
基于隐私政策条款和机器学习的应用分类*
2020-11-20 03:13
通信技术 2020年11期
(上海犇众信息技术有限公司,上海 201100)
0 引言
隐私政策是披露用户数据如何被搜集、使用、共享和管理的声明[1]。随着越来越多的个人信息被APP 收集,与APP 相关的隐私政策逐步受到关注。本文以问卷的形式调查用户阅读隐私政策的情况。调查结果发现,60.3%的用户不了解隐私政策的作用,46.4%的用户在使用APP 前不会阅读隐私政策[2]。隐私政策篇幅长、用语专业等原因,影响了用户阅读隐私政策。因此,隐私政策中存在的问题很有可能成为用户隐私安全的漏洞。针对以上现象,本文提出了基于机器学习的中文隐私政策条款自动分类方法,以达到提升隐私政策可读性并评价其质量的目的。
目前,人们试图根据GDPR[3]标准化英文隐私政策的相关工作[4-7]。另外,有相关研究对英文隐私政策条款进行自动分类。例如:Contissa 等[8]利用机器学习技术对英文隐私政策进行评估,从而发现其中的问题条款;Harkous 等[9-10]使用众包任务标注数据,设计自动化隐私政策分析框架Polisis 对隐私政策条款进行分类。此外,也有针对中文隐私政策现状进行分析的调研。例如:朱颖[11]基于96个移动应用APP 对中文隐私政策进行分析;付少雄等[12]采用内容分析法分析中文隐私政策的制定内容;申琦[13]采用内容分析法考察中文隐私政策的现状与不足。目前,针对中文隐私政策条款自动分类的工作并不多。来自JUNO 隐私政策数据监测平台[14]的数据表明,应用市场中47.8%的隐私政策为中文隐私政策。本文提出的自动分类方法相较传统的内容分析法,可以更快速分析中文隐私政策,既提升其可读性,又节省大量分析时间,因此具有一定的研究价值。
本文使用中文文本处理方法和特征选择方法,通过对比朴素贝叶斯、支持向量机和卷积神经网络3 种模型的文本分类效果,最终使用支持向量机建立中文隐私政策条款自动分类模型。基于隐私政策条款自动分类的结果,检测隐私政策的虚假性和完整性,再依据设计的评价方法对隐私政策进行评分。
1 层次多标签分类模型
1.1 条款自动分类流程
本文构建的隐私政策条款自动分类框架,如图1 所示。

图1 条款分类框架
隐私政策条款自动分类流程主要分为模型训练、模型应用和检测分析阶段。
隐私政策层次多标签模型的训练先是进行人工标注数据,确定条款类别标签及其对应的属性标签,然后使用TF-IDF 算法[15]进行特征选择,提取各类别条款的关键特征训练分类模型,通过调节参数提升模型的性能,最后得到分类模型。
层次多标签模型的应用先是对隐私政策各项类别的条款进行数据预处理,然后进行特征选择,最后调用训练得到的分类模型实现条款分类。
层次多标签模型的检测分析先基于分类结果对隐私政策条款进行虚假性检测,然后进行条款的完整性检测,最后通过设计的隐私政策评价方法得出隐私政策的评分结果。
1.2 隐私政策条款分类指标体系
赵波等[16]认为,国内目前缺少直接针对APP个人信息安全评估的标准,且结合当前针对个人信息安全发布的部门规章、政策文件和标准文件进行分析,得出《信息安全技术个人信息安全规范》是目前使用最广泛的个人信息安全保护标准。因此,本文以《信息安全技术个人信息安全规范》为主要参考标准,根据其中的要求,总结得出隐私政策条款应该至少包含7 个基本分类,而本文将其定义为类别,如个人信息控制者(以下统称“第一方”)收集/使用、其他通用信息等。本文将7 个基本分类对应的具体内容定义为属性,如第一方收集/使用具体内容包括第一方收集的个人信息、第一方何时收集以及第一方收集的目的等。此处以第一方收集/使用类别为例进行详细定义说明,如表1 所示。

表1 第一方收集/使用部分定义
根据分类定义,结合《信息安全技术个人信息安全规范》的要求,借鉴相关工作[9]的方法,本文对隐私政策内容进行了划分。结合隐私政策标注过程的反馈进行反复修正,最终形成“类别-属性-值”层次结构的分类指标体系。该分类指标体系包含7 个类别、50 个属性和91 个值[17],部分分类指标体系如图2 所示。
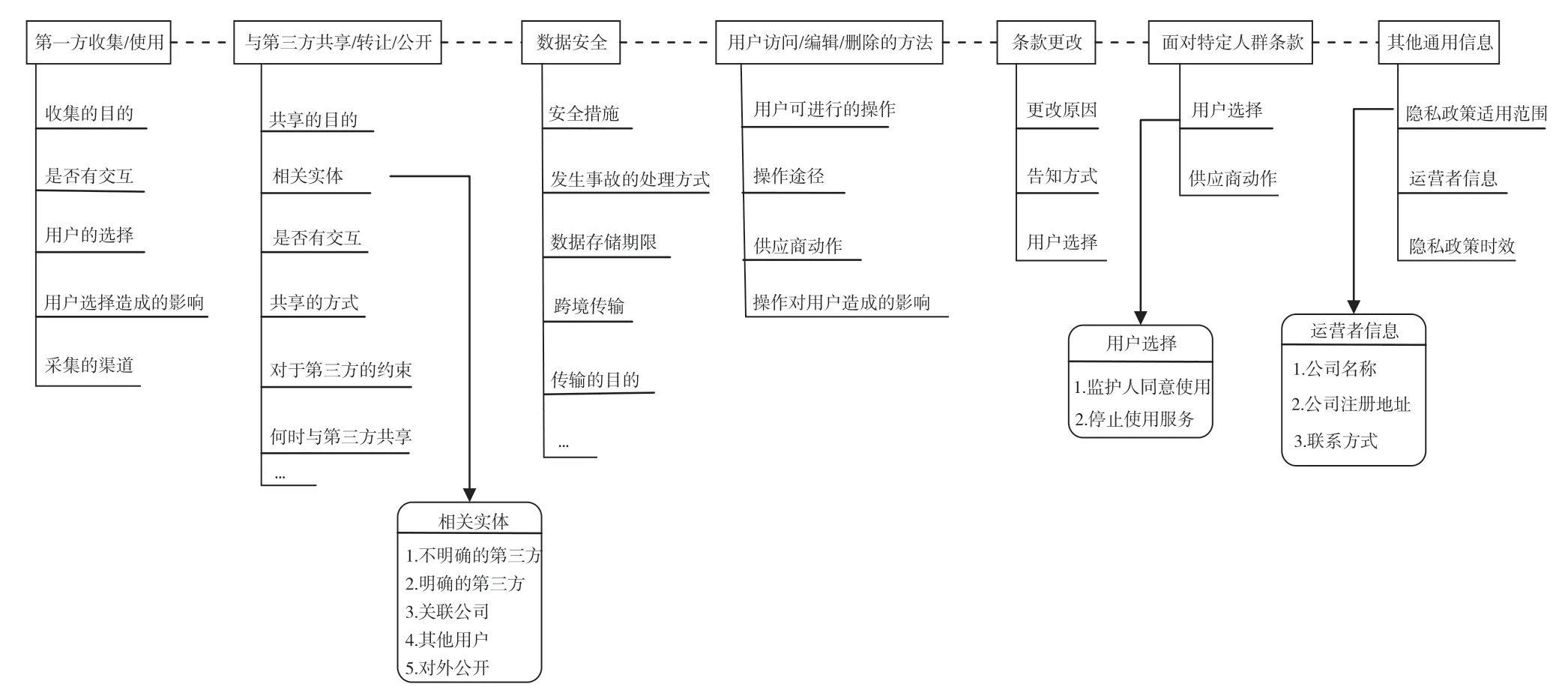
图2 分类指标体系
分类指标体系中方框内的内容代表7 个基本分类,分别用First-Party-Collect-Use 和Third-Party-Share等标签表示。每个方框下对应的内容代表该类别的属性,分别用First-Party-Collect-Use-Purpose 和First-Party-Collect-Use-Collect-User-Choice 等标签表示。对于大部分属性设计相应的值选项,如是否有交互属性设置了是和否两个值。
1.3 条款标注
条款标注以众包任务的方式进行,招募的10名学生全部来自于法律相关专业,在确保标注者充分理解分类指标体系的基础上,对其开放在线标注工具BRAT[18]入口对隐私政策进行标注。经过充分讨论标注有疑问的内容,最终通过调整分类指标体系或者放弃标注等方式解决。对于每一个标注标签需支付0.4 元的报酬,整个标注过程历时90 天。
本文通过Cohen’s kappa 系数[19]检验数据标注的一致性,证明数据标注内容是可信的。该过程最终形成了包含100篇中文隐私政策条款数据集[20]。参考OPP-115[9]的命名方法,本文将该数据集命名为Chinese-OPP-100。该数据集中共包含11 440 个类别和属性标签。
2 实验过程
2.1 隐私政策数据集构建
本文爬取华为应用市场中100 个热门应用的隐私政策作为数据集,覆盖17 种应用类型(包括影音娱乐、实用工具和社交通信等)。在2019 年11月23 日至2019 年11 月28 日期间,通过持续监控华为应用市场,本文爬取1 500 份隐私政策用于检测。
2.2 数据预处理和特征选择
2.2.1 数据预处理阶段
为了使后续的特征选择更准确,本文通过Jieba[21]分词工具的自定义词典功能导入自定义词典。本文的自定义词典根据隐私政策条款的特点进行人工整理与添加。部分自定义词典内容包括匿名化处理、隐私政策以及敏感信息等。为了减少隐私政策中的噪音词,如“的”“甚至”等出现频率高且没有实际意义的词,本文调用哈工大停用词表对隐私政策条款进行去噪处理,以提高后续的分类效果。
2.2.2 特征选择阶段
分类模型性能受到类别特征中无明显分类特征词的影响,因此可通过TF-IDF 算法[15]进行特征选择,选择出能够识别不同条款类别的有效特征。各类别条款关键特征词的部分展示如表2 所示。关键词的权重值越大,表明该词对该类别条款越重要。
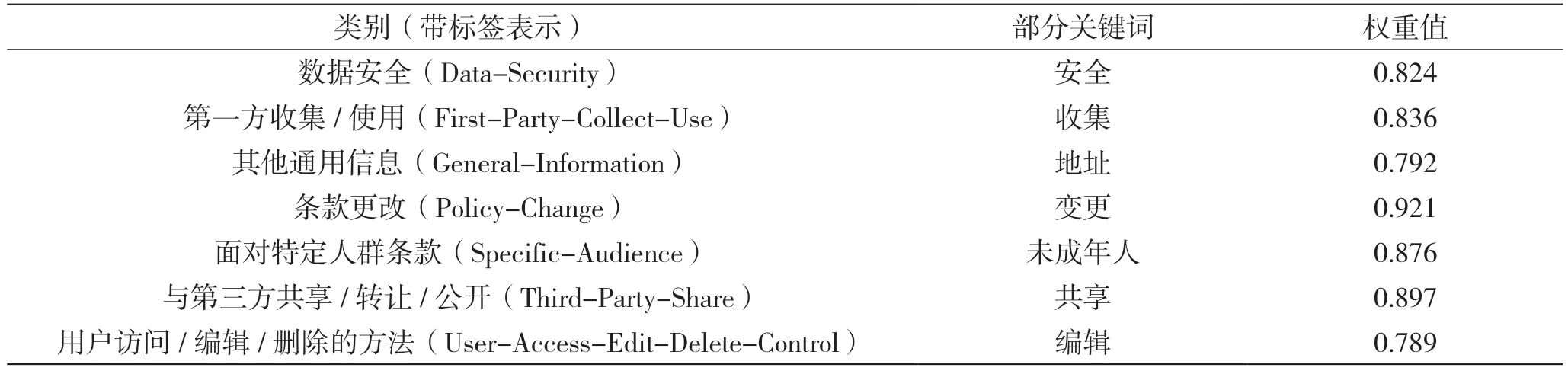
表2 类别条款关键特征词部分展示
2.3 训练方法
为了实现隐私政策条款的自动分类,本文采用机器学习技术,将数据集以8:2 分成训练集和测试集。使用了基于scikit-learn 工具包[22]的朴素贝叶斯和支持向量机,以及基于Keras[23]的卷积神经网络,分别训练多标签分类模型。使用网格搜索自动调整参数,采用简单交叉验证的方法进行训练,每组实验重复5次,以防止随机影响。模型训练完成后,调用分类模型对隐私政策测试集进行类别和属性标签的预测,并与隐私政策条款应该正确对应的类别和属性标签进行比较,计算分类器的性能评价指标。
本文基于类别和属性建立层次多标签分类指标体系。在进行隐私政策条款的自动分类时,先定位到本文定义的类别标签上,再定位到每个类别标签下相对应的属性标签上。因此,本文先对数据集中的7 个类别标签构建一个类别多标签分类模型,再针对各个属性标签构建属性多标签分类模型。
本文主要采用的分类算法是支持向量机算法[24]。由于本文的数据集是多标签数据集,区别于一般的二分类问题,因此采取One-vs-all 策略构建分类器,具体采用scikit-learn 工具包中One Vs Rest Classifier进行实现。在本文样本数量少且特征数量多的情况下,考虑线性支持向量机,使用核函数将有限维空间映射到高维空间,使其线性可分。同时,本文设定惩罚因子C来提升支持向量机模型的性能。因此,本文设置了多个惩罚因子C,以观察不同惩罚因子下支持向量机模型的分类准确率。
图3 显示了不同惩罚因子下简单交叉验证法的分类精确率(横坐标为惩罚因子,纵坐标为对应的分类精确率),表明惩罚因子C分别为1、1.5、2、4、6、8、8.5 和9 这8 个不同数值时,分类精确率逐渐减小。因此,本实验中惩罚因子设为1。

图3 不同惩罚因子下的分类精确率
此处仍以类别多标签分类为例。当本文选取惩罚因子C=1 时,用简单交叉验证法验证支持向量机模型的分类精确率达到了86%。
2.4 性能评价指标
本文使用精确率P、召回率R和F1值对训练得到的分类模型进行性能评价,计算公式分别为:

式中,a表示人工分类中属于该类的隐私政策条被分到该类的数目,b表示人工分类中不属于该类的隐私政策条款被分类模型分到该类的数目,c表示原本属于该类的隐私政策条款却被分类模型分到其他类的数目。
3 实验与结果分析
3.1 类别标签分类结果
为了研究上述分类算法对隐私政策条款类别和属性标签分类的有效性,分别基于本文训练得到的3 种多标签分类模型进行对比实验,实验结果如图4 所示。

图4 3 种分类模型的性能对比
从图4 可以看出,支持向量机模型的精确率、召回率和F1值均在0.85 左右,明显优于其他分类模型。当一个分类模型的性能达到较优时,其召回率增长的同时,精确率仍能保持在一个较高的水平上。而当精确率和召回率均较大时,才能保证F1值较大,一定程度上可以克服数据不均衡问题给分类模型性能造成的影响。反观朴素贝叶斯和卷积神经网络模型的精确率较好,但是这两个模型的召回率和F1值明显偏低。因此,从图4 可知,支持向量机模型在整体分类结果中所表现的性能最好。
3.2 属性标签分类结果
本文研究的是层次多标签分类问题,类别标签类别分类性能指标不能代表隐私政策中各个类别对应属性标签的分类能力。因此,在隐私政策类别分类指标的基础上,进一步研究上述各种算法对本文分类指标体系中7 种条款类别标签对应的属性标签的分类性能,结果如图5 所示。

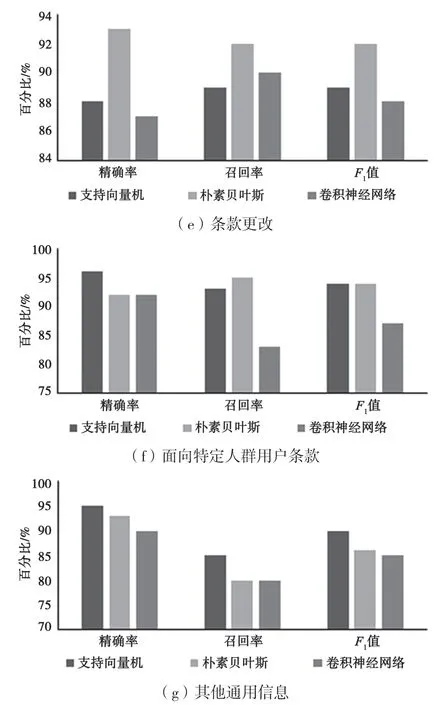
图5 属性标签的分类性能
从图5 可看出,支持向量机、朴素贝叶斯和卷积神经网络这3 个模型,面向特定人群用户条款和数据安全两个类别对应的属性标签的分类性能都较好。这与这两个类别下属性标签的分类特征较为明显有关,模型能够较好地学习到特征。第一方收集使用和与第三方共享转让公开类别对应的属性标签的分类性能,较以上两个类别稍弱。3 种分类模型的精确率值都达到了0.90 以上,召回率和F1值也都在0.85 以上。这与训练数据量大有关,模型能充分学习到分类特征。其余3 个类别对应的属性标签的分类性能稍弱,这与这3 个类别下的属性标签较为复杂有关,会干扰模型学习分类特征,从而对最后分类性能造成影响。纵观图5 中所有类别下属性标签的分类性能,支持向量机模型在7 个条款类别下的分类性能指标均达到了较高水平,其准确率、召回率和F1值均在0.90 上下,在各个类别对应的属性标签的分类性能上明显优于其余两个模型。
4 检测分析
4.1 虚假隐私政策检测
应用市场会为开发者提供填写隐私政策链接的接口,但部分开发者会在此接口处填写用户协议、官方网站或用户协议和隐私政策的混合文本链接。据JUNO隐私政策数据监测平台[14]的爬取结果显示,仅华为应用市场中就存在上万个隐私政策链接,因此通过人工审核来识别隐私政策的虚假性是不现实的。为了对这些虚假隐私政策进行自动检测,设计了一种判断虚假隐私政策的检测方法。
虚假隐私政策的检测基于以下事实。本文根据对华为应用市场上绝大多数隐私政策的观察,认为一篇隐私政策中描述符合除“其他通用信息”外的6项类别条款的比重应该占全文的绝大篇幅。本文设置系数R,在小型数据集上进行简单实验,由式(4)计算得出可以将R设置为0.55。其中,L代表文本长度,li(i=1,2,…,6)代表文本分类后这6 个类别分别对应的结果数量。如果一篇隐私政策中条款描述符合这6 个类别的占比小于R,则认为该隐私政策为虚假隐私政策。
本文对华为市场中的1 500 份隐私政策进行虚假检测。在1 500 篇被检测的文档中发现,578(38.5%)篇文档属于虚假隐私政策。本文在578篇虚假隐私政策中随机抽样250 篇进行人工检测,发现有23篇隐私政策被错误检测为虚假隐私政策,准确率为90.8%。根据对样本检测的结果,推断出R的值设置是合理的。

4.2 隐私政策完整性检测
《信息安全技术个人信息安全规范》要求隐私政策应该完整描述所要告知用户的所有条款信息。因此,如果一篇隐私政策中未全部涵盖本文分类标准中的所有类别对应的条款或者本文分类标准中类别下所有属性对应的条款涵盖的不全,那么该篇隐私政策就是不完整的隐私政策。
基于隐私政策条款自动分类结果,本文对过滤掉虚假隐私政策后的922篇正常隐私政策进行统计,结果如图6所示。从统计结果发现,共有853(92.5%)篇隐私政策没有完整说明“信息安全技术个人信息安全规范”所要求的内容,其中有707 篇隐私政策没有提到个人信息超期处理方式,有414 篇和447篇没有提及个人信息存储期限和个人信息出境情况。最终实验结果表明,目前大部分隐私政策条款在完整性方面不能满足《信息安全技术个人信息安全规范》的要求。

图6 隐私政策条款完整性检测
4.3 隐私政策的内容分布和完整性评分
观察发现,隐私政策条款分布中最常见的问题是:对一个类别条款的描述在隐私政策中多处提及,而不同类别条款的描述又可能在隐私政策中某个位置交叉提及,这种情况下用户很难抓住隐私政策中表达的具体内容。例如,很常见的“第一方收集/使用”和“与第三方共享/转让/公开”这两个类别条款在隐私政策中交错提及,用户很容易混淆这两个类别条款。
因此,本文认为隐私政策条款越完整、分布越集中,得到的评分应该越高。本文以类别为依据,对隐私政策分布情况进行评价,设计了如下评价方法。假设一篇隐私政策包含N句话和M个类别Ci,其中某个类别Ci包含ni句表述。针对某个类别Ci,本文使用式(5)的评价方法表示其条款表述是否集中。

式中,di,i+1表示相同类别Ci表述条款之间包含其他类别表述条款的数量。式(5)的例外情况为:如果一份隐私政策中缺少与Ci对应的隐私政策描述,则E(Ci)=0;如果与Ci对应的隐私政策只有一句话,则E(Ci)=1。

对于整篇隐私政策,使用如式(6)所示的评分方法。式(6)中Q=138,为隐私协议中平均语句数量。之所以在类别平均评分结果上乘以系数,是为了避免只包含少量条款的隐私政策得到高的评分。最后,使用arctan 函数进行归一化处理。
根据上述评分方法,本文选择华为应用中不同类型的10 款APP 进行对比评估。表3 显示了每款APP 隐私政策中所存在的个人信息安全问题及其对应的量化评分结果。量化评分结果可以直观表明隐私政策条款表述是否集中和条款是否完整。图7 给出了922 篇隐私政策的得分分布,横轴代表隐私政策的分数,纵轴代表评分区间内的隐私政策的数量。可以看出,有32.6%(301 篇)隐私政策在0~0.2,6.3%(57 篇)的隐私政策在0.5~0.7。因此,整体上看,隐私政策的质量一般。

表3 10 款APP 应用的对比评分

图7 隐私政策得分分布
5 结语
本文针对用户因中文隐私政策篇幅长、内容难以理解而不愿阅读的问题,提出了一种隐私政策条款自动分类的方法,并以华为应用市场为数据来源,采用TF-IDF 算法提取隐私政策各类别条款的关键特征,最终调用训练得到的支持向量机模型使隐私政策条款可以自动划分成各个类别,方便人们对隐私政策的阅读与理解,并通过分类结果评价华为应用市场中的隐私政策质量。通过在数据集上的测试与验证,证明了本文提出的自动分类法是有效的。该方法可对隐私政策条款按照本文定义的分类指标体系进行较为准确的分类,同时基于该方法对隐私政策的完整性进行了评价,并对隐私政策进行评分。分析结果表明,目前隐私政策的总体质量较低,无法体现其条款所要表达的真实含义。
本文标注数据集的数量有限,影响分类模型充分学习特征,使模型的分类性能受到了影响,因此下一步将扩充标注数据集,以提升模型的分类性能。
猜你喜欢
汽车实用技术(2022年19期)2022-10-19
预防青少年犯罪研究(2022年1期)2022-08-15
陶瓷学报(2021年4期)2021-10-14
少儿画王(3-6岁)(2020年4期)2020-09-13
中国外汇(2019年15期)2019-10-14
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
中国外汇(2015年11期)2015-02-02
