
基于LSTM 的工控入侵检测*
2020-11-20 03:13
通信技术 2020年11期
(上海交通大学,上海 200240)
0 引言
工业控制系统(Industrial Control System)在运输、供电以及水处理等领域应用广泛,是工业基础设施的核心组成部分,也是国民经济、社会运行和国家安全的重要基础[1]。自澳大利亚Maroochy 废水系统攻击[2]、Stuxnet 蠕虫攻击[3]以及德国钢铁厂[4]之后,工业控制系统的安全提升到一个新的高度,受到人们越来越多的重视。
大多数入侵检测系统(Intrusion Detection System,IDS)采用CIDF 通用模型。CIDF 模型将IDS 分为4 个相互关联的部分[5]——事件生成器(Event Generators)、事件分析器(Event Analyzers)、响应单元(Response Units)和事件记录器(Event Recorder)。EG 负责采集和预处理原始数据,包括ICS 中的数据报文、日志以及传感器数据等,格式化为事件并传递给其他3 个模块。EA 是入侵检测系统的核心。EA 实现入侵检测算法,分析传递给它的事件行为,判断事件是否构成异常或入侵行为,并将判断结果传递到RU。RU 根据EA 的判断结果做出响应,包括发出切断电源、停止数据传输命令或改变访问权限。ER 将入侵检测系统的工作流程记录成日志,以供安全人员查看。具体模型如图1 所示。
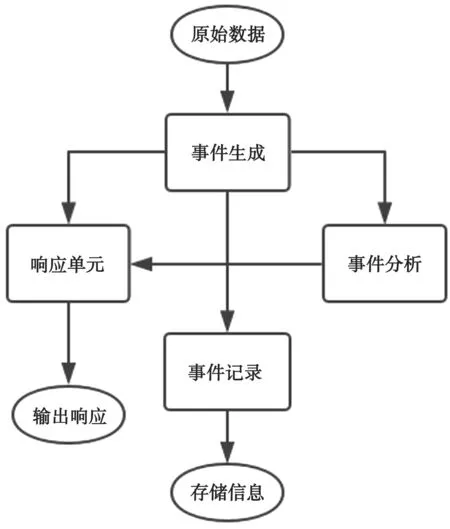
图1 CIDF 通用模型
传统的IDS 通常没有考虑ICS 特有的通信协议,如DNP3 和Modbus,且ICS 的异常检测不能完全依赖网络流量,还需要查看与物理过程控制相关的传感器或执行器信息,增加了数据特征数目和各项数据关联性的复杂程度。传感器传递的数据很有可能受到噪声的影响,导致异常检测设备产生高误报率和低攻击检测率。
国内外已有大量研究人员进行了大量研究,但大多数方法高度依赖预定义的模型和特征来检测异常行为,且现有的入侵检测方法大多针对特定的协议和系统定制,缺少一定的通用性。此外,攻击往往具有时间依赖性,在大多数检测方案中没有涉及。本文设计并实现一个基于LSTM 的IDS 方案,并在SWaT 数据集上评估效果。为了获得更好的对比效果,根据文献[6-7]的描述,实现了Isolation Forest、OSCVM 和Matrix Profile 这3 种检测方案。实验结果表明,基于LSTM 的检测方法比其他3 种检测方法具有更高的正确率,且测试所需要的时间更短,需要的上下文环境更少。
本文余下部分组织如下:第1 部分概述目前已有的检测方法;第2 部分说明实验中的数据集;第3 部分阐述降维方法和主要算法;第4 部分分析评估结果并讨论;第5 部分为结论。
1 相关工作
作为一种有效的防御手段,异常检测已经被广泛应用在各个领域,如检测僵尸网络[8]、检测物联网的攻击[9]以及检测程序的异常行为[10]等。
Maglaras 和Jiang 等人[6]提出使用一类支持向量机(One Class Support Vector Machine,OCSVM)来检测攻击。他们将原始的网络跟踪文件分割为两个独立集合用于训练与测试,但数据集较小,只有不到2 000 条独立完整的跟踪记录。
Goh 等人[11]通过使用递归神经网络,检测网络物理系统的攻击。他们同样使用安全水处理(Secure Water Treatment,SWaT)数据集。在他们的工作中,使用RNN 是为了预测在接下来的一段时间内某一物理属性或某一传感器接收到的数据的变化曲线。如果预测曲线和实际信号曲线有较大差别,说明可能存在入侵。
此外,国内外对工业控制系统的入侵检测还有许多研究成果。Gao 和Morris[12]提出了利用特征码来检测Modbus 数据中攻击的方法;在Schneider 和Bóttinger的研究中,他们通过自动编码器,以无监督的方式检测工业数据集中的真实攻击[13];Knapp 和Langill提出了保护工业网络安全的方法[14];Yang 等人则针对电力系统网络入侵检测问题进行了讨论[15]。
2 SWaT 数据集
新加坡理工大学网络安全中心iTrust 提出的SWaT[16]模拟一个工业水处理厂,通过膜超滤和反渗透装置,每分钟生产5 加仑的过滤水[17]。SWaT在正常模式下运行7 天,在攻击模式下运行4 天,最终生成由与水处理厂和水处理过程有关的物理特性,并与实验中网络流量共同构成数据集。
水处理分为生水存储(Raw Water Storage)、预处理(Pre-treatment)、膜超滤(Ultrafiltration,UF)、紫外线(Ultraviolet,UV)灯脱氯、反渗透(Reverse Osmosis,RO)和处理(Disposal)6 个子过程。子过程之间的联系和转换关系如图2 所示。工厂将准备处理的水储存起来,用不同的化学物质预处理。之后使用膜超滤再进行脱氯处理,输送给反渗透设备。根据水清洁度的高低,决定存储在干净的储水池中还是回到膜超滤环节。

图2 模拟处理过程
SWaT 数据集基于攻击的特点,区分了4 种类型的攻击。
(1)单级别单点攻击(Single Stage Single Point,SSSP):在一个子过程中,对一个点(传感器或执行器)进行攻击。
(2)单级别多点攻击(Single Stage Multiple Point,SSMP):在一个子过程中,集中对多个点进行攻击。
(3)多级别单点攻击(Multiple Stage Single Point,MSSP):在多个子过程中,分别对一个点攻击。
(4)多级别多点攻击(Multiple Stage Multiple Point,MSMP):在多个子过程中,对多个点进行攻击,可以看做是单级别多点攻击在多个子过程上的实现。
在11 天的数据收集过程中,共有36 次攻击。表1 列出了攻击的分类。

表1 SWaT 中攻击类型和次数
3 研究方法
3.1 基于LSTM 的入侵检测建立网络模型
3.1.1 PCA 降维
虽然SWaT 是较为简单的典型工业控制系统,一项物理属性记录中只有53 个数据项,物理控制过程可以抽象为只有51 个属性的数据(其他两个数据项分别为时间戳和标签Normal/Attack),但为了不失一般性,抽取数据特征对数据进行降维处理。
使用卡方检验返回最佳特征,并使用PCA(主成分分析)算法进行降维。为了获得最好的降维效果,在SWaT 数据集上测试最佳特征返回数目为8~14 时降维数据的完整性,具体测试结果如表2所示。抽取数据保留11个属性(时间戳和标签除外),分别是'LIT101'、’AIT203’、’FIT201’、’DPI T301’、’FIT301’、’LIT301’、’AIT402’、’LIT401’、’AIT502’、’PIT501’、'PIT503'。此时数据的损失较少,数据完整性保留程度高。图3 与图4 分别显示了降维前后特征之间的关联性。PCA 处理前,各个属性之间均存在一定关联,其中有部分属性存在明显的正相关与负相关联系。PCA提取出主要特征分量,将抽取后的特征变换为线性无关的表示,因此图4 显示各个维度之间关联性为0。

表2 保留属性与完整性

图3 降维前特征间关联性
为了能够更好地应用SWaT 数据集(以及其他工业控制系统中数据)的时序性特点,将降维后的数据每30 条分作一组,每一组内部数据都是时序的。将每一组数据组成的矩阵转置,形成类似字符串embedding 后的编码结果。

图4 降维后特征间关联性
3.1.2 LSTM 网络
LSTM 是一种特殊的RNN。通过精巧的设计,解决长序列训练过程中梯度消失和梯度爆炸问题。标准RNN 由简单的神经网络模块按时序展开成链式,内部结构如图5 所示。这个重复模块结构简单且单一,记忆叠加方式显得简单粗暴。
LSTM 内部有较为复杂的结构,能通过门控状态选择调整传输的信息,记住需要长时记忆的信息,忘记不重要的信息,如图6 所示。
LSTM 内部主要有3 个阶段。
(1)忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记——“忘记不重要的,记住重要的”。通过计算得到的zf(f表示forget)作为忘记门控,ct-1来控制上一个状态哪些需要保留哪些需要遗忘。
(2)选择记忆阶段。该阶段将输入有选择性地进行“记忆”。主要对输入xt进行选择记忆,重要内容着重记录,不重要内容则少记一些。当前的输入内容由前面计算得到的z表示。选择的门控信号则由zi(i代表information)进行控制。将上面两步得到的结果相加,即可得到传输给下一个状态的ct。
(3)输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要通过zo控制,且对上一阶段得到的co进行放缩(通过一个tanh 激活函数进行变化)。
LSTM 通过门控状态控制传输状态,记住需要长时间记忆的,同时忘记不重要的信息。这对很多需要“长期记忆”的任务尤其好用,但也因为引入了很多内容导致参数变多,加大了训练难度。
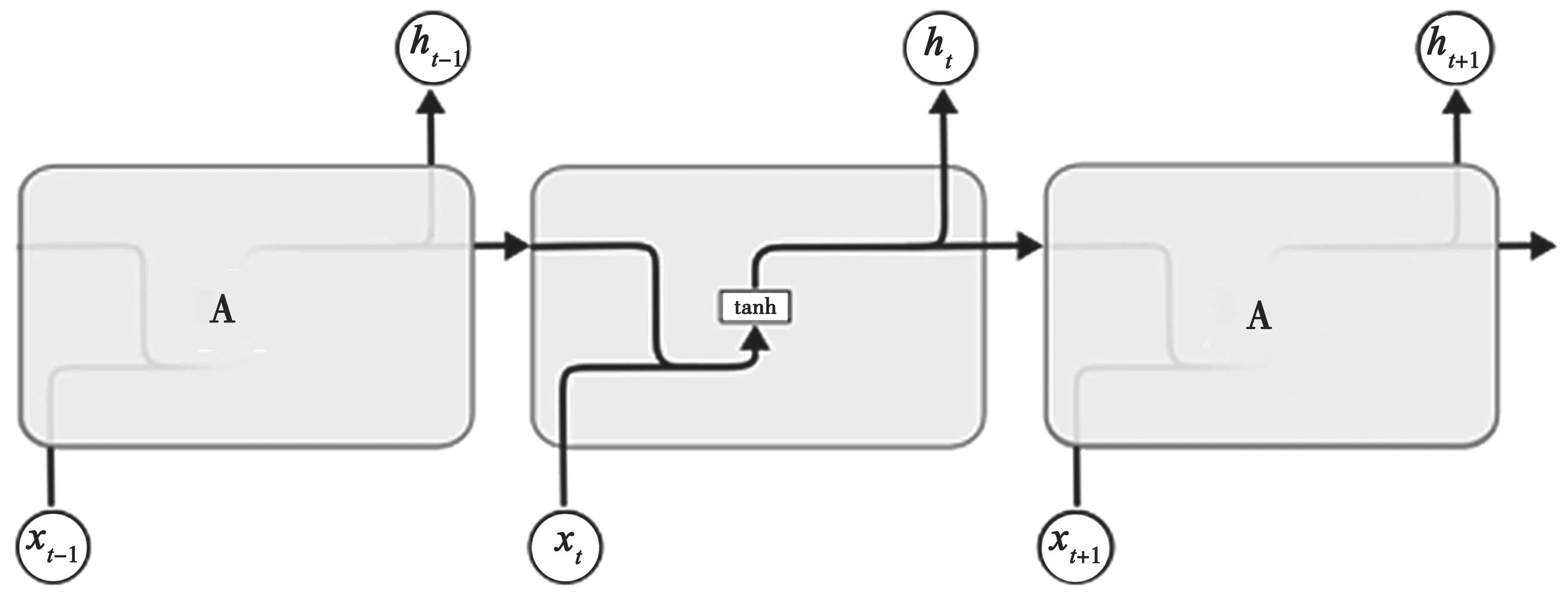
图5 RNN 网络内部结构

图6 LSTM 网络内部结构
3.1.3 网络结构
本文实现了一个基于LSTM 的深度网络。网络包含2 个LSTM 网络层和1 个全连接层,最后使用Sigmoid 进行归一化。由于Sigmoid 会带来过拟合问题,在网络各层间添加Dropout 并设置LSTM 的recurrent_dropout 为0.2。第4 部分评估结果显示,这样的方法是合适的。
3.2 其他入侵检测方法
3.2.1 OCSVM
OCSVM 即一类支持向量机。该模型将数据样本通过核函数映射到高维特征空间,使其具有良好的聚集性。在特征空间中求解一个最优超平面,实现目标数据与坐标原点的最大分离。OCSVM 使用一个类进行训练,以确定测试用例的元素是否属于该类,非常适合单类占主导地位的应用场景,如异常检测。
3.2.2 孤立森林
孤立森林算法是一种适用于连续数据的无监督异常检测方法。与其他异常检测算法通过距离、密度等量化指标来刻画样本间的疏离程度不同,孤立森林算法的核心是通过孤立数据点检测异常值。
孤立森林利用一种名为孤立树的数据结构来孤立样本。孤立树是一种二叉树。因为异常值的数量较少,且与大部分样本具有疏离性,因此异常值更容易被孤立出来,即异常值会距离孤立树的根节点更近,而正常值距离根节点更远。此外,相较于LOF、K-means 等传统算法,孤立森林算法对高维度的数据具有较好的鲁棒性。
3.2.3 Matrix Profile
Yeh 等人于2016 年开发了Matrix Profile[18],将其作为模式识别算法。具有时序性的数据集被分割成长度为m的序列。每个序列从数据集中的一个点开始,以滑动窗口的方式计算每个序列之间的距离,如用z代表归一化距离。

欧式距离与归一化距离有如下关系:

式中,x和y都是具有时序性的序列,μ是各自的均值,σ是各自的标准差。Matrix Profile 将最小距离保存在一个矩阵中。一个较大的最小距离表示了一个异常值,因为这说明序列中没有与他相似的序列。相反,一个小的最小距离表明在数据集中这个序列有较多相似序列,因此异常的可能性较低。
4 实验评估
将SWaT 数据集应用到第3 部分介绍的算法中。这里选取了近50 万条(449 920)物理设备数据记录。在原始的csv 文件中,各条记录按时间戳的顺序排列,每条记录对应一个标签Normal/Attack。
实验在显卡GeForce 940MX、处理器I7-7500U的硬件环境下进行。第3 部分中的4 个模型训练与测试所需时间分别为5 min、3 h、3.6 min 和5 h。
4.1 基于LSTM 的入侵检测评估
训练过程中的损失如图7 所示。可以看到,网络在训练过程中不存在梯度爆炸或梯度消失问题。
如图8 所示,在测试集中,LSTM 网络达到96.5%的准确率,而其他方法效果较差:一类支持向量机在运行3 h 后能达到87.96%的正确率,孤立森林只有不到40%(37.14%)的正确率。
为了对比查准率和查全率,将测试结果可视化为图9 的混淆矩阵。

图7 训练中的损失
4.2 其他检测方法评估
4.2.1 OCSVM
按照第3 部分方法介绍中所描述的,实现了一个一类支持向量机。由于实验中样本数较多而特征数目较少,训练模型时选择的核函数为高斯核函数,即rbf。

图8 正确率对比
LSTM 网络混淆矩阵,如图9 所示。同样的,将测试结果表示为混淆矩阵,并绘制为图10。对比图9 的左下部分,可以明显看出,OCSVM 将更多的攻击判定为正常数据,表明使用OCSVM 作为检测方法会隐含更大的风险。
4.2.2 孤立森林
孤立森林在同一个数据集上的表现比预期结果糟糕——调参过程中,分类准确率最高只有37.14%。与前两种算法相同,将PCA 降维后的数据输入孤立森林模型进行训练,混淆矩阵绘制如图11 所示。对比OCSVM 的结果,孤立森林在检测过程中漏掉的攻击更少,但误报率相当高。在实际的系统中,误报率高会显著增加系统运营和人工排查的成本。
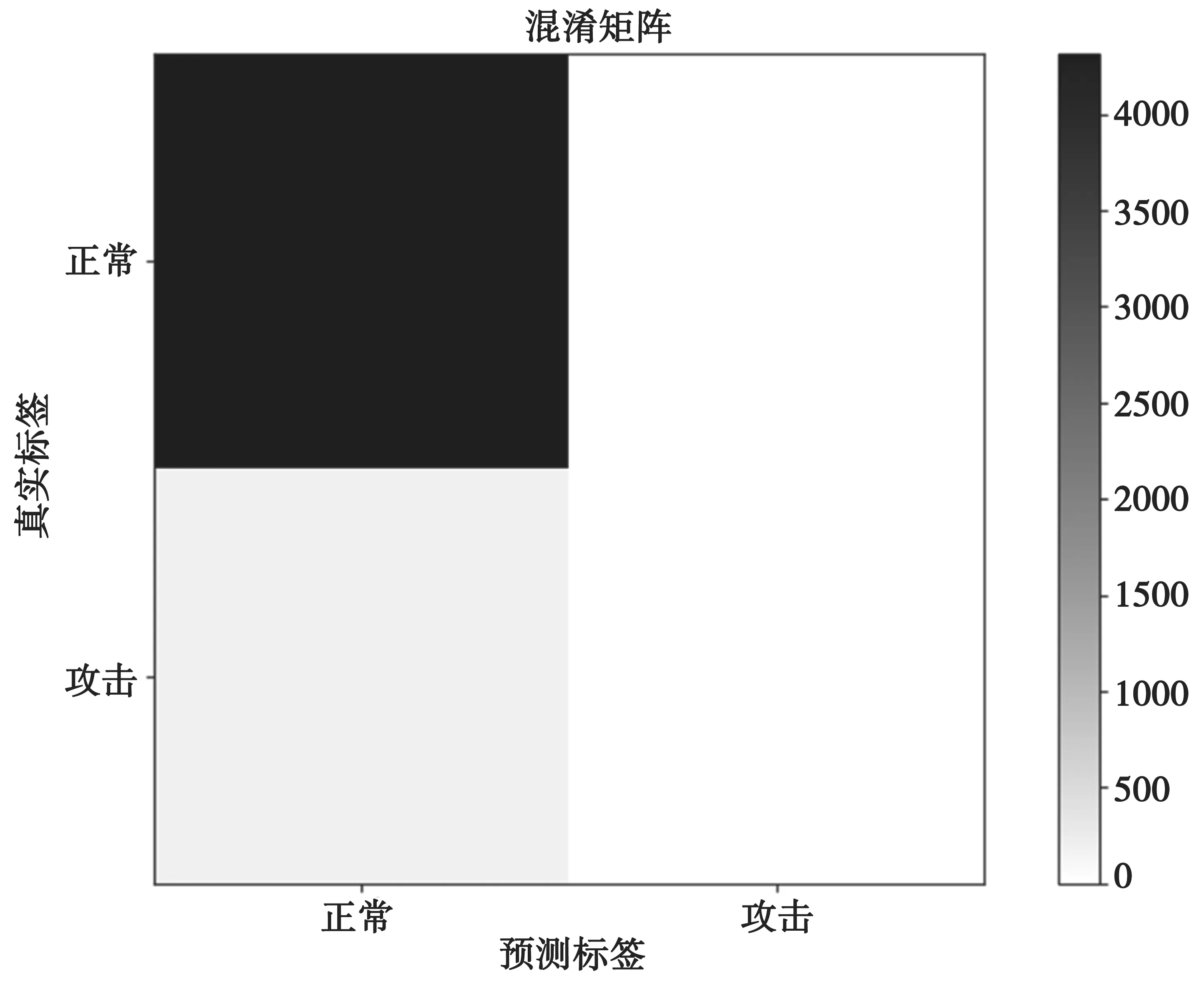
图9 LSTM 网络混淆矩阵
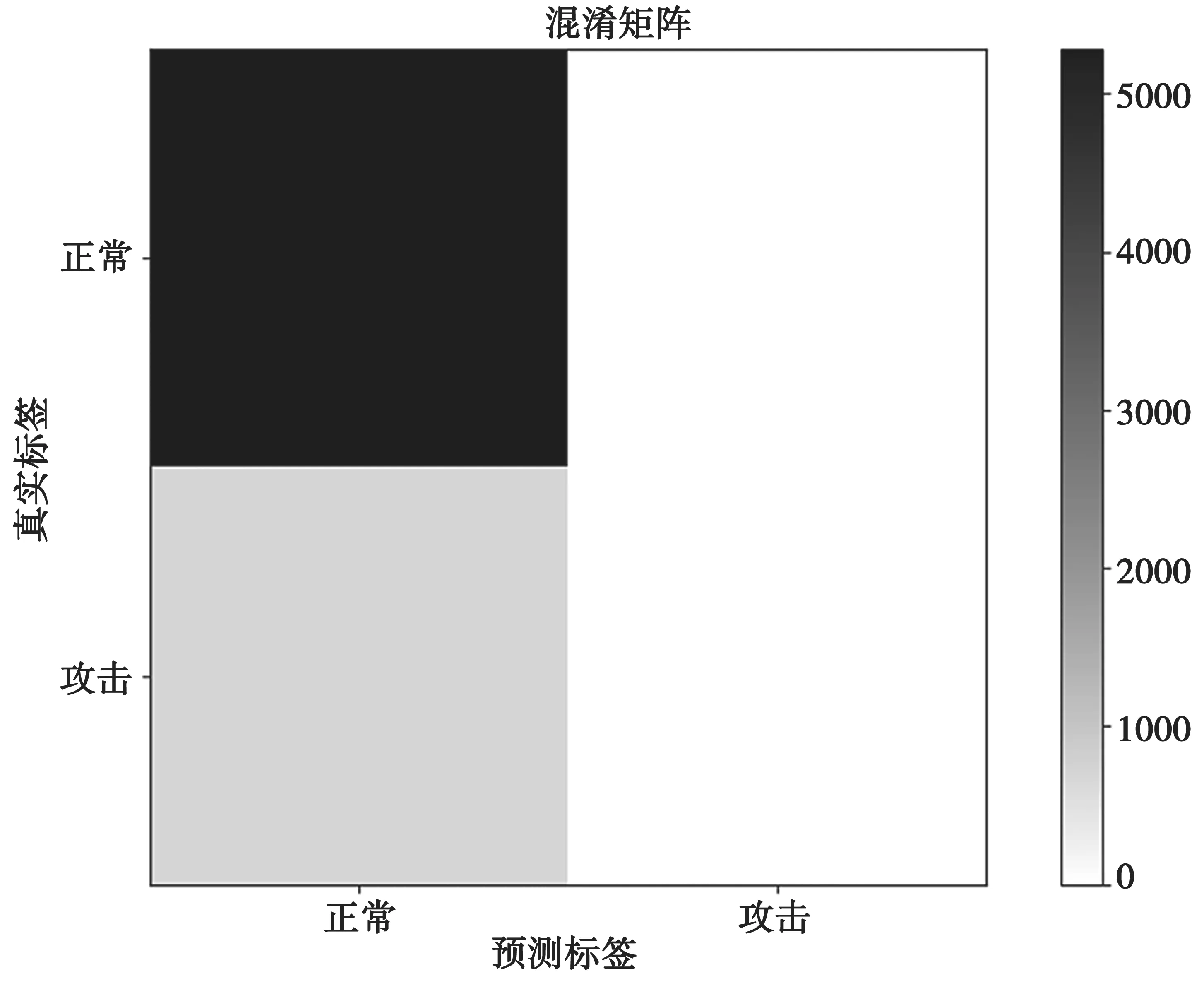
图10 OCSVM 网络混淆矩阵
尽管样本数据是按顺序输入模型进行训练的,但无论是OCSVM 算法还是孤立森林算法,都没有将时间戳当作影响模型的因素之一[9]。打乱样本后再测试的结果相同,这与基于LSTM 的检测方法和Matrix Profile 有显著不同。

图11 孤立森林混淆矩阵
4.2.3 Matrix Profile
Matrix Profile 和评估过的3 种算法有较大差别。Matrix Profile 针对某一物理属性在一个连续时间段内的取值进行分析,计算长度为m的序列之间的距离并确定距离的阈值,因此直观上对单点的攻击检测更有效。
经过多次测试,最终将超参数m确定为500,此时绘制的图像对比最明显。图12 显示了SWaT系统中水箱LIT-401 的水位分析结果。其中,第1行为经过z 分数规范化后的样本数据,第2 行为计算得到的序列之间距离,第3 行为修正弧曲线。可以看到,在噪音的影响下,攻击被隐藏,Matrix Profile 算法的检测效果不理想。
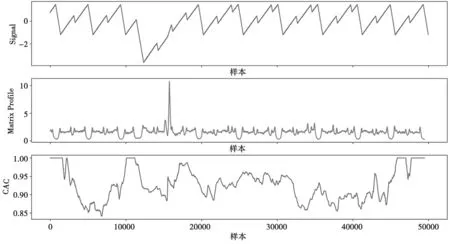
图12 LIT-401 的水位分析
4.3 讨论
基于LSTM 的检测方法在检测准确率上,显著优于孤立森林和一类支持向量机。孤立森林不仅准确率较低(只有不到40%),而且误报率非常高,难以应用到实际的工业生产过程。OCSVM 尽管测试数据集的准确率接近90%,但对比图9 和图10的混淆矩阵可以明显看到,OCSVM 将更多的攻击判定为正常数据,表明相比于LSTM,使用OCSVM作为检测方法会隐含更大的风险,即更多的攻击无法被检测出来。Matrix Profile 则严重受到数据中噪音的影响。正常数据中的噪音会导致模型计算的序列距离更大,一定程度上将实际的攻击数据隐藏起来。而在实际的工业生产过程中,夹杂噪音的数据往往很常见。
除此之外,基于LSTM 的检测方法在测试和部署上也有较大优势。为了计算最小距离,Matrix Profile 需要至少m+1 个数据(研究中m为500),且为了存储最小距离矩阵,空间复杂度为n2。为了获得更准确的最小距离,研究中尝试输入40 万条数据,模型运行时间超过6 h。OCSVM 模型需要的计算时间同样较长,需要至少3 h。
通过多次实验,最终确定基于LSTM 的检测方法在一次判别中只需要30 个时序上连贯的数据就可以达到较高的判别可信度,检测一条数据需要的上下文环境更少。而其他3 种检测方法中,Matrix Profile 在实验中至少需要500 条连续数据,最终获得的曲线图才有较好的区分度(如图12所示)。另外,两种方法并不直接考虑工控数据的时序性特点,都只独立地判断一条工控记录。
5 结语
本文实现了4 种工业控制系统入侵检测方法。通过使用SWaT 数据集进行模型训练和测试,本文评估了这些方法,并将测试结果可视化为混淆矩阵等图表。结果显示,基于LSTM 的检测方法在检测准确率(96.5%)上远远高于孤立森林的准确率(37.14%),并优于一类支持向量机(87.96%)。
除了进一步深入研究基于LSTM 的入侵检测,今后研究有两个主要方向。第一,入侵往往具有时序性特点,LSTM 网络考虑到这一特点,因此测试效果比对比方法好。第二,考虑复杂攻击之间的关联性。第2 章节数据集的介绍中提到4 种攻击方式,可知MatrixProfile 等分析单个属性数值异常情况的检测方法局限性较大。若能具体考虑属性之间的关联,如复杂攻击引起物理属性连锁变化等,此类方法或许能有更好效果。
本文检测方法在设计和实现上还存在一定的缺陷和问题,需要在今后的研究中不断改进。在对数据的分割上,本文按照实际的测试效果得到分割方式,这在实际应用中无法实现。因此,如何更好地分割数据需要进一步研究。此外,数据集不应该局限于SWaT 数据集,因为SWaT 数据集来自较为简单的工业控制系统,所以在更多的数据集上训练和测试将会是以后工作的一个方向。
猜你喜欢
车主之友(2022年4期)2022-08-27
海峡姐妹(2019年12期)2020-01-14
小学生导刊(2018年34期)2018-12-18
读与写·教育教学版(2017年10期)2017-11-10
山东青年(2016年3期)2016-02-28
火控雷达技术(2016年1期)2016-02-06
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
