
融合改进LBP和SVM的偏光片外观缺陷检测与分类
2020-11-18 09:15:20黄广俊邓元龙
计算机工程与应用 2020年22期
黄广俊,邓元龙
深圳大学 机电与控制工程学院,广东 深圳518060
1 引言
随着社会的快速发展,人们的生活方式也发生了显著变化。人们更多地使用电子产品,如智能电视、手机、电脑等,它们已经成为人们日常生活中不可或缺的一部分。偏光片是薄膜晶体管液晶显示器(TFT-LCD)面板的核心部件,它大约占显示器面板总成本的10%[1]。一般而言,TFT-LCD 型偏光片的厚度大约0.3 mm,由5 层透明聚合物薄膜和1 层压敏胶水层组成。在生产过程中,偏光片极其容易出现异物、划痕、气泡、凹凸点、缺胶等外观缺陷。这些缺陷可能存在于薄膜的任何一层,降低液晶面板的质量,甚至导致其失效。偏光片缺陷类别的快速、准确检出,有利于控制产品质量,减少缺陷成品的出现。因此,生产企业对偏光片缺陷检测和分类非常重视。然而,人工目视离线检测存在着劳工强度大、实时性差、准确性不高等问题,而基于机器视觉的检测方法可以很大程度上克服上述弊端。
目前偏光片缺陷检测方法主要有传统图像处理和人工神经网络。Sohn等人提出一种新的稳定检出各种TFT-LCD偏光片缺陷的方法,并设计算法,根据自适应阀值判断偏光片缺陷二值图中是否有缺陷。在种类为6,数量为131的缺陷数据库中,其算法检出率为90.8%,其中暗区II 型缺陷和移除保护膜缺陷检错率较高[2]。Kuo 等人在较早时使用拉普拉斯算子和阀值统计决策方法进行自动检测,在200 张缺陷图像分类中,分类准确率达到98.0%,仅有4 张划痕缺陷被误分到点缺陷[3]。后来则提出使用最大灰度、离心率、对比度和灰度共生矩阵作为缺陷图像特征,输入到径向基神经网络和后向传播神经网络分类器中,在96 张训练样本和84 张测试样本中,分类准确率达到98.9%,单张图像处理时间为2.57 s[4]。Won等人在数量为210的偏光片缺陷数据库中,使用卷积神经网络,正确分类精度达到95.0%[5]。Lei等人使用Faster R-CNN深度学习神经网络来进行偏光片缺陷目标检测,实验结果显示,在使用VGG 模型时,其平均精度均值为67.5%,取得了非常好的检测精度,且检测速度几乎达到实时[6]。然而,传统图像处理方法容易受噪声等影响而降低处理精度和可靠性,而人工神经网络则需要大量的训练样本才可以保证足够的泛化能力,并且学习时间长,容易出现“过学习”等现象,这些问题在一定程度上限制了该方法的应用。支持向量机(Support Vector Machine,SVM)在解决小样本、非线性及高维模式识别问题中具有独特的优势[7]。本文对基于支持向量机的偏光片外观缺陷检测进行研究。实验结果表明,该方法能有效快速地实现偏光片外观缺陷的检测和分类。
2 偏光片外观缺陷检测及其特征提取
2.1 缺陷图像采集
根据暗场成像原理,使用工业相机获取偏光片缺陷图像,选择高斯滤波器作为图像预处理,然后进行缺陷可疑区域的快速检测和分割处理。常见的4 类偏光片缺陷和无缺陷背景图如图1所示。

图1 常见的偏光片外观缺陷类型
2.2 外观缺陷特征提取
2.2.1 LBP描述符及其常用变形
传统局部二值模式(Local Binary Pattern,LBP)描述符是将图像中每一个像素点的灰度值作为阀值,并与所在的3×3 邻域内像素灰度值相比较。为满足更大的区域覆盖,Ojala等人将3×3邻域扩展到任意邻域,并用圆形邻域代替正方形邻域。圆形LBP 描述符允许在半径为R 的圆形邻域内有任意多个像素点。对于邻域内未直接落在像素方格中央的点的灰度值,通过线性插值完成。为解决圆形LBP描述符过于稀疏的直方图问题,Ojala 等人提出了采用等价模式LBP 描述符来进行降维,特征向量维度由原来的256 维降至59 维。然而,等价模式LBP描述符是假设图像中LBP二进制编码仅存在1和0转换不超过2次的情况。由于图像纹理的多样性,每一类图像都有其各自的特点和关键信息,固定的等价模式并不适用于任何种类的图像,等价模式LBP描述符的特征表达能力有所降低[8]。为克服等价模式LBP的缺点,黄飞飞等人提出使用主成分分析方法对LBP进行维数约简,并命名为LBP 子模式。在ORL 数据库中的实验表明,LBP子模式无论在识别率还是维数方面都要优于LBP等价模式。为进一步丰富LBP描述符的描述能力,避免复杂的变换引起的计算复杂度的增加,张敦凤等人融合图像分区均值和传统圆形LBP 描述符的方法,相对单一LBP描述符,在YALU和ORL人脸数据库上,识别率分别提高9.28%和11.50%[9]。LBP 描述符及其变形形式示意图如图2所示。
2.2.2 改进LBP描述符

图2 传统LBP描述符及其变形形式示意图
ILBP具体步骤如下:
(1)特征提取。将预处理后的缺陷图像划分为不同分区,计算每个分区LBP 特征和均值特征,将所有分区提取特征连接成一个新的特征向量。
(2)数据归一化。为了能够更好地统一两种特征,测试样本单独使用训练样本上最大-最小值来归一化,将新的特征向量映射到[-1,1]之间。
(3)主成分分析。设归一化后的特征向量矩阵为X ,其列向量为xk=(x1k,x2k,…,xjk)T,缺陷的某一类型可由xk描述,协方差矩阵为:

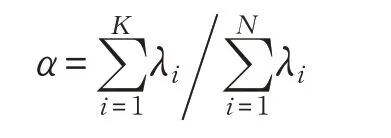
取其所对应的特征向量组成主成分方向,将缺陷图像变换到新的特征空间Y 中:Y=UTX 。
(4)线性判别方法。经PCA(Principal Component Analysis)降维后的缺陷图像特征向量Y=(y1,y2,…,yn)为n 维向量,共有5类,每类缺陷的个数为ni,第i 类的样本均值为,总体缺陷均值为缺陷类内散度矩阵Sw和类间散度矩阵Sb分别为:
融入语境设想,让学生有更多对话文本的机会。如在《天游峰的扫路人》教学中,针对天游峰的奇特景象,不妨建议学生思考:如果你在游览天游峰的时候,见到了这些扫路人,你想与他们畅谈什么呢?很显然,这样的开放性话题,让学生能够有更多自我对话文本的机会,能够让他们在主动融入文本中形成更多的深刻感知。很多同学在设想中认为,自己真想与扫路人一起扫路,体验其中的生活,感受他们的艰辛。有的同学说,扫路人每日登山不是为了赏风景,而是专门寻找败笔,我们游客应该换位思考,不能再随手乱丢垃圾。有的同学说,阅读了此文,让自己感受到劳动最伟大,只有尊重别人的劳动果实,才能收到别人的尊重,等等。

为得到最优投影矩阵,Sw、Sb满足如下准则:
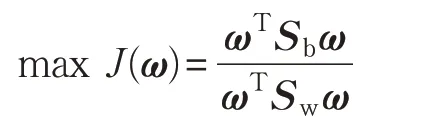
目标函数形式为广义瑞利商,是参数为投影向量ωT的函数。一般而言,经PCA降维后,样本个数大于样本维数,散度矩阵Sw非奇异[10-11]。通过拉格朗日乘数法可求得:

取最大的m 个特征值λi所对应的特征向量ωi构成最佳投影矩阵,将偏光片缺陷图像变换到新的特征空间Z 中:

3 支持向量机分类器设计
3.1 非线性问题的支持向量机
SVM处理非线性分类问题的基本原理就是通过非线性映射算法将原样本映射到一个更高维甚至无穷维的特征空间中,这样就可以将原本空间线性不可分的情况变成高维空间的线性可分问题。由于SVM是二元分类器,在解决多分类问题时,须由二元SVM来构造多元分类器。本文采用一对一法来构造多分类器。至于核函数的选择,本文选用高斯径向基核函数。
3.2 遗传算法参数寻优
SVM 的识别效果不仅受核函数影响,还受惩罚因子c 和核参数g 值的影响,因此需要对参数进行寻优。目前较常用的参数寻优方法有网格搜索法、遗传算法寻优法等。相对网格搜索法,采用启发式算法可以在更大范围内不必遍历网格内的所有参数点,就能找到全局最优解,且能有效减少陷入局部最优解的风险,具有鲁棒性好、收敛速度快的特点[12]。本文使用谢菲尔德大学的遗传算法工具箱来确定参数c 和g,具体流程如图3所示。

图3 使用遗传算法优化SVM参数流程图
4 仿真实验与结果分析
4.1 实验环境
仿真实验环境为Intel®Xeon®CPU E5-2630 v3@2.40 GHz 2.40 GHz,64 GB内存,Win7操作系统,Matlab R2017b 软件。为验证本文算法的准确率,在自建偏光片缺陷数据库和ORL数据库上进行仿真实验。其中,自建数据库包含5类缺陷,每类50张,每张大小为256×256,均根据暗场成像原理,由不同的照射方位拍照获得。随机抽取200 张(每类40 张)缺陷图像用于模型训练,剩余的50 张用于测试模型的性能。另外,ORL 人脸库有400张图像,包含40类,每类10张,每张大小为112×92。随机抽取240 张人脸图像用于模型训练,剩下的160 张用于模型测试。
4.2 实验结果和分析
实验将缺陷图像划分为2×2,4×4,6×6分区,均值特征划分为16×16,32×32分区情况下,两两特征组合来设计实验。另外,还验证了不同LBP 描述符下的识别率。为确保实验数据的可信度,训练样本采用十折交叉验证方法来进行验证,整体数据库的平均识别准确率如表1 所示。
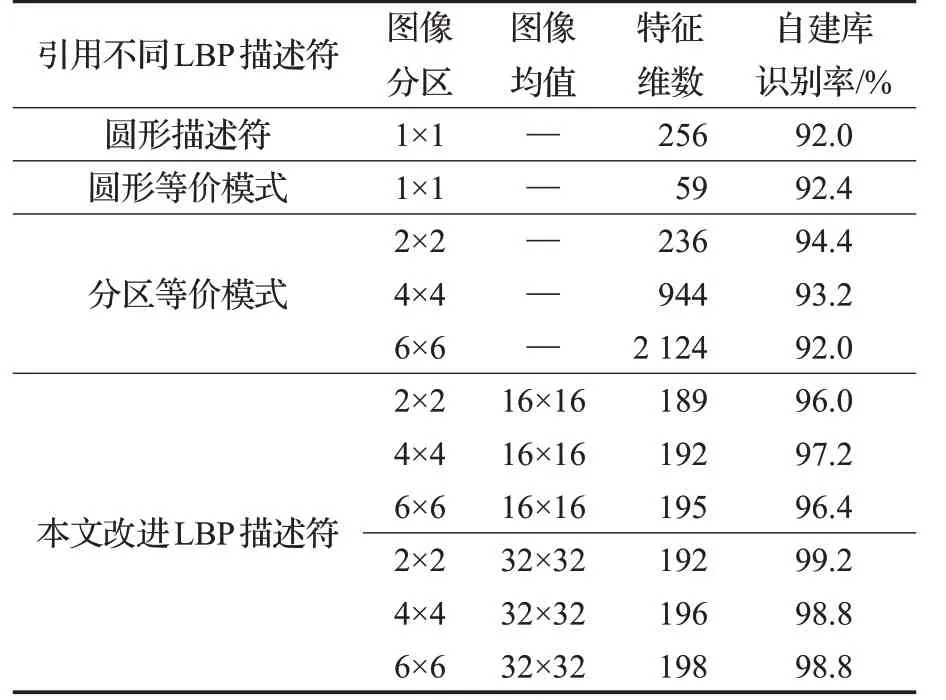
表1 不同LBP描述符及其变形形式下的识别率
从上述结果可以看出:传统LBP描述符分类准确率不高,图像分区在一定程度上可以提高识别准确率,但随着分区的增多,特征维数急剧增加,图像被分割得过于稀疏而丢失一些统计特性,导致识别率有一定程度下降。另外,当贡献率α 取合适值时,2×2图像分区的整体识别率为99.2%,达到最大,优于其他分区的识别准确率,而且特征维数相对较少。在充分考虑缺陷图像样本的类别信息后,改进LBP 描述符能高效地表示图像特征。针对自建数据集,通过调用SKLEARN中的集成算法,比较朴素贝叶斯、K 最近邻、随机森林、支持向量机等5种算法识别准确率,算法参数均调至最优。其在整体自建数据库上的分类结果如表2所示。
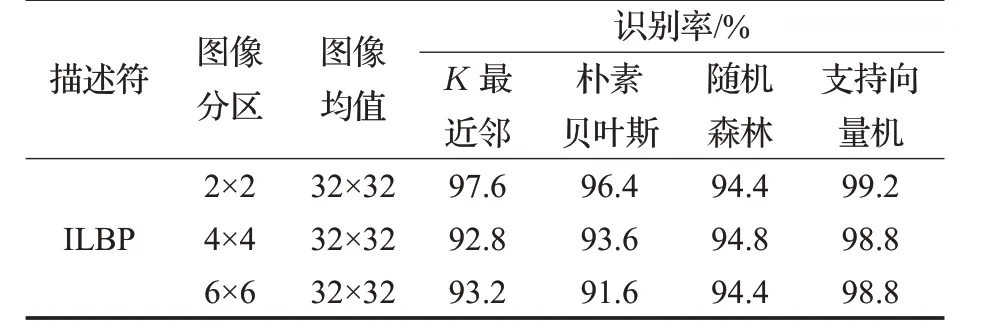
表2 不同算法下的识别率
实验结果显示,本文提出的ILBP描述符,在保证特征维数较低的情况下,识别率能得到很好的提高。识别准确率会随α 和图像分区大小变化。当贡献率α 较小时,丢失原有缺陷图像较多的信息,分类器识别精确度下降。当α 接近1时,缺陷图像保持大量原有的冗余信息,分类器分类困难。同时越精细的分区意味着更高维数的复合特征和更好的局部能力。因此,对于偏光片缺陷图像,当分区越精细时,贡献率α 应取越大的值。偏光片缺陷数据库识别率随主成分贡献率和图像分区大小关系如图4所示。
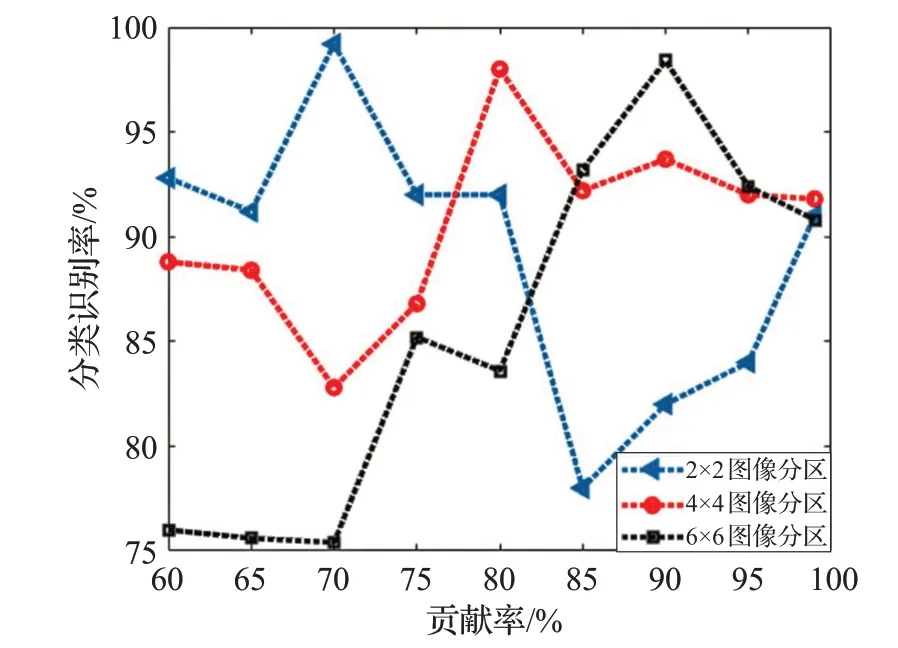
图4 不同主成分和图像分区下的识别率
上述实验充分地说明,当取较大α 值时,ILBP描述符可获得比较理想的识别效果,分类识别精确率和分类效率等综合性能优于传统LBP 描述符及常用的改进LBP 描述符,且分类速度快,每张缺陷图像由输入到完成识别所耗时间在0.92 s,极大地减少了计算的时间复杂度,完全满足工业生产线实际检测需求。
4.3 遗传算法寻优结果
在分类器训练过程中,使用遗传算法对惩罚因子c和核参数g 进行寻优,搜索范围是(2-12,212)。搜索过程中用十折交叉验证法对SVM 分类器进行评价,得到一组交叉验证中平均准确率最高的参数c 和g,利用最优参数进行缺陷图像分类。以2×2图像分区的ILBP描述符在自建数据库上分类为例,参数寻优如图5所示。

图5 遗传算法寻优结果
5 结束语
(1)验证了LBP及其常用变形形式在自建数据库上的识别效果,并对提出的ILBP 描述符在不同分区情况和主成分比例下的识别效果进行讨论。实验结果表明,在自建缺陷数据库中,分类正确率能够达到99%以上,SVM在解决偏光片缺陷识别问题上有着独特的优势。
(2)文中ILBP 描述符应用到ORL 数据库中,分类正确率能够到达99.75%,而且数据的维度仅为39维,相对于徐竞泽等人提出的算法[13],本文算法分类精度更高。另外,相对于张郭凤等人提出的描述符,虽然分类准确率同为99.75%,但是特征维数由原来1 280维降至39 维,大大降低计算复杂度。上述进一步论证了ILBP描述符的有效性。
(3)通过遗传算法参数寻优,避免网络重复搜索和设置。结果表明,利用遗传算法能够在较大范围内有效确定SVM分类器的最优参数。
(4)实验所用的缺陷图像根据透射暗场成像原理拍取,图像数量不多,全都选取典型的缺陷图像,分类干扰少,分类识别准确率较高。因此,接下来的工作是采用其他成像原理,如结构光成像[14]、偏振光成像[15]等来进行图像拍取,而且研究大样本、强干扰情况下的偏光片缺陷图像检测和分类。
猜你喜欢
测绘学报(2022年12期)2022-02-13 09:13:01
中国电子报(2020年86期)2020-12-29 11:54:08
证券市场红周刊(2020年25期)2020-07-04 13:27:59
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
液晶与显示(2019年5期)2019-06-11 07:35:02
中国交通信息化(2018年3期)2018-06-13 03:27:58
数字通信世界(2018年1期)2018-04-18 11:05:22
股市动态分析(2017年24期)2017-06-29 12:00:16
测绘科学与工程(2017年5期)2017-05-07 06:30:44
