
大数据驱动的钢铁工业智能故障诊断技术综述
2020-12-08 03:14韩俊毅
计算机测量与控制 2020年11期
傅 筱,韩俊毅,曹 阔
(1.上海立信会计金融学院 信息管理学院,上海 201209;2.英科铸数网络科技有限公司,重庆 401147)
0 引言
钢铁是支撑国家发展和经济建设的工业脊梁,也是反映一个国家综合实力的重要标志。“工业4.0”自2013年提出后便引起了钢铁行业的广泛关注,标志着传统制造业向智能化的转型[1]。截至2020年1月,世界经济论坛共评选出44家在第四次工业革命尖端技术应用整合工作方面卓有成效、在大规模采用新技术方面走在世界前沿的“灯塔工厂(global lighthouse network)”,其中就有四家钢铁企业入选,它们分别是塔塔钢铁荷兰艾默伊登公司、塔塔钢铁印度公司、韩国浦项制铁公司与中国宝钢股份上海基地工厂[2]。
近年来,越来越多的过程监控与故障诊断系统被用于保证工业生产过程的安全、节能、稳定与高效。来自美国、德国等工业发达体的制造业企业率先围绕自身设备展开工业智慧化,建立了各自的云服务平台,例如通用电气公司的Predix工业互联网操作系统与西门子股份公司的MindSphere开放式物联网操作系统;与此同时,在国内如上海宝信软件股份有限公司、中冶赛迪集团有限公司等科技型企业也积极响应智能化升级战略,助力我国钢铁工业初步进入转型阶段。
目前针对工业故障诊断问题已经建立了相对完整的理论体系,并积累了一定的实践经验,但是钢铁冶炼过程中的不确定、不规则、强相关、高主观等因素仍制约着这项传统工业的数字化转型进程[3-5]。
随着大数据时代的到来,故障诊断系统在推进钢铁智能制造的实际应用中存在着亟待解决的问题,依据大数据的特征可以归纳为以下几点。
1)数据量大(Volume):如何高效采集、传输、存储和管理工业大数据;
2)速度快(Velocity):面对高速积累与实时更新的监测数据,如何保障故障诊断系统的时效性;
3)价值密度低及真实性保障(Value & Veracity):如何挖掘出隐藏在海量数据中的有价值的信息,并对未来可能发生的故障做出可靠、及时的预警;
4)类型多(Variety):多类型及非同源的数据可以更好地描述设备运行状态,但同时也对诊断模型的多模态处理与自适应能力提出了更高的要求。
针对以上问题,本文结合当前大数据时代的特征,总结分析了故障诊断方法在国内外钢铁行业的研究现状,探索了机器学习算法与迁移学习技术在高炉冶铁过程管控中的应用前景及有待突破的关键问题,并在此基础上对未来可能的研究方向进行了展望。
1 高炉炼铁故障诊断系统
高炉炼铁是指在高温下使用还原剂将含铁矿石还原成液态生铁的过程,其工艺流程由高炉本体与上料、送风、煤气回收与除尘、渣铁处理、喷吹燃料五个辅助系统组成[6-7]。在运行过程中,齿轮疲劳损坏、主轴动平衡破坏、通流管路堵塞及其引起的喘振、轴承温度异常升高等都会影响冶炼设备的正常运行[8-9]。如果无法及时识别设备故障,不仅会降低生铁的质量和产量,增加能源消耗,还会缩短设备使用寿命,甚至导致严重的安全事故[10]。
传统的工业设备故障处理主要由技术人员根据原始设备制造商提供的独立设备的性能参数做出判断,其任务包括发现和诊断过程异常事件,并做出合适的决策使对象恢复到安全、正常的运行状态[3-4]。而当前钢铁厂的现场操作员通常只能完成较浅层次的设备养护工作,且即便是具备了较高专业知识水平的工程师也可能由于过往经验的差异而在面对相同故障时做出不同的判断[5]。此外,外部生产环境(如温度、湿度等)的变化及设备运行过程中零部件的磨损、腐蚀直至被替换,都会导致设备的实际性能参数与原厂参数发生偏移;并且随着制造业水平的提高,各类设备的耦合性也在逐渐增强。
因此,我们需要从全局的角度,综合分析冶炼自动化设备现场采集到的工业大数据,从中发现新的模式与知识,实现变工况条件下高炉炼铁故障的智能诊断与预警。
本节分别从工业大数据的采集与实时监控,基于机器学习的故障诊断方法,及迁移学习技术在故障诊断中的应用三方面讨论了可用于解决钢铁企业在大数据时代所面临的数据量大、速度快、价值密度低与类型多等问题的研究进展(其对应关系如图1所示)。
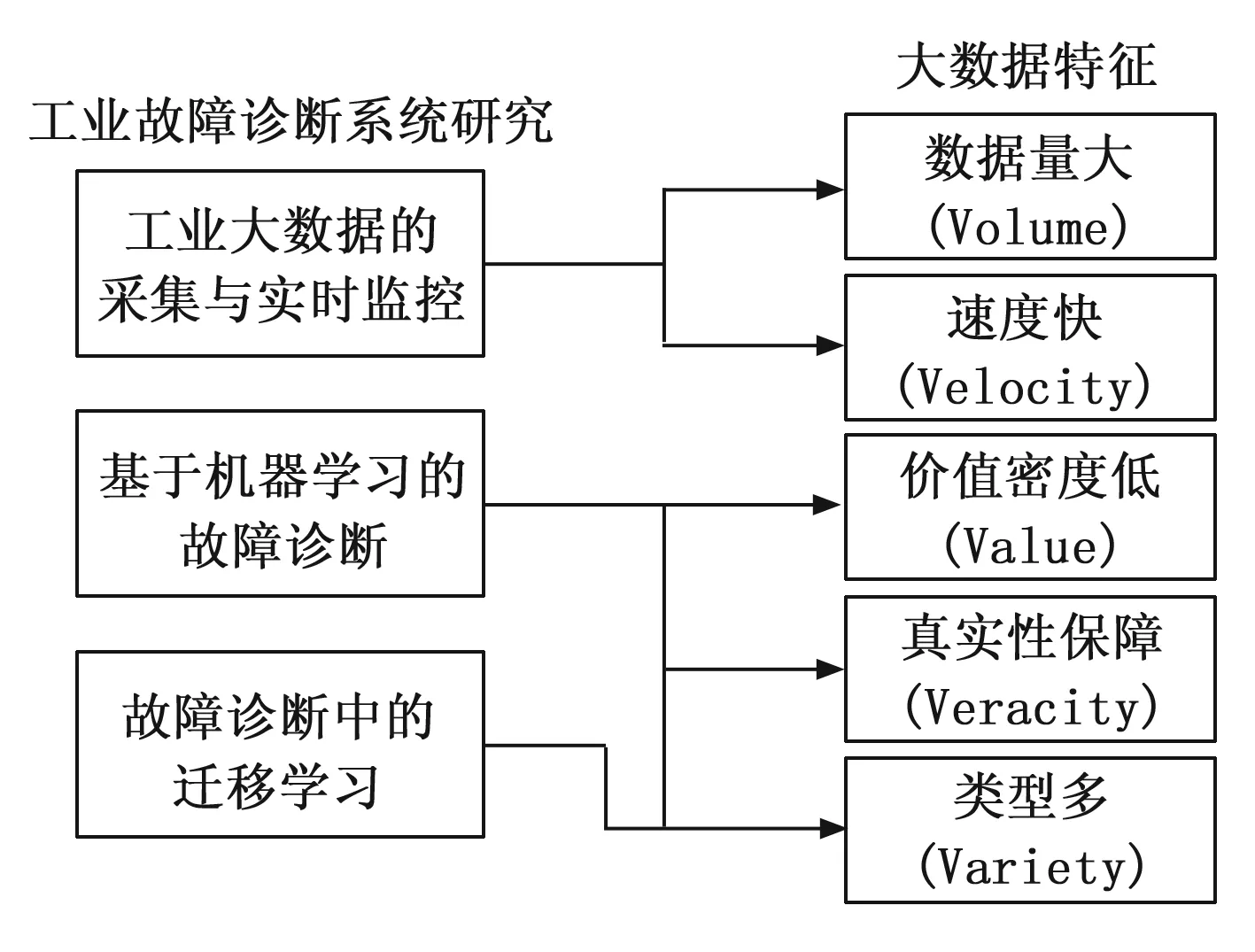
图1 工业故障诊断系统研究与大数据特征之间的对应关系
1.1 工业大数据的采集与实时监控
近些年分布式数据采集和监控(supervisory control and data acquisition,SCADA)系统的普及使人们可以管理和监督钢铁制造过程,充分利用现有的SCADA数据是当前提高设备运行可靠性最迅速、有效的方式之一[11]。然而目前该类系统的故障诊断模块仍主要采用基本的上下限报警模式,即当实时数据与健康估计值之间的残差呈持续升高的趋势并超过预设阈值时,就认为设备出现异常[12]。由于其没有考虑噪声信号的干扰及监测参数之间的相关性,从而存在着较高的虚警率,且无法对部分潜在故障做出及时预警。现有的研究主要从阈值选择和残差评估两方面对SCADA系统的故障诊断模块进行优化。
1.1.1 阈值选择
传感器失效、数据传输异常及人为操作失误等因素都会导致SCADA数据中出现异常值,为了分辨噪声数据与设备异常信号,Marti-puig等[13]通过分析与齿轮箱温度变化相关的特征参数后,发现由环境噪声产生的离群点对正常状态的偏离较大,因而在确定了参数的绝对与相对阈值(例如,轴承温度=环境温度±30 ℃)的基础上,依据专家知识设置了范围更广的上下限去除环境噪声的影响。而针对工业参数阈值选择仍较大程度依赖于主观经验,缺少理论依据的问题,刘跃飞等[12]使用统计过程控制分析得到齿轮箱油温残差近似服从正态分布,并依此分别设定μ±2σ与μ±3σ为异常提示与故障报警阈值。通过研究SCADA数据间的耦合关系,Zhu等[14]使用层次分析法与最小二乘法获得参数的动态阈值,如齿轮润滑箱温度随冷却系统、电机功率、舱室温度等因素的变化而改变;方志宁等[15]则提出通过设置基于逻辑规则的自定义报警阈值,实现在参数值未单独越限的情况下,从系统整体的角度提前做出预警。
1.1.2 残差评估
为了减少因局部异常点而导致的虚警,并有效表征工业过程的动态特性,具有数据平滑功能的滑动窗口被研究用于评估实际观测值与模型预测值间的差异。孙建平等[16]利用滑动窗残差统计法计算估计值与实际值之间的残差均值,描绘相似度曲线,并以此均值的实时变化趋势监测齿轮箱轴承温度是否异常。刘峰里[17]提出双滑动窗法,先利用宽度较小的快速预警窗口对鼓风机相似度序列进行统计分析,而当快速预警窗口监测到异常时,则触发宽度较长的备用窗口进行验证,从而在保证及时发现异常的同时减少因孤立异常点引发的虚警次数。周韶园[18]根据过程事件变化的缓慢或剧烈程度,使用变长度移动窗口保证在每一时刻截取的过程数据都能有效包含过程异常状态的特征信息。Kusiak等[19]与Zhu等[14]则采用滑动窗平均消除缓慢的热传导对温度相关参数的潜在影响。
与此同时,SCADA系统中自带的上下限报警信号则被作为基准,评估改进后的故障诊断模型的性能。为了避免风机报警信号过多导致操作人员难以及时识别,Bangalore等[20]使用三位数字编码对发生在不同部位的不同故障进行分类标注,从而可以直接将故障信息用于指导设备检修。
1.2 基于机器学习的故障诊断
SCADA系统测点众多,采集得到的数据包括振动、温度、压力、功率、电压、电流等信号。其中振动信号因可以指示机械故障与结构缺陷而被广泛地应用于评估设备中齿轮、轴承等部件的健康状况[21-22],现有的很多工业故障诊断系统都依赖于测量和分析位移、速度、加速度等振动信号[23-26]。但是,基于信号的故障诊断方法通常只能提取输出信号的时频域特征,而较少关注输入信号的动态变化,未知的输入扰动会降低它的诊断准确性;并且由于冶金设备涉及的参数众多,单纯地使用基于信号的方法无法表征整个系统的实际运行状况。
因此,为了快速、精确地识别异常,通过分析大量离线及在线数据来描述过程对象的运行模式和相关规律,同时对领域专家的依赖程度较小的,基于机器学习的故障诊断方法被越来越多地应用于提取海量SCADA监控数据中的隐含信息[27]。
过程工业控制中的故障诊断任务可以分为故障检测,故障分离与故障识别[21,28]。
1.2.1 故障检测
故障检测是工业故障诊断中最基本的任务,即判断设备是否出现异常。刘帅等[29]使用核极限学习机(extreme learning machine, ELM)并结合信息熵识别齿轮箱轴承温度异常。为了观察工业设备运行的动态时间特性,吴亚联等[30]将前一采样时刻的主轴承温度与当前时刻的转速、功率等参数同时输入反向传播(backpropagation,BP)神经网络预测当前时刻的轴承温度;方志宁等[15]将BP神经网络与决策树算法结合,以当前的监测数据为模型输入预测后续时刻的参数取值。而Bangalore等[20]则运用NARX(nonlinear autoregressive neural network with exogenous input)神经网络为齿轮箱轴承正常工作10分钟的平均温度建立行为模型,其研究结果表明使用基于机器学习的诊断方法可以比分析振动信号提前约一周预警温度异常。
1.2.2 故障分离
故障分离用于进一步确定故障的种类、发生时间及位置。Zhang等在利用Hotelling’s T2统计量与SPE统计量分析一台高炉12天的历史数据识别其低温异常[31]的基础上,提出了一种基于主成分分析与LMNN (large margin nearest neighbor)的多分类方法诊断四类高炉故障(即悬料、管道行程、崩料与炉温过低)[32];在此过程中,研究者通过融合三台反应机理相似的高炉的两年历史数据,解决了单台高炉故障训练数据不足的问题。机器学习中其它的多分类算法如最小二乘支持向量机[33]、Softmax回归[34]、k近邻算法[35]等同样被应用于判断高炉本体或辅助系统旋转机械的故障类别。
为了识别设备零部件协同工作所造成的同时发生多处故障的情况,Wang等[36]利用基于粒子群优化的变分模态分解算法得到模态分量个数m(即当m=0时:无故障;当m=1时:单一故障;当m>1时:并发故障数目),并通过修改ELM决策方程使其输出前m个可能性最大的故障类别实现对并发故障的诊断,实验结果显示对并发故障的识别率低于对单一故障的识别。
而针对冶金过程中时常会发生的新的未知故障的问题,一种基于滑动窗隐马尔可夫模型(hidden markov model,HMM)的阈值统计方法被用于判断已知及未知故障[37]。研究者提出如果实际观测值的后验概率方差小于HMM方法学习得到的阈值,则说明实际值属于现有模式的概率极低,从而可以判定产生了未知故障;否则就进一步使用维特比算法确定当前滑动窗所属的模式向量,实现故障分离。
1.2.3 故障识别
故障识别用于评估故障的严重程度,如使用现有的ISO-2372设备振动标准[38-39]根据振动速度对转子不平衡与轴系不对中故障进行分级[24]。由于目前并没有统一的冶金设备或零部件故障严重程度的分级标准,Zhu等[14]首先通过对72组轴承振动信号的峰度与均方根聚类分析后,发现适合将其划分为四类,随后采用模糊评价模型将设备健康状况划分“良好”、“需关注”、“异常”与“故障”。设备的故障等级将直接影响钢铁厂后续的运维决策。
1.2.4 方法集成
钢铁工业作为大型复杂工业系统,需要监测的数据类型多种多样。若只采用单一的故障诊断技术,则会存在识别精度低、泛化能力弱等问题,难以取得满意的诊断效果[40]。
融合多种故障诊断方法被证实可以通过方法间的差异互补或交叉验证,平衡不同方法的优缺点来获得比使用单一技术更出色的性能[41]。如通过装袋法与多数投票算法集成不同核函数的SVM算法更准确地判断高炉的运行状态[42],使用支持向量回归合并三种ELM模型(即ELM,WELM与ORELM)的预测结果得到更精确的功率曲线[43];或在采样初期因缺少故障数据先使用基于观测器的方法,而随着设备的运行,当发生故障后,通过将故障数据反馈给诊断模型实现基于知识的诊断[44-45];也可以将振动信号的时频域特征作为参数输入基于机器学习算法的故障诊断模型,通过结合信号处理技术与机器学习方法提高故障诊断系统的精确性与鲁棒性[20,43]。
1.3 故障诊断中的迁移学习
基于机器学习的智能故障诊断方法已被广泛地应用于从不同结构、不同来源的工业SCADA数据中挖掘和解释隐藏的重要信息。然而传统的机器学习方法通常都假设:1)训练集数据与测试集数据服从同一分布;2)可以获得足够的数据训练可靠模型。但在实际的冶金数据采集过程中,由于生产环境和市场需求的持续变化,使用历史数据训练得到的模型很可能无法适用于当前阶段;并且难以将所有类型的,特别是极端工况条件下的故障信息都事先涵盖于模型的训练集中。因此,迁移学习被研究用于解决高炉炼铁故障诊断中,训练集与测试集数据分布存在差异,以及标注数据过期或缺少的问题。
迁移学习指将在解决一个问题时所获得的知识应用于解决另一个不同但相关的问题,即将从源域学习到的知识迁移到目标域中[46]。在设备的故障诊断中,迁移学习通过分析已有的源域数据,为目标域的故障诊断提供有价值的信息,实现在提高数据利用率的同时,提升建模效果。
Zhang等[34]使用测地线流式核方法从少量已标注的源域数据与未标注的目标域数据中提取可传递的特征参数。Chai等[35]提出了一种改良的基于细粒度对抗网络的领域自适应方法,使得通过迁移所产生的特征在降低了源域与目标域之间的分布偏差的同时,也保存了目标域中不同种类的样本的差异化信息。Cao等[47]发现来自ImageNet数据集的海量图片可以被用于训练m层卷积神经网络的前n层神经元完成特征提取,而训练剩余的实现分类功能的m-n层神经元仅需少量的齿轮故障数据即可完成。Xu等[48]使用模型仿真得到的不同制造阶段的数据后,利用栈式稀疏自编码器传递模拟故障信息用以识别真实生产线异常。
现有的智能故障诊断技术被证实可对高炉炼铁过程中不同设备的异常状态进行预警,包括电动机(电机)的超速、断轴、大轴承弯曲、烧瓦与油膜振荡,鼓风机(风机)的风量不足、过热、润滑油泄漏与轴承振动加剧,以及高炉本体的崩料,悬料,管道行程与炉温过低等。研究通过设置相对阈值降低外部环境因素的影响,并利用滑动窗口法评估系统残差,动态监控工业过程,减少虚警的发生。多种机器学习算法被用于从海量SCADA测点数据中自动挖掘隐藏信息,实现故障的检测、分离与识别;同时结合迁移学习技术可以解决冶炼过程中故障数据与健康数据比例失衡的问题。
但是由于高炉炼铁数据采集、检验、标注过程的周期长、成本高,以及不同钢铁集团间数据的非共享性,现有的大多数研究结果都仅仅基于状态相对理想的实验室数据或采样时长较短的现场数据,其在真实复杂工业环境中的鲁棒性及普适能力仍有待进一步验证。
2 研究方向展望
在如今的大数据背景下,智能故障诊断方法随着信息技术和钢铁工业自动化的快速发展而不断完善,但是在解决实际工业问题的过程中仍存在着如下问题:
1)机器学习算法的“黑箱”特性使得现有的基于知识的诊断方法的可解释性较差,很难直观地描述模型输入特征与输出值之间的关系,导致现场操作人员无法直接根据模型结果调整设备参数;
2)不同传感器采样频率不同或信号传输不稳定会造成某些时间点观测数据缺失,且由于冶炼设备长期运行于高温、高压等恶劣环境中,从而易导致传感器失效而无法获得部分参数;
3)目前仍缺乏统一的设备故障严重程度分级标准,这将不仅不利于故障诊断方法在实际工业领域的应用与推广,同时也将阻碍对微小故障的早期诊断,可能导致部分隐蔽性较强的故障直到发展到较严重的水平时才能够被识别出来;
4)以往的故障诊断研究一般只强调设备运行的安全性而没有考虑其运行成本,而值得注意的是,基于机器学习的诊断方法不能做到准确识别每一个潜在故障[49-50],从而可能产生虚警,并影响后续的运维活动;
5)机器学习算法的应用仍局限于局部组件的故障诊断,未能综合考虑零部件及设备间的耦合关系,离评估整体设备及完整工艺流程的运行状态还有一定的差距。
针对以上实际应用需求,基于采集到的工业大数据,我们使用“系统—模块—功能—属性”四层结构描述钢铁冶炼工艺流程(如图2所示,图中以高炉鼓风机的故障诊断为例展开),其中系统层由电动机系统、鼓风机系统、高炉系统等关键设备构成;而各系统可划分为不同模块,如数据采集模块、故障诊断模块、运维管理模块、成本分析模块等;针对每一模块,又可以按照其不同功能设置进一步分解,如故障诊断模块包括故障的检测、分离与识别;最底层的参数属性则直观展示了各个部位的运行状态,同时也是数据与人产生交互的基本方式。
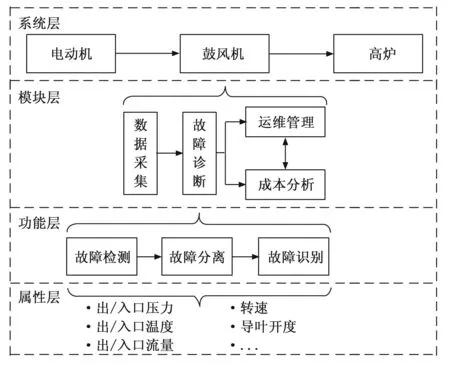
图2 钢铁冶炼工艺层次结构(以鼓风机的故障诊断为例展开)
本节依此结构由底至上整体地对未来可能的研究方向进行展望。
2.1 属性层
在钢铁工业中,实现对关键属性超前一定时间的序列预测对掌握底层动态制造过程,并优化上层性能表现十分重要。炼铁过程中的参数采样具有随机性和间歇性的特点[51],在学习和预测长度不同的时间序列时具有稳定表现的长短时记忆网络和门控循环单元网络模型[52-53]可被进一步研究,如通过添加气温、空气密度、相对湿度等环境因素为附加输入或与其它机器学习算法融合,提高模型中长期预测精度。
2.2 功能层
1)尽管单纯地应用机理分析或技术人员的经验较难解决当前多属性、多耦合、多状态的工业问题,但通过向数据补缺、特征筛选等步骤中引入物理机理模型与领域专家知识(如风机性能曲线、管网特性曲线等),以“数据+机理/知识”的模式进行工业大数据分析,将有助于破解智能故障诊断模型的“黑箱”问题,提升模型的可解释性与可交互性;
2)由于在钢铁行业即使是微小的故障也可能引发严重的安全事故,建立统一的《冶金设备故障严重程度分级标准》可以通过数字、文本、图像等方式多模态地描述故障演变过程,保证决策的一致性;也可以将该分级标准作为基于机器学习的故障识别方法的评价依据,融合信号处理、自然语言处理、图像处理等技术,构建工业知识图谱,更好地实现对故障的早期识别与早期维护。
2.3 模块层
1)采集得到的数据质量将直接影响故障诊断的效果,目前针对钢铁厂所使用的超大功率电机、风机设备的研究较少,且由于现场数据采集耗时长、代价高,多数诊断方法仅采用标准仿真数据库或实验室模拟数据评估其性能,因而研究如何高效地存储、传输并更新海量工业数据可以推进实验理论研究在真实的工业环境中的应用;
2)故障种类、发生部位、严重程度等因素应与成本分析结果共同指导工厂运维部门的作业调度,且对潜在故障的预警及相应的预防性运维活动也会影响经济决策的制定,因此研究“故障”、“运维”、“成本”相关模块之间的交互与融合将帮助提高运维效率,降低生产成本,实现钢铁制造的多目标优化。
2.4 系统层
钢铁冶炼由电机、风机、高炉等系统协同工作,如通过励磁同步电机带动轴流式鼓风机向高炉送风,任一系统的故障都有可能联动导致其它系统发生异常。而钢铁厂现有的技术未能实现对工艺流程所涉及的各系统进行统一管控,系统与系统之间仍依靠人工联系,信息的不一致、沟通的不及时会增加冶炼过程的不确定性,如何将面向单一系统局部故障的诊断方法扩展至面向整体的多系统仍有待研究。
3 结束语
工业大数据具有数据量大、实时性高、价值密度低、数据类型多及需保障真实性等特点,为有效提升其在钢铁工业中的利用价值,深度挖掘揭示工艺流程运行状态的新知识与新规律,本文对近年来应用于高炉炼铁过程的基于机器学习算法的故障诊断技术进行了总结,并探讨了应用迁移学习解决故障数据小样本与类别不均衡问题的可行性,最后结合钢铁企业的实际需求与现存问题,提出了面向整体的分层故障诊断研究思想。通过融合多源数据分析技术,将可以建立高准确率、高可靠性的故障诊断模型,从而降低运维成本、提升工艺水平、保障生产安全,同时将人力解放出来从事更有意义的管理与决策工作。
工业大数据是我国“智能制造”和“工业互联网”的重要技术支撑[54],工业大数据分析技术的创新与发展,必将成为未来提升工业生产力和竞争力的关键要素。基于机器学习算法的故障诊断技术促进了钢铁工业数字化的发展,但面对大数据时代不断涌现的新需求、新机遇,为进一步推进智能故障诊断方法在实际工业场景中的应用,保障传统工业的智能制造与绿色发展,仍需做更多更深入的研究。
猜你喜欢
汽车实用技术(2022年16期)2022-08-31
一重技术(2021年5期)2022-01-18
昆钢科技(2021年3期)2021-08-23
昆钢科技(2021年3期)2021-08-23
昆钢科技(2021年1期)2021-04-13
当代工人(2019年18期)2019-11-11
Coco薇(2015年10期)2015-10-19
汽车电器(2014年5期)2014-02-28
全国新书目(2009年24期)2009-07-17
中国经济信息(2004年15期)2004-08-10
