
一种用于人体关键点检测的改进算法
2020-12-07 06:47刘颖郑力新
现代计算机 2020年30期
刘颖,郑力新
(华侨大学工学院,泉州262500)
0 引言
人体姿态估计在当代生活中的重要性日益凸显,它在自动驾驶、人体尺度测量、人体异常检测、人口密度分析、医学等多个方面起到很重要的作用。在各种人工智能展会上我们都会发现留有它的一席之地。
现在的人体姿态估计算法主要有基于top-down[1-4]和down-up[5-7]两个思想的研究。top-down 是先检测出人体框,然对框类人体进行关键点检测[8]。down-up 是直接对图片中的人体关键点进行检测,然后对检测出的关键点进行人体归属分类。down-up 方法虽然检测速度比较快,但在检测精度上相比top-down 方法相差还是比较多,因此近年top-down 方法成为人体姿态估计研究的主流思想。本文采用top-down 方法综合以往对姿态估计的研究成果进一步对算法进行了改进,在关键点的检测精度上取得了一定的提高。
本文是基于HRNet 网络的一种改进网络[1]。在HRNet 中只将最后一个stage 的输出作为反向参数调整的依据,这样可能会导致中间各层训练效果的丢失,因此我使用了中间监督的方法,将每一个阶段的的输出结果计算出的loss 值进行相加,以此作为反向参数调整的依据。反卷积利用了卷积核对尺度较小的图片矩阵进行尺寸上的扩张,相对于直接像素复制扩张的上采样,保留了更多的原始尺寸上的特征,有利于检测出各尺度图片上的特征信息,使最终的检测结果更加的准确。因此本次研究在每一个中间监督输出网络上都使用了反卷积。我们在中间监督输出部分加入了一个子网络,它包括一个反卷积层将原始像素进行扩张,接着是一个残差网络对扩张后的图片信息进行提取,最后使用了一个卷积网络将其缩小到原始HRNet 网络输出的格式。
1 算法实现
HRNet 网络总体来看是由三个不同分辨率的分支组成,最后使用上采样对特征进行融合输出,它分为4个stage,第一个stage 包含一个(32×64×64),然后经过一个分辨率变化层将(32×64×64)变化成为(32×64×64)和(64×32×32),然后进入第二个stage,stage2 包含3 个相同的module,每个module 最后一层卷积层均进行特征融合,低分辨率向高分辨率融合采用直接上采样,高分辨率到低分辨率采用卷积,重复分辨率扩张层和stage,到stage4 时能获得含有四个分辨你和通道数的stage,在最后一个module 的最后一层卷积层只进行低分辨率到最高分辨率的特征融合,如图1 所示。本次研究在HRNet 上做了一些改善。

图1
1.1 中间监督
HRNet 中网络结构最大的优势是训练了多分辨率上的图片特征,分别是64×64、32×32、16×16、8×8,它们之间相互联系又相对独立的训练,尽可能多地捕获到了图片不同分辨率上的特征和联系,使得检测结果获得了很大的提高,但是随着网络层数的增加有一些浅层的特征过度训练,导致特征效果降低。但是如果网络设置太短会使得一些更深层次的特征得不到提取,因此在本次实验中引入了中间监督,将短网络和深网络训练的特征都进行提取,对它们进行训练和加强,使得训练效果得到了很大的提高。
本次对HRNet 中每个stage 输出结果都进行了监督。我们在每一个stage 中的最后一个模块的fuse 层输出的结果增加了一个out 用于输出最高分辨率的图片特征,最后计算每一个out 分支的loss,将所有分支loss 和作为总loss 进行反向传播。如图2 所示;这样的改进有利于对前几层信息的充分利用。
1.2 高分辨率信息的提取
HRNet 是在64×64、32×32、16×16、8×8 四个级别的分辨率上对图片特征进行训练,本次改进算法中我们使用了反卷积算法在每一个stage 输出上对分辨率进行了放大,由原本的64×64 放大到了128×128,这样可以提高对中小型人物特征的获取。紧接着我们使用了一个残差网络对128×128 分辨率特征进行训练。我们尝试过使用更多的残差模块对其进行特征训练,但是当残差网络为一个时取得了最佳的结果。原始HRNet中上采样都是使用的基于像素复制的直接扩张方法,相比于直接扩张方法利用反卷积进行尺度扩张更能保留原始尺寸中的特征信息。在本次研究中我们将每个中间层的输出使用反卷积操作对其像素进行扩张。中间监督部分输出后的网络结构如图3。

图2 改进网络总体结构图

图3 中间监督输出网络图
1.3 注意力集中机制的加入
HRNet 网络是基于残差网络单元实现的,我们对残差基本单元进行了改进,给残差网络多加了一个分支,在这个分支中,首先对残差输入c*H*W 中每一个通道进行平均池化,使其结构变为C*1*1,再将其进行归一化,用激活函数ReLU 对其进行激活,接着将其进行Sigmoid 操作,将其转换成0-1 的值,再将其与第一个平均池化的结果相乘,得到最终每个通道的权重W,利用W 对残差输入的每个通道进行软化。将得到的软化结果与残差输入和原始输入X 相加,得到最终的改进残差网络输出结果[8]。残差网络广泛应用在所有的网络算法中,主要是因为它即能很好地保持底层的特征不被破坏又能提炼出更深层次的图片特征。实现了图片特征的跨层传递[9]。因为其是没有领域针对性的,虽然训练效果得到了提高,但在一些目的性比较强的网络中,如对物体分类、分割和关键点检测,它不能很好很快的集中到我们想要获取物体的地方,使得训练难度加大,结果差强人意,因此我提出了这个改进残差网络,它可以在保留原始残差信息的同时又保持注意力集中机制,使训练结果更加的准确。如图4 所示。
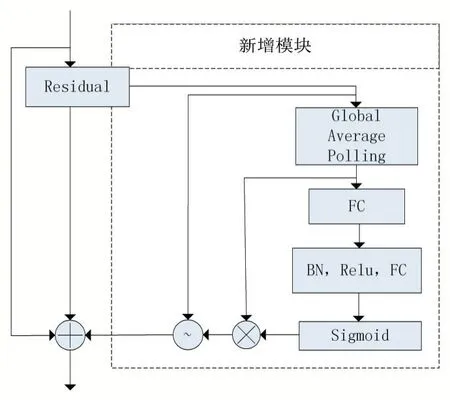
图4 改进残差网络图
2 结果分析
我们在MPII 数据集上对实验结果进行了分析,这个数据集来源于人们日常生活拍摄,包含了各种类型的图片,是当前进行姿态训练和评估比较权威的一个数据集。它包括22246 个训练图片和2958 个测试数据[10]。我们使用PCKH(正确关键点的头归一化概率)得分作为评价指标。将原始HRNet 网络与我们的该进HRNet 算法在MPII 数据集上的检测精度进行了比较。
表1 和表2 比较了两个算法的结果、模型大小和方法的GELOPs,可知改进后的算法相比原来的算法在每个关键点的检测精度上都有提升[11]。使用ResNet-152 作为主干,输入大小为256×256[1]。我们的方法达到了91.0 KCh@0.5 的分数,HRNet 的结果为90.0,得到了比较大的提升。

表2 模型大小和方法的GELOPs 表
COCO 数据集:COCO 数据集[12]包含超过20 万张图像和25 万个人体实例,这些实例都标有17 个关键点。我们在COCO 的train2017 数据集上训练我们的模型,包括57K 个图像和150K 个person 实例。我们使用OSK 作为评判工具将改进后的网络和原始HRNet 网络在COCO 数据集上的检测精度进行了比较,实验结果如表3。
由表3 可知我们的改进算法在中等大小人体身上的关键点检测精度得到了提高。

表1 MPII 数据集上检测结果对比表

表3 COCO 数据集上检测结果对比表
3 结语
本文对原始HRNet 网络进行了改善,将改进后的压缩残差网络代替原始的残差网络[13-14],能更好地检测出人体的关键点。在网络中加入了中间监督概念[15-17],并用反卷积代替原始简单的像素赋值扩张,这样可以提高图片中较小人体的关键点检测精度,在我们实际拍摄照片时,往往较小型人体占大多数,故改进的算法更贴近实际应用。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
建材发展导向(2022年3期)2022-04-19
北京大学学报(自然科学版)(2022年1期)2022-02-21
今日农业(2021年8期)2021-11-28
北京航空航天大学学报(2020年10期)2020-11-14
家庭影院技术(2020年2期)2020-03-25
北京航空航天大学学报(2019年9期)2019-10-26
广东教育·高中(2017年10期)2017-11-07
CHIP新电脑(2016年3期)2016-03-10
新高考·高一物理(2015年5期)2015-08-18
