
基于Linux的多核实时任务调度算法改进
2020-12-08 03:15陈国良朱艳军
计算机测量与控制 2020年11期
陈国良,朱艳军
(武汉理工大学 机电工程学院,武汉 430070)
0 引言
随着计算机的发展,实时调度被广泛应用于实时性强的众多领域,如电子商务、交通管制、航空航天等,要求操作系统能够及时高效地处理多任务的运行。在该领域中,抢占式调度方式被普遍使用,然而抢占多任务时往往会增加内存的总开销和浪费CPU的带宽。
实时调度算法主要有RM(Rate-Monotonic)调度[1]、EDF调度[2]、LLF调度[3]等,其中EDF调度算法从Linux-3.14版本开始加入调度策略。RM与EDF算法在单核方面调度性能最佳,但在多核调度中存在Dhall效应,即存在正规化资源利用率总和任意接近于0的任务集不可调度。Linux中可以通过区域划分的方式避免Dhall效应,但需要人为地划分任务允许运行的CPU核。LLF算法可以规避Dhall效应,其根据任务紧迫程度来决定实时任务的调度顺序,任务松弛度越小表示任务越紧急,但当同一就绪队列中两个任务的松弛度比较接近时,可能会发生任务之间的频繁抢占。文献[4]提出使用SchedISA调度集,将处理器核心分组实现实时任务与非实时任务在不同的核心执行,来提高EDF调度实时性。文献[5-6]提出在就绪队列中在没有松弛度为零的任务时,不抢占当前任务,以此来降低任务上下文切换频率,减小系统开销。文献[7]提出了LLF与LMCF(最低内存消耗优先)相结合的实时调度算法,当所有任务都相对截止期限松弛度不为0时,从LLF调度切换到LMCF调度。文献[8]提出在SCHED_RR调度策略与完全公平调度策略结合,依据任务权重参数来分配时间片大小,不能保证任务在期限内完成。其中,文献[4]和[9]均通过内核分组的方式提高EDF算法的调度性能,但在多核处理器中EDF算法相比LLF算法较差。文献[5-7]均是在LLF算法的基础上作出了相应改进,但在任务集可调度的前提下,同一就绪队列中出现多个等待任务的松弛度同时减为零时,任务可能不能在期限内调度执行完。
针对以上问题,下文基于现有Linux内核中的EDF调度算法实现原理,对传统LLF调度算法提出改进,主要通过减小上下文切换次数以及松弛度的计算,在避免Dhall效应的情况下最大程度减小了系统开销。下文描述基于以下假设:
1)系统中只有一个处理器;
2)在执行状态下,系统中每个任务的所有部分都可能被剥夺执行处理器的权力;
3)所有任务之间相互独立,并且无序;
4)任何任务都不能自己挂起。
1 Linux实时调度问题
实时任务是指任务执行能在截止期限内完成,按照任务周期可以分为周期性任务、偶发性任务和非周期性任务[10]。对于偶发性与非周期性任务,其周期为相邻任务之间到达时刻的最小时间间隔,所以一般使用任务运行时间、截止期限、周期来描述一个实时任务。在Linux内核中实时任务主要通过DL调度类创建,与其他调度类相比具有更高的优先级,是基于EDF调度算法实现。实时任务集只有在可调度的情况下才能在满足期限约束,因此有如下定义。
定义1:假设M个周期性实时任务运行在N个CPU核的处理器上,每个任务的处理时间是Ci,周期时间是Pi,1≤i≤M。若任务利用率总和不超过N,则任务集可调度,即:
(1)
EDF是一种基于截至时间最短优先调度的算法,每一个实时任务包含3个参数:WCET、D、P,其中WCET(worst-case execution time)是任务在最坏情况一个周期运行的时间,D是相对截至期限,P是周期时间,因此实时任务可以表示为(WCET,D,P)。在Linux内核中,EDF属于全局调度,任务可以在任意CPU核上执行,必要时进行核间迁移,提高了多核CPU的整体利用率。绝对截止期限等于相对截至期限加上CPU墙上时间,任务按绝对截止期限的大小排列,系统总是选取截止期限最小的任务运行。
例子E1:假设在M个CPU上,有M+1个实时任务需要运行,任务描述如下:
第一个任务T1=(P,P,P);
剩余M个任务Ti=(e,P-1,P-1).
其中e是具有任意小的最坏情况任务运行时间,一次调度就能运行完。在某一时刻t0这M+1个任务被同时激活,因为第一个任务的截止期限等于t0+P,而后面M个任务的截止期限都是t0+P-1,按照EDF调度规则,后面M个任务会优先在M个CPU上调度,而第一个任务需要等待时间e后才能被调度,执行完任务1后的时刻位于(t0+e+P),超过了其截止期限P,如图1所示。但如果能在最开始分配一个CPU给任务1运行,那么M+1个任务都能在截止期限内运行。
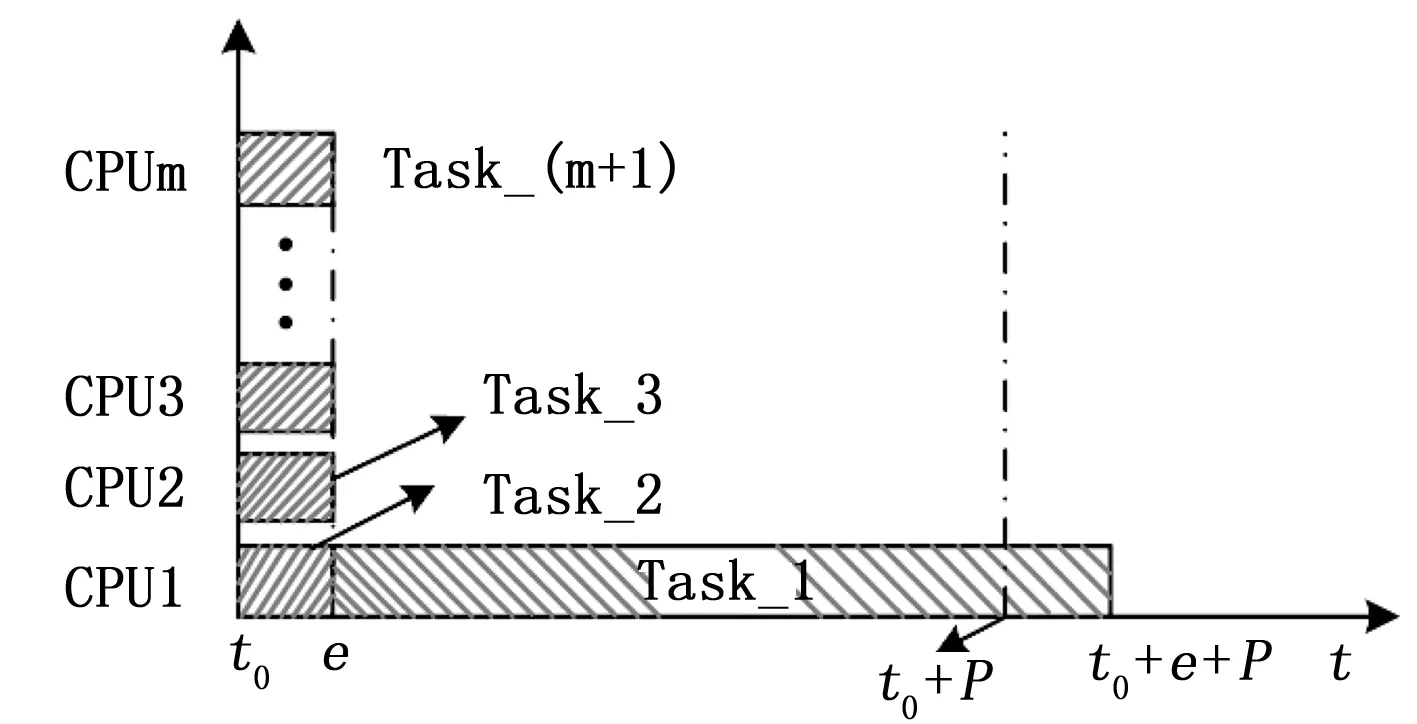
图1 Dhall效应
2 实时调度策略
在多核处理器系统中,LLF调度比EDF具有更好的调度性能[7]。LLF算法一定程度上可以解决多核中出现的Dhall效应,任务加入就绪队列时松弛度S=D-WCET,如果得不到及时调度或任务已经运行了一部分时间,松弛度S=绝对截止时间-当前时间-任务剩余运行时间。其中,松弛度最小的任务获得优先调度,当松弛度为0时任务立即被调度;当出现两个任务的松弛度相同时,按“最近最久未调度”原则调度。那么,例子E1中的(M+1)个任务的松弛度分别是:
S1=0,Si(i=2,3,...,m+1)=P-1-e
按松弛度最小的调度顺序,任务1最先得到调度,在截止期限内(M+1)个任务都得到了调度。任务调度顺序如图2所示。
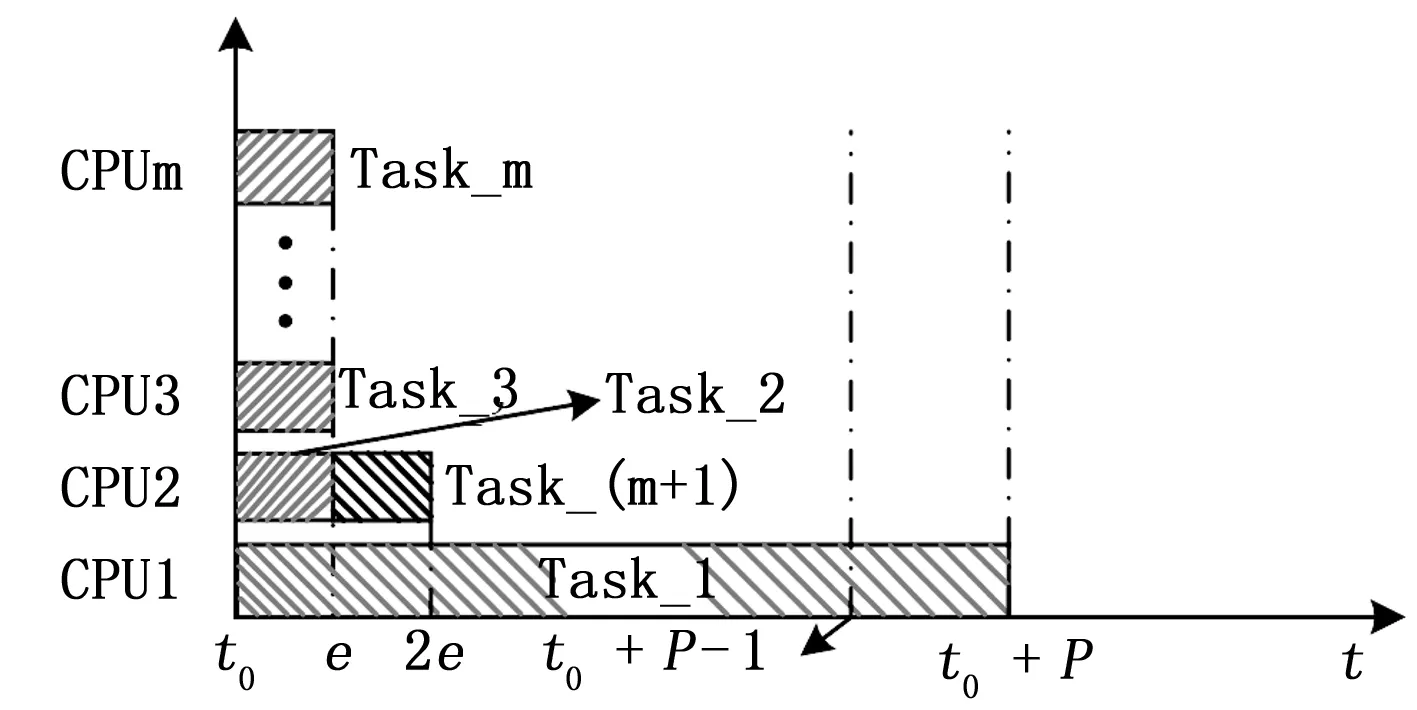
图2 改进后的调度顺序
最小松弛度优先调度在多核情况下仍然不是最优的调度算法,当同一就绪队列上两个任务的松弛度比较接近时,会发生频繁的上下文切换;同时,每次tick周期到来都需要更新就绪队列中任务的松弛度,当系统中实时任务较多时,计算量相对较大。鉴于以上问题,提出以下改进方法:
1)只有当任务被激活加入就绪队列前或当前任务运行完触发主调度器时,更新该CPU就绪队列中所有任务的松弛度;
2)在每个tick周期仅更新待运行任务中松弛度最小任务的松弛度;
3)没有任务被激活时,直到有任务的松弛度为0或当前任务运行完,否则不发生任务切换;
4)当有任务被激活或需要从就绪队列选取下一个待调度的实时任务时,考虑任务抢占或交换相邻松弛度任务的调度顺序。
以上方法1)和2)用于减小松弛度计算,方法3)、4)用于减少任务上下文切换次数,其中方法1)、2)、3)易于实现,为了讨论方法4),在实时任务集可调度的条件下设计如下例子E2:在同一CPU就绪队列中有3个任务被同时激活,如下:
T1=(0.05P,0.5P,0.5P)
T2=(0.05P,0.5P,0.5P)
T3=(0.6P,P,P)
松弛度分别是:
S1=S2=0.45P
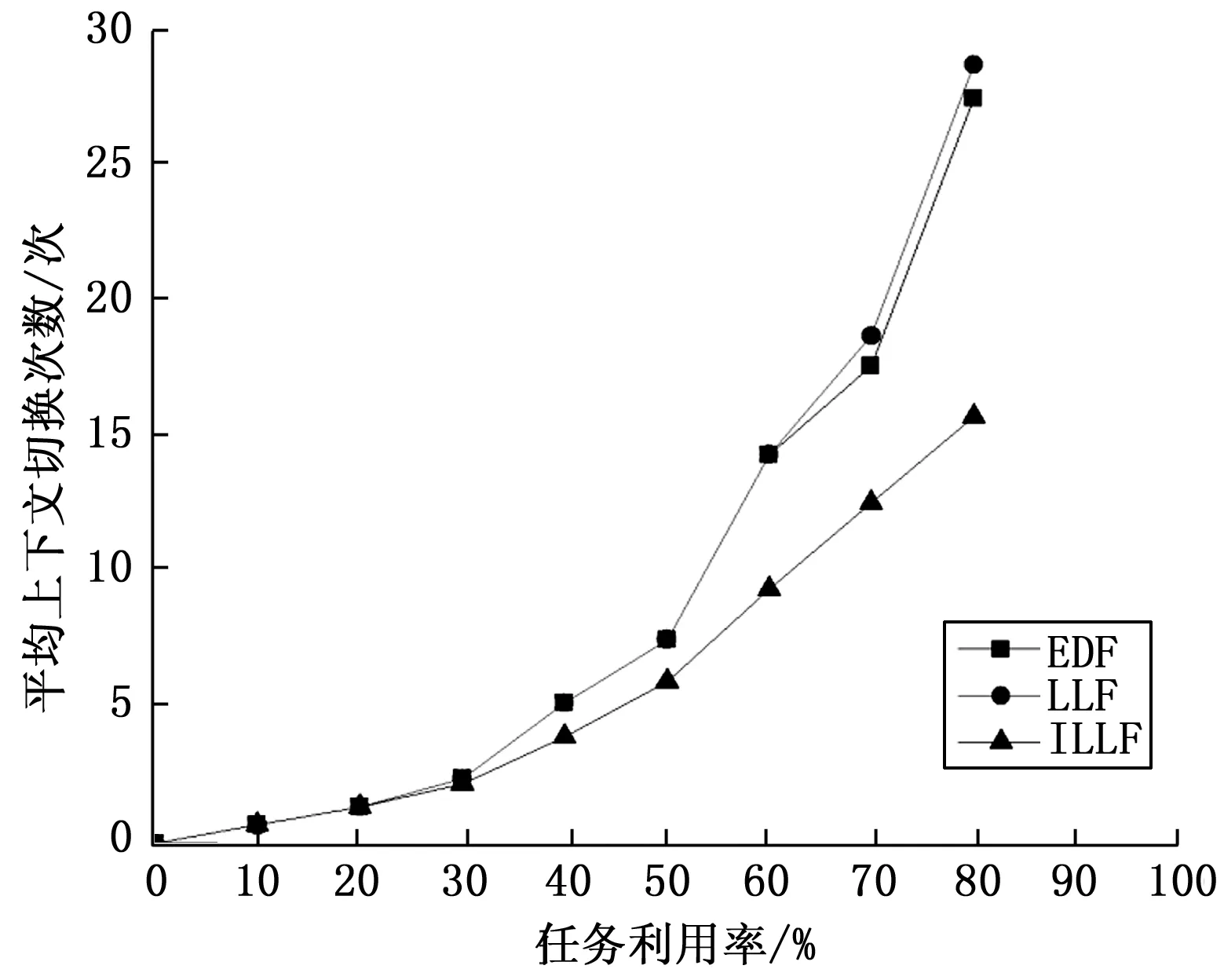
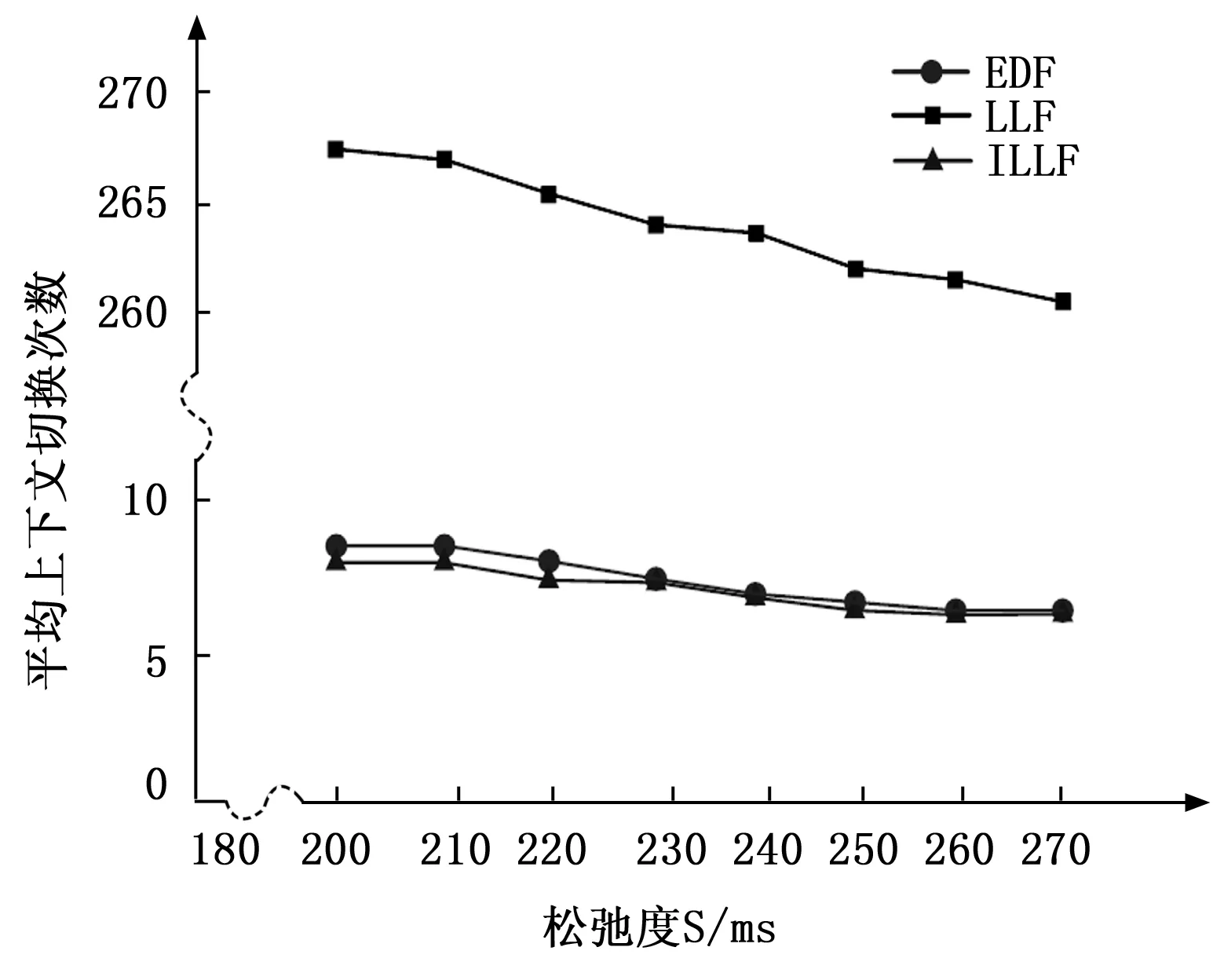
S3=0.4P 当它们同时被激活时,按LLF调度算法任务3优先得到调度。经过时间S1,任务1和2如果均未通过负载均衡迁移至其他CPU核,它们的松弛度将同时减为0,任务1或2会抢占当前CPU。由于它们松弛度都为0,即最紧迫的任务,无论谁抢占当前CPU另一个任务都无法在截止期限内调度执行完。如果交换相邻松弛度任务3与1(假设在就绪队列中,松弛度按3-1-2从小到大排列),按1-3-2顺序排列任务,则任务3运行0.4 P时间时任务2松弛度减小为0抢占任务3,即使当前CPU核上任务不发生迁移,也能按1-3-2-3顺序在期限内保证3个任务调度执行完。 定义2:如果任务剩余运行时间大于其松弛度,则该任务为大活任务,否则为小活任务。 定义3:将任务抢占与交换相邻松弛度任务都称为任务交换,其中不发生任务交换运行的任务称为原始任务,任务交换后运行的任务称为插队任务。 以上例子E2中,按照定义2在任务刚被激活时,任务1和2都是小活任务,任务3 是大活任务。从以上分析看出,先调度松弛度较大的小活任务可能减少任务上下文切换次数。由此提出以下任务交换策略:在任务交换时机到来时,有原始任务K(Rk,Dk,Pk,Sk),插队任务Q(Rq,Dq,Pq,Sq),如果K是大活任务且Q是小活任务,并有Rk>Sq与Rq 接下来对以上调整策略进行分析,如图3所示,以任务K为小活任务和任务为K大活任务两种情况讨论。若任务K为小活任务,有Rk 图3 任务K与Q时间参数 本节将说明如何在实时调度实体中调度ILLF(改进的LLF)任务,对Linux内核进行必要修改并包括其他系统调用,可以从SCHED_DEADLINE调度类中获取新实时调度类的实现,并且新调度类在内核所有调度类中具有最高优先级。 在任务的创建阶段,新创建任务的WCET,截止期限和周期作为参数传递,新任务通过这些参数计算其初始松弛度。更新新加入任务所在就绪队列上所有调度实体的松弛度,按松弛度大小将新任务实体new_task加入就绪队列。其中,入队列函数除了使用rb_leftmost与rb_left2most分别记录松弛度最小的任务M与松弛度仅大于M的任务。Algorithm 1说明了入队列过程,新任务实体所在就绪队列的根节点是rb_root_of_new,当新任务实体松弛度最小或仅大于当前rb_leftmost对应调度实体时,需要更新记录值,最后函数enqueue_sched_entity将new_task加入就绪队列。 Algorithm 1: function enqueue_laxity_entity_function(new_task) do leftmost ← 1; link ← rb_root_of_new; while link do parent ← link; if new_task.laxity < parent.laxity then link ← parent.letf; else link ← parent.right; leftmost ← 0; end if end while if leftmost=1 then rb_left2most← rb_leftmost;rb_leftmost ← new_task;elseif parent = rb_leftmost then rb_left2most ← new_task; end if enqueue_sched_entity (new_task, parent, link); end function 在CPU当前任务执行完或有新任务加入就绪队列后,考虑任务交换。如下Algorithm2所示,参数K、Q分别是原始任务与插队任务。对于新加入任务,K指当前任务,Q指新加入任务;对于当前任务执行完,K指rb_leftmost所指任务,Q指rb_left2most所指任务。其中big_load=1表示任务是大活任务,下一时刻调度函数pick_next_laxity_entity返回的调度实体。 Algorithm 2: function pick_next_laxity_entity(K,Q) do if K.big_load = 1 and Q.big_load = 0 then if K.runtime > Q.laxity and K.laxity ≥ Q.runtime then return Q; end if end if return K; end function 每个tick周期到来时,仅更新等待运行任务中松弛度最小的任务的松弛度。rb_leftmost指针关联的任务如果是当前任务,则待运行任务中松弛度最小的任务与rb_left2most指针相关联,伪代码如下: left_task ← rb_leftmost; if left_task = cur_task then left_task ← rb_left2most; end if left_task.laxity ← left_task.deadline - left_task.runtime - cur_time; 如下Algorithm 3,当任务执行完,函数dequeue_sched_entity从就绪队列移除当前任务cur_task时,需要更新rb_leftmost与rb_left2most记录的任务。 Algorithm 3: function dequeue_laxity_entity(cur_task) do if rb_leftmost = cur_task then rb_leftmost ← rb_left2most; rb_left2most ← rb_left2most.next; else if rb_left2most = cur_task then rb_left2most ← rb_left2most.next; end if dequeue_sched_entity (cur_task); end function 为了验证上述ILLF调度算法效果,选择标准Linux-3.14版本内核,在拥有四核同构处理器的tiny4412开发板上进行实验。其中,标准Linux为了避免实时任务长时间占用CPU,默认情况下在1 s时间内留出5%的CPU时间给非实时任务。实验选择一组运行时间在[5 ms, 80 ms]上的周期任务,最大任务利用率不能超过4*95%=380%。考虑到Linux内核中中断、软中断、自旋锁以及任务上下文切换带来的系统开销,任务利用率控制在4*80%=320%以内。 为了简化,假设每个任务的截止期限与周期相等,任务运行时间为毫秒的整数倍,并配置Hz等于1 000(tick周期时间是1 ms)。创建16个实时任务: Ti=((5i)ms,Di,Pi)(i=1,2,...,16) 分别考虑2种情况下任务调度:1)每个任务的任务利用率相同,松弛度差别较大;2)每个任务的松弛度相同,任务利用率不同。 定义4:在1 s时间内平均每个核上任务上下文切换次数称为任务上下文切换频率。 使用vmstat命令监控任务活动,其中cs列显示每秒进程上下文切换次数。对于情况1),每个CPU平均任务利用率分别从10%~80%,EDF、LLF与ILLF算法的任务上下文切换频率如图4所示,由图可以看出,在处理器任务利用率较低的情况下,3种调度算法对应的上下文切换次数基本一样,在任务利用率达到60%以上时,改进的LLF调度算法的优势得到显现。 图4 不同任务利用率上下文切换频率 对于情况2),松弛度为S0,16个实时任务分别为: Ti=((5i)ms,(5i)ms+S0,(5i)ms+S0)总任务利用率: 总任务利用率最大320%时,对应最小松弛度约为180 ms,取松弛度为200~270 ms,EDF、LLF与ILLF算法任务上下文切换频率如图5所示,由图可以看出,随着松弛度的变化,平均上下文切换次数变化不大,但由于实时任务集的松弛度相同,LLF调度算法带来了频繁的上下文切换,远多于EDF调度算法和ILLF调度算法带来的上下文切换次数。 图5 不同松弛度上下文切换频率 上面实验例子中的任务都是小活任务,为了体现改进方法4)带来的影响,依此创建并激活如下任务: Ti(i=1,2,3,4)=(60 ms,100 ms,100 ms); Tj(j=5,6,...,12)=(5 ms,60 ms,60 ms)。 在EDF、LLF与ILLF算法调度下任务上下文切换频率如表1所示,在Linux负载均衡的作用下,任务T1,T5,T9被放在同一CPU核上运行,在仅使用方法3)时,在任务T1运行过程中,任务T5和T9的松弛度同时到达0,没办法在截止期限内完成任务,而方法4)使得任务T5和T9在任务T1之前运行,既保证了任务能在截止期限内完成,又减少了任务上下文切换次数。 表1 上下文切换次数频率 多核处理器的使用逐渐成为一种趋势,在实时性发方面具有很多优点。基于Linux的实时任务调度算法一直在实时性方面做出改进,现有的Linux内核已经实现了EDF调度算法,但在多核方面容易出现Dhall效应,本文针对此问题提出了一种改进的LLF调度算法,它既避免了EDF调度算法带来的Dhall效应,同时在LLF算法的基础上采取了一定的优化措施减少了任务上下文切换次数以及松弛度的计算,使得系统能根据任务的紧急程度以尽可能小的系统开销在截止期限内完成任务的调度。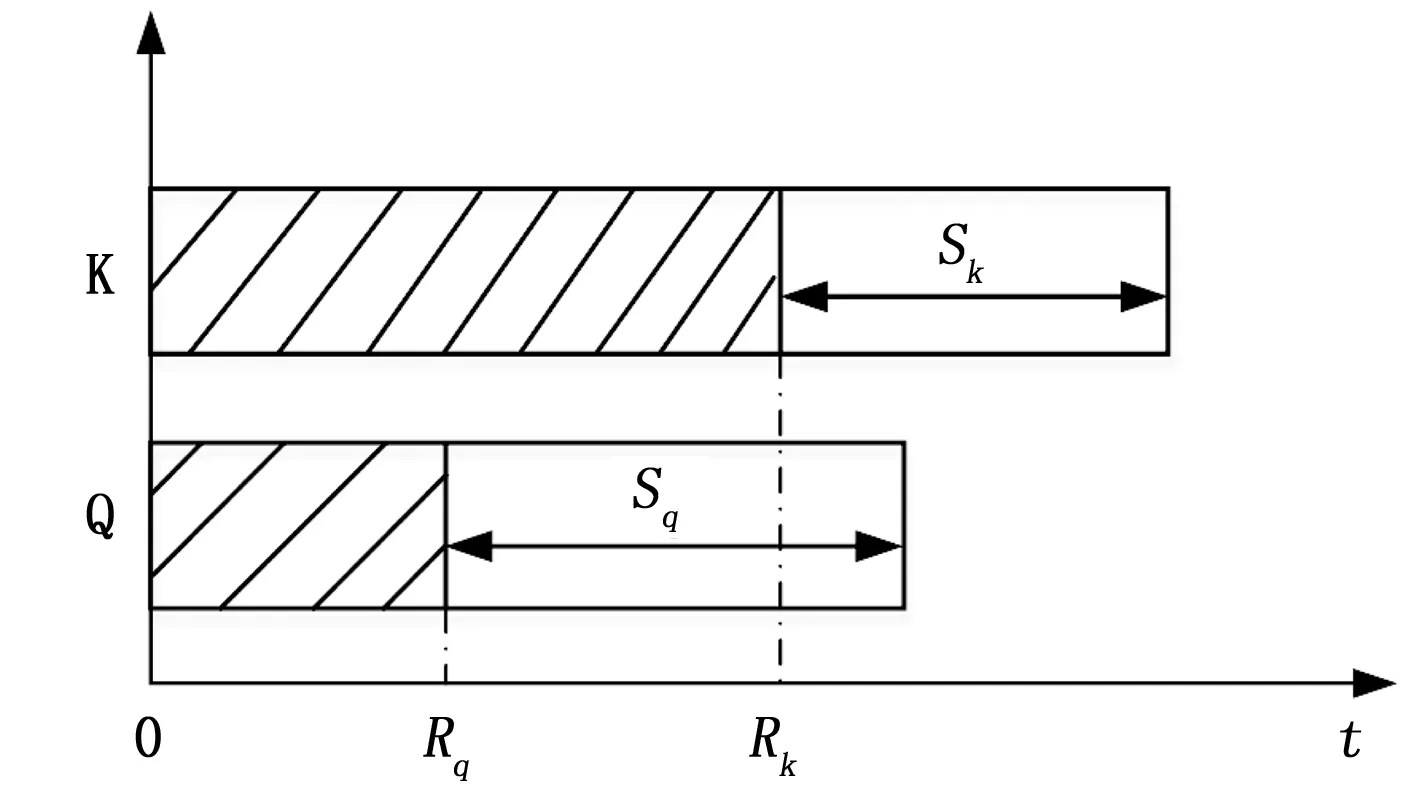
3 实时调度实现细节
4 实验结果与分析

5 结束语
猜你喜欢
矿山安全信息(2022年11期)2022-11-26计算机系统应用(2022年5期)2022-06-27矿山安全信息(2021年3期)2021-11-30今日农业(2021年9期)2021-07-28现代装饰(2021年1期)2021-03-29科学导报·学术(2020年26期)2020-10-21小学生学习指导(低年级)(2020年4期)2020-06-02软件(2020年3期)2020-04-20中学生数理化(高中版.高考理化)(2019年6期)2019-06-22中国计算机报(2019年12期)2019-06-21
