
基于图像融合与YOLOv3的铝型材表面缺陷检测
2020-11-24 07:06郎贤礼
计算机与现代化 2020年11期
张 磊,郎贤礼,王 乐
(合肥工业大学仪器科学与光电工程学院,安徽 合肥 230009)
0 引 言
随着工业化进程的不断推进,我国产业制造的不断转型升级,以及现代计算机技术的飞速发展,现代工业对自动化程度的要求越来越高,工业体系向着智能化的方向发展,人们对工业产品表面质量、精度以及可靠度的要求也越来越高。然而在提高生产效率的同时,产品的表面缺陷问题仍然不可避免。
目前,大多数铝型材生产企业仍采用传统的人工目测方式对铝型材表面进行缺陷检测,主观意识影响大,不仅效率低下而且稳定性差,容易产生误检、漏检等情况。传统的基于人工测量的表面缺陷检测越来越不能满足对铝型材产品检测精准度以及检测速度的要求。因此,基于机器视觉[1]、深度学习[2-3]的目标检测[4-5]技术应运而生,并且蓬勃发展。研究人员开始关注基于深度神经网络[6-7]的计算机视觉[8]算法来进行检测,两阶段检测模型有R-CNN[9]、SPP-Net[10]、Fast R-CNN[11]、Faster R-CNN[12-13]、R-FCN[14]、Mask R-CNN[15]等;单阶段检测模型有YOLO[16-18]系列、SSD[19]、DSSD[20]、FSSD[21]、RetinaNet[22]等。利用深度学习可以解决因铝型材表面缺陷种类多、成像不清晰、噪声干扰大、对比度低、纹理背景复杂、缺陷区域小和整体亮度不均匀等问题造成的检测困难,此外,利用深度学习对铝型材表面进行缺陷检测具有速度快,精准度高等特点。
基于机器视觉、深度学习的方法在工业缺陷检测领域有着良好的应用背景。李宇萌等人[23]基于机器视觉获取点云数据,对其进行预处理,提出了一种基于点云的转子表面缺陷检测方法;姚明海等人[24]结合边缘检测和模板匹配算法,提出了一种基于深度主动学习的磁片表面缺陷检测方法;魏若峰[25]基于深度卷积神经网络,提出了一种具有自适应、自学习特点的铝型材表面瑕疵检测网络;纪艳玲等人[26]提出了一种改进的K-means聚类分割和LVQ神经网络分类的方法,用于OLED显示面板缺陷像素的识别。
本文利用图像融合[27]与YOLOv3的方法,借鉴了SLAM[28]中特征提取与匹配的思想来检测铝型材表面缺陷,实现缺陷的特征提取、定位、自动分类和置信度输出。该方法不仅可以提高检测效率,还可以提升检测精度和准度,具有更强的特征提取能力和泛化能力。
1 缺陷检测方法
利用YOLOv3进行目标检测是近年来研究的热点,但对于不同的目标使用单一的YOLOv3方法往往并不能达到最优的效果。本文提出一种基于图像融合与YOLOv3的铝型材表面缺陷检测方法。其具体思想是:先对原始图像进行预处理,然后对原始图像和处理图像分别进行特征提取和对比匹配融合得到融合图像(即最终的处理后图像);再通过K-means算法聚类和调参优化,最后利用物体检测模型YOLOv3进行表面缺陷检测,得到预测的图像。其原理框架如图1所示。

图1 基于图像融合与深度学习的网络架构
1.1 图像融合
为了提高缺陷位置的像素值,充分曝光缺陷,让目标检测器更精准有效地训练与检测,利用灰度变换增强和空域滤波的方法对图像进行预处理得到处理图像,然后借鉴SLAM中特征提取与匹配的思想,对原始图像和处理图像进行对比匹配融合得到最终的处理后图像。考虑到每幅图像特征位置、形状、大小等不同,为保证实验结果精确,分别对所有样本进行一一处理。
1.1.1 灰度变换增强
如图2所示,因各类样本特征信息不同,这里仅做出了2类样本(不导电和擦花)灰度变换增强的过程作为代表(下同)。先获取原始图像的灰度图像直方图,得出灰度值集中分布的区间(a,b),再通过公式(1)变换将灰度值尽可能地均匀分布在0~255之间,让图像变得更加清晰,得到增强后的图像及灰度图像直方图。
(1)
其中,x为a和b之间的灰度值,y为0~255之间的灰度值。

(a) 不导电原始图像及灰度图像直方图
1.1.2 空域滤波
如图3所示,采用模板和图像的领域相卷积的方法来进行空域滤波。先读入灰度图像,然后通过imnoise函数添加椒盐噪声,建立线性滤波模板,最后通过imfilter函数进行平滑滤波,得到相应滤波后的图像。

图3 空域滤波
1.1.3 特征提取与匹配
特征提取与匹配如图4所示。

(a) 特征点提取
图4借鉴了SLAM(Simultaneous Localization And Mapping)中特征提取与匹配的思想来处理图像。先找出原始图像和处理图像的像素特征点,再借鉴SIFT(Scale-Invariant Feature Transform)特征提取思想进行关键点描述与提取,找出缺陷位置像素信息的SIFT特征,然后对像素信息突出的相同位置(人工选取)特征点进行匹配,并返回匹配点对。最后用基础矩阵F(F是一个3×3的矩阵,表达了立体像对的像点之间的对应关系)过滤匹配的特征点对,画出匹配特征点的连接线。之后对匹配点对设置一个阈值(大于2倍最小距离即视为误匹配,因每张样本特征信息不同,最小距离不固定)进行匹配筛选,保留最优的特征匹配点对。
1.1.4 特征融合
特征融合过程如图5所示。

第一行依次为原始图像、灰度图、HSV图、单通道图、单通道深度图、RGB深度图;
图5依次作出了原始图像和处理图像的灰度图、HSV图、单通道图、单通道深度图、RGB深度图等得到关键特征(人工选取)信息。结合特征提取与匹配的关键特征信息,利用图像融合中亮度调整后按距离比例融合的方法,获取两图关键特征信息,得出重合部分,并转化为亮度图,把每点的亮度值相加,舍弃冗余特征,保留最优特征信息(关键特征交并比值及距离权重)进行特征互补融合,得到最终的处理后图像,并作出了它的灰度图、HSV图、单通道图、单通道深度图、RGB深度图。
1.1.5 处理后图像尺寸调整
原始图像的像素为2560×1920,为保证对照实验结果精确,在不改变特征信息的前提下,处理后图像的像素也调整为2560×1920。
1.2 YOLOv3网络模型
1.2.1 特征提取器
YOLOv3特征提取器在YOLOv2的Darknet-19基础上做了优化,命名为Darknet-53,比ResNet-101更好。包含52层卷积层和1个全连接层,加入了多个连续的1×1和3×3的卷积,借鉴了ResNet网络的残差结构,使用该结构可以让网络结构变得更深(YOLOv2的Darknet-19没有残差结构,YOLOv3的Darknet-53有残差结构),增加直接连接,并且网络层数达到53层。各模型框架在ImageNet数据集上特征提取效果如表1所示。

表1 模型框架在ImageNet上的效果对比
1.2.2 多尺度预测
在结果的预测上,YOLOv3使用了3个尺度,包括1个feature map为13×13的下采样,以及2个feature map分别为26×26、52×52的上采样。YOLOv3的416×416用了52个feature map,主要是为了提高小目标的识别能力。
YOLOv3每个位置预测3个bounding box,也就是anchors_num值为3,而在YOLOv2中会为每个bounding box预测5个坐标(tx,ty,tw,th,to)。另外有N个classes+4个coords+1个objectness,所以每个位置输出(N+4+1)×3个值,这就是每个尺度张量的深度,即cfg中的filters值。
1.2.3 K-means算法
使用K-means算法在整个尺度上均匀分割聚类得到anchor boxes来确定边界框的预测,对数据集重新进行聚类。K-means算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标。可以表示为将给定样本集D={x1,x2,…,xn}划分为G={G1,G2,…,Gk}的过程,每个划分好的簇中的各点,到G的质心μk的距离平方之和称为误差平方和,即SSE(Sum of Squared Error)为:
(2)
因此K-means算法应达到G1,G2,…,Gk内部的样本相似性大、簇与簇之间的样本相似性小的效果,即尽可能减少SSE的值。当k小于真实聚类数时,SSE下降幅度很大,而当k接近于真实聚类数后,SSE下降幅度明显减缓。
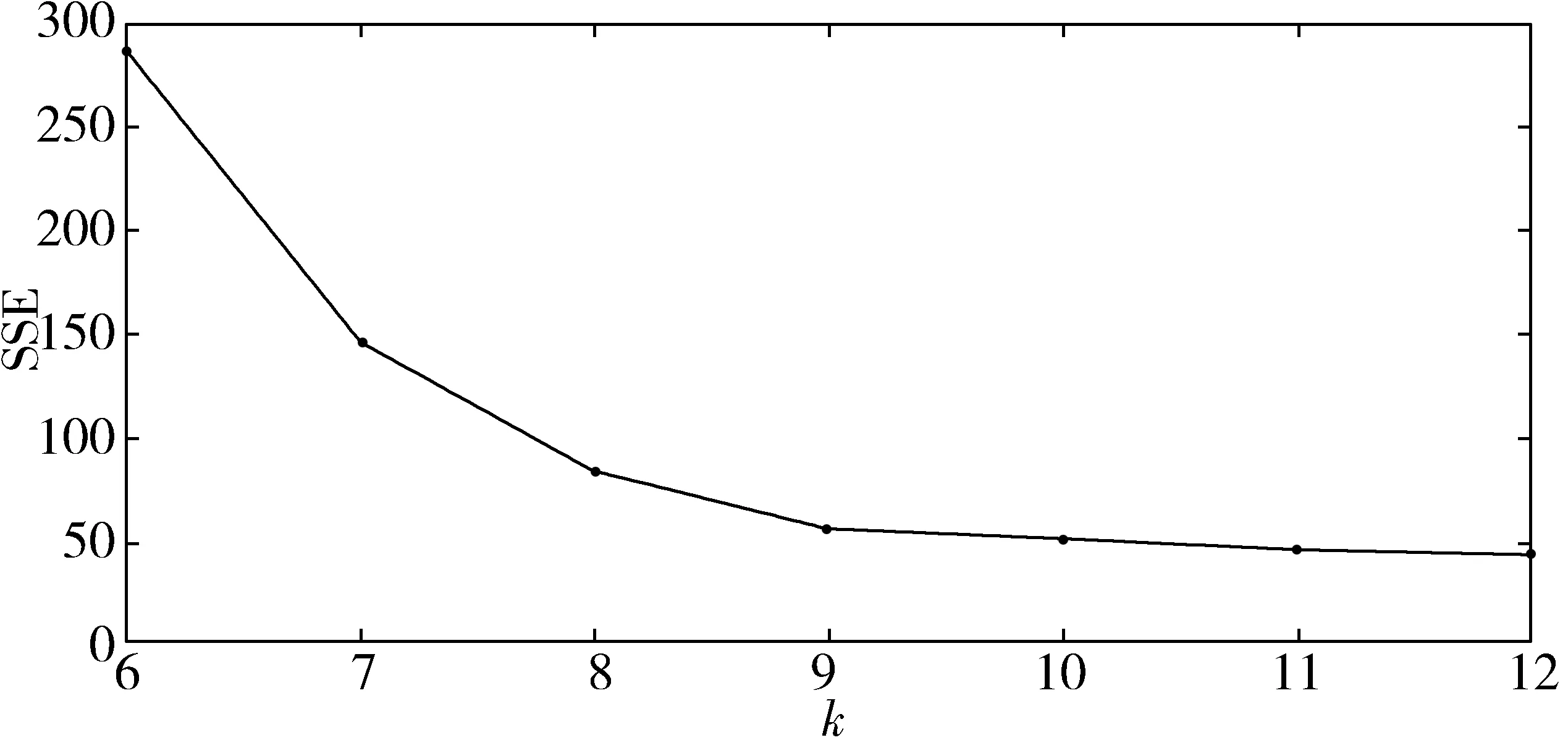
图6 k-SSE关系图
以上为k值与SSE关系变化图,使用手肘法可知当k=9时为最优解。因为K-means初始点敏感,所以每次运行得到的anchor值不一样。本文经过不同方法多次计算,得出了最优的anchor值。即为9个聚类:(15×38)、(26×132)、(89×36)、(116×52)、(138×127)、(205×55)、(327×27)、(404×102)、(406×58)。计算得出这组anchor在数据集上的avg iou为75.45%,比YOLOv3原始的9个聚类在数据集上得出的avg iou值要高得多。
2 实验过程
2.1 实验装置与模型框架
使用Nvidia GeForce GTX 1080Ti和Nvidia TITAN Xp来训练和检测模型,使用Ubuntu16.04, 64位操作系统,使用Darknet深度学习框架与主干网络为Darknet53的YOLOv3模型来进行实验。
2.2 实验数据集制作
原始图像1200幅,其中训练集1080幅图像,验证集120幅图像(验证集1)。处理后图像1200幅,其中训练集1080幅图像,验证集120幅图像(验证集2)。共计2400幅图像进行实验,其中训练集2160幅图像,验证集240幅图像(验证集3)。将缺陷分为不导电(budaodian)、凸粉(tufen)、碰凹(pengao)、擦花(cahua)、涂层开裂(tucengkailie)、起坑(qikeng)等6类。然后利用标注工具分别对原始图像和处理后的图像进行标注,制作成数据集,供后续神经网络训练使用。

图7 原始图像和处理后图像
2.3 模型训练与检测
采用Darknet深度神经网络框架和YOLOv3模型,实现缺陷特征的精确提取与定位、准确分类以及提高置信度。为保证实验结果客观公正,采用按不同类别样本数量比例随机抽样数据来进行训练和检测。
3 实验结果及分析
使用主干网络为Darknet53的YOLOv3模型训练,使用在ImageNet数据集上预先训练的Darknet53模型卷积权重。使用Pascal VOC 2007数据集制作实验数据集,然后利用迁移学习的方法对实验数据集进行迭代训练,利用最后获得的权重参数来检测验证集图像。图8为图像融合与深度学习方法检测验证集的实验结果。

图8 实验结果
根据实验结果可知,该方法能精确检测表面缺陷,并实现分类和定位。计算得出2种模型下各分类的AP值、mAP值以及对验证集的检测成功率,并且作出了P-R曲线来做比较。P-R曲线即为精确率precision(指的是在所有预测为正例的数据中,真正例所占的比例)和召回率recall的关系曲线。

表2 AP值及mAP值对比
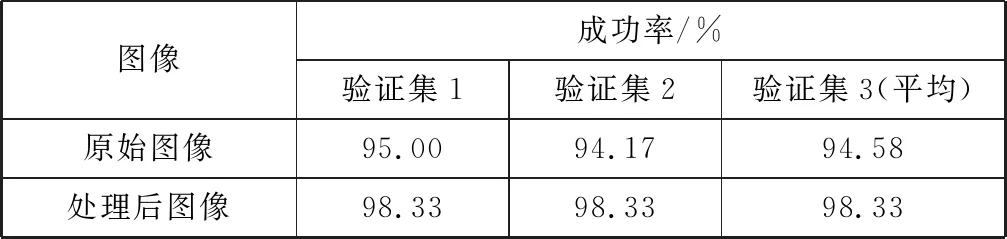
表3 检测成功率对比
从表2、表3可知,在验证集中,处理后图像模型对表面缺陷分类检出的平均成功率为98.33%,比原始图像模型提高了3.75个百分点;验证集mAP值为88.81%,比原始图像提高了4.18个百分点,取得了较为理想的效果。各种缺陷检测的P-R曲线图如图9所示。
第一行3幅图像依次为原始图像不导电、凸粉、擦花的P-R曲线图;第二行3幅图像依次为处理后图像不导电、凸粉、擦花的P-R曲线图。
根据图9可知,处理后图像的P-R曲线都可以完全包围住原始图像的P-R曲线,面积都更大。说明了处理后图像得到的模型比原始图像得到的模型更精确,性能更优越。
4 相关评估指标分析
4.1 Loss、IOU曲线
Loss使用了均方和误差作为损失函数,由3个部分组成:坐标误差、IOU误差和分类误差,计算公式如下:
(3)
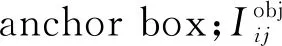
IOU为预测框与实际框的交集面积与并集面积之比,即:
(4)
原始图像与处理后图像的Loss曲线及IOU曲线对比如图10所示。

(a) 原始图像的Loss曲线
从图10可知,处理后图像得出的Loss曲线比原始图像得出的Loss曲线随着迭代次数的增加振荡幅度更小,更趋于平缓。处理后图像得出的IOU曲线比原始图像得出的IOU曲线随着迭代次数的增加波动范围更小,能够快速收敛,这些都表明了处理后图像模型更稳定,性能更好。
4.2 Recall、Recall-IOU曲线
Recall为召回率:
(5)
其中,TP为将正类预测为正类数,FN为将正类预测为负类数。

图11 原始图像和处理后图像的Avg Recall对照图
按比例每隔30幅图像抽样,共36批次1080幅图像,分别计算得出原始图像和处理后图像的Avg Recall,并作出图11。从图11可知,处理后图像得出的曲线比原始图像得出曲线总体Avg Recall值要高得多,而且波动范围更小,后期逐渐趋于稳定,所得出的模型性能更好。
最低IOU阈值设置为0.6,依次上涨0.025个单位,作出了原始图像和处理后图像的Recall-IOU对照图,如图12所示。从图12可知,原始图像模型在IOU≤0.65时,Recall基本上接近于1;当IOU>0.65后不断下降。处理后图像模型在IOU≤0.7时,Recall基本上接近1;当IOU>0.7后不断下降。同时处理后图像模型下降幅度比原始图像模型更缓慢、更平稳。并且当IOU阈值一定时,处理后图像模型比原始图像模型的Recall值都要高,表明处理后图像模型效果更好,性能更优越。

图12 原始图像和处理后图像的Recall-IOU对照图
4.3 ROC曲线
ROC(Receiver Operating Characteristic)又称为感受性曲线(sensitivity curve),用来评价模型分类器的性能。横坐标为假阳率FPR(False Positive Rate),纵坐标为真阳率TPR(True Postive Rate)。
本文分别设置了阈值为0.5和0.6的情况,作出了原始图像模型和处理后图像模型的ROC曲线图,如图13所示。从图13可知:1)当FPR=0时,在2种阈值下,处理后图像模型比原始图像模型得到的TPR值都要高;2)对比4种情况下的等错误率EER(Equal Error Rate,即2类错误FP和FN相等时候的错误率),可以看出,在阈值相同的情况下,EER1>EER2,EER3>EER4;3)对比4种情况下曲线的AUC(Area Under Curve,即指曲线下的面积),可以看出在阈值相同的情况下,处理后图像模型面积始终大于原始图像模型面积。综上所述,处理后图像模型性能更好,性能更优越。

图13 ROC曲线图
5 结束语
本文基于YOLOv3算法,提出了一种基于图像融合和YOLOv3的铝型材表面缺陷检测方法。利用图像增强、空域滤波的方法进行预处理,借鉴了SLAM中特征提取与匹配的思想进行图像融合,再通过K-means算法聚类和调参优化,最后利用物体检测模型YOLOv3对样本进行检测。通过修改网络架构和调参优化进行多次实验,得到了最优结果。实验结果表明:此图像融合与YOLOv3的方法对表面缺陷分类检出的平均成功率为98.33%,比单一YOLOv3方法提高了3.75个百分点;验证集mAP值为88.81%,提高了4.18个百分点,具有更强的特征提取能力和泛化能力。在今后的工作中,笔者将致力于压缩模型提升检测速度,使其更好地移植到小型便携的嵌入式系统中,这也是下一步研究的重点。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
天津医科大学学报(2021年1期)2021-01-26
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
制造技术与机床(2018年8期)2018-10-09
自动化学报(2017年5期)2017-05-14
制造技术与机床(2017年2期)2017-05-04
自动化学报(2017年11期)2017-04-04
制造技术与机床(2017年12期)2017-02-02
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
