
多策略融合的微博数据获取技术探究
2020-12-09 06:52张辉周成祖
网络安全技术与应用 2020年12期
◆张辉 周成祖
(1.北京市公安局网络安全保卫总队北京 100000;2.厦门市美亚柏科信息股份有限公司福建 361008)
社会网点与传统的互联网站点有所不同,无论是微博,还是人人网,都是为了满足用户的需要运行的。社会网点主要的资源是用户,一个用于将自己个人的状态与其他的用户分享,每个人所呈现出来的状态有所不同。为微博作为社会网站,其主要的作用是传播公共信息,其传播效率是非常高的,可以做到实时传播,可以使得整个的网络在短时间内被引爆。所以,微博中信息是非常值得采集的,特别是的用户信息、用户所发布的信息以及用户之间所建立的关系网等等方面的信息都要采集。现在微博技术已经成熟,在平台上采集数据信息是可行的,确保实验数据更加集中,所获得的数据具有权威性[1]。与国外的微博相比较,中国的微博出现时间短,虽然借鉴了国外的一些微博平台,而且也将一些新技术引进来,但是,API接口没有完全开放,就会出现信息采集效率不高的问题,导致覆盖性差不是很好。
1 相关技术的发展情况
移动终端的发展速度不断加快,我们迎来了大数据时代,各种数据呈现出指数增长态势,每一条数据中都所涵盖的信息都有一定的价值,还包括关键信息,诸如用户的虚拟身份账号、用户的手机号捆绑身份证号以及银行卡号等等。如果将这些数据收集起来存储在数据库中,就可对用户的需求全面了解,这也是大数据所发挥的重要价值[2]。在进行数据提取中,由于数据提取方法存在特殊性,特别是自适应匹配和可变滑动窗口的数据,要将其中有价值的数据信息提取出来,就要运用自适应匹配算法,所提取的数据信息才能有较高的精准度,如果采用可变滑动窗口算法,可以比对原始数据,即便不知道属于那种类型,也可以通过循环比对,直到获得有价值的数据。采用这种提取方式,被漏提的有价值数据所占有的比例减少,大数据分析定位能力有所提升,对于核心线索能够快速准确定位。
2 数据提取技术的不足之处以及改进方案
(1)数据提取技术的不足之处
由于原始数据有很多,而且数据的结构非常复杂,从当前的数据提取方法来看,主要是采用模板方法提取或者采用正则表达式提取有价值的数据。这些数据提取方法虽然存在优势,但是也有诸多的不足。主要体现在如下方面。
其一,在数据的匹配通常应用单一的模板,或者采用正则表达式,进行匹配,如果是在复杂特征场景下的数据,要将有价值信息提取出来是存在一定的难度的。
其二,根据数据分析所获得的结果对于数据匹配的范围进行分析,从中能够认识到,进行匹配的数据往往是每行所呈现出来的原始数据,或者对特定范围内所读取的数据匹配,而起局限于原始数据的匹配。
其三,如果数据分布在不同的范围内,有价值的数据就不能用这种方法提取出来[3]。
(2)改进方案
对于数据提取所存在的不足之处,需要采取有效的措施解决,所采用的提取方法是,采用自适应匹配算法将自适应匹配提取出来,采用可变滑动窗口算法提取可变滑动窗口的数据,可以将更多有价值的数据信息提取出来,可以提高数据提取的准确率,大数据技术得以充分利用起来[4]。
采用这种方法提取数据,不同的数据匹配方法,采用自适应匹配算法可以获得良好的效果。具体操作中,将类型不同的原始数据动态调整,能够将更多有价值的数据提取出来,而且保证数据提取的准确率。
属于不同的数据匹配范围,在数据提取的时候使用可变滑动窗口算法,可以循环匹配特征引擎以及原始数据内容,将有关的记录放到内存中,组合附近匹配结果,有价值的数据尽管属于不同的类型,也可以提取出来[5]。
3 技术方案
(1)提取的数据结构
要提高数据分析效果以及数据提取能力,可以发挥分析程序的作用,使用提取引擎将有价值的数据信息提取出来,将可变滑动窗口充分利用起来,对于所属类型不同的数据信息提取。在数据提取的过程中,还在特征规则库和数据块库的基础上展开(表 1:特征规则库;表2:数据块库)。
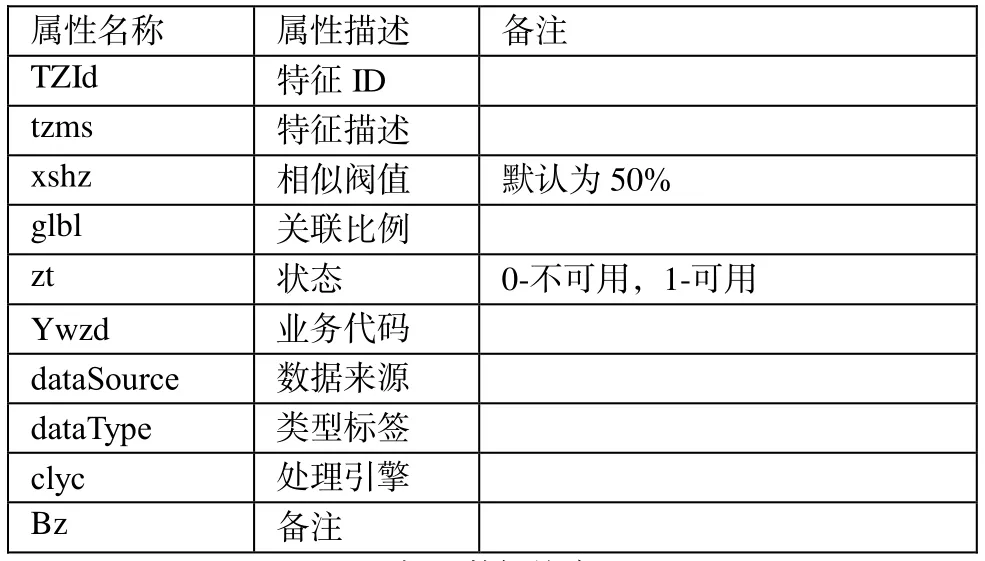
表1 特征规则库
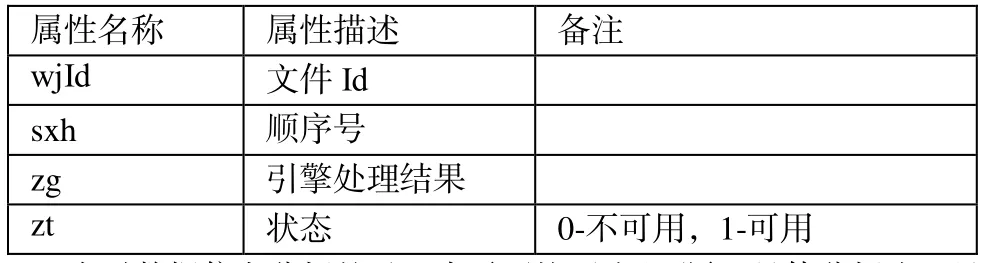
表2 数据块库
在对数据信息分析的过程中需要按照流程进行,具体分析流程见图1。原始数据量非常大,要从中将有价值数据信息提取出来,就需要将相应的场景建立起来[6]。本研究所采用的数据提取技术是发挥自适应匹配算法和可变滑动窗口算法,如果数据为已知类型,使用自动匹配提取引擎就可以将有价值信息提取出来, 不仅提取的速度快,而且精确度高。对于不同类型的数据采用多种提取,比如在运用引擎循环方法的时候,就可以将某一特征的数据信息提取出来,这样,有价值的数据信息就可以准确地被提取出来,大数据分析能力提高,对于核心数据的定位能力也加快[7](图1:数据信息分析流程)。
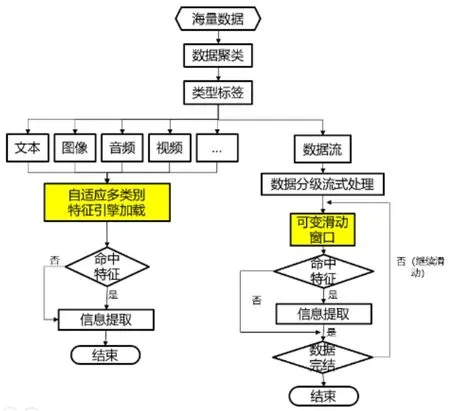
图1 数据信息分析流程
(2)提取数据的方案
采用这种数据提取方法所获得的有价值信息更多。对这种方法进行分析需要使用模型。
使用自适应匹配算法的时候,通常原始数据的格式比较复杂,其复杂特征通常超过两个,在一个文件中很有可能会涵盖多个特征,诸如视频特征、音频特征、图像特征和文本特征等等。如果特征匹配方式比较单一,就会降低执行效率,会存在数据提取不全的问题,运用概率分布算法,对于特征不同数据可以计算,即便处于不同业务场景,也会有同时出现的概率,采用自动匹配的方法对引擎处理,使得复杂特征数据中提取有价值数据的效率更高[8](图2:自适应匹配方法提取数据需要遵循的流程)。
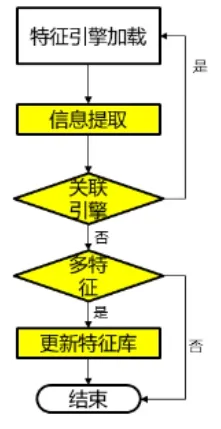
图2 自适应匹配方法提取数据需要遵循的流程
在对信息进行提取的时候,需要依据数据聚类标识的类型标签,还要结合特征规则库,将相应的特征处理引擎Cn予以调用,识别引擎之后返回Cn,将结构数据提取出来。
运用关联引擎算法,就是在相同业务场景中,数据类型相同的情况下,包含的特征有较大概率一样,所以执行达到设置阀值,且去掉关联比例为 0的关联引擎,就可以较低资源代价提取出更多的有价值数据。
算法描述:如果特征规则库中Cn有关联比例已经超过引擎Cm,即其甚至阀值的25%,就可以将Cm调取,提取数据;如果一些新特征引擎与Cn没有关联性,或者特征引擎与Cn之间的关联性介于5%至25%之间,比对特征;如果与Cn之间的关联比例是0%-5%的特征引擎,则不需要进行比对[9]。
采用合并关联引擎算法将特征处理引擎调用,所获得的操作结果可以看作是最终的结果集,将所获得的数据信息存储在数据库当中。
应用可变滑动窗口算法,就是从海量数据流中提取有价值数据,具体而言,是通过运用数据块标识的方法、特征模糊匹配的方法以及可变滑动窗口的方法,将有关联的数据块进行合并之后提取,提取效率提高了,而且保证了准确性[10](图3:可变滑动窗口提取流程算法的运行流程)。
数据块:对数据流的内容进行分析,明确前1K和最后1K是可以截取的内容,与数据流的长度结合起来,对MD5值予以计算,所获得的结果就是数据流的唯一标识 ID,在分块的时候,每次 10000行的频率都要按照规定的顺序操作,数据集合S就能够获得,在数据块表中存储标识ID存储,还要将顺序号编号。
特征匹配:循环遍历数据集合 S,使用特征引擎充比如集合 Sn的特征要素,计算Sn的特征要素与特征规则库之间所存在的一致性,如果从吻合度到设置阀值超过50%,就要将滑动窗口启动,实施特征比对。
滑动窗口:按照数据流标识ID和顺序号,将各个数据集合Sn合并,将下一个数据集合Sn+1以及上一个数据集合Sn-1都纳入其中,就可以形成Mn,此为新的数据集合,将特征引擎合理运用,对Mn的特征要素进行比对,将Mn的特征要素与特征规则库之间的吻合度计算出来,即计算出upSinilarity,如果两者之间的吻合度upSinilarity计算结果是“算结,就可以进入到下一个环节,即信息提取环节,如果吻合度没有达到“就可,就意味新的数据集合Mn还需要继续合并,将Sn-2和Sn+2都结合起来,如此循环往复地执行。
信息提取:在提取信息的时候,需要将特征提取引擎充分利用起来,提取新数据集合Mn中的有价值信息,保存结果。
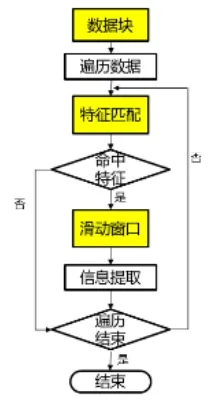
图3 可变滑动窗口提取流程算法的运行流程
4 结束语
通过上面的研究可以明确,现在的互联网环境中,信息挖掘已经成为重点研究的问题。在对微博数据信息的挖掘技术分析中,需要考虑网络挖掘技术的应用,做到全面采集,对于所采集的方法全面了解,予以分析,掌握用户的个人信息以及用户关注信息,并对垃圾信息有效处理,提高信息的价值。
猜你喜欢
钢管(2022年2期)2022-11-28
物联网技术(2020年12期)2021-01-27
房地产导刊(2020年12期)2021-01-14
人民交通(2020年4期)2020-04-16
电子制作(2019年10期)2019-06-17
意林(绘英语)(2018年1期)2018-04-28
商周刊(2017年22期)2017-11-09
汽车零部件(2017年4期)2017-07-12
教学月刊·中学版(教学参考)(2016年5期)2016-06-14
汽车与新动力(2015年1期)2015-02-27
