
面向HPC的函数计算冷启动优化 *
2020-11-30 07:36谭郁松
计算机工程与科学 2020年11期
李 哲,谭郁松,李 宝,余 杰
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
高性能计算问题的解决往往需要用到大量的计算资源,包括足够的内存、足够的存储空间以及为了提升并行计算效率的大量CPU。利用以虚拟机为节点的传统云计算架构,租用大量的云计算资源是一个不错的解决方案[1]。然而,在传统云计算的架构模式下,用户不仅需要针对计算任务做出复杂的分布式设计,同时也需要租用大量的额外计算资源来应对高性能计算问题中可能出现的峰值现象[2]。在实际的任务执行过程中,还需要考虑到节点的故障与恢复等问题。另外,在整个高性能任务执行过程中,申请的云计算资源并不会一直处于满负载或者高负载的状态,导致被用来应对峰值效应的很大一部分资源都出现了浪费现象。
函数计算是近几年诞生的一种全新的云计算范型,是无服务器计算的一种服务模式[3]。与传统云计算相比,用户在函数计算平台上不再需要关心服务器的维护和一些分布式特性的管理,只需要通过函数计算平台提供的相关接口将代码上传,并设定好预期使用资源和运行时长等参数,就可以将其当作一个完整的分布式应用运行。图1给出了一个典型的函数计算平台架构图。每一个云函数是一个基本的计算单元模型,包括了待运行的代码包、一系列参数设置以及相关的配置文件等。每个云函数都可以独立执行自己的业务逻辑,也可以通过函数调用的方式与其他云函数进行交互。通常一个计算任务会由不同的事件触发而执行,这些事件可以由不同的事件触发器(HTTP触发器、定时触发器和对象存储服务触发器等)进行捕获。
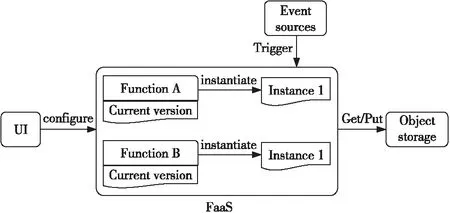
Figure 1 Architecture of FaaS图1 函数计算平台架构图
当函数计算平台收到一个请求时,平台会先定位到相关的云函数,然后会根据云函数提供的配置信息(业务代码、资源限定参数等)提供一个能够处理该请求的容器。容器作为函数计算最基本的计算实例,具有独立的计算资源和运行空间,并且装载了对应云函数所必要的运行环境和相应的业务代码。在处理高性能并发请求的时候,函数平台能够根据请求数量自动地进行扩容,而不需要用户进行管理。同时对单个容器而言,当前容器最大允许使用的内存由用户自行设定。这种快速自动扩容的机制恰好能够很好地用于高性能计算中的并行任务[4],而且不会造成大量的计算资源浪费。这种由平台隐性提供的备用资源措施虽然能够节省很大一笔费用,但也带来了一个函数计算平台上存在的潜在问题——冷启动延迟问题。如上文所述,一个对云函数的请求是由平台所提供的函数容器进行处理的,如果这个容器是之前刚使用过的(通常一个容器被使用完能够存活15~20 min[5]),那么几乎不用额外的启动耗时就可以接着处理新来的请求。但是,如果该云函数一开始就不存在相关函数容器实例,平台就需要为其新创建一个,而在平台收到请求到完成请求处理的这段时间中,需要花费额外的时间来进行容器初始化、运行环境初始化和代码下载等准备工作。这部分任务执行之外的额外耗时被称作冷启动延迟。尽管一次冷启动延迟最多可能仅达到几百毫秒,但考虑到高性能计算应用存在很大的并发量,这个问题就会被严重放大。
针对上述问题,本文结合阿里云提出的快速扩容机制[6],提出了一种通过预热方式来降低冷启动延迟的方法,该方法能够有效地降低函数计算平台在执行高性能计算这一类任务时产生的冷启动延迟。本文第2节介绍有关高性能计算任务和函数计算问题的相关工作;第3节和第4节将对提出的方法进行定义并通过一个高性能计算问题的实验来说明其优化效果;最后对所完成的工作做一个简短的总结并给出今后的工作计划。
2 相关工作
Chung团队[6]在很早就做过高性能计算与容器虚拟化技术结合的研究工作。他们在容器(docker)上运行最常用的高性能计算测试工具HPL(High Performance Linpack)[7]和 Graph500[8],用容器化的方式来执行高性能计算任务。同时他们比较了在虚拟机和容器2种模式下高性能计算任务的执行性能,发现在容器上的运行效果远远好于在虚拟机上的效果。而Spillner团队[9]则进一步将高性能计算问题迁移到了函数计算平台来处理。Josef团队设计了4个典型的高性能计算问题:斐波那契数列、人脸检测、密码破译和天气预测。这4个问题的共同特点是都是计算密集型,而计算密集型任务恰好能够很好地适应函数计算这种计算模式[9,10]。
Malla等人[11]通过实验详细对比了高性能计算任务在函数计算平台上和传统云计算平台上执行的各项结果,包括执行的速度、所需的时间和租用的经济成本等。作者以蛋白质序列匹配算法作为测试任务,分别运行在谷歌的函数计算平台(GCF)上和传统的基础设施平台(GCE)上。他们发现尽管GCF的性能会产生一定的波动,但在相同的性能下,使用GCF会比GCE更加便宜。另一方面,这2种执行模式都会产生前期的任务准备耗时,但在GCF上表现得更为明显。这是因为在任务准备阶段,平台需要在短时间内生成大量容器实例,从而导致冷启动延迟较长。
针对函数计算平台上存在的冷启动延迟这一问题,Lin等人[12]提出利用容器池来对使用过的容器进行保存。他们利用已有的开源函数计算框架Knative[13]进行改进,通过在框架中加入容器池请求的步骤达到优化的目的。这种优化方式在容器实例较少的情况下的确能够有不错的表现,但如果处理高并行度的计算任务,其劣势就很明显,因为不可能每次都提前预存好上百个容器实例。为了使函数计算平台更好地用于解决高性能计算这种短期内并发度较高的计算问题,阿里云提出了一种容器的动态加载技术,能够在短时间内快速复制出大量相同的容器实例,其实验结果显示能够达到秒级启动一万个容器的效果[14]。
上述工作已经证明高性能计算能够很好地和函数计算结合,与此同时函数计算平台在处理该类问题时也确实存在一定的优化空间[15,16]。上文给出的优化策略,很多都是从架构的角度重新设计一个新的函数计算平台,这对于一般的云计算开发者来说无疑是复杂且耗时的。因此,本文将基于阿里云的公有云函数计算平台,结合阿里云平台自身的快速扩容策略,从用户使用的角度出发,提出一种结合时间序列分析技术的预热方法,来有效降低高性能计算问题在函数计算上的冷启动延迟。
3 冷启动分析
实际上高性能计算在函数计算平台上的冷启动现象已经在一些研究工作中被观测到过[17,18]。为了更清晰地展示观测到的冷启动延迟,本节设计了针对不同编程语言的实验,通过调整计算量大小来观察冷启动延迟是否会发生明显的变化。观测实验部署在国内2个知名的函数计算平台上,分别为阿里云的FC(Function Compute)[19]和腾讯云的SCF(Serverless Cloud Function)[20]。
第1个实验不包含复杂的逻辑,仅执行一句“hello world”的输出,目的是测试冷启动延迟在函数计算平台上的存在性。在模拟冷启动时,只需新建一个云函数,那么第1次请求就符合冷启动的条件——不存在该云函数的任何容器实例;对于热启动,只需执行完一次请求后接着执行,就能够满足。本文对FC和SCF上支持的语言都进行了测试,如表1所示,短横线“-”表示FC不支持Go语言。从表1中可以看出,几乎所有的实验中都存在明显的冷启动延迟现象。另外发现,在测试脚本语言Python时,冷启动和热启动运行时长几乎没有差别,这很可能是因为平台事先准备好了相关的容器,而脚本语言的环境并不需要任何的预加载。与之相反的是Java,可以很明显地观察到其在冷启动下的执行时长要远远超过在热启动下的执行时长。这是因为即使平台预先准备好了容器,但Java这种跨平台语言运行之前需要包含JVM的启动过程以及类的加载过程,因此可以很明显地观测到。在接下来的实验中,我们也会选取Java这种易观察到冷启动现象的语言来进行实验。
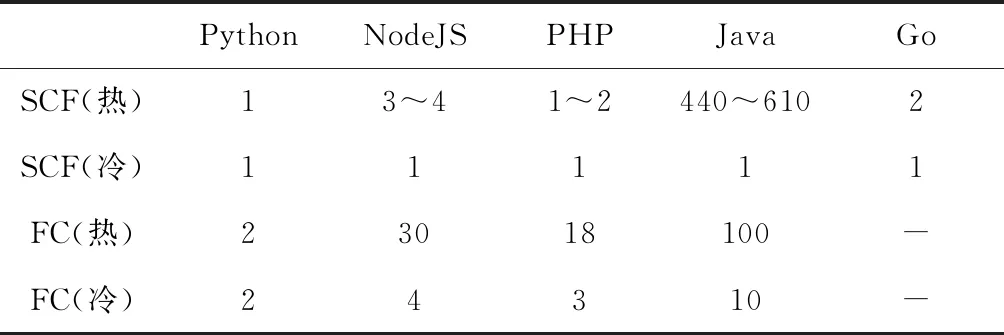
Table 1 Simple task executed on SCF and FC in the way of cold start and warm start
在第1个实验中,观测到了冷启动延迟在函数计算平台上的存在,相对于其他编程语言而言,Java的冷启动延迟最为明显,所以接下来的第2个实验利用Java这种冷启动延迟明显的语言进一步分析冷启动延迟是否受到计算量、内存设定大小以及一些其他因素的影响。实验环境为:JDK 1.8,Maven 3.6.1以及阿里云的FC平台。这个实验利用FC在不同内存设定下计算不同计算量的递归版本的斐波那契数列,然后每种样例分别在冷启动和热启动情况下测试10次,观察对照2种启动模式下的执行情况。
计算任务大小实验结果如图2所示。图2a描述的是运行时长与内存大小之间的关系,在该实验中,计算量是保持一致的(即斐波那契数列的计算长度是一致的)。尽管当内存被设定为256 MB时,运行时长会处于最低,但仍然远远高于热启动的运行时长。如图2a所示,在不同的内存设定中,2种启动模式下的平均运行时长分别为108 ms和13 ms,其差值大约为100 ms左右。图2b展示了计算量大小与在不同启动模式下的延迟关系,从中可以看到,尽管在冷启动和热启动2种情况下,运行时长都会呈指数增长,但是二者的差值仍然保持在100 ms左右。这表明冷启动延迟是一个趋于稳定的值。
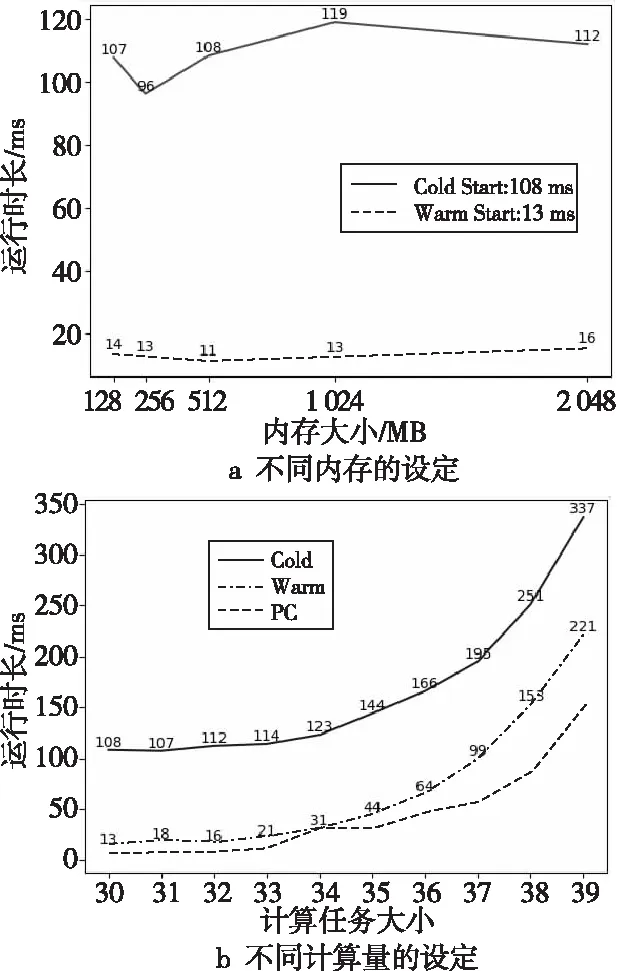
Figure 2 Different cases of Fabonaci sequence test图2 不同参数设定下的斐波那契数列运行结果
最后在第3个实验中观察了FC本身采用的快速扩容机制。在计算斐波那契数列的实验中,利用阿里云FC提供的SDK进行了并发请求的测试。每次测试中,在客户端同时向同一个云函数发送10条执行请求,并观察其平均执行时长。其中斐波那契数列的计算量设定为递归计算第35项,同时将云函数的最大允许使用内存设定为512 MB。如表2所示,当一个云函数存在1个容器实例时,意味着1个热启动处理和9个冷启动处理,那么10条请求的平均处理时长并不会太长,仅仅比单次热启动延迟多17 ms;而当不存在容器实例时,意味着10条请求都是冷启动,此时平均处理时长不仅仅高于单次热启动时长,甚至比单次冷启动时长还要高出将近30%。这个实验结果说明,阿里云能够利用一个已有的完整容器——阿里云容器团队提出的DADI加速器[14]进行快速扩容。

Table 2 Concurrent requests test 表2 并发请求实验 ms
一般而言,一个完整的容器启动镜像往往有上百MB甚至达到GB级,如果每次将已有的镜像完整加载,那么耗时是很高的。阿里云提出的DADI加速器避免了传统容器“下载镜像 > 解压镜像 > 启动容器”的启动步骤,容器的启动耗时以及扩容时间大大缩短,这其中包括3点优化:(1)镜像格式优化:DADI团队设计了一种新型的镜像模式,无需下载和解压全部的完整镜像即可直接访问;(2)按需P2P数据读取:DADI利用树形P2P网络对数据进行分发,即少数P2P根节点从Registry获取,其他节点(宿主机)之间可相互传输数据,利用已有容器快速分发数据到所有节点从而进行扩容;(3)高效的压缩算法:DADI提供了一种新型的压缩文件格式,可按需单独解压用户实际访问的数据,且解压时间开销可忽略不计[14]。
4 解决方案
函数计算平台最大的一个特点是不会暴露给用户任何能够直接操控容器的接口,因此站在用户的使用角度只能够通过调用接口进行优化。本文提出的策略就是提前预测请求到来的时间,然后触发该云函数产生一个完整的容器实例,让之后到来的请求以热启动的方式运行。
在本节首先对要用到的开源预测工具Prophet[21]进行测试,接着采用本文提出的预热方式,分别对密码破译以及多容器协同求π值等场景进行实验。其中的对照实验包括热启动后的执行效果和冷启动后的执行效果。在冷启动的实验中,为了保证每一次调用都是冷启动调用,实验在每次测试时重新创建新的云函数,同时在运行结束后,将该云函数删除,这样就可以保证下一次不会使用到先前残留的热容器实例。
4.1 预测请求时间
Prophet是Facebook提供的一款开源的时间序列分析工具,可以广泛应用于现实生活中的各类时间序列分析问题。Prophet认为任意一个时间序列,都由以下几个部份组合而成:
ypredict(t)=g(t)+s(t)+h(t)+p(t)+ε
(1)
其中,t表示待预测的时间;ypredict(t)表示预测值,g(t)表示数据的大趋势(比如整体的预测值呈上升趋势);周期项s(t)表示周期性的变化趋势,即s(t)的值每隔一个周期就会重复出现相同的变化趋势,周期内的单位时间间隔由数据本身决定(比如每分钟,每小时,本文实验的单位时间间隔为每5分钟),而每个周期内包含的总的时间间隔是相同的;h(t)表示特殊事件(比如节假日);p(t)表示外部因素的影响(比如天气因素、环境因素);ε表示噪声。
本文利用Prophet预测请求时间,本文所涉及到的请求日志数据是每5分钟一次请求的时间序列,不考虑复杂的特殊性因素,这类时间序列存在以每天为单位的周期性,同时并不具备长期变化的大趋势。在这种情形下,只考虑周期项s(t)即可,s(t)可表示为:
(2)
其中,P表示频率,在本文所考虑的情形下,时间序列为每5分钟一次,周期为每天,因此有P=24*60/5=288。
s(t)可表示为2个向量相乘的形式:
s(t)=X(t)·β
(3)
其中,
1≤n≤N
(4)
β=[a1,b1,a2,b2,…,aN,bN]T
(5)
关于N的取值,通常Prophet会根据周期大小给定一个默认值。可以看到的是,N的取值越大,考虑的分量因素就越多,预测得更加精确但是更容易导致过拟合。s(t)的整个预测过程就是通过已有的时间序列拟合出参数an和bn(1≤n≤N),然后再利用拟合出的参数预测相应的时间值,最终得到预测结果。
由于并不能获取到FC的用户日志信息,本文利用Prophet在Github上提供的测试数据集进行了测试。该数据集包含18 000条时间序列,是一个连续2个月左右、间隔5分钟的时间序列数据集,精度都为秒级,同时每条序列后都对应一个y值,代表5分钟内的请求数量。为了模拟函数计算的请求,本文根据y的范围取中间的值作为一个阈值,超过阈值的y设置为1,表示该时间点的未来5分钟内存在一个即将到来的请求;低于阈值设置为0,表示未来5分钟没有请求到来。实际上1可以表示一条请求或多条请求,因为在实验设计中,无论是一条请求或者是多条请求,只要是在5分钟的时间段内,实际上都只会对云函数进行一次预热处理。另外,考虑到容器的存活时间具有延续性——每次处理完新的请求,都至少能再存活15分钟左右,因此本文的实验策略就是比较预测时间点和实际时间点的请求处理状态是冷启动处理还是热启动处理即可。比如一段连续的预测值为:1(第5分钟有请求),0(第10分钟无请求),0(第15分钟无请求)。而实际值为:1(第5分钟有请求),1(第10分钟有请求),1(第15分钟有请求)。由于容器存活时间具有延续性,那么预测点的状态就为:第5、10、15分钟该容器都是处于热状态的,刚好能以热启动的方式处理实际到来的请求。也就是说,只要容器状态为热启动状态,那么无论是否有请求到来,容器都保持热状态。基于此得出的平均预测准确率大约为86%,说明该预测工具在这种情况下的预测准确率还是相当不错的。
4.2 单容器实例破译密码
本节首先对单容器运行案例进行测试,测试用例是通过云函数暴力破解一个5位数的随机密码。该随机密码由数字0~9以及所有的大小写字母组成,随机初始种子可由用户指定。实验测试一共分为3个部份:冷启动测试、热启动测试和预热后测试。
在函数的设计上,实验中的该云函数会被绑定一个HTTP触发器,该触发器可以捕获任意访问该云函数的HTTP请求。通过对HTTP请求参数的解析,云函数可以决定如何进行下一步操作。在每次请求中会加入2个参数,分别是execute和seed。只有当execute的值为true时,云函数才会执行密码破译的任务,同时根据给定的种子值seed,去生成一个随机的5位密码;而当execute被指定为false时,则不会执行任何计算任务,直接退出。这样做的目的是为了对该云函数的容器进行一个最快的预热处理,使预测到的请求能够热启动执行的同时尽可能地减少不必要的计算成本。
在冷启动测试的过程中,每次利用相同的执行代码创建一个新的云函数,以此来保证每个容器不会被复用。另外,将execute参数直接设定为true,使云函数一收到请求就直接开始执行,同时执行完毕后删除云函数及其绑定的触发器。在热启动实验中,首先创建一个云函数,顺序执行多次请求(得到响应结果后再发出下一次请求,同时请求的参数execute设定为true)后,再开始进行测试。这样就可以保证每次测试使用的都是同一个云函数容器实例。预热实验的执行过程则分为多个步骤进行。因为该方法本身就是为了优化冷启动问题,所以仍然需要像冷启动测试过程一样,每次都创建新的云函数和触发器。在处理请求第一步首先对云函数进行预热处理,将execute参数设置为false,并发送一条请求;当收到响应信息后,再将execute参数设定为true,并给seed赋值,令之前产生的容器实例执行密码破译任务。每种情形都进行10次测试,而为了保证计算时长的一致性,设定的seed也都一致,最终的测试结果如表3所示。

Table 3 Single task request test 表3 单任务请求实验 ms
在预期上,单容器实例预热启动的2步总耗时应该和冷启动耗时大致相同。一次完整的预热启动过程包括信号预热和执行请求2个部分,其中预热时长为183 ms,执行时长为973 ms。表3所示的运行结果基本上与预期值一致,即预热后的执行能够至少减少183 ms的启动延迟。由于单步冷启动执行被分为2步,这个并不连续的过程会导致预热启动的总耗时略微高于单次冷启动的执行时长,但对用户而言,增加的3 ms和减少的183 ms相比几乎可以忽略不计。另外读者可能会发现,即使预热后执行,仍然比热启动执行时长略高,这是因为阿里云采用了动态镜像加载的优化策略,在每次执行时只加载完整镜像中运行所必须的一小部分文件。而热启动实验是在单个容器执行了几次之后才开始进行的,因此容器内所需的代码运行环境已经加载完全,运行时长会比预热后的第一次运行时长更短。
4.3 多容器实例协同计算π值
本节利用阿里云的快速扩容机制对多容器实例协同处理问题进行测试。与4.2节实验一样,仍然为每一个云函数绑定HTTP触发器,同时通过HTTP请求传参的方式告知云函数进行预热处理还是执行任务。为了模拟高性能计算在函数计算平台上的执行过程,本节设计了一个多容器实例计算泰勒展开式的实验。该实验利用多个容器实例协同计算π的泰勒展开前1亿项来近似逼近π,如公式(6)所示:
(6)
本节设计了2个云函数来解决这个问题,如图3所示。执行过程分为3步:首先从客户端向counter云函数发送执行请求,请求中会包含3个参数:execute、n和N,分别代表是否执行计算任务、执行计算任务所需计算实例的个数(即图3中的Computing Unit函数)和泰勒展开式的项数;接着counter根据接收的参数在同一时刻向Computing Unit函数通过线程池发送n条请求,并在每条请求上分别设定好对应实例所需计算的泰勒展开项式的位置(比如第i条请求计算泰勒展开式的第j到第k项),同时由counter中的每一个异步请求结果类(Java中为FutureTask类)对请求结果进行维护;当所有的请求都发送出去后,counter实例则会通过轮询的方法将所有Computing Unit实例结果进行汇总,并由counter实例将结果返回给客户端。本节n设置为10,N设置为100 000 000。
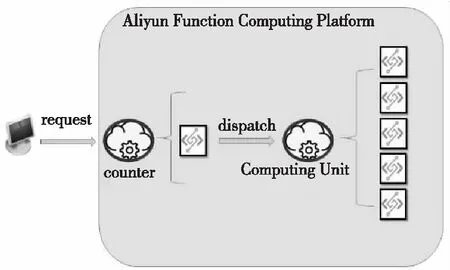
Figure 3 Architecture of π computing task图3 多容器计算π值架构图
与4.2节一样,实验分别对冷启动情形、热启动情形和预热后情形进行测试。与4.2节实验不同的是,本节实验涉及到了二次请求,即客户端先请求counter,counter再请求Computing Unit。在冷启动和预热实验测试中,为了保证每次请求都产生新的容器,仍然采用“创建—调用—删除”云函数的操作方式。另一方面,如第3节测试结果显示,单个Java运行环境至少需要100 ms才能完全初始化,而一个容器实例必须响应完当前请求之后,才能继续响应下一请求,因此当counter向Computing Unit瞬时发送出n条请求时,能够保证每条请求都产生一个全新的容器实例来对请求进行处理。在热启动实验中,利用上一次被使用过的冷启动容器来保证实验是在热启动模式下完成的。在预热实验环节,本节利用阿里云提供的策略对counter和Computing Unit仅预热出一个容器实例,而实际所需的剩下n-1个实例,则通过阿里云的扩容策略进行快速复制。
实验结果如图4所示,一次完整的预热测试包括容器预热和执行计算任务2个过程。从图4中可以看到,冷启动情形下单次请求的执行时长为7 300 ms,远远高出热启动情况下的执行时长578 ms。而在本文提出的方法中,预热时长大约为360 ms,执行计算任务时长大约为4 500 ms。同冷启动情形相比,利用阿里云平台本身的快速扩容机制,预热措施的确能够有效地缩短冷启动延迟。但是另一方面发现,无论是冷启动还是预热之后的执行时长,都远远高于热启动情形下的执行耗时。发生这种现象的原因可能有2个:第1是因为counter和多个Computing Unit本身的冷启动延迟效应,在容器启动时存在一定的延迟;第2则是2种情形下的容器环境并没有加载完全,而热启动的测试都是在冷启动环境执行多次后进行的测试。
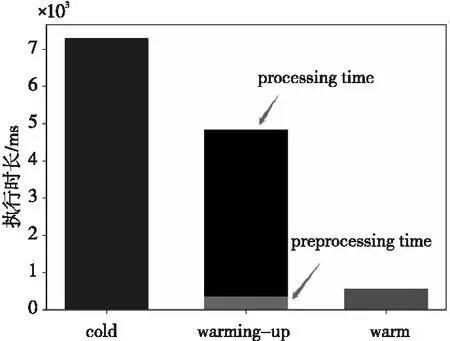
Figure 4 Result of π computing task图4 多容器计算π的实验结果
5 结束语
高性能计算任务已经被证明能够有效运行在函数计算平台上,但其对计算资源的需求非常高,尤其是当整个任务被划分为大量子任务时,需要平台提供大量的容器实例来满足其执行需求。在并发任务过多的情形下,由于需要产生多个实例,同时可能需要进行一些结果同步的操作(比如4.3节),冷启动延迟会严重增加单次任务执行的总耗时,本文提出一种结合快速扩容机制进行提前预热的方法来解决该问题。整个过程非常简单,只需要利用时间序列分析工具预测请求到来的时间点,并在合适的时间段内利用信号将相应的云函数提前预热即可。实验结果表明,无论在单容器实例情形还是多容器协同计算情形下,本文方法都可以在一定程度上减少冷启动延迟。未来的工作需要更多地去探索其他高性能应用场景来验证本文方法。
猜你喜欢
重庆大学学报(2022年6期)2022-06-23
客联(2021年2期)2021-09-10
电子制作(2017年19期)2017-02-02
山东工业技术(2016年15期)2016-12-01
汽车维护与修理(2015年1期)2015-02-28
汽车零部件(2014年8期)2014-12-28
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
军事体育学报(2014年4期)2014-02-27
