)

其中,|·|代表“·”中所含样本的个数.
Li-k-prototypes算法在Liang-k-prototypes算法的基础上,考虑了每个属性的权重,用类内熵定义了属性权重,提出了带权的k-prototypes算法,重新定义了寻找最坏类广义机制及有效性指标.为了给出目标函数,先给出相关概念.

(3)
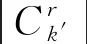

(4)

定义3混合型数据决策系统MDT=(U,A,V,f),其中A=Ar+Ac,在聚类过程中被划分为k类,即Ck={C1,C2,…,Ck}.对于任意一类Ck′∈Ck,在混合属性At(1≤t≤q)下,数值型属性Ar及分类型属性Ac在类Ck′下的权重分别定义为:
(5)
(6)
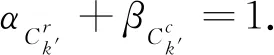
其目标函数为:
(7)
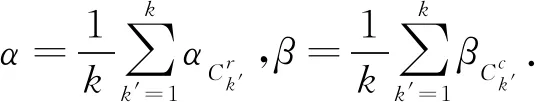
Li-k-prototypes算法虽然能够有效的确定聚类个数,但在定义权重时只考虑了类内熵对权重的影响,没有考虑聚类结果与类内熵和类间熵均有关联,在聚类过程中,综合考虑类内熵和类间熵对属性权重的影响,必会对聚类结果产生积极地作用.因此,本文在k-prototypes算法框架的基础上,综合考虑类内熵和类间熵对属性权重的影响,提出了新的带权的New-k-prototypes算法.
2 基于信息熵的加权聚类算法
聚类试图将数据集中的每1个样本对应划分到不同的类中,为每个样本赋予1个合适的权重,必对聚类结果产生积极的影响.信息熵是一种度量系统混乱程度的有效度量方法,系统的混乱程度与信息熵的大小成正比.本节将讨论基于信息熵的加权聚类算法问题.在给出基于信息熵的混合数据加权聚类算法前,先给出数值型、分类型数据平均类间熵的定义,并结合属性的类内熵及平均类间熵计算混合数据的属性权重.
2.1 基于信息熵的属性权重
针对数值型数据, 1961年数学家Renyi提出Renyi熵[15]的概念,基于Renyi熵,下面给出数值型数据的类内熵与平均类间熵的定义.
(8)
由上述定义1和定义4可知,属性重要度与类内熵成反比,与平均类间熵成正比.下面给出数值型属性重要度(WN)定义.

(9)
对于分类型数据,文献[16]提出了互补熵,在此基础上,定义了分类型数据在某一属性下的类内熵与平均类间熵.
(10)

与数值型属性重要度类似,由上述定义2和定义6可知,属性重要度与类内熵成反比,与平均类间熵成正比.下面给出分类型属性重要度(WC)定义.
(11)
基于上述对数值型、分类型数据重要度的定义,下面基于信息熵给出混合数据中数值型数据和分类型数据权重的定义:
定义8混合型数据决策系统MDT=(U,A,V,f),其中A=Ar+Ac,在聚类过程中被划分为k类,即Ck={C1,C2,…,Ck}.在属性At(1≤t≤q)下,对于任意一类Ck′∈Ck,数值属性及分类属性在Ck′下的权重分别定义为:
(12)
(13)
由(12)及(13)可知,
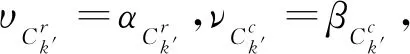
2.2 寻找最坏类广义机制
文献[10-11]提出了2种寻找混合数据中最坏类的广义机制,前者目标函数只考虑了数值型属性及分类型属性个数对分类的影响,后者只考虑了类内熵对分类的影响.因此,基于上述定义,我们定义了新的目标函数.
定义9混合型数据决策系统MDT=(U,A,V,f),其中A=Ar+Ac,在聚类过程中被划分为k类,即Ck={C1,C2,…,Ck}.对于任意一类Ck′∈Ck,有
(14)
其中,
(15)
(16)
缺失一类类间熵的和SBAEM(Ck′)越大,表明缺失该类后系统的混乱度越大,即该类对总类间熵和的影响较小.基于SBAEM(Ck′),我们给出了最坏类的定义:
定义10混合型数据决策系统MDT=(U,A,V,f),其中A=Ar+Ac,在聚类过程中被划分为k类,即Ck={C1,C2,…,Ck}.对于任意一类Ck′∈Ck,有
(17)
2.3 聚类有效性指标
为了评估聚类结果,文献[17-18]已经提出了多种聚类评估指标,然而,这些指标仅适用于数值型数据或分类型数据.文献[10-11]基于混合数据提出了新的聚类评估指标.本节在Li-k-prototypes算法的基础上基于上述对权重的定义,也将新的权重引入有效性指标,重新定义了有效性指标.
(18)

(19)
定义13混合型数据决策系统MDT=(U,A,V,f)其中A=Ar+Ac,在聚类过程中被划分为k类,即Ck={C1,C2,…,Ck}.对于任意一类Ck′∈Ck,有
CUM(Ck′)=υCUN(Ck′)+νCUC(Ck′),
(20)
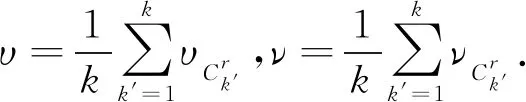
2.4 混合数据相异性度量
Huang[7]提出的k-prototypes,用γ控制数值型属性及分类型属性的重要程度,实际上,选择一个合适的γ是很困难的.Liang[10]定义的相异性度量,用数值型属性和分类型属性占总属性个数的比值反应其权重,没有考虑各属性存在差异.Li[11]定义的相异性度量,用类内熵反应其权重,没有考虑类间熵对重要度的影响.因此,本节综合考虑类内熵及类间熵对重要度的影响,基于新的权重,给出新的相异性度量定义.
定义14混合型数据决策系统MDT=(U,A,V,f),其中A=Ar+Ac,在聚类过程中被划分为k类,即Ck={C1,C2,…,Ck}.对于任意的x∈U,任意一个初始迭代类中心z,相异性度量的定义为:
(21)
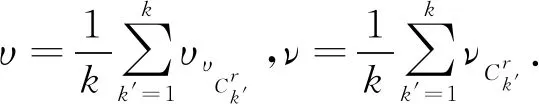
基于上述定义14,New-k-prototypes算法基本步骤如下:
算法1New-k-prototypes算法
输入 决策系统MDT=(U,A,V,f),其中A=Ar+Ac,υ,ν,k.
输出 聚类结果Ck={C1,C2,…,Ck}.
Step 1 从混合数据决策系统MDT中任意选出k个不同样本作为初始迭代类中心;
Step 2 用混合数据相异性度量(21)逐一计算样本到初始迭代类中心的距离,距离最小的被分到该初始迭代类中心所代表的类中;
Step 3 更新类中心;
Step 4 重复Step 2,Step 3直到类中心不变时停止.
2.5 混合数据加权聚类算法
基于上述对寻找最坏类Cw、效性指标CUM及相异性度量D的重新定义,下面提出New-k-prototypes聚类算法,基本步骤如下:
算法2New-k-prototypes聚类算法
输入 决策系统MDT=(U,A,V,f),其中A=Ar+Ac,kmax,kmin,σ.
输出 聚类结果Ck={C1,C2,…,Ck}和最优聚类数k.
Step 1 从混合型数据决策系统MDT中任意选出k个不同样本作为初始迭代类中心Zkmax={z1,z2,…,zkmax};
Step 2i=kmax:kmin;
Step 2.1 当i=kmax时,用Modifiedk-prototypes对样本进行聚类;否则,当i≠kmax时,用New-k-prototypes对样本进行聚类,得出聚类结果Ck={C1,C2,…,Ck};
Step 2.2 计算υ、ν及SBAEM(Ck′),找出最差类Cw,Cw∈Ck;
Step 2.3 根据式(20),计算Ck的有效性指标CUM;
Step 2.4 对Cw中的样本,用上式对其再次分类;
Step 2.5 更新类中心;

3 实验结果与分析
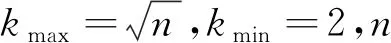

表1 数据集信息描述
为了检验New-k-prototypes算法的有效性,本文采用精度(Clustering Accuracy,CA)、纯度(Purity,PR)、召回率(recall,RE)、兰德指数(Adjusted Rand Index,ARI)和归一化互信息(normalized mutual information,NMI) 5个外部评价指标,以及1个内部评价指标CUM(category utility function for mixed Data,CUM).
对数据集X={x1,x2,…,xm},通过聚类得到的簇划分为C={C1,C2,…,Ck′},参考模型给出的真实簇划分为P={P1,P2,…,Pk}.假定k′=k,内部评价指标CUM根据式(20) 计算,其他5个外部评价指标根据下面给出的公式计算:
(22)
(23)
(24)
(25)
(26)
其中,cj表示类Pi和类Cj中对象的个数,nij=|Pi∩Cj|表示类Pi和类Cj中相同对象的个数,niji*表示正确分到第i类的对象个数.
本节将New-k-prototypes算法与Liang-k-prototypes算法及Li-k-prototypes算法在上述5个外部评价指标(CA、PR、RE、ARI、NMI)下进行比较的结果见表2.表2 5种外部指标的比较如表2所示,本文提出的算法在Statlog和post-operative数据集上优于其余3种算法,在Statlog上表现得更为明显;在 GC及Liver disorders这两个数据集上,有个别指标低于其余3种算法,但总体效果还不错;在Cheart数据集上的数值高于Liang提出的算法所得的数值略低于Li提出的算法所得到的数值.

表2 5种外部指标的比较
图1~图5中的五角星代表New-k-prototypes算法的有效性指标CUM值,三角形代表Li-k-prototypes算法的有效性指标CUM值,圆圈代表Liang-k-prototypes算法的有效性指标CUM值,可以看出由New-k-prototypes算法计算得到的有效性指标CUM的值均在其余2种算法计算得到的有效性指标CUM值之上,且由New-k-prototypes算法得到的分类均正确.
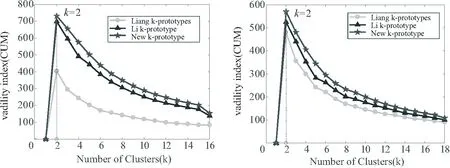
图1 Statlog数据集上CUM随k的变化曲线图 图2 Liver disorders数据集上CUM随k的变化曲线图
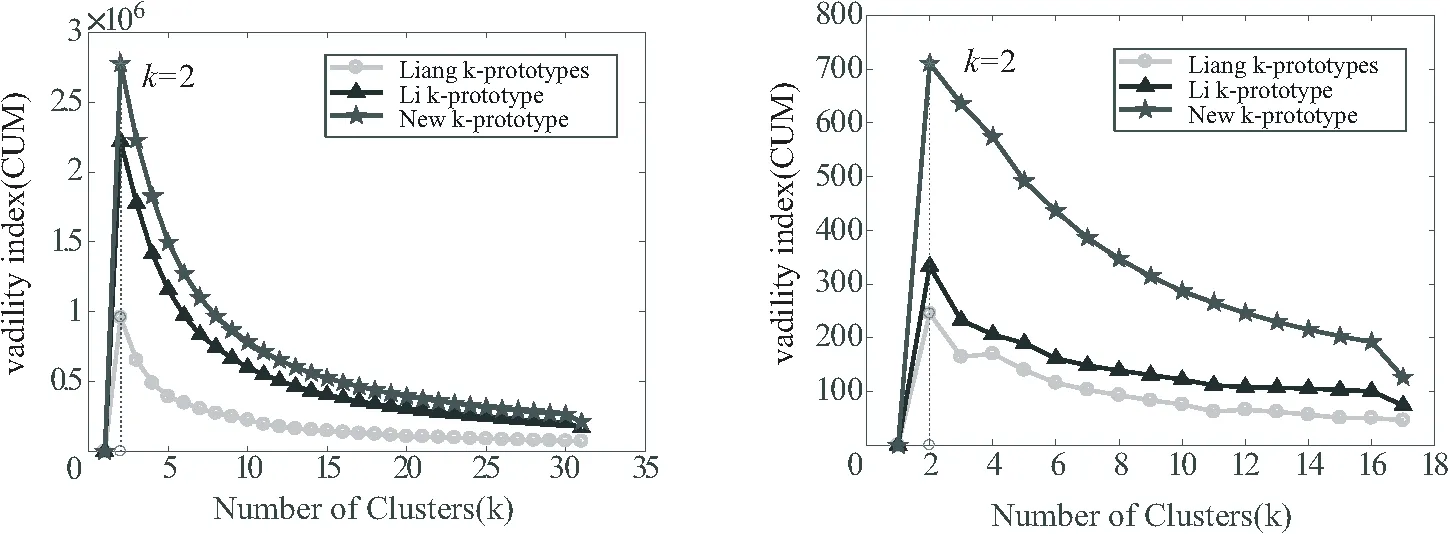
图3 GC数据集上CUM随k的变化曲线图 图4 Cheart数据集上CUM 随k的变化曲线图
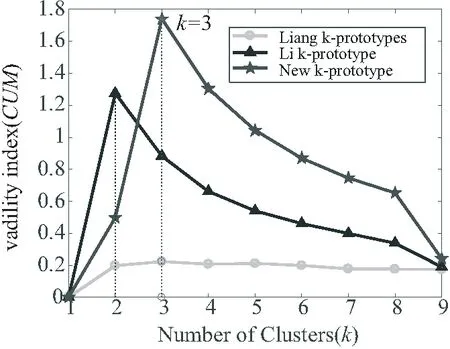
图5 Post-operative数据集上CUM随k的变化曲线图
表3所示为内部评价指标CUM及聚类结果的比较,在表1所列的5个数据集上,用New-k-prototypes算法计算得到的分类个数,均与真实类别数相等,且有效性指标CUM明显比其余2种算法高,数据集Cheart虽然在外部评价指标的值略低于Li,但有效性指标CUM的值甚至是Li有效性指标CUM的两倍多,这就验证了New-k-prototypes算法的有效性.

表3 CUM及聚类结果的比较
4 结语
本文基于信息熵,在Li-k-prototypes算法的基础上,分别基于Renyi熵及互补熵定义了数值型属性及分类型属性的属性权重,进而提出了基于信息熵的混合数据加权聚类算法,并重新定义了寻找最坏类广义机制、有效性指标及相异性度量.New-k-prototypes算法综合考虑类内熵和类间熵对权重的影响,在5个真实数据集上进行了实验验证,结果表明New-k-prototypes算法是有效的.
猜你喜欢
无线互联科技(2020年22期)2021-01-11 13:52:34
当代陕西(2020年17期)2020-10-28 08:18:18
弹箭与制导学报(2020年2期)2020-09-01 02:08:56
传感器与微系统(2018年7期)2018-08-29 00:44:42
人大建设(2018年5期)2018-08-16 07:09:00
电子测试(2017年15期)2017-12-18 07:19:27
电信科学(2017年6期)2017-07-01 15:44:57
自动化学报(2017年4期)2017-06-15 20:28:55
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
