
数字人文视野下的古汉语实体歧义研究
2020-12-15 10:55刘浏王东波黄水清苏新宁
图书与情报 2020年5期
刘浏 王东波 黄水清 苏新宁

摘 要:实体知识的自动识别是古文智能处理的重要内容,也是古文数字人文研究的技术支撑。以实体知识为基础的数字人文研究若不考虑古籍中普遍存在的实体歧义,将难以得到准确可靠的数据和结论。文章以《春秋经传引得》为文本语料,考察了语料中同名异指和异名同指两大类人名实体歧义,根据古文实体歧义消解的特殊性,提出两类歧义的消解方法和思路。研究基于实体语境和时间知识,构建了消歧规则并以先秦古汉语为实例进行了验证。上述方法在其他古汉语语料中的适用性值得进一步探究,基于消歧后的语料,文章呈现了先秦人物的基本全貌,表明了本研究的价值所在。
关键词:古文信息处理;实体歧义;古文智能处理;古文数字人文
中图分类号:TP393.1 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2020089
Abstract In Ancient Chinese Information Processing, the extraction of entity knowledge is one of the most important studies. Study of digital humanities with entity knowledge should concern more about entity ambiguity for more precise results. The article presents two rule-based methods on entity disambiguation with the ancient Chinese corpus. Two types of entity ambiguity were deeply discussed and two methods with examples of entities in Chunqiu Jingzhuan Yinde were presented. Further research on more ancient Chinese corpus would have shown better understanding of the methods presented above. A visualization study with the data of disambiguated entities was carried out at last and thus showed the value of this study.
Key words ancient Chinese information processing; entity ambiguity; intelligent processing; ancient Chinese digital humanities
1 引言
近年来,得益于古籍数字化资源规模的迅速增长和古文智能处理技术的飞速进步,以人名、地名为主的实体识别研究得到了较为广泛的关注和研究,识别的技术和方法也得到了不断的改进,识别效果逐渐提升。实体识别技术的进步,使得面向大规模古籍文本的实体知识自动获取越发高效[1],以实体知识为基础的数字人文研究也因此得以逐步开展[2-3],且成为古籍文本数字人文中值得期待的发展方向[4]。
然而,围绕实体展开的古文智能处理及以此为基础的古文数字人文研究,为简化实体知识的获取难度,大多以实体词语代替实体知识,忽略了古籍中大量存在的实体指称歧义,尤其是人名指称歧义,因而难以保证研究结论的准确。实体歧义的消解,尤其是大规模文本中实体歧义的自动消解,是古文数字人文研究深入开展前无法回避的话题,这也正是本文研究的意义和目的所在。
本文主要分为三个部分,首先介绍了两类典型的实体歧义,分析了古汉语实体歧义的特殊性,探讨了古汉语实体歧义消解的方法;其次以先秦时期古汉语实体歧义为例,在《春秋经传引得》语料的基础上,结合具体的实体歧义实例,分析了基于规则的实体消歧的可行性;最后使用上述方法完成了《春秋经传引得》中实体歧义的消解,并在该消歧语料的基础上,从计量统计、影响力分析和数据可视化的角度展现了先秦人物的基本全貌。
2 研究背景和语料介绍
2.1 实体歧义相关研究
实体歧义可以定义为“一个命名实体指称项可对应到多个命名实体概念”,古籍中的实体歧义以人名歧义为主,如《左传》中的实体词“吴王”,可能是指“夫差”、也可能是指“諸樊”。歧义实体词的指称一般因语境而不同,实体消歧需要做的就是判断在某个语境下,有歧义的实体词语具体指称的实体概念。虽然古文实体消歧目前还未得到重视,但在现代汉语和英语等文本语境下,相关研究从实体识别研究提出伊始便已得到了充分的关注[5]。
实体消歧方法最先以构建规则为主,实体的上下文和外部知识得到了充分的尝试[6-7],相关方法构建的规则受限于特定文本领域,可扩展性不高,但总体而言消歧效果不错;在此之后兴起的机器学习方法主要关注开放领域的实体消歧,早期的方法以聚类为主,将文本表示为向量空间,并根据文本向量的相似度实現歧义的消解[8]。不同聚类模型都得到了深入探究,各类特征如二元词语[9]、社会化网络[10]、外部知识[11]等也得到了充分的尝试。随着机器学习方法的不断深入,实体消歧转向一种将实体识别和实体消歧同时包含在内的研究新框架,也就是实体链接,该方法先找出文本中表示实体的指称,再与特定知识源中的实体概念相链接,以此达到实体消歧目的[12],其中维基百科等百科知识是最常见的知识源。对于实体链接来说,选取知识源中的候选实体是任务的关键,一般通过实体指称和候选实体之间的相似度来决定候选实体排名,而在相似度计算过程中,特征的选取就显得尤为重要[13]。近年来,随着深度学习的不断发展,实体链接问题得到了进一步的推进,并与语义分析、实体关系抽取、跨语言实体消歧研究等问题联系密切。
实体消歧研究仍然是自然语言处理中十分火热的研究问题,基于实体链接的消歧方法也在不断提高消歧的效果,但目前实体消歧极少有面向古汉语的研究,这一方面是由于没有适当规模的语料和知识源作为支撑,另一方面古汉语实体的歧义较之于现代汉语要复杂的多,这也加大了消歧的难度。
2.2 语料选取和处理
本研究语料来源于《春秋经传引得》,“春秋经传”是《春秋》《春秋左氏传》《春秋谷梁传》及《春秋公羊传》四部典籍的合称,该资源在前期研究工作中完成了数字化工作,全文录入共计320030字(含标点)。作为《汉学引得丛刊》的特刊,《春秋经传引得》包含了正文部分以及引得(索引)部分,其中引得部分包括引得词表以及词表对应的全文语境。词表进行了细致的人工消歧,对于多义词,词表中设立多个同形词头,并且这些词头下的语境互不交叉。对于人名实体来说,相关消歧做得更为细致,所有同名的实体,不仅词头和语境做了准确的区分,词头本身还添加了更为详细的人名参考信息,用以区分这些词头,详见下例:
例1: 宋公(參:宋莊公)
故遂相宋公
宋人者宋公也
……
宋公(參:宋共公)
宋公使公孫壽來納幣
公會晉侯齊侯宋公衞侯曹伯伐鄭
……
宋襄公(參:大子慈父,襄公,宋子,宋公,宋公慈父)
宋襄公卽位
宋襄公問焉
……
宋宣公
宋宣公可謂知人矣
……
本研究以此为基础,对词表中的人名实体进行人工识别,从而得到了“春秋经传”中所有人名及其相关语境,并构建了语料库。与语境的关联以及引得本身的专业背景,使其成为研究古汉语实体歧义的优秀资源,其在实体歧义标注中的专业性,保证了本研究实体歧义研究的可靠,避免了古汉语专业问题的争议。另一方面,实体歧义的研究须以实体识别为基础,而古汉语实体识别研究多以“春秋”为对象,因此本研究以“春秋经传”为语料资源,进行古汉语实体歧义的探究,这也是对已有古汉语实体研究的有效补充。
3 古汉语中的实体歧义
3.1 两类实体歧义
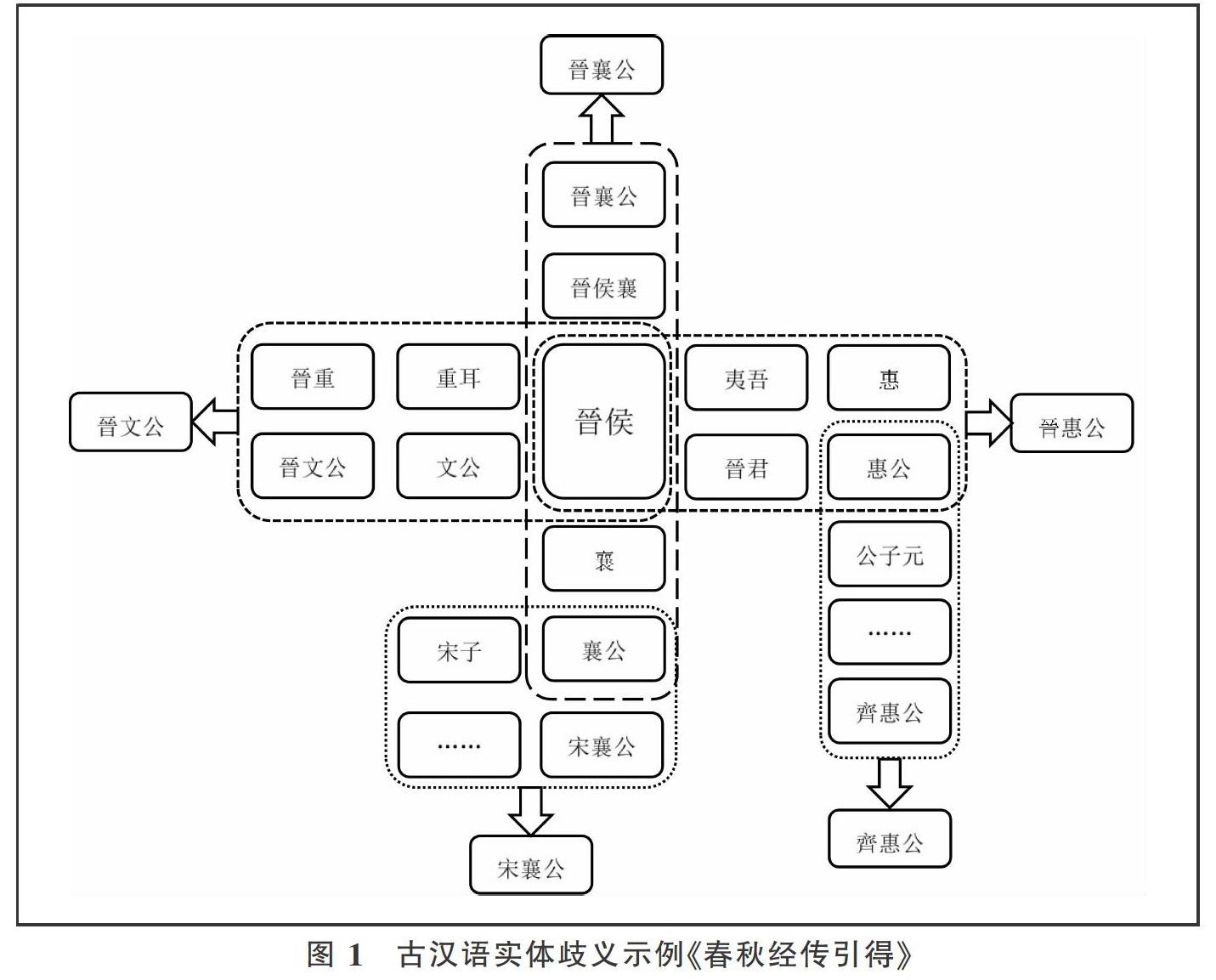
实体歧义可以看作实体词语和实体概念之间存在的多对一或者一对多的关系,根据关系的不同,可以分为同名异指歧义和异名同指歧义。同名异指歧义是一种一对多的关系,即一个实体词语可以指称多个实体;而异名同指歧义是多对一的关系,即多个实体词语可以指向同一个实体。
以上两类实体歧义在古汉语中均十分常见,且往往相互关联,构成十分复杂的实体歧义网络(见图1)。实体歧义的大量存在及复杂关联,表明了古汉语实体歧义研究的必要性,以及实体消歧的困难性。在两类实体歧义中,同名异指歧义在现代汉语及英语等自然语言处理中得到的关注明显更多,这源于其相对更广泛的应用场景和较低的解决难度;但在古文尤其是先秦古文中,由于名词性实体的显著地位(如“晋侯”“宋襄公”等包含爵位或尊称的实体名称),异名同指歧义的重要性同样不容忽视。对于面向实体知识的古文数字人文而言,同时消解同名异指和异名同指两类歧义,是顺利开展研究并得到准确结论的重要前提。
3.2 古汉语实体消歧的特殊性
实体消歧是古汉语实体歧义研究的重要目标,不同于现代汉语或英语,古汉语文本中的实体消歧问题具有较强的特殊性,这种特殊性体现在歧义实体所在语料和歧义实体本身。了解这一特殊性,是开展古汉语实体消歧研究的重要前提。
(1)固定的语料。古文信息处理和古文数字人文研究主要以传世的古籍文本为语料来源,而对于特定的研究问题和对象而言,可以选择的文本语料总体较为固定,以先秦实体研究为例,合适的语料基本以《春秋》及三传为主。有限的语料带来了相对固定的实体歧义,古汉语实体消歧研究因而不可能、也不需要像现代汉语那样关注开放领域问题。在这样的前提下,如何充分利用前人的研究成果,获取语料外部的实体知识,构建基于规则的消歧方法,以获取更准确的消歧结果,成为古汉语实体消歧中最实际可行的研究思路。
(2)较小的语料规模。与现代汉语相关研究相比,研究古汉语实体消歧时可获取的语料规模较小,这使得现代汉语实体消歧中常用的机器学习方法很难发挥出理想的效果。如以《春秋经传引得》为例,该书包含了《春秋》及三传4部古籍的内容,对于春秋时期实体歧义研究来说,该语料就内容而言已经足够充分,但全文也仅有32万余字,若要使用现代汉语实体消歧中常用的文本聚类或实体链接方法,这样的语料规模远远不够。从该角度来看,机器学习方法并不适用于古汉语实体消歧研究。
(3)较多的歧义数量。对于现代汉语实体消歧来说,待消解的同名异指实体一般只包含2个歧义;而在古汉语语料中,实体歧义的情况要更为复杂,名词性实体的存在带来了大量的同名异指实体,这类实体包含的歧义数量也很多,在《春秋经传引得》中,一个实体词语最多可能包含15种同名异指歧义(见表1)。另一方面,正如本文所述,大量的歧义实体对应的却是小规模的语料,这导致语料中大多数歧义实体对应的只有一两个句子。在面对如此复杂的实体歧义问题时,仅利用一两个句子的内容而不借助于外部的知识,显然难以获得准确的实体消歧结果。如何有效地利用外部的知識来减少歧义的复杂性,是解决古汉语实体消歧问题的关键。
3.3 古汉语实体消歧方法探讨
正如本文所述,由于语料固定、语料规模小、歧义数量多等特点,机器学习方法用于古汉语实体消歧的难度相当高,利用外部实体知识构建规则的方法则更为适合。
(1)古汉语实体消歧的对象。根据古汉语实体歧义的特殊性,在进行消歧之前,还可以从另一个角度将实体歧义分为两类,一类实体的歧义只存在于不相关的典籍之间,如“孟子”既可以指称鲁惠公的原配夫人,也可以指称儒家思想家孟轲;但“孟子”在《春秋》中指称前者,在《孟子》中指称后者,该实体词在单部典籍的内部不存在歧义,这类实体词的歧义消解通过限定典籍的范围就可以完成。
另一类实体词语的歧义存在于单部典籍内部,这些实体词的歧义消解一般需要上下文语境的帮助。如以实体词语“晋侯”为例,该词可以指称“晋成公”“晋文公”和“晋襄公”等,在语境“晋侯伐郑及郔”中“晋侯”表示“晋成公”;在语境“晋侯潜会秦伯于王城”中“晋侯”表示“晋文公”,“晋侯”歧义的消解与其出现的上下文语境密切相关。
(2)实体消歧的思路。在以上两类实体歧义消解中,本文主要关注单部典籍内部的实体消歧,这类实体歧义消解一般围绕和利用实体词所在的上下文语境,主要思路是将实体消歧转化为对实体词语所在语境的消歧。据此,同名异指歧义消解就是将出现歧义实体词的语境划分为多个类别,每个类别指称一个实体;而异名同指歧义消解就是将包含多个实体词语的语境合并为一个类别,使得它们指称同一个实体(见表2、表3)。上述思路可以通过构建规则的方式来实现,结合实体上下文语境特点,借助实体外部知识可以有效地实现实体歧义的自动消解。
对于同名异指歧义来说,由于古籍中同一时间段一般不会出现同名现象,因此可以借助实体语境的时间知识来消解歧义。如以“晋侯”为例,根据《春秋》,“晋景公”在位于鲁宣公到鲁成公时期,“晋昭公”在位于鲁昭公时期,“晋献公”在位于鲁庄公到鲁僖公时期,“晋成公”在位于鲁宣公时期,对于实体词“晋侯”而言,其指称的不同实体存在于不同的时间段中,且时间段相互之间不交叉。因此,可以直接通过标注“晋侯”所在语境的时间,根据上述时间段划分语境类别,实现实体词“晋侯”的歧义消解。同样的情况在《春秋经传引得》来说十分常见,不大的语料规模,以史实为主文本内容和以名词性指称词为主的歧义实体,使得这种实体歧义消解方法十分可靠。
异名同指歧义依然可以通过语境进行消解,方法以同名异指歧义的消解为基础,且需要借助实体百科知识。异名同指歧义的消解总体可以分为两个部分,以表3中实体词“晋文公”为例,首先需要借助实体百科知识得到“重耳”“晋侯”与“晋文公”之间的对应关系,并以此为基础获取“晋文公”的候选实体词及相应语境;接着,对于“晋侯”这类本身具有同名异指歧义的实体词,其相关候选语境还应该再进行消岐,消岐方法与上文方法相同。异名同指歧义消解时,一般选取最常见和通用的实体词作为消歧后的实体词,如“晋文公”“郑庄公”等,选取标准可以参考百科知识。
4 古汉语同名异指消歧规则初探
本文简单阐述了古汉语实体歧义的特点以及该特点下最合适的实体消歧方法,并提出了使用实体语境时间知识消解同名异指歧义的基本思路。本研究将以先秦古汉语实体歧义为例,通过细化和制定相关规则,结合典型实例,来验证该方法在消解同名异指歧义时的可行性和有效性。研究以《春秋经传引得》为语料,该语料包含了4695个人名实体词,共表示了1421个人物,正如本文所述,对于研究先秦古汉语实体歧义来说,该语料已足够充分。
4.1 《春秋》的时间表示
《春秋》使用鲁国国君的谥号加年份来表示年号,这些年号与公元纪年相互对应(见表4),据此,可以将《春秋经传引得》所有语境发生的时间以公元纪年的方式来表示,这样更有利于后续消歧研究中进行的时间比较,详见下例:
例2:{桓公十二年}
1 十有二年,春,正月。
2 夏,六月,壬寅,公會紀侯莒子盟于歐蛇。
左 十二年,夏,盟于曲池,平杞莒也。
4.2 語境的时间标注
完成语料中年号和公元纪年的转换之后,自动查找并标注《春秋经传引得》中每一个实体词头下,所有语境在原文中对应的时间,完成标注后的实体语境见例3所示:
例3:晉侯(參:晉襄公)
晉侯敗狄于箕 前627年
晉侯伐衞 前632年
晉侯朝王於温 前626年
公孫敖會晉侯于戚 前626年
晉侯疆戚田 前626年
晉侯及秦師戰于彭衙 前625年
晉侯禦之 前625年
公及晉侯盟 前614年
4.3 基于时间规则的两类同名异指歧义消解
标注了语境的时间之后,可以得到语境所属实体词的时间区间,如“晋侯(参:晋襄公)”的时间区间就是[前614年:前632年]。使用时间规则进行同名异指歧义消解需要满足一个要求,即同名实体词之间的时间区间不能交叉。本文以《春秋经传引得》为语料,该语料中的同名异指歧义实体均满足这一要求。根据实体歧义的数量以及实体语境的规模,同名实体不同指称下的实体时间区间有可能间隔较大,也有可能基本连续。对于前者,可以直接利用时间间隔进行歧义消解;对于后者,需要借助额外的时间知识帮助歧义消解。
(1)基于时间间隔的歧义消解。当实体歧义数量较少或实体语境规模较小时,歧义实体的时间区间间隔较为明显,利用这些间隔实现语境的分类,可以迅速实现同名异指歧义的消解。本文将以“赵孟”为例,详细描述这种方法。“赵孟”在《春秋》中有四个歧义指称,分别为“赵武”“赵襄子”“赵鞅”和“赵盾”,对“赵孟”所属的语境的时间进行标注之后,可以统计出每一年出现相关语境的次数(见表5),统计可知该实体词出现的年份并不连续,有时甚至跨度很大(见图2),如“赵孟”所属语境很鲜明地分为四个部分,即四个时间区间,这个四个时间区间也就对应了 “赵孟”所指向的四个不同的实体。语境出现次数随时间分布类似于“赵孟”的同名异指实体词,可以通过时间区间的间隔实现语境划分,从而实现歧义消解。
(2)基于时间知识的歧义消解。当然实体的歧义数量较多或实体相关语境数量较多时,很难从语境的时间分布中找出明显的时间间隔,这类实体歧义的消解还需要借助额外的时间知识。如以“晋侯”为例,该实体词在《春秋经传引得》中可以指向15个实体,从其出现的时间分布(见图3),可见由于歧义数量相对比较多,难以在语境时间分布上准确区分出时间间隔,此时想要根据时间区间和时间间隔进行准确的同名异指歧义消解十分困难。这种情况对于“郑伯”“齐侯”等实体词来说同样如此(见图4、图5)。
对于这一类语境时间分布较为复杂的同名异指实体词来说,需要借助外部知识来划分时间区间。根据鲁国国君年号的转换方式,可以同样对“晋侯”“郑伯”和“齐侯”等进行在位年份的转换。如以“郑伯”为例,其对应了14个实体的在位年份(见表6),根据表6的时间区间可以划分得到“郑伯”指向的14个实体的所属语境,从而完成对“郑伯”的歧义消解。该方法同样适用于“晋侯”“齐侯”这类表示诸侯的实体词,对于其他人名实体词,也可以通过类似的百科知识构建语境年份对照表,从而实现歧义消解。
综上可以看出,对于同名异指歧义实体来说,通过语境的时间间隔或实体相关时间知识构建规则,可以有效地消解歧义。在《春秋》这类编年体古籍中,语境时间的获取较为容易;而对于其他类型的古籍来说,可以结合机器学习的方法自动识别实体语境中的时间实体,并将之转换为可用的语境时间。实体相关的时间知识,可以从《汉语大词典》《春秋左传词典》为主的词典或百科中自动获取。基于规则的方法可以保证歧义消解的准确性,也可以为异名同指歧义的消解提供可靠的知识来源。
5 基于消歧实体的春秋人物概貌
消歧完成后得到的实体知识更加准确,以此为基础进行的实体知识挖掘和数字人文研究也将得到更可靠的结果。本研究对《春秋经传引得》中所有人名实体进行了歧义消解,并对消歧后的实体进行了计量统计、影响力分析和数据可视化呈现,从整体上描绘出春秋时期的人物概貌。
5.1 春秋人物异名解析
《春秋经传引得》中包含了4695个人名实体词,共表示了1421个人物,其中875个人物有两个以上的名称,占总数的61.58%,可见异名同指现象在春秋时期十分普遍。有超过188个(近30%)的人物有三个以上名称,超过87个人物有四个以上名称,这表明了该时期异名同指现象的普遍和复杂。异名同指现象实际上反映了春秋时期人物的成长和经历,如异名数目排第一的“士会”还有“士季、随会、随季、范子、范会、武季、随武子、范武子、会”等名称。其中“士会”表明了他父亲的“氏”和他自己的“名”;“随会、范会”是由于他被封于“随”和“范”之后以封地为氏;“士季、随季”表明了他在家族中的排行(四子);“武季、随武子、范武子”则是根据“谥号”对他的尊称。通过对“士会”异名的分析,可以发现他丰富的人生经历和较高的社会地位。《春秋》中异名数量较多的人物大多如“士会”一样有自己的封地和相应的谥号,在当时具有较高的社会影响力,人物异名统计相关数据也支持这一论断(异名数量排名靠前的人物大多是大诸侯和地位显赫的贵族)。因此从一定程度上可以认为,人物的异名数量越多,其人生经历越丰富,社会地位越高(异名实体分布的相关数据见图6、表7)。
5.2 春秋人物影响力分析
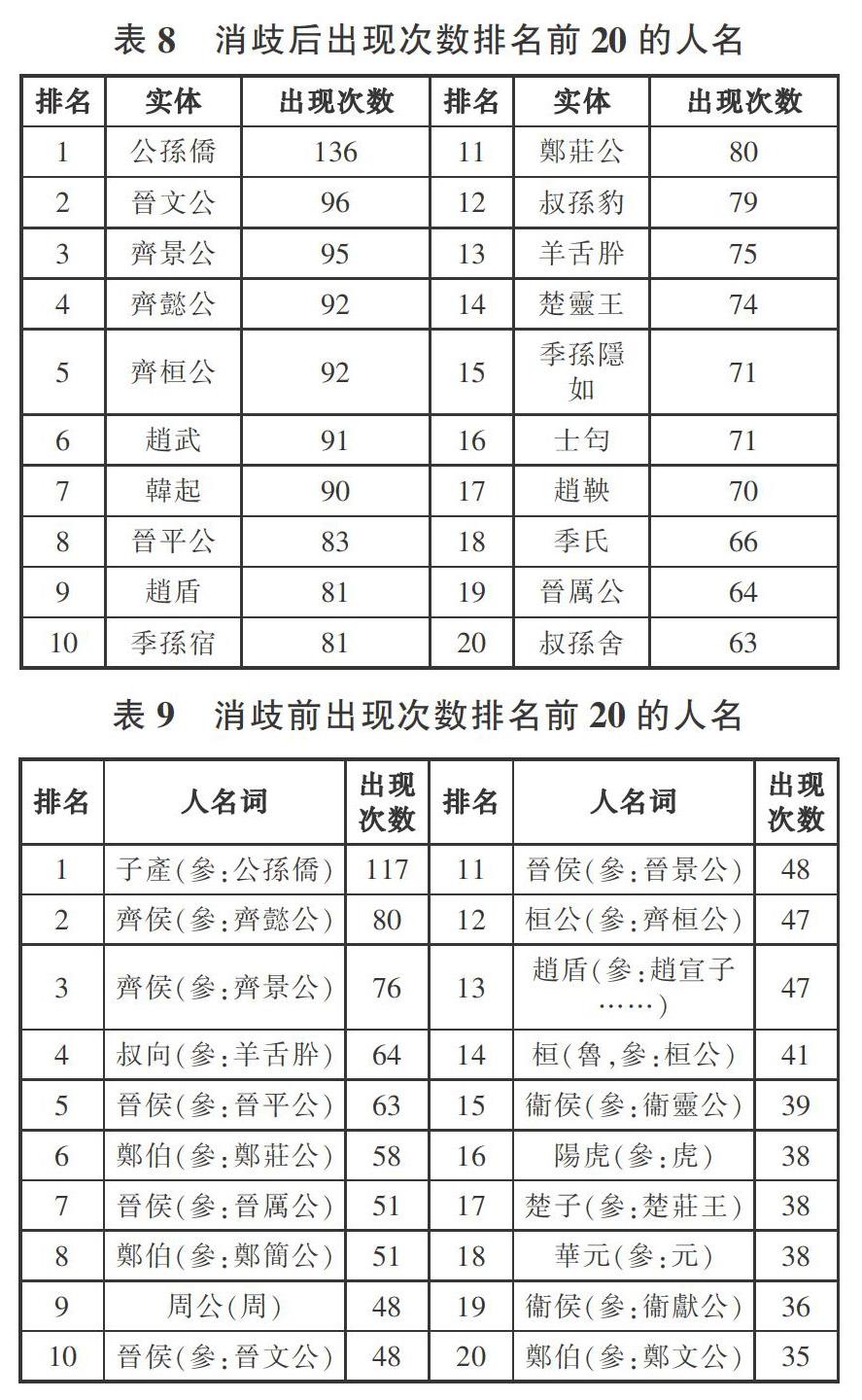
人物的异名数量可以看出其社会地位,但并不能准确反映他对时代的影响力。衡量一个人物影响力的高低,可以参考文献计量的思路,通过其在语料中出现的次数来计量,而这樣的计量必须基于消歧后的统计数据才能保证准确。根据实体消歧后的语料,可以统计得到《春秋经传引得》中人物出现次数的分布数据(见表8),将之与消歧前人物出现次数的分布数据(见表9)相比较,可以发现实体歧义消解对数字人文研究的重要影响。
对比分析表8和表9可以发现,绝大多数的人物排名出现了较大的变化,尤其是“晋文公、齐桓公”等消歧前排名并不靠前的人物,在歧义消解之后排名跃居前列,而这恰与他们在“春秋”时代的影响力相符,因此歧义的消解可以使得通过人物出现次数获得的影响力分析数据更加准确。具体来看,公孫僑(也就是子产)始终是出现次数最多的人名实体,无愧于其“春秋第一人”的称号;在众多诸侯中,“晉文公”消歧后的排名提高了很多,达到第2名的水平,符合其“春秋五霸”地位,“齊桓公”也同样如此,而齐国的三位君主排列3至5名,展现了他们强大的实力和对鲁国的影响力,除此之外,著名的“鄭莊公”也高居第11位,无愧其“春秋三小霸之首”的地位。除诸侯之外,其余的实体也都是“春秋”中重要的人物,其中“趙氏”非常显著,晋国大夫趙盾、其孙“赵氏孤儿”趙武、趙武之孙趙鞅均排名靠前,而与趙武关系密切的韓起的排名也很高,表明了“韓氏”在晋国的显赫,“趙氏”“韓氏”的重要地位也预示着春秋末期“三家分晋”的必然性。
根据消歧后人物出现次数统计数据,可以通过词云的形式进行可视化的数据展示,以对“春秋”中的人物有一个更为直观的了解(见图7),从图中可以看出实体的字号与该实体的出现次数有关,字号越大说明该人名实体出现次数越多,排名前200的人名实体均包含在该图中,该图可以看作“春秋”人物的一个缩影。
6 结论
对于以实体知识为基础的数字人文研究来说,知识的准确与否决定了相关研究结论是否可靠,本文以《春秋》中的人名歧义为例,一方面发现了歧义存在的普遍性和歧义消解的必要性,另一方面也验证了基于规则的方法在歧义消解问题中的可行性。本文通过人物异名数来考察其人生经历和社会地位,说明了消歧后的实体知识可以为古文数字人文研究提供新的研究视角;而通过对出现次数排名靠前人物进行的统计分析,本文也验证了消歧后的实体知识可以带来更加准确的分析结果。通过获取更大规模的消歧实体语料和相应的实体知识,可以期待更加丰富同时更加可靠的古文数字人文研究。
参考文献:
[1] 王东波,高瑞卿,沈思,等.面向先秦典籍的历史事件基本实体构件自动识别研究[J].国家图书馆学刊,2018,27(1):65-77.
[2] 范佳.“数字人文”内涵与古籍数字化的深度开发[J].图书馆学研究,2013(3):29-32.
[3] 欧阳剑.大规模古籍文本在中国史定量研究中的应用探索[J].大学图书馆学报,2016,34(3):5-15.
[4] 欧阳剑.面向数字人文研究的大规模古籍文本可视化分析与挖掘[J].中国图书馆学报,2016,42(2):66-80.
[5] Wacholder N,Ravin Y,Choi M.Disambiguation of proper names in text[C].In Association for Computational Linguistics,1997:202-208.
[6] Ravin Y,Kazi Z.Is Hillary Rodham Clinton the president?:disambiguating names across documents[C].In Association for Computational Linguistics,1999:9-16.
[7] Smith D A,Crane G.Disambiguating geographic names in a historical digital library[C].In Springer,2001:127-136.
[8] Bagga A,Baldwin B.Entity-based cross-document coreferencing using the vector space model[C].In Association for Computational Linguistics,1998:79-85.
[9] Pedersen T,Purandare A,Kulkarni A.Name discrimination by clustering similar contexts[C].In Springer,2005:226-237.
[10] Bekkerman R,McCallum A.Disambiguating web appearances of people in a social network[C].In ACM,2005:463-470.
[11] Han X,Zhao J.Structural semantic relatedness: a knowledge-based method to named entity disambiguation[C].In Association for Computational Linguistics,2010:50-59.
[12] Bikel D M,Castelli V,Florian R,et al.Entity Linking and Slot Filling through Statistical Processing and Inference Rules[C].TAC,2009.
[13] 線岩团,余正涛,洪旭东,等.基于特征加权重叠度的中文实体协同消歧方法[J].中文信息学报,2017,31(2):36-41.
作者简介:刘浏,男,南京农业大学信息管理学院讲师;王东波,男,南京农业大学信息管理学院教授;黄水清,男,南京农业大学信息管理学院教授;苏新宁,男,南京大学信息管理学院教授。
