
融合时序文本与高阶交互拓扑的在线抗议预测
2020-12-15 04:55罗森林李东超吴舟婷潘丽敏吴倩
北京理工大学学报 2020年11期
罗森林,李东超,吴舟婷,潘丽敏, 吴倩
(1.北京理工大学 信息与电子学院,北京 100081; 2.国家计算机网络应急技术处理协调中心,北京 100094)
随着互联网的快速发展,推特、微博等社交媒体成为公众集中表达个人观点与情绪的主流媒介. 同时由于社交媒体具备平台开放性、资讯时效性且传播快速等特点,社交媒体容易被不法分子利用,严重危害国家政治安全和用户信息安全[1].
基于社交媒体的在线抗议预测任务包括抗议活动发生的时间、地点的预测以及用户抗议倾向的预测. 目前对抗议活动发生的时间地点的预测通常利用社交媒体产生的文本内容及时间戳[2]、hashtag[3]等结构化信息预测抗议活动发生的时间或地点,如EMBERS系统[3]. 通过预测抗议活动当天用户推文的抗议倾向性,能够帮助安全监管部门提前预知抗议活动参与者的规模,做出相应级别的预防措施.
社会学研究表明通过信息的流通,能够让那些本来就享有共同偏好的用户汇聚在一起,同时还改变了那些社会运动潜在参与者的偏好,让他们走出沉默,通过话语或行动表达诉求[4]. 如果用户在过去发表过抗议相关推文,那么用户将更有可能参与抗议活动,同时如果用户被抗议相关的推文@,该用户则更具备抗议倾向性[5];另外如果用户感兴趣的人发表了抗议相关推文,那么该用户的抗议倾向性就会得到加强[6]. 所以用户抗议倾向性既与用户发表推文内容及交互推文内容相关,也受用户的交互拓扑影响.
当前用户抗议倾向预测的方法主要利用用户发表推文内容及交互推文内容预测用户下一条推文状态[7-9],没有考虑用户间高阶交互拓扑对用户属性建模的影响. 因此引入网络嵌入方法对用户间高阶交互拓扑进行建模,网络嵌入是一种通过编码节点拓扑结构建模节点属性的方法,其中通过融合节点文本内容与交互拓扑的算法可提高节点分类效果. 然而,网络嵌入方法尚未用于抗议倾向预测任务. 同时,由于社交媒体信息迭代快,用户属性变化频率高,同一个用户的行为特点在一定时间段内会发生多次变化,用户属性的分析结果往往具有一定的时效性[10],所以用户推文信息的时序性对用户抗议倾向性也有重要的影响.
早期基于社交媒体的研究多集中于利用文本信息进行事件预测. Williams等[11]利用Facebook数据对美国总统大选中的候选人支持率进行预测. Bollen等[12]基于Twitter数据,分析用户集体情绪状态,预测美国道琼斯工业平均指数. Balanco等[13]从Twitter数据中抽取有价值的用户信息,预测世界杯锦标赛的比赛结果.
在线抗议预测是根据社交媒体信息,对未来发生的抗议活动的时间、地点或人物抗议倾向进行预测. 在线抗议预测近年来逐渐引起研究者的重视. Kallus[2]利用事件抽取技术从Twitter文本中抽取事件、实体、时间等特征,用于预测一段时间内发生抗议活动的概率. Muthiah等[3]基于新闻和社交媒体的文本信息,利用关键词过滤等技术提取抗议活动的关键信息,提出了一个可以预测抗议活动发生的时间、地点的EMBERS系统. Korolov等[13]提出用户参与抗议活动的状态变化分为四个阶段,并利用逻辑回归算法预测发生抗议活动的概率. Qiao等[14]基于隐马尔可夫算法提出了一个预测抗议活动是否发生的模型. Wu等[15]证实了抗议活动的发生与推文的数量变化有显著相关性. 这些对抗议活动发生的时间、地点进行预测的方法已经取得了不错的效果. 对人物抗议倾向性的研究也取得一定进展,Godin等[5]通过模拟用户之前发表推文的主题来预测用户下一条推文的特征. Kywe等[4]使用协同过滤的方法,将相似用户的推文内容结合,用以预测用户下一条推文的特点. Ma等[16]将用户的推文、时间信息与候选用户间的推文交互相结合,预测该用户下一条推文的状态. Ranganath等[6]基于几何布朗运动,建模用户发表的推文信息与交互推文信息对用户状态的影响,预测用户的下一条推文是否在宣称抗议.
交互拓扑信息是表示用户社交关系的重要特征,随着网络嵌入技术的发展,利用网络嵌入技术对交互拓扑中的用户节点进行向量化表示,成为获取用户交互拓扑信息的重要手段. Belkin等[17]提出利用欧氏距离度量两个节点的距离,并假设相连的节点距离相近,构建了Laplace特征表;Chen等[18]通过将不同节点的损失权重差异化,进一步改进了Laplace特征表方法. 随着神经网络技术的进步,深度学习技术也被引入到网络表示学习中来. Perozzi等[19]DeepWalk算法,充分利用随机游走序列的信息,应用Skip-gram模型学习节点的分布式表示;Tang等[20]提出大规模信息网络嵌入(large-scale information network embedding,LINE)算法,旨在处理节点间关系建模过程中的一阶稀疏问题,通过非直接相连节点的共同邻居刻画这两个节点的二阶相似度,挖掘了用户之间的深层次连接,丰富了交互拓扑. Tu等[21]提出上下文感知网络嵌入(context-aware network embedding,CANE)算法,在LINE算法基础上引入文本信息,并利用注意力机制关注用户间交互推文信息特征,生成用户向量表示. 当前算法只关注于用户之间交互推文的特征,缺失对用户本身文本时序差异性的关注,忽视了用户不同时间段产生的不同主题性文本内容对用户属性刻画的贡献度不一.
针对当前在线抗议预测对用户个人属性利用不充分的问题,提出一种融合时序文本与高阶交互拓扑的在线抗议预测方法,利用自注意力机制关注用户本身内容时序差异性对用户表征的影响,结合用户间交互推文信息特征建模用户文本向量表示,同时融合用户高阶交互拓扑信息,对用户节点进行向量化表示,并对其下一条推文的抗议倾向性进行预测.
1 融合时序文本与高阶交互拓扑的在线抗议人物预测方法
1.1 原理框架
方法原理图如图1所示,通过关键词筛选和专家判断,对用户最新一条推文进行抗议倾向性标注,得到正负样本用户集;利用用户推文信息和用户间交互拓扑构建用户表示向量. 文本信息的处理方式通过定义目标函数Lt(e),既关注用户自身推文的时序差异性,也学习了用户间交互推文信息特征对用户表征的影响;另外基于用户间交互拓扑结构,学习用户间高阶交互拓扑特征,构建目标函数Ls(e);结合Lt(e)和Ls(e),用户表示向量学习的目标函数构建如式(1)所示为
L(e)=Lt(e)+Ls(e).
(1)
对于用户u,经过模型训练得到用户文本表示向量ut和用户交互表示向量us,结合两种向量表示构成用户表示向量u. 基于用户表示向量,构建分类器,预测用户的下一条推文是否在宣称抗议.
1.2 时序文本表示建模
社交媒体话题种类丰富,更新迭代速度快,用户不同时间段发表的推文对于用户当前状态的判定会出现不同程度的影响,所以关注用户自身发表推文的时序差异性对于用户抗议倾向判定的影响十分必要.
自注意力机制在模型训练过程中通过学习用户推文的时序差异性,对不同时间发表的不同重要程度内容赋予不同权重信息[24]. 时序文本建模基于自注意力机制对用户推文内容进行处理,通过构建自注意权重矩阵,关注用户自身推文由于内容发表时序差异性对用户向量表示所带来的影响.
首先利用卷积神经网络(convolutional neural network, CNN)单元处理原始推文文本S=(w1,w2,…,wn),wi代表单词文本,利用looking-up层操作将wi表示成单词向量wi,得到推文文本序列S=[w1w2…wn]. 然后将文本序列输入到卷积层和池化层中,得到推文表示向量T′=[r1r2…rn]T,其中ri∈Rd,d为词向量维度,n为文本长度.
基于自注意力机制思想学习带有时序权重信息的推文文本表示,构建时序矩阵Aself∈Rd×d. 对用户推文内容T′进行处理,关注用户个人文本信息,学习用户推文内容的时序差异性,最终得到用户时序权重推文表示T,如式(2)所示.
(2)
通过时序文本建模方式对用户推文进行处理,得到每个用户k的文本表示向量Tk∈Rn×d,其中n是文本长度,即单词数量,d是词向量维度.
用户之间会根据交互对象的不同而产生不同的文本,所以需要建模用户间的交互推文信息特征. 首先构建注意力矩阵A∈Rd×d,对于一对用户u和v,根据时序文本建模方法得到对应的文本表示Tu和Tv,计算得到用户间的关联矩阵F∈Rn×n,如式(3)所示为
(3)
F矩阵的每一个元素代表着用户间文本单词与单词的交互权重分值,通过行池化和列池化操作得到Au和Av向量,如式(4)(5)所示为
(4)
(5)
(6)
最终,得到用户文本表示向量u′t和v′t,如式(7)(8)所示为
u′t=Tuau.
(7)
v′t=Tvav.
(8)
1.3 高阶交互拓扑建模
用户的社交网络包含丰富的特征信息,用户之间的一阶显性联系容易统计得到,但是用户之间的高阶隐性关联需要通过算法进行挖掘. 如图2所示,图中实线代表显性联系,虚线代表隐性联系,当用户与两个团体均有同等程度联系时,通过非显性连接用户之间的邻居用户构建隐性连接,分析该用户的隐含社交关系,从而判断该用户与抗议团体联系更紧密,与非抗议团体关联相对较弱. 通过使用LINE算法,对用户的隐含社交关系进行挖掘,通过保持用户之间的二阶相似性,构建高阶交互拓扑,得到用户的交互特征向量表示.
图中显性关系定义为一阶相似性,对于由边(u,v)连接的每对顶点,该边缘的权重wu,v表示u和v之间的一阶相似性,如果顶点之间没有观察到边缘,他们的一阶相似性为0. 对于每个无向边(u,v),定义顶点u和v的联合概率分布为
(9)
(10)
图中的隐性关系定义为二阶相似性,二阶相似性指的是在网络中一对顶点之间的接近程度是其邻域网络结构之间的相似性. 二阶相似性假定与其他顶点共享邻居顶点的两个点彼此相似.
数学上,让pk=[wk,1…wk,|V|]表示k与附近所有其它顶点的一阶相似性,那么k和h之间的二阶相似性由pk和ph之间的相似性来决定. 如果没有一个顶点同时与k与h连接,那么k和h的二阶相似性是0. 对于每个有向边(u,v),定义顶点v是顶点u的邻居的概率:
(11)
式中:|V|表示顶点集合;v′和v″分别为表示顶点本身和其他顶点的邻居时的向量.
另外,二阶相似性的目标函数为
(12)
1.4 目标函数
根据前面所述,定义优化目标函数如下
L(e)=Lt(e)+Ls(e).
(13)
Ls(e)=wu,vlnp2(v′s|u′s).
(14)
Lt(e)=αLtt(e)+βLts(e)+γLst(e).
(15)
Ltt(e)=wu,vlnp2(v′t|u′t).
(16)
Lts(e)=wu,vln p2(v′t|u′s).
(17)
Lst(e)=wu,vlnp2(v′s|u′t).
(18)
模型的目标是通过最大化以上目标函数L(e),获得用户u基于文本的向量表示u′t和基于交互拓扑的向量表示u′s,然后将两种向量表示结合作为用户节点向量表示为
u=u′t+u′s.
(19)
但是直接优化以上目标函数的代价太高,会消耗大量的计算资源,所以实验过程中采用负采样的方法对目标函数进行了修改,如式(20)所示,
(20)
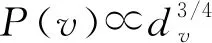
利用训练得到的用户表示向量u进行抗议倾向性预测,判断用户是否为抗议人物. 利用公式(21)计算得到用户抗议性倾向预测值y′,与真实标签进行对比,计算预测准确率.
y′=softmax(wu+b).
(21)
2 实验分析
2.1 实验数据
数据来源于Apollo Social Sensing Toolkit提供的开放数据,数据集中包括大约1 800万条推文,包含172 388位用户.
数据集收集于2011年1月31号到2011年2月18号的埃及革命期间,该时段埃及爆发了一系列的街头示威、游行、集会、罢工等抗议活动. 社会学研究表明,埃及革命抗议活动期间,社交媒体起到了积极的推动作用,埃及革命也被称为“推特革命”[23-24]. 该数据集包含了用户在埃及革命期间发表的推文,同时数据集中包含了大量用户相互@的信息,能够还原抗议期间用户之间的社交联系.
实验过程中,选取5 d作为一个用户的状态持续时间,比如使用1月31号到2月5号期间的推文,根据设定的关键词对用户该时段的最新一条推文进行初步筛选,再通过人工判断该用户的最新一条推文是否在表达抗议,最终完成数据集的标注处理,数据处理流程如图3所示.
最终,实验过程中使用到的数据情况如表1所示,其中正样本代表有抗议倾向的用户样本,负样本代表没有抗议倾向的用户样本.
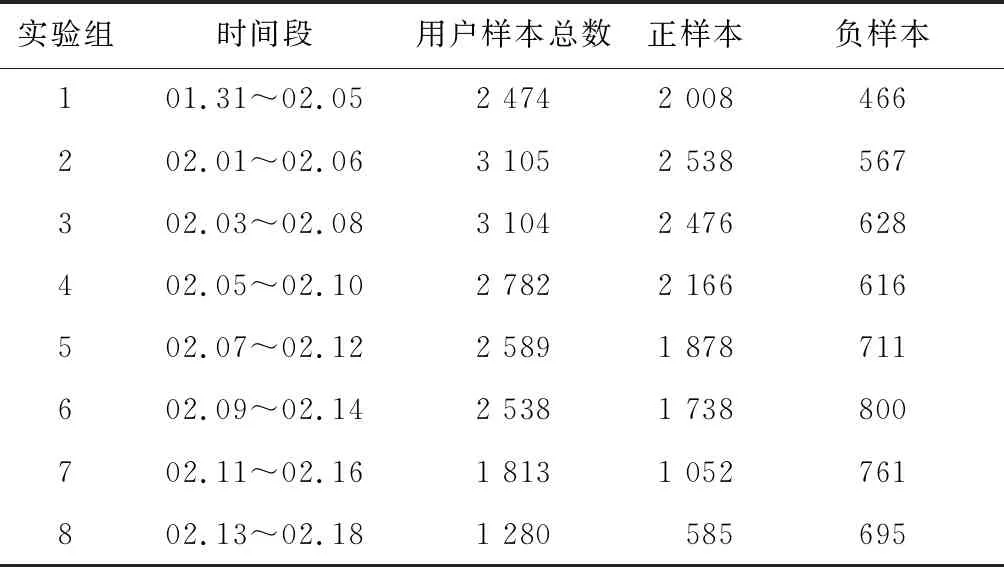
表1 实验数据Tab.1 Experimental datasets
2.2 评价方法
实验采用准确率(Rac)对结果进行评价与比较,准确率是实验过程中常用的评价标准,该评价方法综合考虑了实验过程把正类和负类分对的情况,具体计算方法如公式(22)所示.
(22)
式中:NTP为将正类预测为正类的样本数目;NTN为将负类预测为负类的样本数目;NFP为将负类预测为正类的样本数目;NFN为将正类预测为负类的样本数目.
2.3 抗议倾向性预测
为了验证引入融合时序文本与高阶交互拓扑的方法对抗议预测的实验结果带来的积极影响,与当前先进算法进行对比. 同时为了证明算法的普适性,分别在不同时间段的数据集上进行对比实验. 选用5 d为时间窗口,该时段内的信息量能够代表用户的最近状态. 利用时间窗口,将原始数据集切分为8个子数据集,以数据集内最新一条推文对用户进行标注,以80%的数据作为训练集,10%作为验证集,10%作为测试集. 为了公平,所有对比算法在实验过程中均设置用户表示向量的维度为200,实验结果如表2所示.

表2 用户抗议倾向预测准确率Tab.2 User protest tendency prediction accuracy
由实验结果可以看出,在多数数据集上,融合时序文本与高阶交互拓扑的在线抗议预测方法取得了良好的实验效果,优于当前先进算法. 实验结果说明,通过时序文本建模方法对用户个人推文信息进行表示,能够学习到用户推文时序差异性对用户属性建模的影响,同时通过融合高阶交互拓扑信息,能够还原用户真实社交情况,有利于用户属性建模,能够提高抗议人物预测准确率. 另外,随着时间推移,预测的准确率总体呈下降趋势. 原因是在抗议活动的尾声,用户对抗议活动的关注度减弱,推特对抗议活动的话题讨论不再集中,使得推特中的推文信息噪声增多,导致预测准确率下降.
2.4 维度特征实验
为了评估不同维度用户表示向量对在线抗议预测性能的影响,利用算法训练不同维度的用户表示向量,对用户的抗议倾向进行预测,并在前4组数据集上进行实验,实验结果如图4所示.
由实验结果可以看出,当用户表示向量的维度设置为200时,预测准确率最高. 特征维度设定为300时,预测结果波动较小,设定为400时,整体波动较大. 同时,由实验结果图可以看出,当维度设置小于400维时,特征维度不同造成的最终结果差异不大,准确率最多相差一个百分点.
2.5 抗议规模预测
为了表明本文提出的方法对抗议活动规模预测具有直观的借鉴意义,利用本文提出的方法对抗议活动各时段用户的推文状态进行判断,并统计预测的抗议用户数量和Twitter中明确宣称抗议的用户数量,结果如图5所示.
由实验结果可以看出,本文提出的方法预测的抗议规模与线上真实抗议规模有很高的契合度,在第二组实验中,线上真实抗议规模和预测抗议规模都达到顶峰,这与现实世界中该时段集中爆发抗议活动的表现一致. 同时,从图中可以观察到,随着抗议活动接近尾声,抗议分子的数量也在规律性的下降,说明随着时间推移,民众的抗议情绪也在消退. 所以本文提出的方法能够协助安全监管部门感知、预测、预警未来抗议活动的规模状况,主动作出相应级别的决策反应,显著提高社会治理能力,保障国家安全.
2.6 案例分析
为了更好地说明算法的有效性,选取数据集中的正样本用户Indiffirent,分析其在抗议活动期间的交互情况和推文内容. 该用户在抗议活动期间的交互情况如表3所示,交互用户users代表用户Indiffirent@过的用户们,用户标签代表其中一个用户u的标签属性,1代表正样本,0代表负样本,交互次数是用户Indiffirent与各个用户u互相@的次数,比如Indiffirent和marwame 之间相互@了1次.u与正样本用户交互次数代表用户u的交互过程中,正样本用户所占的次数.
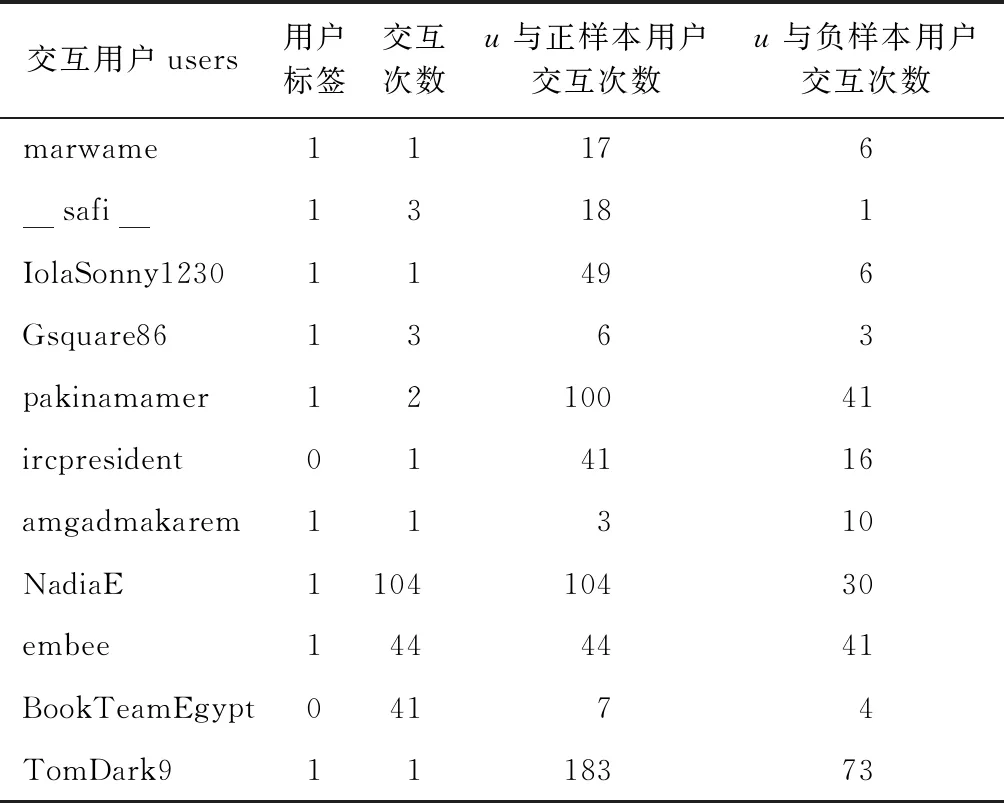
表3 正样本用户Indiffirent交互情况说明Tab.3 Positive sample user Indiffirent interaction description
从表3中可以看出,正样本用户Indiffirent在抗议活动期间直接交互的用户多数正样本用户,这是该用户的一阶拓扑特性. 另外,所有交互用户users的互动过程中,正样本的比例远高于负样本的比例,这是用户Indiffirent的高阶拓扑特性. 从现实世界的交互情况可以看出,算法构建的高阶拓扑结构能够深度构建用户交往圈,完善用户属性建模.
用户Indiffirent在抗议活动期间发表的推文内容如表4所示,从推文内容可以看出,该用户在抗议活动初期只是关注于抗议活动进展,随着时间推移,该用户开始在推文中出现煽动网络用户去参加抗议的内容. 所以,在抗议活动初期,该用户并不具备抗议倾向,但是在预测的节点,该用户已经变成了具有抗议倾向的抗议分子,所以用户推文内容的时间差异性对用户抗议属性的判断起着重要的作用.

表4 用户Indiffirent推文内容Tab.4 User Indiffirent tweet content
3 结 论
针对在线抗议预测中缺少对用户自身推文时序差异性及交互拓扑的关注,从而影响抗议预测准确率的问题,提出了一种融合时序文本与高阶交互拓扑的在线抗议预测方法. 该方法考虑用户自身推文时序差异性对用户属性建模的影响,通过引入自注意力机制,学习用户自身推文内容时序差异性的权重矩阵,建模用户时序推文表示,再结合用户间交互推文信息特征构成用户文本表示向量,然后融合用户高阶交互特征向量共同构建用户特征向量,最后基于用户特征向量预测其下一条推文是否在宣称抗议. 实验结果表明,在多组实验数据集中,实验效果优于当前先进算法,准确率最高能达到93.9%. 该方法融合时序文本与高阶交互拓扑,能够有效提升在线抗议预测的准确率,对抗议规模的预测有直观的借鉴意义. 将来的研究可以在以下三方面进行:①在线抗议中心人物判断;②在多地区数据集上证明本方法的适用性;③线上抗议活动演变趋势预测.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
南风(2020年8期)2020-08-06
音乐天地(音乐创作版)(2020年2期)2020-04-18
北京航空航天大学学报(2019年9期)2019-10-26
福建基础教育研究(2019年7期)2019-05-28
数学学习与研究(2018年15期)2018-11-12
上海师范大学学报·自然科学版(2018年3期)2018-05-14
