
大数据环境下基于主客观赋权的数据质量评估方法研究
2020-12-15 08:37张文婷
科学技术创新 2020年36期
张文婷
(华北电力大学,北京102200)
随着互联网技术的普及,进入信息化时代,数据越来越成为公认的最有价值的资产,对于数据质量高低的研究也越来越成为人们孜孜不倦讨论的课题。数据质量的提升对于公司决策有着重大的作用,但是,由于数据的复杂性,影响因素太多,它们处于不同的层次,同时也具有不同的重要性权重,很难客观地评估数据质量。目前,针对数据采集信息系统中数据质量评估的方法大多是从主观层面得出,主观评价依赖性过强[1]。因此,针对质量评价体系的评价指标的构建、评价方法的研究等各个方面的不足,本文采用基于AHP- 信息熵的数据挖掘方法,通过挖掘隐藏在指标隶属度中的客观分类知识信息来定义权重[2]。按照数据质量评价指标在总评选指标中的重要性的不同,分离出决定性的指标维度,并且通过熵权法客观分析数据中隐藏的权重信息,本文通过实验验证了所提出模型的有效性,实现了采集的数据质量的精准有效评估。
1 数据质量评估方法背景
1.1 方法研究的必要性
在如今的大数据环境下,数据量十分庞大,数据包含的维度也较为复杂, 如果不能及时地采集到的数据进行实时有效的评估,在后续的工作中,依旧让脏数据参与工作,这对于领导决策、有着非常大的危害作用[2]。数据质量评估是一项很重要的事情,因为它对于发挥数据的商业价值有着非常重大的意义。目前,数据质量评价方法的实现主要有两类,一类是通过人工评价的方式,组成评价小组直接对其进行打分,但是,这种人工的方式仅仅适用于人数较少情况,若是人数较多,统计起来也同样费时费力、结果也有可能并不准确;另一种便是基于传统统计学的机器学习方法的评估,主要包括灰色理论、神经网络等,具有一定的表达能力和学习能力,但是考虑的因素过于简单,对于评估结果的精确性有一定的影响[3]。因此,受这些想法的启发,在传统统计学的基础上,本文对于这些方法做出了改进,基于层次分析法和客观熵权法对数据质量评估模型进行了深入的研究。
1.2 主客观赋权法
层次分析法是一种定性与定量结合的方法,它能够将我们所要研究的问题拆分成许多组成因素,并对于这些组成因素赋予不同程度的重要性比较值,根据相关关系及隶属关系分成不同的层次,转化为多层次决策型问题[4]。根据各影响因素的重要程度构造重要性矩阵,通过一致性检验便可使用其最终的权重结果。
而熵权法中的熵值本是评估系统无序程度的一个重要指标。在多指标权重的确定过程中,熵权法的思路是通过各个指标间的差异大小来求得权重值。若计算出的信息熵值较小,表明该指标的差异程度越大,在综合评价中起的作用也就越大,提供的信息越多,所偶得到的该指标的权重值也就越大[5]。在电力质量评价、医疗评估各方面熵权法都表现出了良好性能。
由于层次分析法(AHP)是根据专家经验构造重要性比较矩阵,经过逐层检验得到的主观权重值,受到主观想法影响较多,因此在此基础上,我们结合基本不受主观因素影响仅仅通过数据来判断的熵权法得到的客观权重值,将二者进行结合,能使各指标的权重值配比更加合理,对于数据质量的评估也更精确,同时也减少了人工的复杂性与干预程度。
2 模型及验证
2.1 本文提出的模型
为建立合适的数据质量评估模型,我们首先需要选定合适的指标,我们从准确性、完整性、依赖性三个角度出发,选取合适的指标。准确性(T1):数据语义是否准确(T11)、数据的表达语法是否准确(T12)、数据值是否准确(T13);完整性(T2):数据属性是否完整(T21)、数据值域是否完整(T22)、数据量规模是否充足(T23);依赖性(T3):数据值依赖性(T31)、数据格式依赖性(T32)、数据格式依赖性(T33)。
对于不同的信息系统,指标的贡献程度也有所差异。例如,各行各业对于数据的准确性要求是必然的,因此针对此属性我们需要进行详细的检测,必要时需预先设置好可参照库,但某些领域对于数据值之间的依赖性并没有提出过高的要求。因此,我们的模型首先采用(1)层次分析法计算权重值,对各层中的因素进行两两比较,构造出判断矩阵,我们计划选取有经验的专家构造重要性矩阵,使得我们的主观权重更加精确,得到权重值Wij;(2)熵权法。
(1)本模型对数据三个维度的情况进行统计,针对各层次各指标得到打分值Xij(表示i 层次j 指标的打分结果);
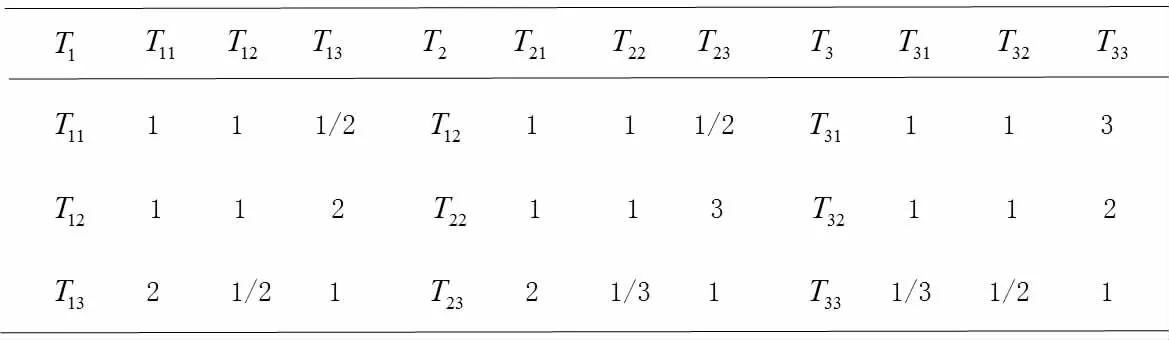
表1 多层次判断矩阵
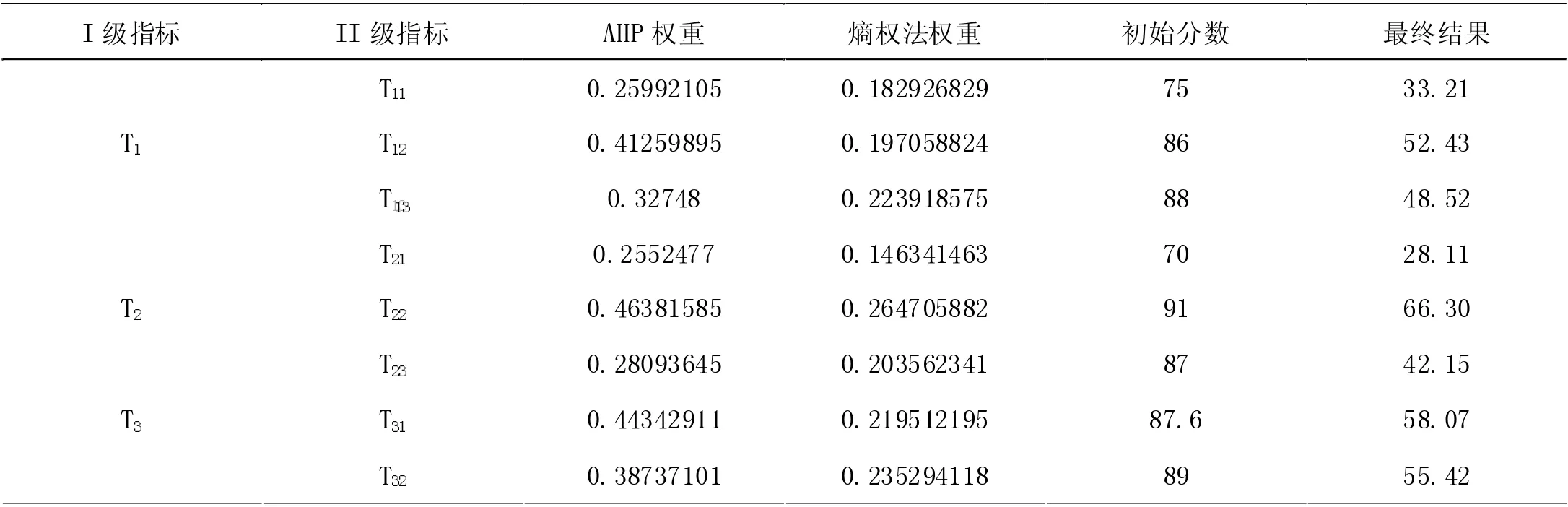
表2 AHP 求得各指标权重结果表
(2)根据公式(1)(2)分别计算指标信息熵Ei,信息冗余度Di

(3)计算指标权重值

(4)计算组合权重值

(5)根据(2)中统计得的各层次各指标分数与组合权重值计算最终得分。

2.2 实验结果及验证
以某地交通信息采集系统中的电能质量数据为实验对象,对其传输的数据进行评估,验证本文所提出模型的有效性。
我们首先构造多层次的判断矩阵如表1。
经过一致性检验,其CR<0.1,因此通过了一致性检验,我们得到各指标的AHP 权重值如表2 所示。
本文根据所设定的模型将主观权重和客观权重分别通过层次分析法和熵权法算出,并求得了综合权重与初始分数相乘,得到了各项指标的最终结果。从结果可以看出,我们的得分,并不完全依靠主观评判,也同时摆脱了过于依赖数据的客观结果,证明了本模型的有效性。
3 结论
本文通过主客观赋权的方法提出了数据质量评估模型,该模型适用于大多数的信息采集系统,本文以交通数据采集系统的数据为例,多层次地对采集到的数据进行了评估,以便于及时汇报其中的差错数据与脏数据,为后续数据的应用提供强有力的保证。同时本文所提出的维度尚有不足,希望随着时代的进步能够提出更精确有效的应用范围更为广泛的数据质量评估模型。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
选煤技术(2022年2期)2022-06-06
心理学报(2022年5期)2022-05-16
客联(2021年3期)2021-09-10
当代陕西(2020年17期)2020-10-28
奥秘(创新大赛)(2018年8期)2018-11-29
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
商情(2017年38期)2017-11-28
新教育时代·教师版(2016年47期)2017-04-27
