
一种基于模式识别的微服务异常检测方法
2020-12-04 08:01郑杰生谢彬瑜吴广财
计算机技术与发展 2020年11期
郑杰生,谢彬瑜,吴广财,陈 非,花 磊
(1.广东电力信息科技有限公司,广东 广州 510000; 2.苏州博纳讯动软件有限公司,江苏 苏州 215000)
0 引 言
微服务架构由于具有开发效率高、部署敏捷、弹性伸缩等优势,越来越多地用于开发各类应用[1]。云计算数据中心近年来广泛部署基于微服务架构的软件应用,相应的基础架构(如Kubernetes,Mesos)也随之快速发展以支撑和管理大规模微服务[2]。由于多样化的微服务应用具有不同的资源需求和行为特点,数据中心管理更加关注服务及应用特征,以针对不同应用类型制定管理策略。微服务生态系统具有异构性,包括开源软件(如Nginx,Redis)、第三方服务和特定领域应用,剖析和理解微服务应用以保障可靠性具有挑战性[3]。已有微服务分析方法通常研究单个微服务以分析特定应用属性,如可执行文件名称、端口号、配置文件、容器镜像元数据。但是,这些属性不是微服务的固有属性,可以进行隐藏或调整,并且会随着软件技术的发展而动态扩展,因此这种面向特定应用的分析方法具有不可靠性或不完整性;基于包检查的应用分析方法计算效率低下,无法以较小开销及时分析实际部署微服务的运行时行为,难以在代码级准确解析微服务特征;另外,严格的租户隐私标准禁止对租户的微服务进行侵入性分析或检测,增加了准确分析微服务的难度。
该文以统一、高效、非侵入的方式监测微服务应用的运行时行为。对于以进程形式运行的微服务,搜集微服务与主机操作系统交互时(如访问文件系统和网络,同步线程)发出的系统调用;对于基于容器(如Docker,LXC)部署的微服务,监测服务器操作系统内的系统调用,与应用无关且对微服务透明,可以对不同微服务应用实现统一的非侵入式低开销的系统调用监测。
为了应对实际环境中不断增长的多种类型的微服务应用,该文提出了一种监督式贝叶斯学习模型,将系统调用序列刻画为k阶马尔可夫链,使用k阶转移概率表示序列化的微服务行为历史记录,对系统调用执行序列进行精细划分,以刻画不同类型微服务应用的特点。进而,面向特定微服务应用类型,使用自监督式的自动编码器建模微服务应用的行为,通过该模型检测当前应用的系统调用序列是否出现异常。
1 异常检测方法
微服务通常作为独立进程或在容器内部执行,每次调用微服务会产生相应的系统调用流。将微服务执行单元集合表示为U={u1,u2,…,un},其中,ui为进程或容器形态的微服务执行单元,n为执行单元数量。当ui调用发生时,会生成有序的系统调用序列,建立模型以表示微服务执行的随机过程,通过系统调用间的转移概率表示微服务应用类型的行为特征。方法具体包括以下步骤:
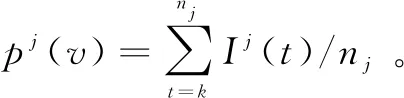
而后,评估系统调用条件概率。使用训练序列数据集估计条件概率,pj(vj|v)表示在微服务执行单元uj调用序列中,系统调用行为v之后vj出现的概率。对于0阶序列模型,执行单元uj的系统调用v的概率为pj(v)。对于k阶序列模型,当前动词依赖于最近k个动词,行为v的调用概率为pj(vj|v)。一旦从训练序列中计算得到执行单元uj的条件概率,可以依次递归估计该序列中各系统调用行为的条件概率。
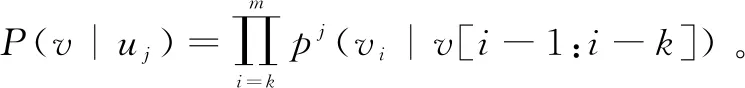
基于贝叶斯的系统调用序列建模的计算开销随着微服务数量线性增长,在实际部署环境中,服务执行单元数量通常较高,因此会具有较高的计算开销。此外,高阶贝叶斯模型在uj上计算k阶条件概率矩阵将产生指数级训练时间,并且矩阵计算会占用较多内存。为了解决此可伸缩性问题,以分层方式进行微服务类型分析。首先,使用分层聚类方法[4]将执行单元uj分为N组。使用Minkowski距离计算两个执行单元之间的距离,并基于距离度量执行聚类操作。
算法1具体描述了文中使用基于深度学习的自动编码器进行异常检测。在训练过程中,将系统调用序列表示为固定长度的特征向量,使用训练数据集构建自动编码器以重建原始训练数据。在测试过程中,如果当前系统调用序列数据的特征向量为异常序列数据,自动编码器会产生较高的重建损失。对于微服务执行单元uj,将训练得到的自动编码器表示为AEj,测试序列产生的重建损失应在随机变量Lj的置信区间[5],否则将该序列数据检测为异常系统调用序列。因此,需要选择合理的损失阈值L,以最大程度减少假阳性和假阴性检测错误。
算法:基于模式识别的异常检测。
输入:Seq //微服务系统调用序列。
输出:AnomalyScore //微服务异常值。
过程:
AnomalyScore=loss //异常值初始化为当前编码器的损失值
for eachAEiinGdo //遍历编码器集合G
loss=evaluate(AEi,Seq) //使用编码器计算最小损失值
if AnomalyScore>loss then
AnomalyScore=loss
end if
end for
2 系统实现
2.1 监测代理与监测器
如图1所示,文中实现了提出的异常检测方法的原型系统,主要包括监测代理、系统调用监测器、微服务分析器和异常检测器等四个模块。
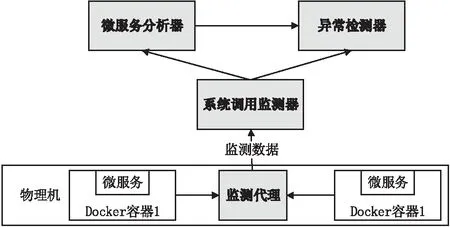
图1 微服务异常检测系统架构
在实际部署中,系统调用追踪技术通常采用ptrace软件工具,对于每个系统调用,被追踪的进程会暂停两次,因此会引入巨大的资源和性能开销。为了以较小开销实现非侵入系统调用监测,该文使用eBPF内核虚拟化技术,无需自定义内核,将用户定义的字节码程序动态注入到内核挂钩函数,以监测关注的内核事件,支持即时编译以在内核中以主机速度运行。使用基于eBPF的系统调用追踪程序vltrace,确定每个系统调用的进入和退出位置,并记录系统调用的众多参数。但vltrace采用重量级监测方案,不提供运行时的灵活性,一旦eBPF程序被编译并加载到内核中,其追踪行为便会保持不变,因而难以在每个微服务上动态启用/禁用追踪以最小化开销。该文仅在每个系统调用中,记录系统调用的ID和时间戳,并且进行扩展以收集特定于系统调用上下文(例如,用于打开、读取、写入等文件描述符)的细粒度系统调用监测信息。动态打开/关闭不同PID追踪,无需重新加载eBPF追踪工具软件,只需写入访问的内核PID表。当加载新的微服务时,Docker容器运行时环境会将主要PID通知给用户空间信息收集器的守护程序。然后,将所有PID记录在进程树的PID表中,特定的PID积累足够的追踪数据时,将PID标记为停止追踪,并汇总记录信息。
2.2 微服务分析器
微服务的中心数据库从系统调用监测器收集系统调用序列以持久化存储。监督式贝叶斯学习模型由训练和检验两个阶段构成。在训练模式下,系统调用监测器向模块提供系统调用序列训练数据集,并且将其标识为特定微服务执行单元的训练数据。微服务分析器模块检查大小为k的输入序列,并为微服务建立k阶转换矩阵。如果已经学习了该微服务类型,那么就存在相应的转移矩阵,新的序列数据将会增强该模块,而后将矩阵的转换次数归一化,使用Dirichlet优先级将其初始化。在检验模式下,测试序列输入到该模块,对于每个训练的微服务,使用k阶矩阵计算序列的概率分布。选择最高概率的微服务类型,并声明该序列数据属于该微服务类型。微服务之间的概率分布随测试序列长度的增加而变化,如果微服务已成功分类,则该微服务的概率将迅速收敛。
2.3 异常检测器
对于每个微服务执行单元uj,实现序列到序列的自动编码器AEj集合,重构原始输入序列为输出序列,对新添加的序列数据进行异常检测。输入序列在输入自动编码器之前转换为编码矢量;自动编码器将此序列编码为64维特征向量;输出重复L次以构建中间序列(L为输入序列长度);中间序列经过具有softmax激活函数的时间分布Dense层,被另一个具有64个输出单元解码为原始的编码输入序列。
3 评 价
3.1 监测开销
实验环境部署7台虚拟机(VM),每台VM具有2.40 GHz虚拟CPU内核,32 GB内存,运行在CentOS 8.0,启动了bcc和eBPF JIT以监测微服务运行。
本节评价原型系统对资源和性能的影响。对于CPU资源开销,基于eBPF的内核追踪程序监测微服务的每个进程的前N个系统调用,忽略后续系统调用,比较了两种不同设置下服务器的CPU使用率。首先,在裸服务器上部署微服务,不启动eBPF与监测数据搜集器,监测服务器的总CPU时间。而后,运行eBPF追踪器和监测数据收集器,但是禁用对微服务的追踪。重复产生相同负载,MySQL、MongoDB、WordPress、ownCloud、Joomla的CPU时间开销分别为3.47%、2.58%、4.17%、4.86%、3.08%,微服务监测的CPU时间开销低于5%。
在性能开销方面,本节运行三个基准程序iperf、dd和gzip,分别模拟网络I/O、磁盘I/O与CPU密集的微服务,分别启动和不启动系统调用监测。iperf模拟网络I/O密集微服务,性能衰减5.17%;dd模拟磁盘I/O密集的微服务,性能衰减7.26%;gzip模拟CPU密集微服务,性能衰减3.14%。实验结果表明,对于不同类型的工作负载,监测系统引入了较少的性能开销。
3.2 微服务分类
通过在原型上部署各种实际的微服务以评估原型系统的分类能力。该文选取NoSQL数据库、SQL数据库、KV数据库、HTTP服务器、文件系统、远程访问、内容检索、内容服务等八类24个典型微服务,产生工作负载,搜集系统调用序列数据以构成训练数据集合。选取的微服务中有一些具有更高的相似度,例如,MariaDB和MySQL都是执行数据库相关操作;Nextcloud从ownCloud派生而来,继承了其许多功能;WordPress和Drupal都是在Apache HTTP服务器上运行的基于PHP的Web应用程序,具有共享相同的PHP API和请求处理机制。
使用特定于微服务的工作负载生成器或手动访问微服务执行单元来生成工作负载,从而收集系统调用序列数据。当微服务启动多个进程时,从各PID收集单独的系统调用序列,而后将其连接起来以形成每个微服务的长序列。由于工作负载的重复系统调用行为会在条件概率矩阵中产生偏差,序列中连续重复的最大数量限制为12。在不同的微服务中,所得序列的长度范围从18K到450K。将每个微服务获得的序列细分为训练和测试序列数据,前者输入到模型进行训练,而后者则用于评估该模型执行的分类准确性。
选择三种不同的微服务类别,包括Web应用、SQL数据库和NoSQL数据库,检测是否可以准确识别不同类型。图2表示微服务分类精度与序列长度的关系。为了生成不同长度的测试序列,从收集的原始测试序列中提取长度为N的随机子序列。对于每个长度N,使用180个测试序列样本进行分类,并计算准确率。实验结果表明,随着测试序列长度的增加能够正确区分微服务类型,NoSQL数据库、Web应用和SQL数据库分别需要长度约800、1 000和1 200的系统调用序列。
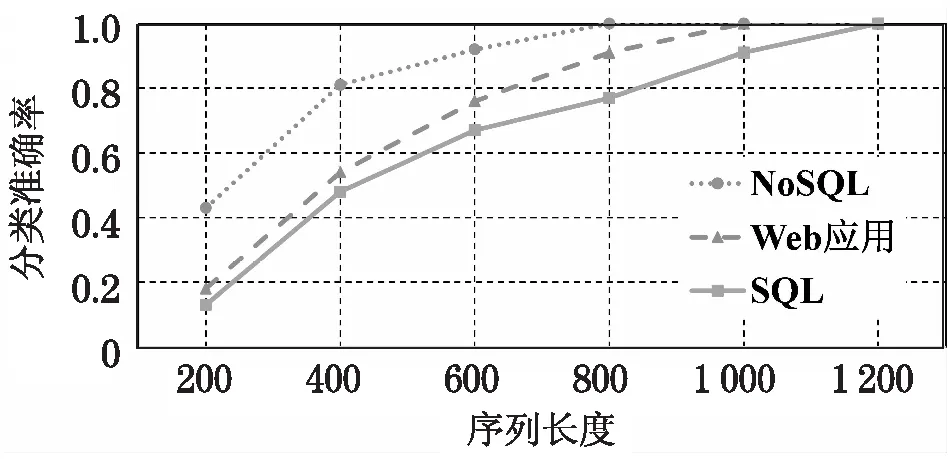
图2 微服务分类准确率
3.3 异常检测
该文评估基于自动编码器的异常值检测的性能。异常值检测过程依赖于自动编码器产生的重建损失,因此需要设置合理的损失阈值,使得最小化漏报率,即异常测试实例检测为正常(false negative,FN)和错报率(false positive,FP),即正常测试实例检测为异常。该文使用此前搜集的24个微服务的系统调用序列数据集来评估,以800个输入序列训练每个AEj,每个序列的长度为1 000。
采用单一自动编码器学习现有所有执行单元生成的系统调用序列集合,然后针对给定的测试序列进行检测,如果自动编码器返回的重建损失高于L,则检测为异常。图3显示了损失阈值对异常检测准确性的影响,从24个微服务中删除了2个微服务,并为剩下的22个微服务训练了一个自动编码器。然后,对于经过训练的自动编码器,将删除的微服务所产生的系统调用序列视为异常值。据此方法,准备了24个自动编码器,每个编码器将缺失的微服务产生的系统调用序列检测为异常值。对于特定的损失阈值L,从24个服务中随机选择一个微服务,使用准备好的自动编码器执行异常检测,每个实验重复执行180次,计算异常检测精度。如果将阈值L设置过高,则会将更多的异常序列错误分类为正常(即,假阴性)。如果将阈值L设置过低,则会将正常序列错误分类为异常(即假阳性)。使用单一自动编码器无法同时将假阳性和假阴性最小化,可达到的准确度低于53%。为每个微服务类型训练一个单独的自动编码器,实现两级异常检测。将前面使用的24个微服务分为六组,根据异常类型将异常检测应用于每个分组,而后检测每个微服务类型异常检测的准确性。异常检测的准确性随损失阈值而变化,实验结果表明,当合理选择损失阈值,可以实现零假阳性和假阴性错误。

图3 异常检测准确率对比
4 相关工作
系统调用监测主要用于异常入侵和恶意软件检测,着重于识别与正常系统行为偏离的异常。基于系统调用监测,当前研究工作提出了许多异常检测模型,例如子序列分析[6]、行为马尔可夫模型[7]、有限状态自动机[8]、动态贝叶斯网络[9]和深度神经网络[10]。文献[11]提出了一种在系统调用级别的强制执行安全策略,捕获正常应用程序行为自动生成的安全策略,可以在每个系统调用的基础上实现简单的准入控制,而无需考虑跨系统调用序列的依赖性。以上方法的适用性仅限于网络应用或网络协议[12],而文中的方法则普遍适用于应用程序的多种工作负载。文献[13-14]提出了基于半监督学习的离群值检测方法,针对标记样本和未标记样本混合的情况,通过k-means算法聚类以识别离群值,但以上方法只适用于系统规模较小的情况,难以应对微服务类型众多、依赖复杂的应用实际部署场景[15]。
5 结束语
微服务架构的异构性和动态性对数据中心的运维管理带来了挑战,已有运行监测技术通常采用统一模型分析应用运行状态,然而多样化微服务的软件行为差异巨大,难以通过单一模型刻画。针对以上问题,提出一种基于系统调用模式识别的微服务异常检测方法。使用非侵入的轻量级系统调用追踪技术监测微服务的运行状态,基于贝叶斯学习刻画微服务行为,根据微服务行为特点进行分类,在特定微服务类型下,学习微服务运行状态模型,基于自动编码器检测微服务行为异常。实验结果表明,该方法具有较低的性能开销,能够有效区分微服务类型,并且准确检测微服务异常。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年4期)2022-08-05
传感器世界(2022年3期)2022-05-24
数字技术与应用(2021年1期)2021-03-24
智能计算机与应用(2016年6期)2017-05-08
小天使·一年级语数英综合(2017年3期)2017-04-25
莫愁(2017年9期)2017-04-07
汽车博览(2016年9期)2016-10-18
小学阅读指南·低年级版(2016年1期)2016-09-10
中国信息化·学术版(2013年1期)2013-05-28
